

Tác giả: Jordan Ranous
(ngày 11 tháng 9 năm 2023)
Các mô hình ngôn ngữ lớn mang lại khả năng đáng kinh ngạc mới, mở rộng biên giới của những gì có thể thực hiện được với trí tuệ nhân tạo. Tuy nhiên, kích thước lớn và đặc tính thực hiện độc đáo của chúng có thể làm cho việc sử dụng chúng một cách hiệu quả về chi phí trở nên khó khăn. NVIDIA TensorRT-LLM đã được công bố mã nguồn mở để tăng tốc quá trình phát triển của các mô hình ngôn ngữ lớn.
NVIDIA TensorRT-LLM là gì?
NVIDIA TensorRT-LLM là một công cụ hoặc phần mềm do NVIDIA phát triển và công bố mã nguồn mở, được thiết kế để tăng tốc và tối ưu hóa quá trình suy luận của các mô hình ngôn ngữ lớn (LLM – Large Language Models). Các LLM như GPT-3, GPT-4, và các biến thể khác đang trở nên quan trọng trong lĩnh vực Trí tuệ Nhân tạo và xử lý ngôn ngữ tự nhiên.
NVIDIA đã hợp tác chặt chẽ với các công ty hàng đầu như Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (hiện nay là một phần của Databricks), OctoML, Tabnine và Together AI để tăng tốc và tối ưu hóa quá trình suy luận của các LLM. Điều này giúp cải thiện hiệu suất và khả năng sử dụng hiệu quả của các mô hình này trong nhiều ứng dụng khác nhau, từ chatbot đến xử lý ngôn ngữ tự nhiên và nhiều ứng dụng AI khác.
Những đổi mới này đã được tích hợp vào phần mềm mã nguồn mở NVIDIA TensorRT-LLM, dự kiến sẽ được phát hành trong vài tuần tới. TensorRT-LLM bao gồm trình biên dịch học sâu TensorRT và bao gồm các nhân tối ưu hóa, các bước tiền xử lý và hậu xử lý, cũng như các nguyên tắc giao tiếp đa GPU/đa nút cho hiệu suất đột phá trên GPU NVIDIA. Nó cho phép các nhà phát triển thử nghiệm với các LLM mới, mang lại hiệu suất tối ưu và khả năng tùy chỉnh nhanh chóng mà không cần kiến thức sâu về C++ hoặc NVIDIA CUDA.
TensorRT-LLM cải thiện tính dễ sử dụng và tính mở rộng thông qua một API Python modul mã nguồn mở cho việc xác định, tối ưu hóa và thực thi kiến trúc mới và các cải tiến khi LLM phát triển và có thể được tùy chỉnh dễ dàng.
Ví dụ, MosaicML đã thêm các tính năng cụ thể mà họ cần lên TensorRT-LLM một cách trôi chảy và tích hợp chúng vào ngăn xếp dịch vụ hiện tại của họ. Naveen Rao, Phó Chủ tịch Kỹ thuật tại Databricks, lưu ý rằng “điều này thực sự rất dễ dàng.”
Hiệu suất của NVIDIA TensorRT-LLM
Tóm tắt bài viết chỉ là một trong nhiều ứng dụng của LLMs. Các chỉ số dưới đây cho thấy sự cải thiện về hiệu suất do TensorRT-LLM mang lại trên kiến trúc mới nhất của NVIDIA, được gọi là Hopper.
Các con số dưới đây phản ánh việc tóm tắt bài viết bằng cách sử dụng NVIDIA A100 và NVIDIA H100 với bộ dữ liệu CNN/Daily Mail, một bộ dữ liệu nổi tiếng để đánh giá hiệu suất tóm tắt.
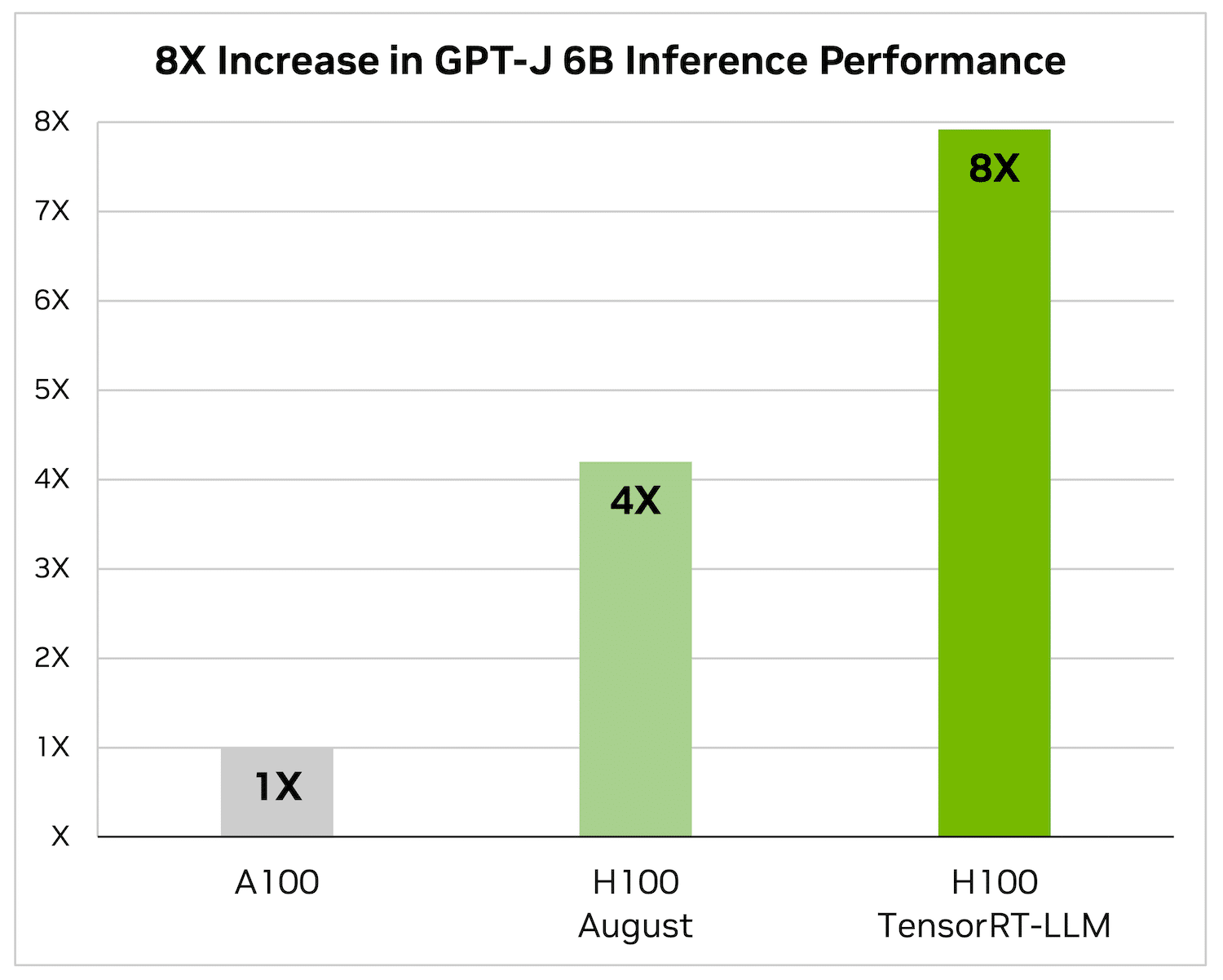
Máy chạy H100 độc lập nhanh hơn gấp 4 lần so với máy chạy A100. Khi thêm TensorRT-LLM và các lợi ích của nó, bao gồm việc xử lý hàng loạt trong quá trình bay, kết quả là một tăng gấp 8 lần để cung cấp tỷ lệ suất cao nhất.
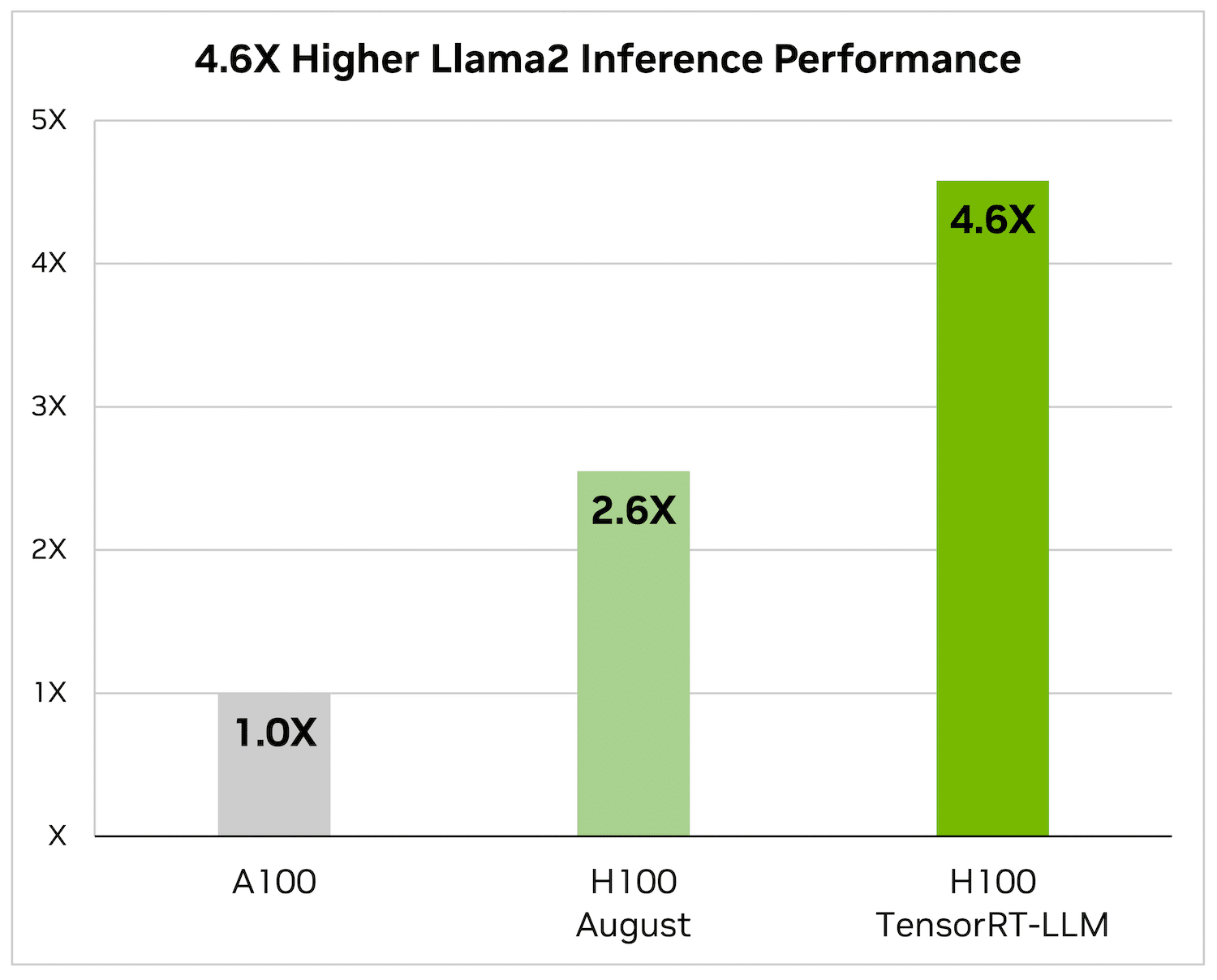
Trên Llama 2 – một mô hình ngôn ngữ phổ biến được Meta phát hành gần đây và được sử dụng rộng rãi bởi các tổ chức muốn tích hợp trí tuệ nhân tạo tạo nên, TensorRT-LLM có thể tăng tốc hiệu suất suy luận lên đến 4,6 lần so với GPU A100.
Tốc độ tiến hóa trong hệ sinh thái ngôn ngữ lớn đáng kinh ngạc
Sự đổi mới trong hệ sinh thái Mô hình Ngôn ngữ Lớn (LLM) đang tiến triển nhanh chóng, đồng thời tạo ra các kiến trúc mô hình đa dạng với khả năng mở rộng. Một số LLM lớn và tiên tiến nhất, như Llama 2 của Meta với 70 tỷ tham số, đòi hỏi sử dụng nhiều GPU để cung cấp phản hồi thời gian thực. Trước đây, việc tối ưu hóa suy luận LLM để đạt hiệu suất tối đa đòi hỏi nhiệm vụ phức tạp như phân chia thủ công các mô hình trí tuệ nhân tạo và điều phối thực thi trên GPU.
TensorRT-LLM đơn giản hóa quy trình này bằng cách sử dụng tính song song của tensor, một hình thức của tính song song mô hình mà phân phối ma trận trọng số qua các thiết bị. Cách tiếp cận này cho phép thực hiện quy trình suy luận quy mô lớn một cách hiệu quả trên nhiều GPU kết nối thông qua NVLink và nhiều máy chủ mà không cần sự can thiệp của nhà phát triển hoặc sửa đổi mô hình.
Khi xuất hiện các LLMs mới và kiến trúc mô hình mới, các nhà phát triển có thể tối ưu hóa mô hình của họ bằng cách sử dụng các kernel trí tuệ nhân tạo mới nhất của NVIDIA có sẵn trong TensorRT-LLM, bao gồm các cài đặt tiên tiến như FlashAttention và attention đa đầu được che khuất.
Hơn nữa, TensorRT-LLM bao gồm các phiên bản đã được tối ưu hóa trước của các LLMs phổ biến được sử dụng rộng rãi, chẳng hạn như Meta Llama 2, OpenAI GPT-2, GPT-3, Falcon, Mosaic MPT, BLOOM và nhiều mô hình khác. Các mô hình này có thể dễ dàng triển khai bằng cách sử dụng giao diện lập trình ứng dụng Python thân thiện với người dùng của TensorRT-LLM, giúp các nhà phát triển tạo ra các LLM tùy chỉnh phù hợp với nhiều ngành công nghiệp khác nhau.
Để đối phó với tính động của công việc LLM, TensorRT-LLM giới thiệu việc xử lý hàng loạt trong quá trình bay, tối ưu hóa lên lịch các yêu cầu. Kỹ thuật này cải thiện việc sử dụng GPU và gần như gấp đôi tỷ lệ suất trên các yêu cầu LLM thực tế, giảm Thiệt hại Tổng cộng (TCO).

Hơn nữa, TensorRT-LLM sử dụng các kỹ thuật định mức hóa để biểu diễn trọng số và hoạt động của mô hình ở độ chính xác thấp hơn (ví dụ, FP8). Điều này giảm tiêu thụ bộ nhớ, cho phép các mô hình lớn chạy một cách hiệu quả trên cùng phần cứng mà vẫn giảm thiểu nguồn lực liên quan đến bộ nhớ trong quá trình thực thi.
Hệ sinh thái LLM đang phát triển nhanh chóng, mang lại khả năng và ứng dụng mạnh mẽ trong nhiều lĩnh vực khác nhau. TensorRT-LLM tối ưu hóa suy luận LLM, cải thiện hiệu suất và TCO. Nó giúp các nhà phát triển tối ưu hóa mô hình dễ dàng và hiệu quả. Để truy cập TensorRT-LLM, các nhà phát triển và nghiên cứu có thể tham gia vào chương trình truy cập sớm thông qua framework NVIDIA NeMo hoặc GitHub, miễn là họ đã đăng ký trong Chương trình phát triển NVIDIA bằng địa chỉ email của tổ chức.
Thay lời kết luận
Chúng tôi đã lâu đã nhận thấy tại The Lab rằng có nguồn tài nguyên không tận được sử dụng không đủ trong ngăn xếp phần mềm, và TensorRT-LLM làm rõ rằng việc tập trung lại vào việc tối ưu hóa và không chỉ là sáng tạo có thể rất quý báu. Khi chúng tôi tiếp tục thử nghiệm với các framework và công nghệ tiên tiến khác nhau, chúng tôi có kế hoạch kiểm tra và xác minh độ hiệu quả từ việc cải thiện thư viện và phiên bản SDK.
Rõ ràng NVIDIA đang bỏ thời gian và nguồn lực phát triển để tận dụng tối đa hiệu suất từ phần cứng của mình, củng cố thêm vị trí của họ là nhà lãnh đạo ngành công nghiệp và tiếp tục đóng góp cho cộng đồng và làm cho trí tuệ nhân tạo trở nên phổ biến hơn bằng cách duy trì tính mã nguồn mở của các công cụ.