


Tác giả: Alex McFarland
10 tháng 8 năm 2023
Trong thế giới ngày càng phát triển của Trí tuệ Nhân tạo (AI), Mô hình Ngôn ngữ Lớn (LLM) đã xuất hiện như một điểm mốc quan trọng, thúc đẩy sự đổi mới và định hình lại cách chúng ta tương tác với công nghệ.
Khi những mô hình này trở nên ngày càng phức tạp, có sự tập trung gia tăng vào việc đánh giá quyền truy cập vào chúng. Các mô hình mã nguồn mở, đặc biệt là đang đóng một vai trò then chốt trong việc đánh giá quyền truy cập, cung cấp cho nhà nghiên cứu, nhà phát triển và những người đam mê cơ hội để đào sâu vào sự phức tạp của chúng, điều chỉnh chúng cho các nhiệm vụ cụ thể hoặc thậm chí xây dựng trên nền tảng của chúng.
Trong bài viết này, chúng ta sẽ khám phá một số LLM mã nguồn mở hàng đầu gây được sự chú ý trong cộng đồng AI, mỗi mô hình đều mang đến những điểm mạnh và khả năng độc đáo riêng.
1. Llama 2

Llama 2 của Meta là một sự bổ sung đột phá cho danh mục mô hình Trí tuệ Nhân tạo của họ. Điều này không chỉ là một mô hình khác; nó được thiết kế để cung cấp nhiều ứng dụng tiên tiến. Dữ liệu huấn luyện của Llama 2 rộng lớn và đa dạng, làm cho nó tiến bộ đáng kể so với người tiền nhiệm của nó. Sự đa dạng trong quá trình huấn luyện đảm bảo rằng Llama 2 không chỉ là một cải tiến theo từng bước mà còn là một bước đột phá hướng tới tương lai của sự tương tác được thúc đẩy bởi Trí tuệ Nhân tạo.
Sự hợp tác giữa Meta và Microsoft đã mở rộng tầm nhìn cho Llama 2. Mô hình mã nguồn mở này hiện được hỗ trợ trên các nền tảng như Azure và Windows, với mục tiêu cung cấp cho các nhà phát triển và tổ chức các công cụ để tạo ra trải nghiệm được tạo ra bởi Trí tuệ Nhân tạo. Sự hợp tác này là sự cam kết của cả hai công ty trong việc làm cho Trí tuệ Nhân tạo dễ tiếp cận và mở cửa cho tất cả.
Llama 2 không chỉ là một phiên bản kế nhiệm của mô hình Llama ban đầu; nó đại diện cho một sự thay đổi mô hình trong lĩnh vực chatbot. Trong khi mô hình Llama ban đầu là đột phá trong việc tạo ra văn bản và mã lập trình, thì tính sẵn có của nó đã bị hạn chế để ngăn chặn việc lạm dụng. Llama 2, mặt khác, được thiết lập để tiếp cận một đối tượng rộng lớn hơn. Nó được tối ưu hóa cho các nền tảng như AWS, Azure và nền tảng lưu trữ mô hình Trí tuệ Nhân tạo của Hugging Face. Hơn nữa, với sự hợp tác giữa Meta và Microsoft, Llama 2 sẽ ghi dấu ấn của mình không chỉ trên Windows mà còn trên các thiết bị sử dụng hệ thống-on-chip Snapdragon của Qualcomm.
An toàn là trái tim của thiết kế của Llama 2. Nhận thấy những thách thức mà các mô hình ngôn ngữ lớn trước đó như GPT đôi khi đã tạo ra nội dung sai lầm hoặc có hại, Meta đã thực hiện biện pháp mạnh để đảm bảo tính đáng tin cậy của Llama 2. Mô hình đã trải qua quá trình huấn luyện nghiêm ngặt để giảm thiểu ‘mộng du’, thông tin sai lệch và sự thiên vị.
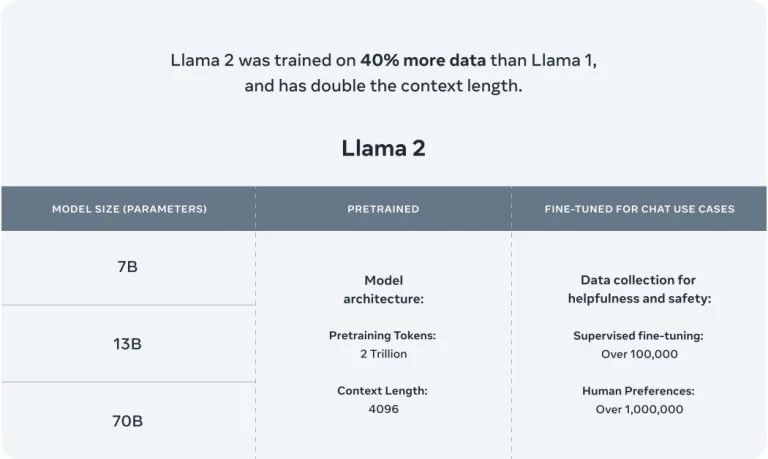
Các tính năng hàng đầu của LLaMa 2:
- Dữ liệu Huấn luyện Đa dạng: Dữ liệu huấn luyện của Llama 2 rất rộng rãi và đa dạng, đảm bảo hiểu biết và hiệu suất toàn diện.
- Sự hợp tác với Microsoft: Llama 2 được hỗ trợ trên các nền tảng như Azure và Windows, mở rộng phạm vi ứng dụng của nó.
- Sẵn có mã nguồn mở: Khác với người tiền nhiệm của nó, Llama 2 sẵn sàng cho một đối tượng rộng lớn hơn, có thể được điều chỉnh tốt trên nhiều nền tảng.
- Thiết kế tập trung vào An toàn: Meta đã tập trung vào an toàn, đảm bảo rằng Llama 2 sản xuất kết quả chính xác và đáng tin cậy trong khi giảm thiểu kết quả có hại.
- Phiên bản Tối ưu hóa: Llama 2 có hai phiên bản chính – Llama 2 và Llama 2-Chat, với phiên bản sau đặc biệt được thiết kế cho cuộc trò chuyện hai chiều. Những phiên bản này có độ phức tạp khác nhau từ 7 tỷ đến 70 tỷ tham số.
- Huấn luyện Nâng cao: Llama 2 được huấn luyện trên hai triệu mã thông tin, một sự tăng lên đáng kể so với 1.4 nghìn tỷ mã thông tin của Llama ban đầu.
2. Claude 2
Mô hình Trí tuệ Nhân tạo mới nhất của Anthropic, Claude 2, không chỉ đơn giản là một bản nâng cấp mà đại diện cho một sự tiến bộ đáng kể trong khả năng của các mô hình Trí tuệ Nhân tạo. Với các chỉ số hiệu suất được nâng cao, Claude 2 được thiết kế để cung cấp cho người dùng những phản ứng kéo dài và logic. Sự truy cập vào mô hình này rộng rãi, có sẵn thông qua giao diện lập trình ứng dụng (API) và trang web beta riêng của nó. Phản hồi từ người dùng cho thấy rằng việc tương tác với Claude là trực quan, với mô hình cung cấp giải thích chi tiết và thể hiện khả năng ghi nhớ kéo dài.
Về khả năng học thuật và lý luận, Claude 2 đã đạt được những thành tựu đáng kể. Mô hình đã đạt điểm 76.5% trong phần kiểm tra nhiều lựa chọn của Kỳ thi luật, đánh dấu một sự cải thiện so với 73.0% đạt được bởi Claude 1.3. Khi so sánh với sinh viên đại học chuẩn bị cho các chương trình sau đại học, Claude 2 đã biểu thị trên phân vị thứ 90 trong Kỳ thi GRE về đọc và viết, cho thấy sự thành thạo tạo ra nội dung phức tạp.
Khả năng đa dạng của Claude 2 là một đặc điểm đáng chú ý khác. Mô hình có thể xử lý đầu vào lên đến 100.000 tokens, cho phép xử lý tài liệu lớn từ hướng dẫn kỹ thuật đến nguyên văn một cuốn sách. Ngoài ra, Claude 2 có khả năng tạo ra các tài liệu kéo dài, từ các thông báo chính thức đến câu chuyện chi tiết mượt mà. Khả năng mã hóa của mô hình cũng đã được nâng cao, với Claude 2 đạt điểm 71.2% trên kiểm tra lập trình Python Codex HumanEval và 88.0% trên GSM8k, một bộ kiểm thử toán tiểu học.
An toàn vẫn là mối quan tâm hàng đầu của Anthropic. Sự tập trung đã được đặt vào việc đảm bảo rằng Claude 2 không dễ bị thao túng để tạo ra nội dung gây hại hoặc không phù hợp. Thông qua các đánh giá nội bộ tỉ mỉ và việc áp dụng các phương pháp an toàn tiên tiến, Claude 2 đã biểu thị sự cải thiện đáng kể tạo ra các phản ứng vô hại so với các phiên bản trước đó.
Tổng quan về các tính năng quan trọng của Claude 2:
- Tăng cường Hiệu suất: Claude 2 cung cấp thời gian phản hồi nhanh hơn và cung cấp các tương tác chi tiết hơn.
- Nhiều điểm Truy cập: Mô hình có thể được truy cập thông qua một API hoặc qua trang web beta riêng của nó, claude.ai.
- Xuất sắc trong Lĩnh vực Học thuật: Claude 2 đã cho thấy kết quả đáng khen trong các bài đánh giá học thuật, đặc biệt là trong phần đọc và viết của Kỳ thi GRE.
- Khả năng Xử lý Đầu vào/Đầu ra Mở rộng: Claude 2 có thể quản lý đầu vào lên đến 100.000 mã thông tin và có khả năng tạo ra các tài liệu kéo dài trong một phiên làm việc.
- Sự Thạo nghiệp trong Lập trình Nâng cao: Kỹ năng lập trình của mô hình đã được hoàn thiện, như thể hiện qua các điểm số trong các bài đánh giá về lập trình và toán học.
- Giao thức An toàn: Các đánh giá nghiêm ngặt và các kỹ thuật an toàn tiên tiến đã được áp dụng để đảm bảo rằng Claude 2 sản xuất các kết quả vô hại.
- Kế Hoạch Mở rộng: Mặc dù Claude 2 hiện chỉ có sẵn tại Mỹ và Vương quốc Anh, nhưng có kế hoạch mở rộng sự sẵn có của nó trên toàn cầu trong tương lai gần.
3. MPT-7B

MosaicML Foundations đã đóng góp quan trọng vào lĩnh vực này với sự ra mắt của MPT-7B, mô hình LLM mã nguồn mở mới nhất của họ. MPT-7B, viết tắt của MosaicML Pretrained Transformer, là một mô hình biến đổi giống GPT, chỉ có bộ giải mã. Mô hình này có một số cải tiến, bao gồm việc tối ưu hóa hiệu suất các lớp và những thay đổi trong kiến trúc để đảm bảo tính ổn định trong quá trình huấn luyện.
Một tính năng nổi bật của MPT-7B là việc huấn luyện trên một bộ dữ liệu rộng lớn bao gồm 1 nghìn tỷ mã thông tin văn bản và mã lập trình. Quá trình huấn luyện khắc nghiệt này đã được thực hiện trên nền tảng MosaicML trong vòng 9,5 ngày.
Tính mã nguồn mở của MPT-7B đặt nó thành một công cụ quý báu cho các ứng dụng thương mại. Nó có khả năng ảnh hưởng đáng kể đến phân tích dự đoán và quá trình ra quyết định của doanh nghiệp và tổ chức.
Ngoài mô hình cơ bản, MosaicML Foundations cũng phát hành các mô hình chuyên biệt được tùy chỉnh cho các nhiệm vụ cụ thể, chẳng hạn như MPT-7B-Instruct để thực hiện theo hướng dẫn ngắn gọn, MPT-7B-Chat để tạo ra đoạn hội thoại và MPT-7B-StoryWriter-65k+ để tạo ra câu chuyện dài hơn.
Hành trình phát triển của MPT-7B rất toàn diện, với đội ngũ MosaicML quản lý toàn bộ quá trình từ việc chuẩn bị dữ liệu đến triển khai trong vài tuần. Dữ liệu được thu thập từ nhiều kho lưu trữ khác nhau, và nhóm đã sử dụng các công cụ như GPT-NeoX của EleutherAI và trình tách mã thông tin 20 tỷ để đảm bảo việc huấn luyện kết hợp đa dạng và toàn diện.
Tổng quan về các tính năng quan trọng của MPT-7B:
- Giấy phép Thương mại: MPT-7B được cấp giấy phép cho mục đích thương mại, biến nó thành một tài sản quý báu cho doanh nghiệp.
- Dữ liệu Huấn luyện Rộng lớn: Mô hình được huấn luyện trên một tập dữ liệu lớn bao gồm 1 nghìn tỷ mã thông tin.
- Xử lý Đầu vào Dài hạn: MPT-7B được thiết kế để xử lý đầu vào vô cùng dài mà không cần phải hy sinh chất lượng.
- Tốc độ và Hiệu suất: Mô hình được tối ưu hóa cho quá trình huấn luyện và suy luận nhanh chóng, đảm bảo kết quả kịp thời.
- Mã nguồn Mở: MPT-7B đi kèm với mã nguồn mở hiệu quả, thúc đẩy tính minh bạch và dễ sử dụng.
- Ưu Việt So sánh: MPT-7B đã chứng minh sự ưu việt so với các mô hình mã nguồn mở khác trong phạm vi từ 7 tỷ đến 20 tỷ, với chất lượng của nó tương đương với LLaMA-7B.
4. Falcon
Falcon LLM, là một mô hình đã nhanh chóng lên đỉnh của hệ thống LLM. Cụ thể, Falcon LLM, đặc biệt là Falcon-40B, là một LLM cơ bản được trang bị 40 tỷ tham số và đã được huấn luyện trên một nghìn tỷ mã thông tin ấn tượng. Nó hoạt động như một mô hình giải mã chỉ một cách tự động, điều này có nghĩa là nó dự đoán mã thông tin tiếp theo trong một chuỗi dựa trên mã thông tin trước đó. Kiến trúc này gợi nhớ đến mô hình GPT. Đáng chú ý, kiến trúc của Falcon đã cho thấy hiệu suất ưu việt so với GPT-3, đạt được thành tích này chỉ với 75% ngân sách tính toán huấn luyện và yêu cầu ít tính toán hơn trong quá trình suy luận.
Nhóm tại Viện Đổi Mới Công Nghệ đã đặc biệt chú trọng đến chất lượng dữ liệu trong quá trình phát triển Falcon. Nhận thức về tính nhạy cảm của các LLM đối với chất lượng dữ liệu huấn luyện, họ đã xây dựng một đường ống dữ liệu mở rộng mà đã tỉ mỉ đến hàng chục nghìn lõi CPU. Điều này cho phép xử lý nhanh chóng và trích xuất nội dung chất lượng cao từ web, được đạt qua các quy trình lọc và loại bỏ trùng lặp mở rộng.
Ngoài Falcon-40B, TII cũng đã giới thiệu các phiên bản khác, bao gồm Falcon-7B, với 7 tỷ tham số và đã được huấn luyện trên 1,500 tỷ mã thông tin. Cũng có các mô hình chuyên biệt như Falcon-40B-Instruct và Falcon-7B-Instruct, được tùy chỉnh cho các nhiệm vụ cụ thể.
Việc huấn luyện Falcon-40B là một quá trình toàn diện. Mô hình đã được huấn luyện trên tập dữ liệu RefinedWeb, một tập dữ liệu web tiếng Anh khổng lồ được xây dựng bởi TII. Tập dữ liệu này được xây dựng trên nền tảng CommonCrawl và đã trải qua quy trình lọc kỹ lưỡng để đảm bảo chất lượng. Sau khi mô hình đã được chuẩn bị, nó đã được kiểm tra đối với một số tiêu chuẩn mã nguồn mở, bao gồm EAI Harness, HELM và BigBench.
Tổng quan về các tính năng quan trọng của Falcon LLM:
- Tham số Rộng lớn: Falcon-40B được trang bị 40 tỷ tham số, đảm bảo sự học toàn diện và hiệu suất cao.
- Mô hình Giải mã Chỉ Tự động: Kiến trúc này cho phép Falcon dự đoán mã thông tin tiếp theo dựa trên mã thông tin trước đó, tương tự như mô hình GPT.
- Hiệu suất Ưu việt: Falcon vượt trội so với GPT-3 trong khi chỉ sử dụng 75% ngân sách tính toán huấn luyện.
- Đường ống Dữ liệu Chất lượng Cao: Đường ống dữ liệu của TII đảm bảo việc trích xuất nội dung chất lượng cao từ web, quan trọng cho quá trình huấn luyện của mô hình.
- Đa dạng các Mô hình: Ngoài Falcon-40B, TII cung cấp Falcon-7B và các mô hình chuyên biệt như Falcon-40B-Instruct và Falcon-7B-Instruct.
- Sự Sẵn có Mã nguồn Mở: Falcon LLM đã được công bố mã nguồn mở, thúc đẩy tính tiếp cận và tính bao gồm trong lĩnh vực Trí tuệ Nhân tạo.
5. Vicuna-13B

LMSYS ORG đã để lại một dấu ấn đáng kể trong lĩnh vực các mô hình LLM mã nguồn mở với sự ra mắt của Vicuna-13B. Chatbot mã nguồn mở này đã được huấn luyện tỉ mỉ thông qua việc điều chỉnh lại LLaMA trên các cuộc trò chuyện do người dùng chia sẻ từ ShareGPT. Các đánh giá sơ bộ, với GPT-4 làm thẩm định, cho thấy rằng Vicuna-13B đạt hơn 90% chất lượng so với các mô hình nổi tiếng như OpenAI ChatGPT và Google Bard.
Nổi bật, Vicuna-13B vượt trội hơn so với các mô hình đáng chú ý khác như LLaMA và Stanford Alpaca trong hơn 90% trường hợp. Toàn bộ quá trình huấn luyện cho Vicuna-13B đã được thực hiện với mức chi phí khoảng 300 đô la. Đối với những người quan tâm đến việc khám phá khả năng của nó, mã nguồn, trọng lượng (weights), và một bản demo trực tuyến đã được công khai cho mục đích không thương mại.
Mô hình Vicuna-13B đã được điều chỉnh tỉ mỉ với 70.000 cuộc trò chuyện do người dùng chia sẻ từ ChatGPT, cho phép nó tạo ra các phản ứng chi tiết và có cấu trúc tốt hơn. Chất lượng của những phản hồi này có thể so sánh với ChatGPT. Tuy nhiên, việc đánh giá các chatbot là một công việc phức tạp. Với sự tiến bộ của GPT-4, có sự tò mò về khả năng của nó để hoạt động như một khung đánh giá tự động cho việc tạo bài kiểm tra và đánh giá hiệu suất. Các kết quả sơ bộ cho thấy rằng GPT-4 có thể tạo ra các xếp hạng nhất quán và đánh giá chi tiết khi so sánh các phản hồi của chatbot. Đánh giá ban đầu dựa trên GPT-4 cho thấy rằng Vicuna đạt được khả năng 90% so với các mô hình như Bard/ChatGPT.
Tổng quan về các tính năng quan trọng của Vicuna-13B:
- Tính Mã nguồn Mở: Vicuna-13B có sẵn để mọi người truy cập, thúc đẩy tính minh bạch và sự tham gia của cộng đồng.
- Dữ liệu Huấn luyện Rộng Lớn: Mô hình đã được huấn luyện trên 70.000 cuộc trò chuyện do người dùng chia sẻ, đảm bảo sự hiểu biết toàn diện về các tương tác đa dạng.
- Hiệu suất Cạnh tranh: Hiệu suất của Vicuna-13B tương đương với các lãnh đạo trong ngành như ChatGPT và Google Bard.
- Quá trình Huấn luyện Tiết kiệm Chi phí: Toàn bộ quá trình huấn luyện cho Vicuna-13B đã được thực hiện với mức chi phí thấp, khoảng 300 đô la.
- Điều chỉnh tốt trên LLaMA: Mô hình đã được điều chỉnh tỉ mỉ trên LLaMA, đảm bảo hiệu suất và chất lượng phản hồi cao hơn.
- Khả dụng Bản Demo Trực Tuyến: Một bản demo trực tuyến tương tác có sẵn để người dùng thử nghiệm và trải nghiệm khả năng của Vicuna-13B.
Khả năng mở rộng của các mô hình ngôn ngữ

Khả năng ứng dụng của Các Mô hình Ngôn ngữ Lớn (LLMs) là rất rộng và liên tục mở rộng, với mỗi mô hình mới đều đẩy lùi giới hạn và mở ra tiềm năng mới. Đặc tính mã nguồn mở của các LLM được thảo luận trong bài viết này không chỉ thể hiện tinh thần hợp tác của cộng đồng Trí tuệ Nhân tạo mà còn mở đường cho các đổi mới ở tương lai.
Những mô hình này, từ khả năng chatbot ấn tượng của Vicuna đến các chỉ số hiệu suất vượt trội của Falcon, đại diện cho đỉnh cao của công nghệ LLM hiện tại. Khi chúng ta tiếp tục chứng kiến sự tiến bộ nhanh chóng diễn ra mỗi ngày, rõ ràng rằng các mô hình mã nguồn mở đã và sẽ đóng vai trò quan trọng định hình tương lai của AI.
Dù bạn là một nhà nghiên cứu lâu năm, một người đam mê về Trí tuệ Nhân tạo mới nổi, hoặc đơn giản là tò mò về tiềm năng của những mô hình ngôn ngữ, bây giờ là thời điểm không thể tốt hơn để bắt đầu!
Thử ngay bạn nhé!