

Các vector này hoạt động như các biểu đồ toán học của các đặc điểm hoặc phẩm chất. Số chiều trong mỗi vector có thể biến đổi rộng rãi, từ chỉ vài chiều đến hàng ngàn chiều, dựa trên sự phức tạp và mức độ chi tiết của dữ liệu.
Giới thiệu Với sự bùng nổ của các Mô hình Ngôn ngữ Lớn (LLM) như GPT-4 của OpenAI và Claude của Anthropic, nhu cầu về cách hiệu quả để xử lý và tiến hành quá trình xử lý lượng dữ liệu khổng lồ mà chúng sử dụng đã tăng cao. Nhiều người có thể quen thuộc với cơ sở dữ liệu quan hệ tiêu chuẩn, nhưng các yêu cầu độc đáo của LLMs thường đòi hỏi sử dụng các công cụ chuyên biệt hơn.
Do đó, chúng ta đã thấy xuất hiện một loại cơ sở dữ liệu mới: Cơ sở dữ liệu Vector.
Cơ sở dữ liệu Vector là gì?
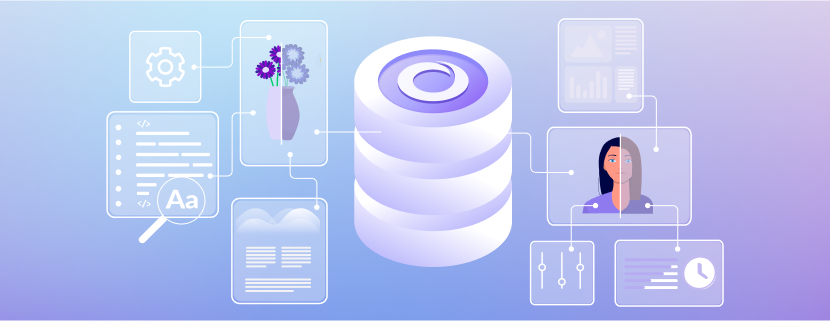
Một cơ sở dữ liệu Vector là một loại cơ sở dữ liệu cụ thể được thiết kế để chuyển đổi dữ liệu – thường là dữ liệu văn bản – thành các vector đa chiều (còn được gọi là nhúng vector) và lưu trữ chúng theo cách tương ứng. Các vector này hoạt động như các biểu đồ toán học của các đặc điểm hoặc phẩm chất. Số chiều trong mỗi vector có thể biến đổi rộng rãi, từ chỉ vài chiều đến hàng ngàn chiều, dựa trên sự phức tạp và mức độ chi tiết của dữ liệu.
Điều này cho phép phân tích và so sánh dữ liệu một cách hiệu quả và hiệu quả, cho phép thực hiện các nhiệm vụ như tìm kiếm sự tương đồng và phân cụm. Việc sử dụng các vector trong một cơ sở dữ liệu có thể cải thiện đáng kể khả năng xử lý dữ liệu và cho phép các ứng dụng dựa trên dữ liệu tiên tiến.
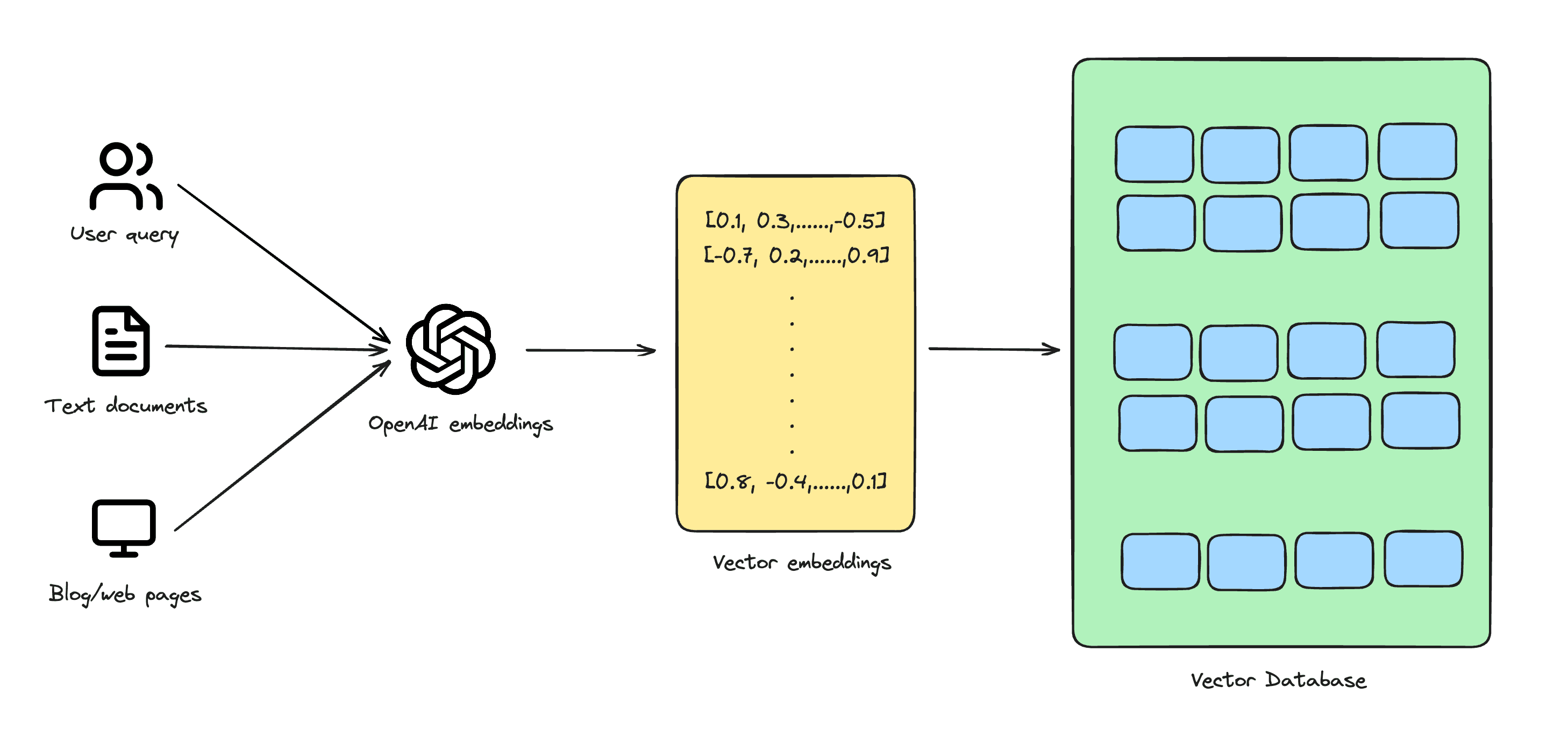
Hãy tưởng tượng bạn đang viết một bài nghiên cứu dài, và thay vì đọc từng trang một, bạn có một thư mục đặc biệt biến mỗi trang thành một mã vạch duy nhất. Những mã vạch này đại diện cho những điểm chính và chi tiết của từng trang. Một số mã vạch có thể đơn giản chỉ với vài dòng, trong khi những cái khác rất phức tạp với hàng ngàn dòng, phụ thuộc vào độ sâu của nội dung trên trang đó.
Bây giờ, nếu bạn muốn tìm các trang có chủ đề tương tự hoặc nhóm chúng theo chủ đề, bạn chỉ cần so sánh mã vạch của chúng một cách nhanh chóng. Phương pháp này giúp quản lý và hiểu nội dung nghiên cứu của bạn trở nên dễ dàng và hiệu quả hơn, giống như cách cơ sở dữ liệu vector xử lý và phân tích dữ liệu.
8 cơ sở dữ liệu vector phổ biến nhất hiện nay

1. Pinecone
Pinecone là một công cụ giúp dễ dàng cung cấp bộ nhớ dài hạn cho các ứng dụng trí tuệ nhân tạo (AI) có hiệu suất cao. Đó là một cơ sở dữ liệu vector quản lý, chạy trên nền tảng đám mây với giao diện lập trình ứng dụng (API) đơn giản và không có phiền toái về hạ tầng. Pinecone cung cấp kết quả truy vấn tươi mới và đã lọc với độ trễ thấp ở quy mô hàng tỷ vectors.
2. Weaviate
Weaviate là một cơ sở dữ liệu vector mã nguồn mở. Nó cho phép bạn lưu trữ các đối tượng dữ liệu và nhúng vector từ các mô hình học máy ưa thích của bạn, và mở rộng một cách mượt mà lên hàng tỷ đối tượng dữ liệu.
3. Chroma
Chroma là cơ sở dữ liệu nhúng mã nguồn mở. Chroma giúp việc xây dựng các ứng dụng sử dụng Mô hình Ngôn ngữ Lớn trở nên dễ dàng bằng cách làm cho kiến thức, sự thật và kỹ năng có thể được tích hợp vào các Mô hình Ngôn ngữ Lớn.
4. LanceDB
LanceDB là một cơ sở dữ liệu mã nguồn mở dành cho tìm kiếm vector được xây dựng với lưu trữ liên tục, giúp đơn giản hóa việc truy xuất, lọc và quản lý các nhúng vector.
5. Milvus

Milvus là một cơ sở dữ liệu vector mã nguồn mở được xây dựng để hỗ trợ tìm kiếm sự tương đồng của các nhúng và ứng dụng trí tuệ nhân tạo. Milvus giúp tìm kiếm dữ liệu không cấu trúc trở nên dễ dàng hơn và cung cấp trải nghiệm người dùng đồng nhất bất kể môi trường triển khai.
6. Qdrant
Qdrant là một công cụ tìm kiếm sự tương đồng vector và cơ sở dữ liệu vector. Nó cung cấp một dịch vụ sẵn sàng cho sản xuất với một API thuận tiện để lưu trữ, tìm kiếm và quản lý các điểm – các vector với thông tin bổ sung.
7. Supabase
Supabase là một cơ sở dữ liệu Vector mã nguồn mở dành cho việc phát triển ứng dụng trí tuệ nhân tạo. Sử dụng pgvector để lưu trữ, chỉ mục và truy cập nhúng, và bộ công cụ trí tuệ nhân tạo của chúng tôi để xây dựng các ứng dụng trí tuệ nhân tạo với Hugging Face và OpenAI.
8. Vercel Postgres
Vercel Postgres là một cơ sở dữ liệu SQL không máy chủ được thiết kế để tích hợp với Vercel Functions và khung công việc frontend của bạn. Với pgvector để tìm kiếm sự tương đồng vector, bạn có thể xây dựng các ứng dụng tìm kiếm ngữ nghĩa bằng cách sử dụng Next.js và Vercel AI SDK.
Lựa chọn cơ sở dữ liệu vector cho ứng dụng AI

Khi chọn một cơ sở dữ liệu vector, có một số yếu tố cần xem xét, như:
- Kích thước và loại dữ liệu bạn cần lưu trữ: Một số cơ sở dữ liệu vector thích hợp hơn cho việc lưu trữ lượng lớn dữ liệu, trong khi những cái khác phù hợp hơn cho việc lưu trữ lượng nhỏ dữ liệu. Một số cơ sở dữ liệu vector phù hợp hơn cho việc lưu trữ dữ liệu văn bản, trong khi những cái khác phù hợp hơn cho việc lưu trữ dữ liệu hình ảnh hoặc âm thanh.
- Các tính năng và chức năng bạn cần: Một số cơ sở dữ liệu vector cung cấp nhiều tính năng và chức năng hơn so với các cơ sở dữ liệu khác. Ví dụ, một số cơ sở dữ liệu vector cho phép bạn xây dựng các mô hình học máy, trong khi các cơ sở dữ liệu khác không cho phép.
- Ngân sách của bạn: Các cơ sở dữ liệu vector có mức giá dao động từ miễn phí đến hàng ngàn đô la mỗi tháng. Quan trọng là bạn chọn một cơ sở dữ liệu vector phù hợp với ngân sách của bạn.
Các ứng dụng của cơ sở dữ liệu vector
- Tìm kiếm hình ảnh: Cơ sở dữ liệu vector có thể được sử dụng để xây dựng các hệ thống tìm kiếm hình ảnh có khả năng tìm kiếm các hình ảnh tương tự dựa trên nội dung hình ảnh của chúng.
- Đề xuất gợi ý sản phẩm: Cơ sở dữ liệu vector có thể được sử dụng để xây dựng các hệ thống đề xuất sản phẩm, giúp đề xuất sản phẩm cho người dùng dựa trên lịch sử mua sắm và sở thích của họ.
- Phân loại văn bản: Cơ sở dữ liệu vector có thể được sử dụng để phân loại các tài liệu văn bản vào các danh mục khác nhau, chẳng hạn như tin tức, thể thao hoặc tài chính.
- Xử lý ngôn ngữ tự nhiên: Cơ sở dữ liệu vector có thể được sử dụng để thực hiện các nhiệm vụ xử lý ngôn ngữ tự nhiên, như phân tích tâm trạng và dịch máy.
- Phát hiện gian lận: Cơ sở dữ liệu vector có thể được sử dụng để phát hiện gian lận bằng cách nhận biết các mẫu hoạt động đáng ngờ.
- Khám phá thuốc mới: Cơ sở dữ liệu vector có thể được sử dụng để khám phá các loại thuốc mới bằng cách nhận biết các mẫu trong dữ liệu sinh học.
Sử dụng Cơ sở dữ liệu Vector như thế nào?

Sử dụng một cơ sở dữ liệu vector không khác biệt nhiều so với việc sử dụng bất kỳ loại cơ sở dữ liệu nào khác, tuy nhiên, các hoạt động bạn thực hiện có thể thay đổi dựa trên bản chất cụ thể của dữ liệu vector. Dưới đây là hướng dẫn đơn giản để bắt đầu:
- Cài đặt & Thiết lập: Bắt đầu bằng việc lựa chọn cơ sở dữ liệu vector phù hợp với nhu cầu của bạn. Sau khi đã lựa chọn, làm theo hướng dẫn cài đặt được cung cấp. Nhiều cơ sở dữ liệu cung cấp các giải pháp dựa trên đám mây, vì vậy việc thiết lập có thể đơn giản như tạo tài khoản.
- Nhập Dữ liệu: Nhập dữ liệu vector của bạn vào cơ sở dữ liệu. Bước này có thể đòi hỏi bạn chuyển đổi dữ liệu của mình thành định dạng vector nếu nó chưa ở dạng đó.
- Truy vấn: Khi dữ liệu của bạn đã ở đúng vị trí, bạn có thể bắt đầu truy vấn cơ sở dữ liệu để tìm các vector tương tự hoặc thực hiện các hoạt động phân tích. Hầu hết các cơ sở dữ liệu vector sẽ cung cấp cho bạn một ngôn ngữ truy vấn hoặc một API được tùy chỉnh để xử lý các hoạt động vector.
- Bảo trì & Mở rộng: Giống như với bất kỳ cơ sở dữ liệu nào khác, bạn cần theo dõi hiệu suất, xử lý việc sao lưu và đảm bảo rằng cơ sở dữ liệu của bạn mở rộng phù hợp với nhu cầu của bạn.