Để giúp anh/chị quyết định có đọc tiếp hay không, tôi xin phép cung cấp các thông tin liên quan đến bài post này như sau:
· Chủ đề: Machine Learning · Tính thời sự: tháng 05/2026 · Thời gian đọc: 10 phút để đọc ý chính, 15 phút để đọc thêm lý giải nguyên lý kỹ thuật
Đề dẫn
Báo chí và mạng xã hội đang tràn ngập các bài viết về Agent/Agentic AI. Bài này cũng dài (xin cảnh báo trước với anh/chị thế) nhưng tôi chỉ tập trung vào các mốc tiến hóa của Agent từ năm 2023 đến nay (điểm đột phá, bước ngoặt). Do trên diễn đàn toàn là người làm về khoa học – công nghệ nên nhiều chỗ trong bài viết tôi đi sâu vào lý giải nguyên lý kỹ thuật đứng đằng sau. Nếu anh/chị thấy “nhức đầu” thì vui lòng bỏ qua các phần đó.
–
Tôi thấy nhiều tài liệu dịch từ “Agent” là “Tác tử” hoặc “Tác nhân”. Trong khuôn khổ bài nhàn đàm này, xin phép anh/chị dùng luôn từ tiếng Anh là “Agent”. Cùng gốc với từ “Agent” trong tiếng Anh có từ “Agency” – có thể dịch là “đại lý”. Đại lý của một doanh nghiệp nào đấy là đơn vị đứng ra thay mặt doanh nghiệp tương tác với khách hàng, thế giới bên ngoài tại điểm đặt đại lý.
Ngoài từ “Agent”, theo khuyến cáo của nhiều nguồn, trong bài viết tôi sử dụng một số từ tiếng Anh sau:
Memory: Bộ nhớ
Framework: Khung phát triển
Orchestration: Điều phối
Observability: Khả năng quan sát. Để có khả năng quan sát, LLM cần đến khả năng lưu ký (logging), lưu vết (tracing) và đo lường (metrics).
Workflow: Luồng xử lý
Retrieval: Truy xuất dữ liệu
–
❶. Agent hoạt động như thế nào?
Cuối năm 2022, đầu năm 2023, LLM (Large Language Model) hoạt động đơn giản theo nguyên tắc sau:
[Prompt] → {LLM} → [Response]
Nghĩa là LLM “ngồi đó” chờ chúng ta chất vấn [Prompt] và LLM giải đáp chất vấn [Response].
–
Dần dần LLM tiến hóa thành LLM Agent. Một cách cô đọng:
Nghĩa là, bây giờ LLM, sau khi nhận được câu lệnh [Instruction], thay vì trả lời bằng một văn bản thuần túy, LLM lập một chu kỳ vòng lặp (iteration) n lần gồm: nhận thức (Perception), lập luận (Reasoning) và hành động (Action). Sau khi kết thúc vòng lặp, lúc đó LLM mới cho ra “báo cáo kết quả” [Report result].
–
Ví dụ:
Đầu vào (Input): “Nghiên cứu giá cổ phiếu hiện tại của Apple và gửi email tóm tắt cho sếp của tôi”.
Suy nghĩ (Thought): Agent tự tư duy và lập kế hoạch: “Mình cần tìm giá cổ phiếu trước. Mình nên sử dụng công cụ Tìm kiếm Google.”
Hành động (Action): Agent tạo ra một lệnh để sử dụng công cụ tìm kiếm.
Quan sát (Observation): Công cụ trả về giá cổ phiếu ($215.30). Agent quan sát và “đọc” kết quả này.
Điều chỉnh (Refinement): Agent cập nhật kế hoạch tiếp theo: “Bây giờ đã có giá, mình cần soạn bản thảo email.”
Hoàn tất (Completion): Agent thực hiện hành động cuối cùng (gửi email) và thông báo cho người dùng rằng công việc đã hoàn tất.
Kiến trúc cốt lõi
Hãy tưởng tượng Agent giống như một trợ lý chuyên nghiệp. Agent không chỉ cần “bộ não” để tư duy mà còn cần các công cụ, bộ nhớ và một bản kế hoạch:
Thành phần
Phép ẩn dụ
Mô tả
Agent Core (Bộ não)
Trợ lý
Chính là LLM (như GPT-4o, Claude 3.5). Nó diễn giải các chỉ dẫn và quyết định nên làm gì tiếp theo.
Planning (Lập kế hoạch)
Danh mục việc cần làm
Khả năng chia nhỏ một mục tiêu phức tạp thành các tác vụ nhỏ (sub-tasks) có thể quản lý được.
Memory (Bộ nhớ)
Tủ hồ sơ
Lưu trữ các tương tác và thông tin trong quá khứ để Agent không “quên” những gì nó đã làm ở các bước trước.
Tools (Công cụ)
Thiết bị làm việc
Các API bên ngoài, calculator, trình duyệt web, … mà Agent có thể “gọi” để hoàn thành công việc.
Tóm tắt: Agent là một hệ thống dùng LLM để suy luận, đưa ra quyết định và hành động theo vòng lặp, kết hợp với công cụ và bộ nhớ để hoàn thành mục tiêu.
❷. Các mốc tiến hóa của Agent từ năm 2023 đến nay
Nếu anh/chị đã từng sử dụng ChatGPT vào đầu năm 2023, nhớ lại các trải nghiệm vào thời điểm đó và so sánh với các trải nghiệm vào thời điểm hiện nay (tháng 5/2026) thì quả là “một trời một vực”. Phần này tôi muốn cùng anh/chị điểm lại các mốc tiến hóa của Agent, chúng đồng thời cũng là các mốc tiến hóa của LLM.
2023 – Sự ra đời của kỷ nguyên Agentic AI hiện đại
Chúng ta biết rằng chức năng ban đầu của LLM là tạo sinh văn bản: từ prompt nó tạo sinh ra một chuỗi các “từ” (word). Chuỗi này có quy tắc rất đơn giản: từ tiếp theo là “dự đoán” của chuỗi các từ trước đó. Kết quả đầu ra là một chuỗi văn bản. Câu hỏi đặt ra cho cộng đồng nghiên cứu là: Làm thế nào để biến cái tạo sinh này thành một thứ biết “suy nghĩ”, “lập luận”, “hành động”? Một câu hỏi khó, đúng không nhỉ?
1. Ngay từ đầu năm 2022, người ta phát hiện ra rằng nếu yêu cầu nó (LLM) “Let’s think step by step” (suy nghĩ từng bước) – thông qua thiết kế prompt – thì nó thực hiện tốt hơn nhiều đối với các vấn đề logic, toán, khoa học thường thức (chain-of-thought). Bằng cách đơn giản đó, người ta kích hoạt LLM tự chia nhỏ vấn đề lớn thành chuỗi các vấn đề con. [Trong nghiên cứu khoa học, người ta vẫn hay gặp hiện tượng “serendipity”: phát minh được thực hiện một cách tình cờ hơn là cố ý. Có lẽ ý tưởng chain-of-thought cũng là hiện tượng “serendipity”?!]
Một cách cô đọng: Chain-of-Thought: [Đầu vào] → {Bước 1} → {Bước 2} → … {Bước n} → [Kết quả]
Đối với các vấn đề con trong các bước [1→n], LLM tự lấy tri thức của chính nó để giải quyết vấn đề. Tức là tri thức nội tại của LLM chứ không phải tri thức ngoài. Ý tưởng then chốt của ReAct rất đơn giản: nếu LLM có thể suy luận từng bước, thì có lẽ nó cũng có thể đưa ra hành động từng bước một?!
Cuối năm 2022 (tháng 10/2022), nhóm nghiên cứu của Google đăng bài ReAct (Reasoning + Acting), biến chuỗi “các bước” trong chain-of-thought thành chuỗi (Lập luận, Hành động, Quan sát).
Một cách cô đọng:
ReAct: [Đầu vào] → {Lập luận, Hành động, Quan sát} → {Lập luận, Hành động, Quan sát} → … → {Lập luận, Hành động, Quan sát} → [Kết quả]
Cái đặc biệt ở đây: “Hành động” là lấy tri thức ở ngoài LLM. Ví dụ lấy dữ liệu trên Wikipedia, sử dụng “Search Engine” để tìm kiếm thông tin trên Web, hoặc chạy một đoạn mã lập trình để xử lý một tính toán phức hợp. Bằng cách này, LLM không chỉ biết sử dụng tri thức nội tại của chính nó mà còn biết sử dụng tri thức ngoài. (Trong chain-of-thought, LLM chỉ sử dụng kiến thức nội tại của chính nó.)
2. Tuy nhiên, để LLM có được chuỗi “Lập luận” tương ứng với “Hành động”, người ta vẫn phải Fine-Tuning. Nghĩa là con người vẫn cần gắn nhãn để LLM biết bắt chước “Lập luận” nào tương ứng với “Hành động” gì:
“Lập luận 1” → “Hành động 1”,
“Lập luận 2” → “Hành động 2”
Đầu năm 2023 (tháng 2/2023), nhóm nghiên cứu Meta đăng bài Toolformer. Ý tưởng cốt lõi của Toolformer là cho phép LLM tự học (self-supervised learning) cách sử dụng các công cụ—chẳng hạn như lúc nào thì gọi search engine, lúc nào thì dùng calculator, lúc nào thì gọi API, … thay vì dựa vào dữ liệu dán nhãn. Tức là LLM tự biết rằng với “Lập luận x” sẽ phải sử dụng “Hành động y”.
Từ 2 bài báo trên, LLM từ chỗ chỉ biết tạo sinh, bây giờ nó còn biết suy nghĩ, hành động. Điều đó chứng tỏ rằng LLM theo mô hình GPT được xây dựng trên nền Transformer còn nhiều bí ẩn chưa khai thác hết!? Đây là điểm mà những nhà nghiên cứu lạc quan có thể hy vọng mô hình GPT một ngày nào đó sẽ dẫn tới AGI (Artificial General Intelligence).
❰/Tiếm đàm❱
► Cộng đồng nghiên cứu đã nhanh chóng thống nhất về mô hình ReAct:
Lập luận → Hành động → Quan sát → Lập luận → …
✪ Function calling
Một bước đột phá kỹ thuật quan trọng nữa là tính năng function calling của OpenAI, cho phép LLM gọi API và công cụ theo định dạng có cấu trúc [nguồn].
Ý tưởng chính của function calling là cho phép LLM tương tác với hệ thống ngoài. Trái với tên gọi, LLM không tự thực thi mã lệnh. Thay vào đó, nó phát hiện khi nào cần một công cụ, trích xuất thông tin cần thiết từ Prompt, cung cấp tham số chính xác cần thiết để gọi hàm (chạy đoạn mã đó) trong môi trường của người dùng.
1. Define Tools: Người dùng cung cấp cho mô hình một danh sách các chức năng có sẵn. Mỗi chức năng được mô tả bằng lược đồ JSON bao gồm tên hàm, mô tả về những gì hàm sẽ thực hiện và các tham số của hàm.
2. Suy luận của mô hình: Khi người dùng đặt câu hỏi (ví dụ: “Thời tiết ở Hà Nội như thế nào?”), mô hình sẽ so sánh câu hỏi đó với mô tả công cụ (Define Tools).
3. Lệnh gọi công cụ: Nếu mô hình quyết định cần một công cụ nào đó, nó sẽ ngừng tạo sinh văn bản thông thường. Thay vào đó, nó trả về một lệnh gọi công cụ (hàm) — một đối tượng JSON chứa tên hàm và các tham số được trích xuất (ví dụ: {“location”: “HaNoi”}).
4. Local Execution: Ứng dụng trên máy người dùng nhận JSON này, phân tích cú pháp và thực thi hàm (ví dụ: gọi API thời tiết hoặc truy vấn cơ sở dữ liệu).
5. Tổng hợp cuối cùng: Ứng dụng trên máy người dùng gửi kết quả của hàm đó trở lại mô hình. Mô hình sau đó sử dụng dữ liệu thực tế đó để tạo ra phản hồi bằng ngôn ngữ tự nhiên cho người dùng.
Lợi ích của function calling mang lại:
· Đầu ra dữ liệu có cấu trúc: Chức năng này buộc mô hình phải xuất ra JSON hợp lệ phù hợp với lược đồ cụ thể của người dùng, điều này rất cần thiết cho việc tự động hóa đáng tin cậy. · Thông tin thời gian thực: Cho phép các mô hình truy cập dữ liệu vượt quá thời gian huấn luyện ban đầu (cutoff), chẳng hạn như giá cổ phiếu hiện tại hoặc hồ sơ nội bộ của công ty. · Khả năng thực hiện hành động: Điều này biến LLM từ một “trợ lý biết nói” thành một Agent có khả năng thực hiện các hành động, chẳng hạn như đặt vé máy bay hoặc gửi email.
✪ ChatGPT code interpreter
Một đột phá khác trong khoảng thời gian tháng 7/2023, cũng rất quan trọng, là “ChatGPT code interpreter” của OpenAI. ChatGPT code interpreter hoạt động bằng cách nhúng phần mềm thông dịch ngôn ngữ Python vào bên trong ChatGPT. Khi người dùng cung cấp một Prompt hoặc file, ChatGPT sẽ viết mã Python để giải quyết tác vụ, chạy ngầm mã đó và trả về kết quả dưới dạng số, dưới dạng hình ảnh trực quan hoặc dưới dạng file, thả trực tiếp vào cuộc hội thoại của người dùng.
Công cụ này hoạt động thông qua một vòng lặp logic liên tục, từng bước một:
1. Instruction & Translation: Người dùng đưa ra một yêu cầu cho ChatGPT (ví dụ: “Phân tích tệp CSV này và tạo biểu đồ hiển thị doanh số bán hàng hàng tháng”). 2. Tạo mã: Chatbot đóng vai trò như một lập trình viên, viết mã Python để thực hiện yêu cầu của người dùng. 3. Execution: Môi trường Python chạy đoạn mã. Người dùng có thể nhấp vào menu thả xuống “Show work” để xem chính xác mã đang được chạy trong thời gian thực. 4. Iterative Refinement: Nếu mã lệnh báo lỗi hoặc kết quả đầu ra không chính xác, ChatGPT sẽ tự động đọc thông báo lỗi, viết lại mã và thử lại cho đến khi thành công. 5. Kết quả cuối cùng: Kết quả được hiển thị dưới dạng văn bản, dưới dạng hình ảnh tương tác hoặc ảnh tĩnh (như biểu đồ hoặc đồ thị), hoặc file có thể tải xuống.
Nhờ tính năng đặc biệt này nên ChatGPT vượt ra ngoài khuôn khổ tạo sinh văn bản thông thường:
· Phân tích và trực quan hóa dữ liệu: Người dùng có thể tải lên các file dữ liệu (CSV, Excel, JSON) để nó làm sạch, xử lý và lập biểu đồ. · Chuyển đổi file: Dễ dàng chuyển đổi các loại file, chẳng hạn như chuyển đổi PNG thành JPG, nén video hoặc thay đổi kích thước hình ảnh. · Toán học & Logic: Giải quyết các phương trình phức tạp, tính toán số liệu thống kê và mô hình hóa thuật toán một cách hoàn hảo mà không có những “ảo giác” thường thấy ở các LLM “truyền thống”. · Code Debugging: Tải lên các đoạn mã bị lỗi của bạn và yêu cầu ChatGPT tìm lỗi, chạy chúng trong môi trường giả lập và cung cấp file đã sửa để tải xuống.
Các hệ thống này đưa ra nhiều ý tưởng sau này đã trở thành cốt lõi của Agent:
Chia nhỏ mục tiêu (goal decomposition)
Lập kế hoạch một cách đệ quy
Sử dụng công cụ
Bộ nhớ dài hạn
Tự tạo prompt
Thực thi nhiều bước
✪ Cuối 2023: Xuất hiện hệ thống Multi-Agent
Microsoft giới thiệu AutoGen — kiến trúc nhiều Agent phối hợp với nhau.
Thay vì một LLM Agent làm tất cả, hệ thống có thể phối hợp:
Agent lập kế hoạch
Agent nghiên cứu
Agent phản biện (Critic)
Agent thực thi
Ý tưởng này về sau trở thành nền tảng cho điều phối Agent cấp doanh nghiệp.
Nói đến Multi-Agent (đa tác nhân), có một bài báo rất đáng chú ý do Đại học Standford kết hợp với Google đăng vào tháng 4/2023: “Generative Agents: Interactive Simulacra of Human Behavior”: một thị trấn ảo gồm 25 Agent tương tác tự trị. Tư tưởng chủ đạo của công trình nghiên cứu này là sự kết hợp giữa LLM và kiến trúc quản lý bộ nhớ, hoạch định chuyên biệt nhằm xây dựng các Agent có khả năng tái hiện hành vi nhân bản một cách chân thực.
· Ký ức của Agent (Memory Stream): Một kiến trúc lưu trữ toàn bộ nhật ký trải nghiệm của Agent bằng ngôn ngữ tự nhiên. Nó đánh giá các “ký ức” dựa trên tính gần đây (recency), tầm quan trọng và mức độ liên quan. · Phản tư (Reflection): Khả năng tổng hợp định kỳ những trải nghiệm trong quá khứ và rút ra những kết luận ở cấp độ cao hơn (ví dụ: hình thành quan điểm hoặc nhận thức về mục tiêu dài hạn) thay vì chỉ đơn thuần nhớ lại các sự kiện một cách thô sơ. · Lập kế hoạch (Planning): Chuyển hóa những “ký ức” và “suy ngẫm” này thành các kế hoạch hàng ngày một cách có cấu trúc, chi tiết đến từng giờ, định hướng hành động và hành vi của Agent.
Thông qua việc tương tác trong một môi trường giả lập (sandbox) giống như một thị trấn nhỏ, các Agent có thể nảy sinh những tương tác xã hội tự nhiên – như mở tiệc, truyền tai nhau tin tức và kết bạn -hoàn toàn tự động mà không cần con người nhúng tay vào.
[Phản tư: quá trình tự quan sát, suy ngẫm, và đánh giá sâu sắc về suy nghĩ, hành động, cảm xúc và trải nghiệm của bản thân nhằm hiểu rõ hơn về mình và thúc đẩy sự phát triển, cải thiện trong tương lai]
Một trong những hạn chế vào thời điểm năm 2023 là vấn đề “vòng lặp” (loop): các Agent dễ rơi vào “vòng lặp vô tận” và tỷ lệ ảo giác (hallucination) cao. Vào thời điểm đó, chúng giỏi việc lập kế hoạch hơn là thực sự thực thi. Tức là chúng chỉ biết vẽ ra luồng điều khiển nhưng chưa biết làm thế nào để thực thi luồng điều khiển đó.
Đánh giá chung: Mặc dù mang tính cách mạng, vào thời điểm năm 2023 Agent mới chỉ ở mức thử nghiệm, trong môi trường giả lập, mới chỉ là “đồ chơi” chứ chưa đi vào triển khai thực tế được.
2024 — Từ thử nghiệm sang kỹ nghệ (engineering)
✪ Thời kỳ bùng nổ của RAG và Agentic RAG:
RAG (Retrieval-Augmented Generation): cho phép LLM trích xuất thông tin ngoài (nằm ngoài tri thức nội tại của LLM). RAG thực hiện bằng 2 pha: Pha 1: trích xuất thông tin ngoài; Pha 2: trộn thông tin truy xuất với Prompt sau đó tạo sinh kết quả.
RAG tiến hóa thành “Agentic RAG”: Thay vì chỉ trích xuất thông tin 1 lần, nó tự thiết lập một vòng lặp: (trích xuất thông tin, đánh giá thông tin). Nó có thể dùng nhiều phương thức trích xuất thông tin như search web, cơ sở dữ liệu vector, API, calculator. Nếu nó chưa tìm thấy thông tin cần tìm nó tự điều chỉnh tham số và lặp lại quy trình.
✪ Agent đa phương thức (multimodal)
GPT-4o (tháng 5/2024) và các mô hình đa phương thức khác đã mở rộng đáng kể năng lực của Agent. Agent giờ đây có thể:
✪ Tính năng “Computer Use” (10/2024) của Anthropic ra đời, một cuộc cách mạng về Agent
“Computer Use” là Agent tự trị (Autonomous Agent), không cần sự can thiệp của con người. Chúng ta hình dung “Computer Use” giống hệt như người ngồi trước màn hình máy tính với bàn phím và chuột. “Computer Use” đọc hiểu màn hình, biết đâu là nút nhấn (button), đâu là menu, đâu là ô nhập dữ liệu, … giống hệt như chúng ta quan sát màn hình vậy.
· Nhìn & Chụp ảnh màn hình: “Computer Use” định kỳ chụp ảnh màn hình: một ảnh tức thời (screenshot) của “giao diện đồ họa”.
· Điều khiển con trỏ: “Computer Use” có thể tạo ra các lệnh để di chuyển chuột, kéo thả và nhấp chuột vào các tọa độ hoặc phần tử nào đó trên giao diện.
· Nhập liệu bằng bàn phím: “Computer Use” có thể nhập văn bản, điền vào biểu mẫu và thực hiện các phím tắt để điều hướng hoặc chỉnh sửa.
✪ Tháng 11/2024: MCP thay đổi toàn bộ hệ sinh thái
OpenAI đã tiên phong trong lĩnh vực “Deep Thinking” (tư duy sâu với việc ra mắt dòng “o1” từ tháng 9/2024. Đây là những mô hình đầu tiên được thiết kế để thực hiện “agentic reasoning workflows” (luồng suy luận Agent) bằng cách tiền xử lý trước khi cho ra kết quả cuối cùng.
Sau OpenAI là DeepSeek với việc ra mắt dòng “DeepSeek-R1”. Tiếp đó là Google với mô hình “Gemini Deep Think”. Anthropic tích hợp “Thinking Tokens” vào các mô hình của họ.
Deep Thinking (thường được gọi là “Reasoning” hoặc “Thinking Mode”) trong LLM là quá trình để nó tạo ra một chuỗi suy luận từng bước nội tại — giống như sử dụng giấy nháp — trước khi đưa ra câu trả lời cuối cùng.
1. Cơ chế cốt lõi: Suy nghĩ thành lời: Theo truyền thống, mô hình LLM tạo ra câu trả lời cuối cùng ngay lập tức, tức là phương pháp “bản nháp đầu tiên cũng là bản cuối cùng”. Ngược lại, các mô hình Deep Thinking dành thời gian inference để “suy nghĩ”. Chúng tạo ra một đoạn độc thoại nội tâm bao gồm các “mã lập luận” ẩn hoặc riêng biệt, phác thảo vấn đề, đưa ra các phương pháp tiếp cận và tự điều chỉnh trong quá trình thực hiện.
2. Reinforcement Learning: Các mô hình này không chỉ được “khuyến khích” suy luận; chúng được huấn luyện bài bản bằng cách sử dụng phương pháp Reinforcement Learning chuyên biệt. Thay vì chỉ tối ưu hóa cho luồng hội thoại, mô hình được nhận phần thưởng (Reward) trong quá trình huấn luyện khi nó hoàn thành công trong việc:
· Phân tích các vấn đề phức tạp thành các phần nhỏ hơn, dễ giải quyết.
· Phê bình và loại bỏ các hướng suy luận sai.
· Khám phá các giải pháp thay thế trước khi đưa ra câu trả lời cuối cùng.
3. Test-time Compute: Không giống như quá trình tạo sinh thông thường tuân theo trình tự tuyến tính, Deep Thinking sử dụng khả năng tính toán biến đổi trong quá trình kiểm tra. LLM dành nhiều tài nguyên tính toán hơn —thường tạo ra số lượng token gấp 10 đến 20 lần so với bình thường—để kiểm tra kỹ lưỡng một câu hỏi trước khi đưa ra câu trả lời cuối cùng.
Cơ chế này giúp Agent vượt qua những giới hạn của việc tạo sinh thông thường:
· Giảm Hallucination (ảo giác): Mô hình kiểm tra logic của chính nó bằng toán học, phát hiện lỗi trước khi chúng hiển thị kết quả cuối cùng. · Xử lý logic đa bước: Nó hoạt động tốt trên lý luận phức tạp, toán học cao cấp và gỡ lỗi.
✪ OpenAI xây dựng hệ sinh thái Agent
Tháng 3/2025: OpenAI ra mắt Agents SDK cùng với Responses API, cung cấp cho developers các thành phần cơ bản để xây dựng Agent.
Tháng 10/2025: OpenAI giới thiệu AgentKit, bổ sung các tính năng nâng cao để giúp xây dựng các Agent “Deep Research” (nghiên cứu sâu) và Agent “Customer Support” (hỗ trợ khách hàng) đáng tin cậy hơn.
Mô hình kiến trúc Agent dần rõ ràng hơn:
Suy luận bằng LLM
Chọn công cụ
Vòng lặp thực thi
Memory / state (bộ nhớ / trạng thái)
Kiểm chứng kết quả
Có con người giám sát
✪ Kỷ nguyên CLI: Agent tự lập trình
Có thể nói sự ra đời của Claude Code (Anthropic) vào tháng 5/2025 (preview tháng 2/2025) là điểm khởi đầu cho kỷ nguyên “Agent tự lập trình” (Code Agent). Ý tưởng mang tính cách mạng của Claude Code là đưa LLM Agent vào nằm ngay trong terminal hoặc IDE của người lập trình. Thay vì chỉ trả lời câu hỏi trên trình duyệt, Agent giờ đây đọc toàn bộ mã nguồn trên máy, chạy các công cụ phát triển (development tools) ngay trên máy, chỉnh sửa file và tự động chạy các bước cần thiết để hoàn thành các tác vụ của “Prompt”. Đại ý: thay vì người lập trình gõ từng dòng lệnh, lưu lên file hay chạy thử, … thì bây giờ người lập trình chỉ nói cần làm gì (Prompt) bằng ngôn ngữ tự nhiên là Agent tự hiểu ý rồi tự đọc file, tự gõ lệnh, chạy linter, tự lưu file, chạy thử, kiểm lỗi, tự debug, … cho đến khi hoàn thành.
Cùng ý tưởng, chúng ta phải nói đến Codex (tháng 5/2025) của OpenAI. Thật ra, Codex phiên bản đầu ra đời từ rất sớm: năm 2021 nhưng lúc đó Codex chỉ là một plug-in vào VS Code.
Đến tháng 6, cùng ý tưởng, Google cho ra đời Gemini CLI (open source).
Ngoài 3 “ông lớn” trên, rất nhiều giải pháp tương tự ra đời. Có thể kể đến một vài ví dụ như Cline (open source), Aider (open source), GitHub Copilot, Cursor, Replit, Windsurf, Amazon Q Developer, Continue.dev.
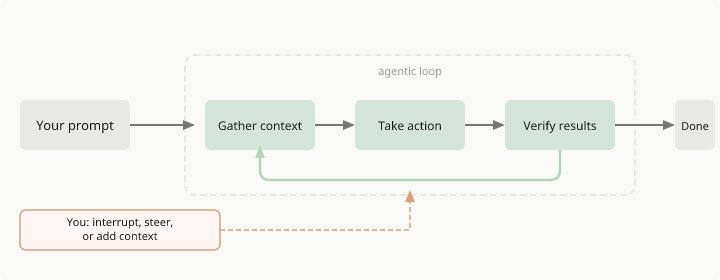
Nguyên lý hoạt động của Claude Code? (Xem hình minh họa ở dưới) [Nguồn]
Khi giao việc cho Claude bằng lời (Prompt), nó sẽ thực hiện qua 3 pha: thu thập context (ngữ cảnh), triển khai hành động và xác thực kết quả. Các pha này đan xen linh hoạt với nhau. Claude sử dụng các công cụ xuyên suốt quá trình này—dù là tìm kiếm file để hiểu mã nguồn, chỉnh sửa để thực hiện thay đổi, hay chạy các bài test để kiểm tra lại công việc.
Ở cấp độ tổng quan, Claude Code hoạt động như một vòng lặp:
1. Giao việc cho nó bằng ngôn ngữ tự nhiên (Prompt). 2. Nó xây dựng context (ngữ cảnh) từ Project (nằm trên máy). 3. Mô hình quyết định hành động cần thực hiện. 4. Công cụ thực thi hành động đó là cục bộ (ngay trên máy). 5. Kết quả được đưa trở lại mô hình. 6. Lặp lại cho đến khi tác vụ hoàn thành.
Cấu trúc cốt lõi khá giống với vòng lặp giả lập sau (đối với anh/chị biết lập trình):
if response requests tool: execute_tool() return_result_to_model() else: show_answer_to_user() break
Chú ý rằng lập trình viên (người) cũng là một phần của vòng lặp này (xem hình minh họa). Họ có thể can thiệp bất cứ lúc nào để hướng Claude theo một hướng khác, cung cấp thêm context (ngữ cảnh) hoặc yêu cầu nó thử một cách tiếp cận khác. Claude Code hoạt động tự chủ nhưng vẫn phản hồi lại đầu vào của con người.
✪ Tích hợp Agent vào hệ điều hành và bộ duyệt
· Giữa năm 2025: Microsoft & Apple tích hợp Agent vào hệ điều hành: Agent có quyền đọc email, lên lịch họp và điều chỉnh cài đặt hệ thống mà không cần hướng dẫn từng bước rõ ràng từ người dùng. · Giữa năm 2025: Các bộ duyệt (Browser) bắt đầu tích hợp Agent: Microsoft Edge tích hợp Copilot, Google Chrome tích hợp “AI Mode”, Apple Safari tích hợp “Apple Intelligence”.
Nếu MCP tập trung vào kết nối công cụ, thì A2A tập trung vào giao tiếp giữa các Agent: Mạng lưới các Agent phối hợp với nhau.
Đánh giá chung năm 2025: Agent được “chuẩn hóa” và “tích hợp”.
2026 (Hiện tại) – Digital Coworker
✪ Tính năng “Computer Use” đã trưởng thành
Các Agent giờ đây có thể “nhìn” màn hình máy tính, di chuyển con trỏ và tương tác với các phần mềm cũ không có API, giống hệt như một nhân viên thực thụ.
✪ Agent chủ động
Các hệ thống đã chuyển từ phản ứng (chờ lệnh) sang chủ động. Trong logistics, Agent giờ đây có thể phát hiện lỗi (như đơn hàng bị chậm) và tự giải quyết (hoàn tiền cho khách, điều hướng lại đơn hàng) trước khi con người kịp báo cáo.
✪ Agent được phổ cập, “bình dân hóa”
Các mô hình nguồn mở như GLM-5.1 và Falcon-H1R đã đạt hoặc vượt qua các ông lớn độc quyền trong các bài kiểm tra suy luận, cho phép doanh nghiệp vận hành các Agent hiệu suất cao ngay tại máy chủ nội bộ để bảo mật dữ liệu tuyệt đối.
✪ Xuất hiện “Hệ điều hành Agent”
Khái niệm HĐH Agent:
Hệ điều hành Agent (Agent Operating System – AOS) là một hạ tầng phần mềm quản lý nhiều Agent tự trị (User ở đây là Agent chứ không phải là con người). Nó đóng vai trò như một “Kernel” tập trung xử lý việc lập lịch tác vụ, quản lý Context (ngữ cảnh), phân bổ Tools (công cụ) và Memory (bộ nhớ), cho phép các Agent làm việc cùng nhau một cách an toàn và đáng tin cậy trên quy mô lớn.
Tại sao lại cần AOS?
Các hệ điều hành truyền thống (như Windows hay Linux) được xây dựng cho con người sử dụng file và thư mục, trong khi các Agent được thiết kế để thực hiện các tác vụ phức tạp, nhiều bước trên nhiều phần mềm khác nhau. Nếu không có một hệ thống tổng thể, các Agent sẽ gặp khó khăn trong việc chia sẻ ngữ cảnh (context), dẫn đến “lệch hướng nhận thức” hoặc tiêu thụ Memory (bộ nhớ) không hiệu quả. Một hệ điều hành Agent (AOS) cung cấp những điều sau:
· Quản lý Context và Memory: Hoạt động như RAM và ổ cứng cho Agent, đảm bảo các Agent “ghi nhớ” các tác vụ đã thực hiện mà không vượt quá giới hạn token của chúng. · Điều phối: Lên lịch cho Agent nào nhận nhiệm vụ nào và phối hợp việc chuyển giao công việc liền mạch giữa chúng (ví dụ: chuyển một khách hàng tiềm năng đủ điều kiện từ Agent Research sang Agent tiếp cận khách hàng). · Tool Resolution: Quản lý các Skill và API bên ngoài — coi Tools như System Calls mà các Agent có thể sử dụng một cách an toàn mà không làm sập hệ thống cốt lõi. · Trust, Safety, & Guardrails: Thiết lập các giới hạn quyền hạn để các Agent không hành động mà không được ủy quyền hoặc truy cập thông tin nhạy cảm một cách bất hợp pháp.
Bức tranh hiện tại và các giải pháp mới nổi
Thế giới đang trải qua một sự dịch chuyển lớn từ việc sử dụng các chatbot AI riêng lẻ sang triển khai các hệ thống mạng lưới các Agent tự trị. Các giải pháp đang xuất hiện cho cả môi trường doanh nghiệp và các nhà phát triển (developer):
· Nền tảng doanh nghiệp: Các nền tảng lớn đang tích cực kết nối quy trình làm việc của Agent với cơ sở hạ tầng hiện có. Ví dụ, PwC’s agent OS cho phép các doanh nghiệp điều phối và quản lý các Agent trên các hệ sinh thái doanh nghiệp khổng lồ. · Open-Source Frameworks & Research: Các dự án như GitHub – agiresearch/AIOS và GitHub – buildermethods/agent-os cung cấp các Kernel nền tảng để phân lập tài nguyên và duy trì các tiêu chuẩn mã nguồn cho các Agent. · Kiến trúc chuyên biệt: Các nền tảng như MindStudio cho phép các nhà phát triển xây dựng trực quan các lớp Orchestration (điều phối), Memory (bộ nhớ) và định tuyến cần thiết để vận hành các Agent nghiệp vụ tự trị.
✪ Xuất hiện “nền kinh tế Agent”
Dựa trên nền giao thức A2A, các Agent từ các công ty khác nhau có thể “đàm phán” với nhau. Ví dụ: Agent du lịch của công ty A đàm phán trực tiếp với Agent định giá của hãng hàng không B mà không cần sự can thiệp của con người.
Ấn tượng nhất cuối năm 2025, đầu năm 2026 có lẽ là Agent tự lập trình (Coding Agent). Người lập trình không còn gõ câu lệnh vào trình soạn thảo như trước đây nữa, kể từ khi máy tính ra đời, kỷ nguyên đó đã qua rồi. Coder giờ đây chỉ cần khởi tạo các Agent, giao nhiệm vụ cho chúng *bằng tiếng Anh* và quản lý cũng như xem xét, đánh giá công việc của chúng (xem tweet của Andrej Karpathy trên X).
Liệu tất cả các Agent khác đã đạt đến mức hoàn thiện như Agent tự lập trình (Coding Agent)? Câu trả lời vào thời điểm hiện nay là “Chưa” – căn cứ theo nhiều nguồn. Vì sao vậy? Lý do chính: mã nguồn (source code) cũng là văn bản, và mọi chỉnh sửa phần mềm đều có thể được thực thi, kiểm tra và đánh giá lỗi ngay lập tức, mang lại cho Agent một vòng phản hồi nghiêm ngặt và khách quan. Trong lúc các Agent loại khác thường phải xử lý sự “mơ hồ”. Một Agent nghiên cứu thị trường hoặc trả lời email phức tạp của khách hàng dựa vào sự chấp thuận chủ quan của con người hơn là các bài kiểm tra khách quan, đen trắng rõ ràng như trong lập trình.
✪
Một loại Agent gần đây nổi lên như là một hiện tượng “siêu trí tuệ” là các Agent khám phá khoa học, đặc biệt là các Agent khám phá khoa học liên ngành. Thường con người chỉ giỏi trong một lĩnh vực nhất định. Trong khi các hệ thống Multi-Agent lại có khả năng giải quyết các vấn đề phức tạp, liên ngành đòi hỏi kiến thức và kỹ năng đa dạng.
✪
Gần đây rộ lên trên mạng xã hội xem Agent như là Digital Worker (nhân viên kỹ thuật số). Liệu các doanh nghiệp đã sẵn sàng giao việc cho các nhân viên “mới” này chưa?
Để trả lời câu hỏi này, chúng ta quay trở lại bản chất của Agent: Agent làm việc theo “Probabilistic” chứ không phải “Deterministic”. Mà đã là “Probabilistic” thì không bao giờ chắc chắn rằng Agent hoàn thành công việc theo đúng 100% như “đặc tả”.
Cũng trên mạng xã hội, người ta đề cập đến một nghề nghiệp mới: “Quản lý các Agent”. Con người sẽ chuyển từ người thực hiện sang người đánh giá. Công việc của con người sẽ là xác định mục tiêu, đặt ra các giới hạn (ngân sách) và “kiểm toán” công việc do một đội ngũ Agent tạo ra.