

Tác giả: Alex McFarland
Cập nhật ngày 30 tháng 12 năm 2024
Trí tuệ nhân tạo thông thường cho rằng việc xây dựng các mô hình ngôn ngữ lớn (LLMs) đòi hỏi nguồn vốn khổng lồ – thường lên đến hàng tỷ USD đầu tư. Tuy nhiên, DeepSeek, một startup AI từ Trung Quốc, vừa phá vỡ quan niệm đó với thành tựu mới nhất của họ: phát triển một mô hình AI đẳng cấp thế giới chỉ với 5,6 triệu USD.
Mô hình V3 của DeepSeek có thể cạnh tranh trực tiếp với các ông lớn trong ngành như Gemini của Google và những sản phẩm mới nhất của OpenAI, trong khi chỉ sử dụng một phần nhỏ tài nguyên tính toán thông thường. Thành tựu này đã thu hút sự chú ý của nhiều lãnh đạo trong ngành, và điều đặc biệt đáng chú ý là công ty đã đạt được điều này dù phải đối mặt với các hạn chế xuất khẩu từ Hoa Kỳ, khiến họ không thể tiếp cận các chip Nvidia hiện đại nhất.
Kinh tế học AI hiệu quả
Những con số đã kể một câu chuyện hấp dẫn về hiệu suất. Trong khi hầu hết các mô hình AI tiên tiến cần từ 16.000 đến 100.000 GPU để huấn luyện, DeepSeek chỉ sử dụng 2.048 GPU chạy trong 57 ngày. Quá trình huấn luyện của mô hình đã tiêu tốn 2,78 triệu giờ GPU trên các chip Nvidia H800 – một con số đáng kinh ngạc đối với một mô hình 671 tỷ tham số.
Để dễ hình dung, Meta cần khoảng 30,8 triệu giờ GPU – tức là gấp khoảng 11 lần công suất tính toán – để huấn luyện mô hình Llama 3, vốn thực tế có ít tham số hơn với 405 tỷ. Cách tiếp cận của DeepSeek giống như một bài học đỉnh cao về tối ưu hóa trong giới hạn. Làm việc với GPU H800 – các chip AI do Nvidia thiết kế đặc biệt cho thị trường Trung Quốc với khả năng bị giảm – công ty đã biến những giới hạn tiềm năng thành đổi mới. Thay vì sử dụng các giải pháp có sẵn để giao tiếp giữa các bộ xử lý, họ đã phát triển các giải pháp tùy chỉnh tối đa hóa hiệu quả.
Trong khi các đối thủ vẫn hoạt động dựa trên giả định rằng cần những khoản đầu tư khổng lồ, DeepSeek đang chứng minh rằng sự sáng tạo và tận dụng hiệu quả tài nguyên có thể cân bằng sân chơi.
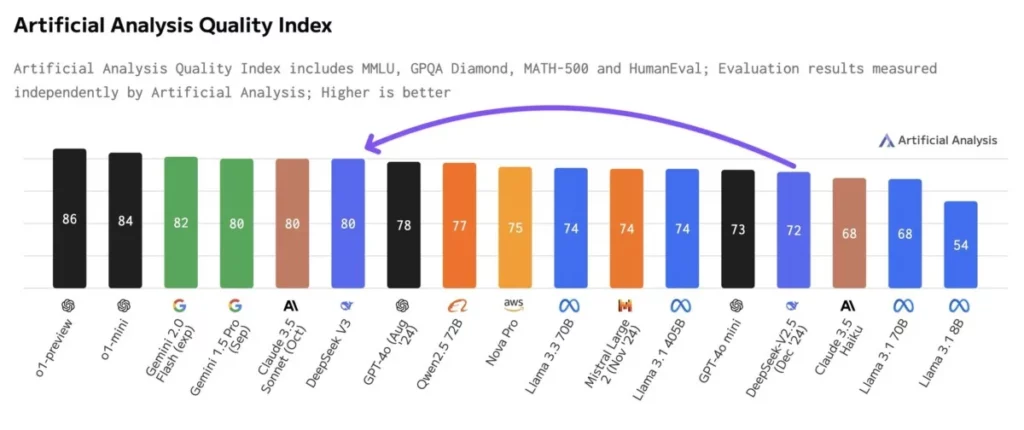
Kỹ thuật hoá điều không thể
Thành tựu của DeepSeek nằm trong phương pháp kỹ thuật sáng tạo của họ, chứng minh rằng đôi khi những đột phá quan trọng nhất đến từ việc làm việc trong các giới hạn thay vì đổ nguồn lực vô hạn vào một vấn đề.
Ở trung tâm của sự đổi mới này là một chiến lược gọi là “cân bằng tải không mất mất mát phụ trợ.” Hãy tưởng tượng nó giống như việc điều phối một hệ thống xử lý song song khổng lồ, nơi mà thông thường bạn sẽ cần những quy tắc phức tạp và hình phạt để giữ cho mọi thứ hoạt động trơn tru. DeepSeek đã lật ngược quan niệm truyền thống này, phát triển một hệ thống tự nhiên duy trì sự cân bằng mà không cần sự phức tạp của các phương pháp truyền thống.
Nhóm nghiên cứu cũng tiên phong trong một kỹ thuật mà họ gọi là “Dự đoán đa token” (Multi-Token Prediction – MTP) – một kỹ thuật cho phép mô hình suy nghĩ trước bằng cách dự đoán nhiều token cùng một lúc. Trong thực tế, điều này có nghĩa là tỷ lệ chấp nhận ấn tượng từ 85-90% đối với những dự đoán này trên các chủ đề khác nhau, mang lại tốc độ xử lý nhanh gấp 1,8 lần so với các phương pháp trước đây.
Kiến trúc kỹ thuật của mô hình thực sự là một tác phẩm mẫu mực của hiệu quả. V3 của DeepSeek sử dụng phương pháp “mixture-of-experts” với tổng số 671 tỷ tham số, nhưng đây là điểm thông minh – mỗi token chỉ kích hoạt 37 tỷ tham số. Việc kích hoạt chọn lọc này có nghĩa là họ có được lợi ích của một mô hình khổng lồ nhưng vẫn duy trì hiệu quả thực tế.
Lựa chọn khung huấn luyện chính xác FP8 hỗn hợp của họ là một bước tiến nữa. Thay vì chấp nhận các giới hạn truyền thống về độ chính xác giảm, họ phát triển các giải pháp tùy chỉnh giữ nguyên độ chính xác trong khi giảm mạnh yêu cầu về bộ nhớ và tính toán.
Tác động lan tỏa trong hệ sinh thái AI
Tác động từ thành tựu của DeepSeek lan tỏa xa hơn rất nhiều so với một mô hình thành công duy nhất.
Đối với phát triển AI ở châu Âu, đột phá này đặc biệt quan trọng. Nhiều mô hình tiên tiến không thể vào EU vì các công ty như Meta và OpenAI không thể hoặc không muốn thích ứng với Đạo luật AI của EU. Cách tiếp cận của DeepSeek chứng minh rằng việc xây dựng AI tiên tiến không nhất thiết phải sử dụng các cụm GPU khổng lồ – mà chủ yếu là về việc tận dụng các tài nguyên sẵn có một cách hiệu quả.
Phát triển này cũng cho thấy cách mà các hạn chế xuất khẩu có thể thực sự thúc đẩy sự đổi mới. Việc DeepSeek không thể tiếp cận phần cứng cao cấp đã buộc họ phải suy nghĩ khác đi, dẫn đến những tối ưu phần mềm có thể chưa bao giờ xuất hiện trong một môi trường giàu tài nguyên. Nguyên tắc này có thể thay đổi cách chúng ta tiếp cận phát triển AI trên toàn cầu.
Tác động đến sự phổ biến AI là rất sâu sắc. Trong khi các ông lớn ngành công nghiệp tiếp tục đốt cháy hàng tỷ USD, DeepSeek đã tạo ra một mô hình phát triển AI hiệu quả và tiết kiệm chi phí. Điều này có thể mở ra cơ hội cho các công ty nhỏ hơn và các tổ chức nghiên cứu trước đây không thể cạnh tranh vì hạn chế tài nguyên.
Tuy nhiên, điều này không có nghĩa là cơ sở hạ tầng tính toán quy mô lớn sẽ trở nên lỗi thời. Ngành công nghiệp đang chuyển trọng tâm vào việc mở rộng thời gian suy luận – thời gian mà một mô hình mất để tạo ra câu trả lời. Khi xu hướng này tiếp tục, các tài nguyên tính toán lớn vẫn sẽ cần thiết, và có lẽ là ngày càng nhiều hơn theo thời gian.
Nhưng DeepSeek đã thay đổi căn bản cuộc trò chuyện. Tác động dài hạn là rõ ràng: chúng ta đang bước vào một kỷ nguyên mà suy nghĩ sáng tạo và sử dụng tài nguyên hiệu quả có thể quan trọng hơn sức mạnh tính toán thuần túy. Đối với cộng đồng AI, điều này có nghĩa là tập trung không chỉ vào những tài nguyên chúng ta có, mà là cách sáng tạo và hiệu quả chúng ta sử dụng chúng.