


Ngày 6/11/2023 đại diện của VinAI đã cập nhật thông tin giới thiệu 2 biến thể mô hình ngôn ngữ lớn PhoGPT-7B5 và PhoGPT7B5-Instruct được huấn luyện trước với 7,5 tỉ tham số từ 41GB dữ liệu văn bản tiếng Việt có tên PhoGPT trên github và huggingface hướng tới người dùng Việt Nam.
Mô hình này được huấn luyện với dữ liệu bao gồm 1GB văn bản từ Wikipedia và 40GB dữ liệu đã được loại bỏ trùng lặp được trích xuất từ khoảng 14.896.998 bài báo tiếng Việt trên internet được công bố đến ngày 21/5/2021 của tác giả Vương Quốc Bình (từ Đại học Công nghiệp) trên Github.
Theo nhóm tác giả của VinAI, PhoGPT đã được đào tạo sử dụng 150.000 cặp lời nhắc và phản hồi bằng tiếng Việt từ các nguồn dưới đây:
- 67.000 tập con của cặp hỏi đáp từ dataset của dự án Bactrian-X được công bố với 52 ngôn ngữ phổ biến.
- 40.000 cặp ShareGPT (tải về json của ShareGPT) không bao gồm mã nguồn lập trình và toán đã được dịch sang tiếng Việt sử dụng VinAI Transtale.
- 40.000 lời nhắc (prompt) đã được dịch sang tiếng Việt về các từ ngữ nhận thức về yêu/ghét, xúc phạm, độc hại, an toàn.
- 1.000 cặp câu hỏi và trả lời dựa trên ngữ cảnh
- 500 đề thơ
- 500 đề luận
- 500 sửa lỗi chính tả
- 500 tóm tắt tài liệu (chưa rõ tài liệu nào)
Đánh giá mô hình PhoGPT
Nhóm phát triển đã tiến hành đánh giá thử nghiệm mô hình và tiến hành so sánh với ChatGPT 3.5-turbo cùng một số mô hình mở khác như Vietcuna-3B, Vietcuna-7B-V3, URA, LlaMa-7B và URA-LLaMa-13B với 80 câu hỏi Vicuna được dịch thủ công sang tiếng Việt thuộc 8 mục khác nhau. Mỗi câu hỏi được đưa vào 6 mô hình để nhận được câu trả lời sau đó trộn ẩn danh trước khi đưa đến các nhà đánh giá độc lập để chấm điểm với thang điểm từ 1-5 tương đương 1 – Kém (ví dụ: trả lời sai), 2 – Kém (ví dụ: trả lời một phần câu hỏi), 3 – Khá, 4 – Tốt, đến 5 – Xuất sắc và thu được kết quả dưới đây:
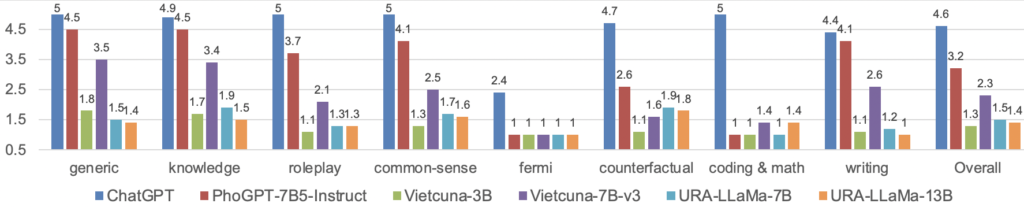
Các bạn có thể xem bảng kết quả và tự có đánh giá của riêng mình tại đây: Kết quả thử nghiệm
Dẫn lời nhóm tác giả về việc đánh giá: Như được hiển thị trong hình kết quả ở trên, PhoGPT-7B5-Instruct của chúng tôi có khả năng cạnh tranh mạnh mẽ so với ChatGPT cho các câu hỏi “chung”, “kiến thức”, “thông thường” và “viết”. Đáng chú ý, PhoGPT-7B5-Instruct vượt trội đáng kể so với các hướng dẫn cơ bản về nguồn mở trước đây dành cho tiếng Việt, ngoại trừ ở hạng mục “mã hóa & toán học” trong đó Vietcuna-7B-v3 và URA-LLaMa-13B hoạt động tốt hơn PhoGPT-7B5-Instruct. Hơn nữa, trong danh mục “nữ tính”, tất cả các mô hình nguồn mở đều hoạt động kém. Đối với PhoGPT-7B5-Instruct, những kết quả này được dự đoán trước do thiếu dữ liệu kiểu “coding & math” và “femi” trong kho ngữ liệu tiếng Việt tiền đào tạo của chúng tôi. Lưu ý rằng một số câu trả lời “tốt” từ Vietcuna-7B-v3 và URA-LLaMa-13B cho các câu hỏi “mã hóa & toán học” có nội dung giống hệt với câu trả lời từ ChatGPT. Điều này cho thấy các cặp câu hỏi-câu trả lời này có thể xuất hiện ngẫu nhiên trong các tập dữ liệu hướng dẫn sau đây được sử dụng để tinh chỉnh Vietcuna và URA-LLaMa.
Tải xuống mô hình
Bạn có thể tải xuống mô hình để thử nghiệm cho riêng mình theo chỉ dẫn dưới đây:
| Mô hình | Tải xuống |
|---|---|
vinai/PhoGPT-7B5 | https://huggingface.co/vinai/PhoGPT-7B5 |
vinai/PhoGPT-7B5-Instruct | https://huggingface.co/vinai/PhoGPT-7B5-Instruct |
Chạy mô hình
với Transformer
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer
model_path = "vinai/PhoGPT-7B5-Instruct"
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
config.init_device = "cuda"
# config.attn_config['attn_impl'] = 'triton' # Enable if "triton" installed!
model = AutoModelForCausalLM.from_pretrained(
model_path, config=config, torch_dtype=torch.bfloat16, trust_remote_code=True
)
# If your GPU does not support bfloat16:
# model = AutoModelForCausalLM.from_pretrained(model_path, config=config, torch_dtype=torch.float16, trust_remote_code=True)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
PROMPT = "### Câu hỏi:\n{instruction}\n\n### Trả lời:"
input_prompt = PROMPT.format_map(
{"instruction": "Làm thế nào để cải thiện kỹ năng quản lý thời gian?"}
)
input_ids = tokenizer(input_prompt, return_tensors="pt")
outputs = model.generate(
inputs=input_ids["input_ids"].to("cuda"),
attention_mask=input_ids["attention_mask"].to("cuda"),
do_sample=True,
temperature=1.0,
top_k=50,
top_p=0.9,
max_new_tokens=1024,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
response = response.split("### Trả lời:")[1]với vLLM
PhoGPT cũng có thể chạy với vLLM . Xem tài liệu vLLM để biết thêm chi tiết.
Tinh chỉnh mô hình
Xem tài liệu llm-foundry để biết thêm chi tiết. Để tinh chỉnh hoàn toàn vinai/PhoGPT-7B5 hoặc vinai/PhoGPT-7B5-Instruct trên một GPU A100 duy nhất có bộ nhớ 40GB, bạn nên sử dụng decoupled_lionw trình tối ưu hóa có giá trị device_train_microbatch_size được đặt thành 1.
Hạn chế
PhoGPT có những hạn chế nhất định. Ví dụ, nó không giỏi trong các nhiệm vụ liên quan đến lý luận, mã hóa hoặc toán học. PhoGPT đôi khi có thể tạo ra lời nói có hại, căm thù, phản hồi thiên vị hoặc trả lời các câu hỏi không an toàn. Người dùng nên thận trọng khi tương tác với PhoGPT vì có thể tạo ra kết quả đầu ra không chính xác.
Giấy phép sử dụng mô hình
Xem chi tiết giấy phép: Giấy phép sử dụng
Mô hình ngôn ngữ này được VinAI cung cấp mở sử dụng đến cộng đồng tuy nhiên sẽ khả năng sẽ không được OSI chấp nhận vì các điều khoản thương mại đi kèm khi triển khai mô hình có trên 1 triệu người dùng một tháng thì sẽ phải thực hiện một thoả thuận riêng và chấp thuận của VinAI cũng như việc VinAI giữ quyền ngưng thoả thuận này nếu người dùng vi phạm các điều khoản tại điểm 3 4 và 7 của thoả thuận.
Giấy phép có hiệu lực điều chỉnh tuân theo luật pháp của Việt Nam và phân xử tranh chấp tại toà án nhân dân thành phố Hà Nội.