

Để giúp anh/chị quyết định có đọc tiếp hay không, tôi xin phép cung cấp các thông tin liên quan đến bài post này như sau:
- Chủ đề: Parallel computing (điện toán song song), Electronics (Điện tử), Machine Learning
- Tính thời sự: Tháng 5/2024.
- Thời gian đọc: 11 phút, lồng vào thời gian uống cà phê (uống cà phê xong là đọc xong).
–
Ⓐ. Đề dẫn.
Tôi đã có dịp đàm luận cùng anh chị về GPU (Graphics Processing Unit), về việc sản xuất chip, về quy trình, các nội dung liên quan đến thiết kế chip. Lần này, chúng ta thử tò mò xem TPU (Tensor Processing Unit) được Google thiết kế, sản xuất rồi đưa vào vận hành như thế nào. Tôi cho rằng dân ICT là dân có bản tính tò mò, đặc biệt là tò mò về công nghệ.
Con đường dẫn đến TPU
Ngay từ năm 2006, Google đã tính đến chuyện làm ASIC (IC chuyên dụng), nhưng họ còn nấn ná chưa thực hiện. Đến năm 2013, khi họ định đưa giọng nói vào tìm kiếm (voice search) thì câu chuyện trở nên cấp bách. Họ tính rằng, nếu trung bình một người dùng một ngày thực hiện voice search trong 3 phút thì Google phải tăng gấp đôi số lượng trung tâm dữ liệu (data centers) của họ chỉ để khai thác các mô hình Machine Learning vào thời điểm lúc bấy giờ. Rõ ràng là cần tăng tốc độ xử lý các mô hình – vấn đề là cần tăng tốc ở khâu nào?
❰Bên lề❱
Tôi xin phép được “làm tươi” bộ nhớ của anh/chị về mô hình mạng nơ-ron (neural network). Để xây dựng mô hình, người ta tập hợp một lượng cực lớn dữ liệu (cỡ Giga, Tera bytes), làm sạch dữ liệu rồi huấn luyện (training) mô hình. Khi huấn luyện mô hình người ta điều chỉnh các trọng số (weights) sao cho đầu ra được tối ưu.
Sau khi đầu ra được cho là tối ưu, người ta dừng pha huấn luyện và đưa mô hình vào triển khai trong thực tế. Triển khai ứng dụng trong thực tế là như thế nào? Một cách giản lược, chúng ta hình dung như sau:
[Đầu vào] ⇨ {Mô hình} ⇨ [Đầu ra]
Lấy một ví dụ cho dễ hiểu: mô hình nhận dạng giọng nói. Để huấn luyện, người ta tập hợp hàng chục/trăm ngàn bản ghi dạng:
[âm thanh giọng nói → văn bản tương ứng],
[âm thanh giọng nói → văn bản tương ứng],
…
Sau khi huấn luyện thì khi chúng ta “nói một câu” (dạng âm thanh) thì mô hình cho ra một “đoạn văn bản”:
[Câu nói] ⇨ {Mô hình} ⇨ [đoạn văn bản]
❰/Bên lề❱
Pha huấn luyện thường kéo dài hàng tuần, thậm chí hàng tháng – người ta không đặt nặng vấn đề tốc độ xử lý với pha này. Chất lượng mô hình mới là vấn đề người ta quan tâm ở pha huấn luyện. Lấy ví dụ: mô hình nhận dạng giọng nói. Chất lượng mô hình là đạt được mức độ nhận dạng với sai sót rất thấp: ví dụ, dưới 1%. Tuy nhiên, khi khai thác mô hình (suy diễn: inference) thì tốc độ là cái người ta quan tâm hàng đầu. Ví dụ: tìm kiếm bằng giọng nói (voice search). Khi người dùng nói một câu thì engine tìm kiếm (search engine) phải nhận dạng gần như ngay tức thì (trong vòng vài giây đồng hồ), chuyển câu nói thành văn bản, rồi search engine dùng văn bản đó để tìm kiếm trên Internet. Không có chuyện sau khi nói xong phải mất mấy phút mới nhận dạng được giọng nói: người dùng sẽ bỏ đi, không quay lại dùng dịch vụ search engine đó nữa. Như vậy, khâu cần tăng tốc là khâu khai thác mô hình (inference).
 Hình 1: Một mạng nơ-ron sau khi huấn luyện. Hình 1: Một mạng nơ-ron sau khi huấn luyện. |
Giả thiết rằng sau khi huấn luyện, người ta được mạng nơ-ron như trong hình 1. Sang bước khai thác mô hình: cho vector đầu vào là X ([x1, x2, x3]) chúng ta phải tính vector đầu ra Y ([y1, y2]). Nghĩa là cho X mô hình suy ra Y.
[x1, x2, x3] ⇨ {Inference} ⇨ [y1, y2]
Mời anh/chị chúng ta cùng đi vào chi tiết một tẹo nhé:
- Đầu vào: [x1, x2, x3]
- Đầu ra: [y1, y2]
- Hàm kích hoạt (activation) là hàm sigmoid:

–
Thực chất Inference là feedforward pass. Trong feedforward pass, các đầu vào sẽ được nhân với trọng số ở mỗi lớp để tạo ra đầu ra ở lớp tiếp theo. Vậy nên lớp h (lớp ẩn) được tính như sau:

(nhân ma trận: [x] * [w (trọng số)] = [h’])
Sau đó, ở lớp ẩn (lớp h), áp hàm kích hoạt thì được:

–
Cuối cùng chúng ta áp phép nhân ma trận với tập trọng số, áp hàm kích hoạt để tính các nơ-ron đầu ra:


–
Tóm tắt: từ trái sang phải, không tính lớp đầu vào (x), cách tính giá trị mỗi lớp là:
[h/y] = factivation (nhân ma trận)
–
Có thể dễ dàng nhận thấy các phép toán của Inference là loạt các phép nhân ma trận và áp hàm kích hoạt (activation function). Số các phép nhân ma trận tùy thuộc vào mô hình có bao nhiêu lớp (layers). Các mô hình thông thường có từ vài chục đến vài trăm lớp, có khi đến hàng nghìn lớp. Tại mỗi lớp, số trọng số (weights) thường từ hàng triệu đến hàng chục triệu. Tổng hợp lại, có thể thấy lượng tính toán là khổng lồ.
Chú ý: Khi khai thác mô hình (Inference), các trọng số (weights) có giá trị cố định.
–
Kết luận: Khâu cần tăng tốc là Inference và trọng tâm của tăng tốc là nhân ma trận.
–
Nếu dùng thuật toán phần mềm để tăng tốc thì rất ít thứ có thể làm được. Vì vậy, bắt buộc họ phải nghĩ đến việc “cứng hóa” phép nhân ma trận. Việc “cứng hóa” có nghĩa là sau mỗi nhịp xung đồng hồ máy thực hiện đồng thời N phép toán (ví dụ, N = 256*256). Một nhịp xung đồng hồ tương đương với một clock của khối thạch anh. Ví dụ, TPUv1 có clock speed là 700 MHz – nghĩa là trong 1 giây có 700 triệu nhịp xung đồng hồ.
Vấn đề là thiết kế phần cứng như thế nào?
–
Ⓑ. Kiến trúc TPU.
Yêu cầu thiết kế
Vào thời điểm năm 2013, khi nói đến Google là chúng ta nói đến công ty phần mềm máy tính, là công ty sở hữu công cụ tìm kiếm trên mạng Internet. Họ không chuyên về phần cứng. Vì vậy, cách mà Google tiếp cận giải quyết vấn đề là họ mời một kiến trúc sư phần cứng danh tiếng làm trưởng nhóm kỹ thuật dự án, đó là ông Norman Jouppi. Mọi thứ sau đó phải theo quan điểm của trưởng nhóm.
Theo quan điểm của ông này, thiết kế TPU cần tư duy cấp tiến, đột phá. Lúc đầu họ đặt lên bàn rất nhiều phương án thiết kế để tạo ra một con “chip suy luận” (inference) bằng việc lai tạo từ CPU và GPU, nhưng cuối cùng Jouppi chọn một hướng đi riêng cho Google. Jouppi cho biết nhóm kỹ thuật phần cứng đã nghĩ đến FPGA để giải quyết vấn đề: giá rẻ, hiệu quả và hiệu suất cao trước khi chuyển sang giải pháp ASIC. Ông giải thích: “Lý lẽ cơ bản mà mọi người đưa ra đối với FPGA là họ muốn thứ gì đó dễ thay đổi nhưng vấn đề hiệu suất (performance), vấn đề khả năng lập trình (programmability), vấn đề tiêu hao năng lượng thấp thì FPGA không bằng ASIC”. “TPU có thể lập trình được như CPU hoặc GPU. Nó không chỉ được thiết kế cho một mô hình mạng nơ-ron; nó thực thi các lệnh CISC trên nhiều mô hình. Vì vậy, nó vẫn có thể lập trình được, nhưng sử dụng ma trận làm nguyên hàm thay vì vectơ hoặc số vô hướng”.
–
Kết luận: TPU ngoài việc chạy nhanh còn phải “tiêu hao năng lượng thấp”.
Ngoài ra, vì họ cần triển khai TPU vào các máy chủ hiện có lúc đó của Google một cách nhanh nhất có thể, họ đã chọn giải pháp thiết kế bộ xử lý TPU dưới dạng card gắn ngoài, cắm vào một khe PCI trên bo mạch chủ.
–
Sơ đồ khối
 Hình 2: Sơ đồ khối TPU (nguồn) Hình 2: Sơ đồ khối TPU (nguồn) |
Hình 2 ở trên mô tả sơ đồ khối của TPU. Quy ước về màu trong sơ đồ trên:
- Xanh lá cây: Phần I/O không thuộc TPU
- Xanh da trời: Dữ liệu đệm trong TPU
- Vàng: Mảng tính toán
- Đỏ: Mảng điều khiển
–
Để không làm nhức đầu anh/chị, tôi trích xuất một số khối cơ bản trong sơ đồ trên:
- Matrix Multiplier Unit (MXU): Khối nhân ma trận (màu vàng ở góc phải trên). Khối này gồm 65,536 bộ MAC (Multiply-Accumulate – nhân & cộng dồn).
- Unified Buffer (UB): Vùng bộ nhớ đệm hợp nhất (màu xanh da trời ở giữa) chứa 24MB bộ nhớ SRAM. Bộ nhớ này đóng vai là các thanh ghi (register).
- Activation Unit (AU): Khối hàm kích hoạt (màu vàng ở góc phải dưới). Các hàm này được “cứng hóa”.
Nhằm kiểm soát sự phối hợp giữa các khối này, người ta đưa vào nhiều câu lệnh (instruction). Dưới đây là các câu lệnh chính:
- Read_Host_Memory: câu lệnh đọc bộ nhớ của CPU và chuyển vào bộ nhớ đệm UB.
- Read_Weights: câu lệnh đọc bộ nhớ trọng số (Weight Memory) và chuyển vào hàng đợi FIFO (Weight FIFO). Weight FIFO là một đầu vào của MXU.
- MatrixMultiply/Convolve: câu lệnh này kích hoạt MXU thực hiện phép nhân với UB và lũy kế vào Accumulators. Cách thực thi: đầu tiên, trọng số được đọc vào ma trận vuông 256×256 ô (bước 2 ở trên). Đầu vào [x] được chia thành B mảng 256: Input = mảng B*256. Phép nhân được thực hiện B nhịp xung (xem thêm phần Systolic Array ở dưới). Dưới góc độ lập trình, chúng ta có thể viết như sau:
Accumulators = Input * Weights. - Activate: câu lệnh kích hoạt hàm phi tuyến activation function với các tùy chọn như ReLU, Sigmoid, … Kết quả sau khi áp hàm kích hoạt được lưu vào bộ nhớ UB. Nếu gọi hàm kích hoạt là factivation, dưới góc độ lập trình, chúng ta có thể viết như sau:
UB = factivation (Accumulators). - Write_Host_Memory: câu lệnh đọc dữ liệu từ bộ nhớ đệm UB của TPU và ghi vào bộ nhớ của CPU.
–
Luồng xử lý của TPU
Cách phối hợp giữa CPU và TPU tương tự như cách phối hợp giữa CPU và GPU: vai của CPU là chủ (host) và vai của TPU là thiết bị (device). CPU thiết lập các tham số trước khi “ra lệnh” (instruct) TPU thực hiện các phép toán.
–
Có thể khái quát luồng xử lý trong nội tại TPU như sau:
- TPU đọc bộ nhớ từ CPU và ghi vào bộ nhớ UB (Read_Host_Memory)
- TPU đọc trọng số từ bộ nhớ DRAM (bộ nhớ ngoài – ký hiệu DDR DRAM Chips trong hình 2) ghi vào Weight FIFO (bộ nhớ trong của TPU) (Read_Weights)
- Nạp trước trọng số (weights) vào 256×256 ô MAC (bộ nhân và cộng dồn) của MXU – lấy dữ liệu từ Weight FIFO (phía trên khối MXU)
- Thiết lập dữ liệu systolic trong khối Systolic Data Setup (phía trái khối MXU)
- Thực thi phép nhân ma trận: [dữ liệu systolic: B*256] x [trọng số (weights): 256*256] bằng loạt nhịp xung đồng hồ. Kết quả ghi vào Accumulators (phía dưới khối MXU) (MatrixMultiply/Convolve)
- Áp hàm kích hoạt (Activation), áp hàm chuẩn hóa (Normalize / Pool), ghi kết quả vào bộ nhớ UB (Activate)
- Đọc kết quả trong bộ nhớ UB và ghi vào bộ nhớ của CPU (Write_Host_Memory)
–
Ⓒ.Systolic Array: trái tim của TPU.
Bây giờ chúng ta tò mò cùng tìm hiểu xem TPU thực hiện phép nhân ma trận như thế nào.
Nhân ma trận
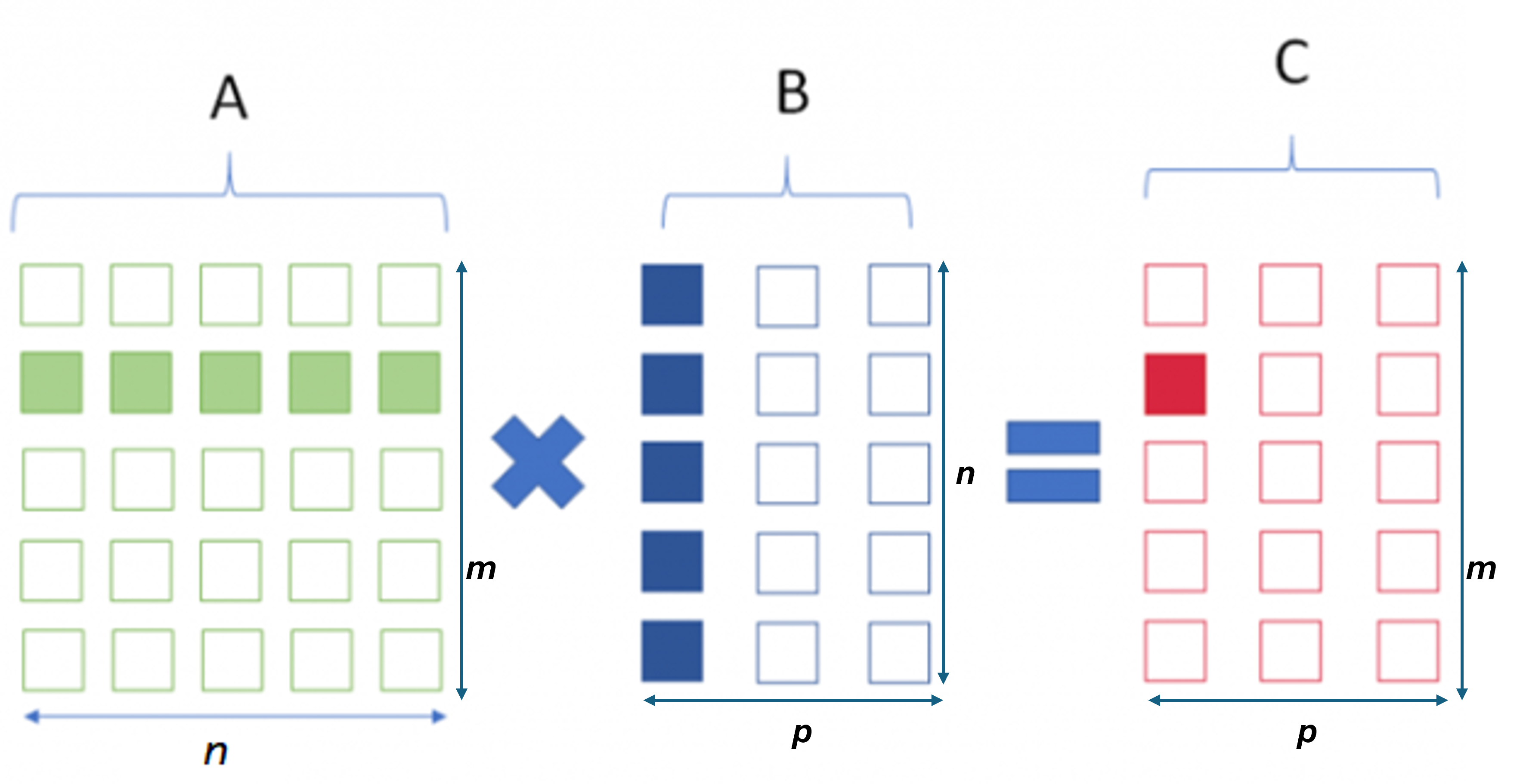
Nhưng trước hết chúng ta cùng nhắc lại khái niệm nhân ma trận. Giả thiết chúng ta nhân 2 ma trận A và B với nhau được ma trận C như trong hình 3. A có m hàng, n cột (m × n), B có n hàng, p cột (n × p), C có m hàng và p cột (m × p). Chú ý rằng A và B muốn nhân được với nhau thì số cột của A phải bằng số hàng của B.
 Hình 3: Nhân ma trận: A × B = C Hình 3: Nhân ma trận: A × B = C |
Mỗi một ô trong ma trận C (màu đỏ) = tổng của các tích của ô trong ma trận A (màu xanh lá cây) với ô trong ma trận B (màu xanh nước biển):

Để tính cij chúng ta cần n phép nhân và (n-1) phép cộng.
❰Bên lề❱
Việc tính các ô trong ma trận C là hoàn toàn độc lập với nhau nên người ta có thể áp dụng tính toán song song đối m × p ô của C. Đây là lý do vì sao các GPU được áp dụng rộng rãi trong mạng nơ-ron (neural network): các ô cij được tính song song với nhau bằng hàng ngàn processor của GPU.
❰/Bên lề❱
–
Systolic Array
Bây giờ chúng ta bàn đến kiến trúc systolic. Đây là một kiến trúc phần cứng khá thú vị, đã được đề cập đến bằng một bài báo từ năm 1982. Anh/chị nào có thời gian tìm hiểu sâu về vấn đề này xin tham khảo ở đây.
Hệ thống systolic là mảng hình lưới các ô có tên gọi là PE. PE là viết tắt của Processing Element – tạm dịch là phần tử xử lý. Mỗi phần tử PE thực hiện phép toán như nhân, cộng và truyền dữ liệu sang phần tử kế tiếp. Thông tin được truyền từ ô này sang ô bên cạnh theo hình thức “đường ống” – không sử dụng bộ nhớ trung gian. Việc không sử dụng bộ nhớ trung gian vừa tăng tốc độ xử lý vừa giảm thiểu tiêu hao năng lượng. Giao tiếp với thế giới bên ngoài chỉ thực hiện ở các ô biên (xem hình 4 dưới đây).
Phương thức xử lý của hệ thống systolic gần giống với phương thức xử lý “đường ống”. Chỉ khác là hệ thống systolic có đường ống hai chiều: ống đẩy từ trái qua phải và ống đẩy từ trên xuống dưới.
 Hình 4: Kiến trúc hệ thống mảng Systolic (nguồn). |
Khối MXU của TPU là mảng systolic gồm N x N (N=256) bộ MAC. MAC tương đương với PE trong hình 4.
MXU thực hiện phép nhân ma trận như thế nào?
Để đơn giản hóa vấn đề, tôi xin phép minh họa bằng việc nhân 2 ma trận 3×3: WA=Y.
Trước khi thực hiện phép nhân ma trận, người ta nạp trước W (mảng trọng số) và sắp xếp các phần tử của ma trận A như trong hình 5 dưới đây.
Phép nhân ma trận được thực hiện bằng các nhịp xung đồng hồ (clock). Chúng ta ký hiệu một ô trong lưới systolic là w(i,j).Sau mỗi nhịp xung, các ô trong lưới sẽ thực hiện các phép toán sau:
- Lấy giá trị w(i,j) nhân với đầu vào a (đầu vào a được truyền từ phía trái sang). Nếu j > 1 thì đầu vào a là w(i,j-1). Nếu j = 1 thì đầu vào là từ một phần tử thuộc mảng A (bên trái).
- Lấy kết quả phép nhân w(i,j)*a cộng với giá trị s của ô phía trên truyền xuống được w(i,j)*a + s. Nếu i > 1 thì s chính là giá trị của ô w(i-1,j). Nếu i = 1 thì s = 0.
- Truyền giá trị đầu vào a sang ô bên phải: w(i, j+1), trừ trường hợp j = N.
- Truyền giá trị w(i,j)*a + s xuống ô bên dưới: w(i+1, j), trừ trường hợp i = N.
–
 Hình 5: Sắp xếp các phần tử mảng A và nạp trước dữ liệu vào các phần tử mảng W.Chú ý: Các phần tử của ma trận A được sắp xếp theo hình bình hành, thứ tự cột từ phải sang trái. Các ô trống được bù bằng giá trị 0 (không). Hình 5: Sắp xếp các phần tử mảng A và nạp trước dữ liệu vào các phần tử mảng W.Chú ý: Các phần tử của ma trận A được sắp xếp theo hình bình hành, thứ tự cột từ phải sang trái. Các ô trống được bù bằng giá trị 0 (không). |
Minh họa
Tiếp theo, xin mời anh/chị xem minh họa theo các thời điểm t=1, t=2, …
 Toàn bộ dữ liệu ma trận A tịnh tiến sang phải.Chú ý: phép nhân đầu tiên w11a11 (góc trái trên của MXU). Toàn bộ dữ liệu ma trận A tịnh tiến sang phải.Chú ý: phép nhân đầu tiên w11a11 (góc trái trên của MXU). |
 Toàn bộ dữ liệu ma trận A tiếp tục tịnh tiến sang phải.Chú ý: Phép nhân và cộng dồn ở các ô của MXU. Đồng thời quan sát việc truyền dữ liệu từ trái sang phải và từ trên xuống dưới. Toàn bộ dữ liệu ma trận A tiếp tục tịnh tiến sang phải.Chú ý: Phép nhân và cộng dồn ở các ô của MXU. Đồng thời quan sát việc truyền dữ liệu từ trái sang phải và từ trên xuống dưới. |
 Toàn bộ dữ liệu ma trận A tiếp tục tịnh tiến sang phải.Chú ý: Phép nhân và cộng dồn ở các ô của MXU. Đồng thời quan sát việc truyền dữ liệu từ trái sang phải và từ trên xuống dưới. Toàn bộ dữ liệu ma trận A tiếp tục tịnh tiến sang phải.Chú ý: Phép nhân và cộng dồn ở các ô của MXU. Đồng thời quan sát việc truyền dữ liệu từ trái sang phải và từ trên xuống dưới. |
 Chú ý: xuất hiện đầu ra đầu tiên: y11 của ma trận Y. Chú ý: xuất hiện đầu ra đầu tiên: y11 của ma trận Y. |
 Chú ý: xuất hiện thêm 2 phần tử y12 và y21 của ma trận Y (ngoài y11 ở thời điểm trước). Chú ý: xuất hiện thêm 2 phần tử y12 và y21 của ma trận Y (ngoài y11 ở thời điểm trước). |
 Chú ý: xuất hiện thêm 3 phần tử y13, y22 và y31 của ma trận Y. Chú ý: xuất hiện thêm 3 phần tử y13, y22 và y31 của ma trận Y. |
 Chú ý: xuất hiện thêm 3 phần tử 0, y23 và y32 của ma trận Y. Chú ý: xuất hiện thêm 3 phần tử 0, y23 và y32 của ma trận Y. |
 MXU hoàn tất phép nhân ma trận.Chú ý: Các phần tử của ma trận Y xếp theo hình bình hành, chuyển vị (transpose) trục hoành thành trục tung. MXU hoàn tất phép nhân ma trận.Chú ý: Các phần tử của ma trận Y xếp theo hình bình hành, chuyển vị (transpose) trục hoành thành trục tung. |
–
Ⓓ. Trải nghiệm so sánh CPU, GPU, TPU.
Phần này tôi xin giới thiệu với anh/chị cách thử và so sánh thời gian xử lý của CPU, GPU, TPU ngay trên chính PC/Laptop của anh/chị.
 Ý tưởng là trên cùng phép toán, chúng ta thử tính thời gian xử lý phép toán đó của CPU và thời gian xử lý cũng cùng phép toán đó của GPU, TPU. Tôi chọn 2 phép toán để so sánh:
Ý tưởng là trên cùng phép toán, chúng ta thử tính thời gian xử lý phép toán đó của CPU và thời gian xử lý cũng cùng phép toán đó của GPU, TPU. Tôi chọn 2 phép toán để so sánh:
- Phép toán 1: nhân 2 số vô hướng với nhau
- Phép toán 2: nhân 2 ma trận với nhau – mỗi ma trận có 10,000 dòng, 10,000 cột (là ma trận có 100 triệu số thực). Ma trận này được khởi tạo bởi một hàm ngẫu nhiên.
Công cụ mà tôi sử dụng là google colab notebook (đặt tên file là “CPU, GPU, TPU comparison.ipynb”). Trong file này tôi sử dụng ngôn ngữ lập trình Python trên nền framework PyTorch. Anh/chị nào có nhã ý tìm hiểu chi tiết xin mời anh/chị tham khảo phần Phụ lục.
▼ Giải thích ý tưởng
Tôi chia phần chương trình thành 3 đoạn: đoạn 1 do CPU xử lý, đoạn 2 do GPU xử lý và đoạn 3 do TPU xử lý. Tôi đánh số các Cell để anh/chị tiện theo dõi. Trong mỗi Cell, ngay dòng lệnh đầu tiên tôi sử dụng hàm %%timeit để đo thời gian xử lý của cả Cell. Anh/chị nào tò mò về lập trình của %%timeit xin tham khảo ở đây.
- Cell[1], Cell[2], Cell[3] do CPU xử lý.
- Cell[4], Cell[5], Cell[6], Cell[7] do GPU xử lý
- Cell[8], Cell[9], Cell[10] do TPU xử lý
–
CPU
Cell [1]: import framework PyTorch
Cell [2]: Đo thời gian xử lý nhân 2 số với nhau (thực chất là nhân 2 ma trận (1,1) với nhau). Thời gian CPU xử lý mất khoảng 6.4 micro giây.
Cell [3]: Đo thời gian xử lý nhân 2 ma trận (10000, 10000) với nhau. Thời gian CPU xử lý mất khoảng 29.1 giây (gần nửa phút).
–
GPU
Trước khi xử lý, chuyển sang chế độ chạy bằng GPU. Cách chuyển như sau:
- Click menu Runtime
- Chọn Change Runtime Type
- Chọn GPU
Cell[4]: import framework PyTorch
Cell[5]: chọn device là CUDA
Cell[6]: Đo thời gian xử lý nhân 2 số với nhau (thực chất là nhân 2 ma trận [1,1] với nhau). Thời gian GPU xử lý mất khoảng 60 micro giây (so với CPU chỉ mất 6.4 micro giây).
Cell[7]: Đo thời gian xử lý nhân 2 ma trận (10000, 10000) với nhau. Thời gian GPU xử lý mất khoảng 986 mili giây (chưa đầy 1 giây) so với CPU xử lý mất 29.1 giây.
–
TPU
Trước khi xử lý, chuyển sang chế độ chạy bằng TPU. Cách chuyển như sau:
- Click menu Runtime
- Chọn Change Runtime Type
- Chọn TPU
Cell[8]: import framework PyTorch
import torch_xla
import torch_xla.core.xla_model as xm
Cell[9]: Đo thời gian xử lý nhân 2 số với nhau (thực chất là nhân 2 ma trận [1,1] với nhau). Thời gian TPU xử lý mất khoảng 577 micro giây (so với CPU chỉ mất 6.4 micro giây).
Cell[10]: Đo thời gian xử lý nhân 2 ma trận (10000, 10000) với nhau. Thời gian TPU xử lý mất khoảng 615 micro giây (hơn 1 nửa mili giây) so với CPU xử lý mất 29.1 giây (gần nửa phút), GPU mất 986 mili giây. Tức là TPU nhanh hơn GPU 1,500 lần.
–
Có một điểm thú vị là TPU nhân 2 số với nhau (mất 577 micro giây) không khác nhiều so với nhân 2 ma trận (10000, 10000) với nhau (mất 615 micro giây)!
▲ Hết giải thích ý tưởng
–
Ⓔ.Suy ngẫm chậm 
- Xuất phát từ nhu cầu thực tế khi tìm kiếm bằng giọng nói (voice search), Google đã cho ra đời bộ tăng tốc (accelerator) TPU. Phiên bản đầu (TPUv1) chỉ để phục vụ khâu Inference trong Deep Learning. Các phiên bản sau (TPUv2, TPUv3, …) thì TPU phục vụ tất cả các khâu trong Deep Learning (Inference & Training). Cuối cùng, TPU được Google tích hợp vào điện toán đám mây Google Cloud Platform. Nghĩa là TPU tham gia vào tất cả các khâu tính toán trên điện toán đám mây của Google.
- Amazon cũng có bước đi tương tự. Năm 2019 họ cho ra đời Inferentia nhằm tăng tốc độ xử lý Inference của Deep Learning. Năm 2020 họ tích hợp thêm chip Trainium nhằm tăng tốc độ xử lý cho khâu Training. Khác với Google, Amazon không công bố thiết kế của Inferentia và Trainium.
- Chúng ta đang chứng kiến sự chuyển dịch từ GPU đa năng sang IC chuyên dụng (ASIC). Có một điểm khác biệt giữa GPU và IC chuyện dụng: các công ty sản xuất IC chuyên dụng không bán sản phẩm của họ ra thị trường. Không biết là các nhà cung cấp dịch vụ điện toán đám mây trong nước đã bỏ thời gian để khảo sát, cân nhắc xu hướng này chưa?
–
Cuối cùng, nhân dịp Giáng sinh, trân trọng gửi lời chúc Giáng sinh An lành đến tất cả các anh/chị trên diễn đàn ICT-VN!
Trân trọng & vui nhã

LeVanLoi
–
Ⓕ. Phụ lục: Nội dung file “CPU, GPU, TPU comparison.ipynb”
CPU
[1] import torch
—
[2] %%timeit
z = torch.randn(1,1)
result = torch.matmul(z,z)
del z, result
–
6.4 µs ± 157 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
—
[3] %%timeit
z = torch.randn(10000,10000)
result = torch.matmul(z,z)
del z, result
–
29.1 s ± 580 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
GPU
Trước khi xử lý, chuyển sang chế độ chạy bằng GPU. Cách chuyển như sau:
- Click menu Runtime
- Chọn Change Runtime Type
- Chọn GPU
[4] import torch
—
[5] device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
—
[6] %%timeit
z = torch.randn(1,1).to(device)
result = torch.matmul(z,z)
del z, result
–
The slowest run took 5.22 times longer than the fastest. This could mean that an intermediate result is being cached.
60 µs ± 51.4 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
—
[7] %%timeit
z = torch.randn(10000,10000).to(device)
result = torch.matmul(z,z)
del z, result
–
986 ms ± 194 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
–
TPU
Trước khi xử lý, chuyển sang chế độ chạy bằng TPU. Cách chuyển như sau:
- Click menu Runtime
- Chọn Change Runtime Type
- Chọn TPU
[8] import torch
import torch_xla
import torch_xla.core.xla_model as xm
[9] %%timeit
z = torch.randn(1,1, device=xm.xla_device())
result = torch.matmul(z,z)
del z, result
577 µs ± 83.5 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
[10] %%timeit
z = torch.randn(10000,10000, device=xm.xla_device())
result = torch.matmul(z,z)
del z, result
615 µs ± 64.1 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
Tác giả: Lê Văn Lợi
(nguyên Viện trưởng Viện tin học Doanh nghiệp – VCCI)