

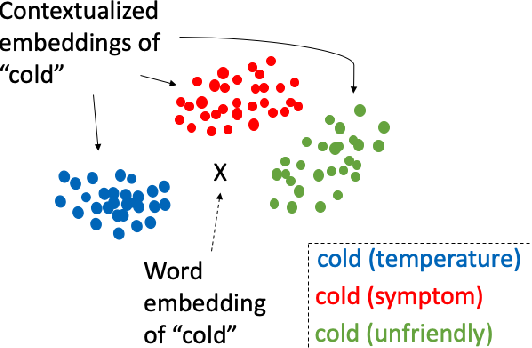
Trong huấn luyện mô hình ngôn ngữ, Contextual Embeddings là một phương pháp biểu diễn từ ngữ (word representation) dựa trên ngữ cảnh (context). Điều này có nghĩa là biểu diễn của một từ được xác định bởi ngữ cảnh xung quanh nó, bao gồm các từ khác trong câu hoặc văn bản.
Trước khi có Contextual Embeddings, phương pháp phổ biến nhất để biểu diễn từ ngữ là thông qua Word Embeddings như Word2Vec hoặc GloVe. Tuy nhiên, Word Embeddings xác định một biểu diễn cố định cho mỗi từ trong từ điển, độc lập với ngữ cảnh. Điều này có thể gây mất mát thông tin về ngữ nghĩa và mối quan hệ từ vựng trong các câu hoặc văn bản.
Contextual Embeddings, ví dụ như Embeddings from Language Models (ELMo) và Transformer-based models như GPT, BERT, làm việc theo cách khác. Thay vì một biểu diễn cố định cho mỗi từ, chúng tạo ra một biểu diễn từ ngữ duy nhất dựa trên ngữ cảnh xung quanh từ đó.
Cách thức hoạt động của Contextual Embeddings thường dựa trên kiến trúc mạng nơ-ron hồi quy (RNN) hoặc kiến trúc mạng tự chú ý như Transformer. Trong quá trình huấn luyện, mô hình được truyền vào một chuỗi các từ ngữ, và mỗi từ được biểu diễn dựa trên các từ xung quanh nó trong ngữ cảnh. Quá trình này có thể được thực hiện theo hai hướng: từ trái sang phải (đối với các ngôn ngữ có hướng) hoặc hai chiều (cho các ngôn ngữ không có hướng).
Khi mô hình được huấn luyện, nó học cách biểu diễn từ ngữ dựa trên ngữ cảnh. Điều này có lợi ích là từ cùng một từ vựng có thể có những biểu diễn khác nhau tùy thuộc vào ngữ cảnh xung quanh nó. Ví dụ, trong câu “Tôi bước qua cầu”, từ “cầu” có thể được hiểu là “cầu treo” hoặc “cầu đá” tùy thuộc vào ngữ cảnh, và Contextual Embeddings có thể bắt được sự khác biệt này.
Khi sử dụng Contextual Embeddings, chúng ta có thể sử dụng biểu diễn từ ngữ dựa trên ngữ cảnh trong nhiều nhiệm vụ ngôn ngữ khác nhau. Ví dụ, trong tác vụ phân loại văn bản, chúng ta có thể sử dụng Contextual Embeddings để biểu diễn các câu và sau đó đưa chúng vào một mô hình phân loại như SVM hoặc mạng nơ-ron để phân loại các văn bản.
Một ứng dụng phổ biến của Contextual Embeddings là trong mô hình ngôn ngữ dựa trên Transformer như BERT (Bidirectional Encoder Representations from Transformers). BERT sử dụng kiến trúc Transformer để học biểu diễn từ ngữ dựa trên ngữ cảnh cả từ trái sang phải và từ phải sang trái. Nó xây dựng một biểu diễn từ ngữ đại diện cho mỗi từ trong câu, gọi là “BERT embeddings”. Các BERT embeddings có thể được sử dụng trong nhiều tác vụ khác nhau như phân loại văn bản, dự đoán từ tiếp theo, hay sinh văn bản mới.
Một lợi ích quan trọng của Contextual Embeddings là khả năng nắm bắt được các mối quan hệ ngữ nghĩa và cấu trúc ngữ pháp trong văn bản. Nhờ vào khả năng này, mô hình có thể hiểu được các biểu đạt ngôn ngữ phức tạp hơn và đưa ra dự đoán chính xác hơn trong các tác vụ ngôn ngữ.
Tuy nhiên, việc huấn luyện mô hình sử dụng Contextual Embeddings cũng đòi hỏi một lượng dữ liệu lớn và tài nguyên tính toán cao. Mô hình phải được huấn luyện trên các tập dữ liệu lớn nhưng đa dạng để có thể nắm bắt được các biểu cảm và ngữ nghĩa phong phú trong ngôn ngữ.
Tóm lại, Contextual Embeddings là phương pháp biểu diễn từ ngữ dựa trên ngữ cảnh trong huấn luyện mô hình ngôn ngữ. Chúng cho phép mô hình hiểu được sự phụ thuộc ngữ cảnh của từ và nắm bắt được mối quan hệ ngữ nghĩa trong văn bản. Điều này đóng góp quan trọng cho hiệu suất và khả năng hiểu ngôn ngữ của mô hình trong các tác vụ ngôn ngữ khác nhau.
Kiểm soát ngữ nghĩa của nhiều bối cảnh nhằm tránh chồng lấn như thế nào?
Để kiểm soát ngữ nghĩa của nhiều Contextual Embeddings mà không bị chồng lấn từ ngữ sử dụng, bạn có thể áp dụng các phương pháp sau đây:
- Sử dụng lớp phân loại ngôn ngữ: Một cách tiếp cận là sử dụng lớp phân loại ngôn ngữ (language classification layer) để phân biệt và kiểm soát ngữ nghĩa của các Contextual Embeddings. Trong mô hình, bạn có thể thêm một lớp phân loại sau khi biểu diễn từ ngữ đã được tính toán. Lớp phân loại này sẽ học để phân biệt ngôn ngữ trong ngữ cảnh cụ thể và đưa ra dự đoán ngôn ngữ chính xác. Việc này giúp kiểm soát ngữ nghĩa mà không bị chồng lấn của các từ ngữ sử dụng.
- Sử dụng ngữ cảnh đặc trưng: Một phương pháp khác là sử dụng ngữ cảnh đặc trưng (domain-specific context) để định rõ ngữ nghĩa. Nếu bạn đang làm việc trên một lĩnh vực cụ thể, hãy xem xét sử dụng dữ liệu huấn luyện hoặc từ vựng đặc trưng cho lĩnh vực đó để tăng cường ngữ nghĩa của các Contextual Embeddings. Điều này giúp mô hình hiểu và biểu diễn ngữ nghĩa trong ngữ cảnh cụ thể mà không bị chồng lấn từ ngữ sử dụng.
- Tăng cường dữ liệu huấn luyện: Một lựa chọn khác là tăng cường dữ liệu huấn luyện với các ví dụ ngôn ngữ đa dạng và phong phú. Bằng cách mở rộng tập dữ liệu huấn luyện với các văn bản từ nhiều nguồn và ngôn ngữ khác nhau, mô hình sẽ được tiếp xúc với nhiều ngữ nghĩa và ngữ cảnh khác nhau, từ đó giúp kiểm soát ngữ nghĩa mà không bị chồng lấn từ ngữ sử dụng.
- Điều chỉnh và tinh chỉnh: Nếu bạn đang làm việc trên một nhiệm vụ cụ thể, bạn có thể điều chỉnh và tinh chỉnh mô hình Contextual Embeddings cho phù hợp với ngữ nghĩa của từng ngôn ngữ sử dụng. Điều này có thể được thực hiện
- bằng cách sử dụng kỹ thuật điều chỉnh (fine-tuning) hoặc học chuyển giao (transfer learning). Kỹ thuật điều chỉnh cho phép bạn điều chỉnh các trọng số của mô hình Contextual Embeddings dựa trên dữ liệu huấn luyện của mình. Bằng cách này, bạn có thể tinh chỉnh mô hình để tập trung vào ngữ nghĩa và ngữ cảnh cụ thể của từng ngôn ngữ sử dụng.
- Ngoài ra, học chuyển giao là một phương pháp sử dụng mô hình đã được huấn luyện trước đó trên một tác vụ liên quan và áp dụng nó vào nhiệm vụ mới. Bằng cách này, bạn có thể tận dụng kiến thức ngữ nghĩa đã được mô hình học trong quá trình huấn luyện ban đầu và áp dụng nó cho từng ngôn ngữ sử dụng riêng biệt.
- Quan trọng nhất, để kiểm soát ngữ nghĩa của nhiều Contextual Embeddings mà không bị chồng lấn từ ngữ sử dụng, bạn cần có dữ liệu huấn luyện đa dạng và đại diện cho các ngôn ngữ sử dụng. Điều này giúp mô hình hiểu và phân biệt các ngữ nghĩa và ngữ cảnh khác nhau trong từng ngôn ngữ.
- Tóm lại, để kiểm soát ngữ nghĩa của nhiều Contextual Embeddings mà không bị chồng lấn từ ngữ sử dụng, bạn có thể sử dụng lớp phân loại ngôn ngữ, sử dụng ngữ cảnh đặc trưng, tăng cường dữ liệu huấn luyện, điều chỉnh và tinh chỉnh mô hình, cũng như sử dụng kỹ thuật học chuyển giao. Kết hợp các phương pháp này sẽ giúp đảm bảo rằng mô hình Contextual Embeddings có khả năng hiểu và biểu diễn ngữ nghĩa một cách chính xác và không bị chồng lấn từ ngữ sử dụng.
Ví dụ cụ thể về việc biểu diễn một bối cảnh
Có 3 bối cảnh cần biểu diễn nằm ở 3 đoạn dữ liệu dưới đây:
1. “công ty cổ phần rada, hợp tác cung cấp thợ sửa chữa và các dịch vụ gia đình phục vụ các hộ cư dân trong toà nhà được triển khai ứng dụng phần mềm homeid. công ty tnhh công nghệ và thương mại beesky việt nam, đây là công ty cung cấp giải pháp bms beehome trong đó ứng dụng giao tiếp và thu phí cư dân cư dân sử dụng homeid công ty viện công nghệ thông tin và truyền thông cdit, viện cung cấp giải pháp ghi chỉ số điện nước ezwater qua app di động cùng với phần mềm homeid như một giải pháp đồng bộ. khách hàng sử dụng phần mềm homeid: các công ty cung cấp dịch vụ quản lý toà nhà; các chủ đầu tư hoặc các ban quản trị khách hàng của sàn tmđt: các chủ shop, chủ ki ốt hoặc các công ty cung ứng mặt hàng thực phẩm (rau, củ, quả, thịt, cá, gia cầm…), đồ gia dụng thiết yếu dành cho hộ cư dân chung cư.”
2. “homeid là một hệ thống phần mềm dùng cho cư dân và ban quản lý tại các toà nhà chung cư sử dụng trong việc thông báo và thu phí dịch vụ quản lý vận hành hàng tháng đồng thời là một công cụ giao tiếp hai chiều giữa ban quản lý và cư dân trong các hoạt động hàng ngày.”
3. “ưu điểm của phần mềm: bên ngoài các chức năng tiêu chuẩn, phần mềm còn cung cấp thêm một số tính năng bao gồm một sàn thương mại điện tử dành riêng cho cư dân và một hệ thống thợ sửa chữa với hơn 10.000 thợ sẵn sàng phục vụ. với những dịch vụ bổ sung này, cư dân sẽ hài lòng hơn và do đó, công ty quản lý tòa nhà sẽ có thể kéo dài được thời hạn hợp đồng với các tòa nhà. so sánh với facebook hay zalo thì đây là kênh thông tin riêng biệt, bảo mật, có tích hợp nhiều công cụ thanh toán tự động cũng như theo dõi tiến độ hợp nhất giữa cư dân và ban quản lý.”
Chúng ta có thể phân tách thành 5 bối cảnh khác nhau như sau:
- Chunk 1: “công ty cổ phần rada, hợp tác cung cấp thợ sửa chữa và các dịch vụ gia đình phục vụ các hộ cư dân trong toà nhà được triển khai ứng dụng phần mềm homeid.”
- Chunk 2: “công ty tnhh công nghệ và thương mại beesky việt nam, đây là công ty cung cấp giải pháp bms beehome trong đó ứng dụng giao tiếp và thu phí cư dân cư dân sử dụng homeid.”
- Chunk 3: “công ty viện công nghệ thông tin và truyền thông cdit, viện cung cấp giải pháp ghi chỉ số điện nước ezwater qua app di động cùng với phần mềm homeid như một giải pháp đồng bộ.”
- Chunk 4: “khách hàng sử dụng phần mềm homeid: các công ty cung cấp dịch vụ quản lý toà nhà; các chủ đầu tư hoặc các ban quản trị.”
- Chunk 5: “khách hàng của sàn tmđt: các chủ shop, chủ ki ốt hoặc các công ty cung ứng mặt hàng thực phẩm (rau, củ, quả, thịt, cá, gia cầm…), đồ gia dụng thiết yếu dành cho hộ cư dân chung cư.”
Hoặc có thể biểu diễn năm đoạn thông tin này với chung một bối cảnh ví dụ như để trả lời câu hỏi “đối tác của HomeID là ai”:
- Chunk 1: “Công ty cổ phần Rada là đối tác hợp tác cung cấp thợ sửa chữa và các dịch vụ gia đình phục vụ các hộ cư dân trong toà nhà. Họ đã triển khai ứng dụng phần mềm HomeID.”
- Chunk 2: “Công ty TNHH Công nghệ và Thương mại Beesky Việt Nam là đối tác của HomeID. Họ cung cấp giải pháp BMS BeeHome, trong đó ứng dụng giao tiếp và thu phí cho cư dân sử dụng HomeID.”
- Chunk 3: “Viện Công nghệ Thông tin và Truyền thông CDIT là đối tác của HomeID. Họ cung cấp giải pháp ghi chỉ số điện nước EZWater qua ứng dụng di động, kết hợp với phần mềm HomeID để tạo ra một giải pháp đồng bộ.”
- Chunk 4: “HomeID có các đối tác khách hàng bao gồm các công ty cung cấp dịch vụ quản lý toà nhà, các chủ đầu tư và các ban quản trị.”
- Chunk 5: “HomeID cũng hợp tác với khách hàng của sàn thương mại điện tử (TMĐT) bao gồm các chủ shop, chủ ki ốt và các công ty cung ứng mặt hàng thực phẩm (rau, củ, quả, thịt, cá, gia cầm…) cũng như đồ gia dụng thiết yếu dành cho hộ cư dân chung cư.”
Kết luận
Biểu diễn dữ liệu dưới dạng ngữ cảnh (Contextual Embeddings) trong huấn luyện dữ liệu riêng là phương pháp cung cấp ngữ nghĩa bằng các giải nghĩa làm giầu cho ngữ cảnh mà chúng ta hướng tới, giúp mô hình hiểu rõ hơn ý định mà chúng ta định tối ưu hướng tới các mục đích cụ thể.
Cách biểu diễn này khá tốn kém về dữ liệu tuy nhiên có ưu điểm về độ chính xác cũng như ít chồng lấn về ngữ nghĩa so với cách biểu diễn dưới dạng từ khoá đại diện hoặc các câu hỏi đơn.
Trong việc huấn luyện dữ liệu riêng cho các tổ chức, sẽ tuỳ theo mục đích cụ thể cùng với dữ liệu có thể cung cấp mà chúng ta có thể lựa chọn phương pháp tổ chức dữ liệu dưới các dạng khác nhau (trong đó có dạng ngữ cảnh này) để đáp ứng.