


Tác giả: Aayush Mittal
Ngày 6 tháng 12 năm 2023
Nhìn lại vào năm đầu tiên của ChatGPT, rõ ràng thấy rằng công cụ này đã thay đổi đáng kể cảnh AI. Ra mắt vào cuối năm 2022, ChatGPT nổi bật với phong cách thân thiện với người dùng, giao tiếp tự nhiên khiến trải nghiệm tương tác với AI trở nên giống như nói chuyện với một người thay vì một máy móc. Phương pháp mới này nhanh chóng thu hút sự chú ý của công chúng. Chỉ trong vòng năm ngày sau khi ra mắt, ChatGPT đã thu hút một triệu người dùng. Đến đầu năm 2023, con số này tăng lên khoảng 100 triệu người dùng hàng tháng, và đến tháng 10, nền tảng này đã thu hút khoảng 1,7 tỷ lượt truy cập trên toàn thế giới. Những con số này nói lên về sự phổ biến và hữu ích của nó.
Trong suốt năm qua, người dùng đã tìm ra nhiều cách sáng tạo để sử dụng ChatGPT, từ những công việc đơn giản như viết email và cập nhật sơ yếu lý lịch đến việc khởi đầu kinh doanh thành công. Nhưng không chỉ là cách mà mọi người sử dụng nó; công nghệ chính nó đã phát triển và cải thiện. Ban đầu, ChatGPT là một dịch vụ miễn phí cung cấp câu trả lời văn bản chi tiết. Bây giờ, có ChatGPT Plus, bao gồm ChatGPT-4. Phiên bản cập nhật này được đào tạo trên nhiều dữ liệu hơn, trả lời ít câu hỏi sai hơn và hiểu rõ hơn các hướng dẫn phức tạp hơn.
Một trong những cập nhật lớn nhất là ChatGPT hiện có thể tương tác theo nhiều cách – nó có thể nghe, nói, và thậm chí xử lý hình ảnh. Điều này có nghĩa là bạn có thể nói chuyện với nó qua ứng dụng di động và cho nó xem hình ảnh để nhận câu trả lời. Những thay đổi này đã mở ra những khả năng mới cho AI và đã thay đổi cách mọi người nhìn nhận và suy nghĩ về vai trò của AI trong cuộc sống của chúng ta.
Từ sự xuất hiện ban đầu là một bản demo công nghệ đến tình trạng hiện tại là một người chơi quan trọng trong thế giới công nghệ, hành trình của ChatGPT rất ấn tượng. Ban đầu, nó được coi là cách để thử nghiệm và cải thiện công nghệ thông qua phản hồi từ cộng đồng. Nhưng nhanh chóng trở thành một phần quan trọng của cảnh quan AI. Sự thành công này cho thấy hiệu quả khi điều chỉnh các mô hình ngôn ngữ lớn (LLMs) với cả học có giám sát và phản hồi từ con người. Do đó, ChatGPT có thể xử lý một loạt các câu hỏi và nhiệm vụ.
Cuộc đua để phát triển các hệ thống AI có khả năng và linh hoạt nhất đã dẫn đến sự gia tăng của cả các mô hình mã nguồn mở và độc quyền như ChatGPT. Để hiểu về khả năng tổng quát của chúng, cần có các chỉ số đánh giá toàn diện trên một loạt nhiệm vụ. Phần này đi sâu vào những chỉ số này, làm sáng tỏ về cách các mô hình khác nhau, bao gồm cả ChatGPT, so sánh với nhau.
Các tiêu chí đánh giá mô hình ngôn ngữ lớn (LLMs)

- MT-Bench: Tiêu chí này kiểm thử khả năng đối thoại đa lượt và khả năng tuân thủ chỉ dẫn qua tám lĩnh vực: viết, diễn xuất vai diễn, trích xuất thông tin, lý luận, toán, lập trình, kiến thức STEM và ngành nhân văn/xã hội. Các LLMs mạnh mẽ như GPT-4 được sử dụng làm bộ đánh giá.
- AlpacaEval: Dựa trên bộ đánh giá AlpacaFarm, bộ đánh giá tự động này sử dụng LLM để đánh giá mô hình dựa trên phản hồi từ các LLMs tiên tiến như GPT-4 và Claude, tính toán tỷ lệ chiến thắng của các mô hình ứng viên.
- Bảng xếp hạng Open LLM: Sử dụng Hệ thống Đánh giá Mô hình Ngôn ngữ, bảng xếp hạng này đánh giá LLMs trên bảy tiêu chí quan trọng, bao gồm các thách thức lý luận và các bài kiểm tra kiến thức tổng quát, cả trong cài đặt không chạm và cài đặt vài chạm.
- BIG-bench: Tiêu chí đánh giá chung này bao gồm hơn 200 nhiệm vụ ngôn ngữ mới lạ, trải dài trên nhiều chủ đề và ngôn ngữ đa dạng. Nó mục tiêu là thăm dò LLMs và dự đoán khả năng tương lai của chúng.
- ChatEval: Một khung tranh luận đa tác nhân cho phép các đội tự độc lập thảo luận và đánh giá chất lượng của các câu trả lời từ các mô hình khác nhau đối với các câu hỏi mở và các nhiệm vụ sinh ngôn ngữ tự nhiên truyền thống.
So sánh hiệu suất
Về các tiêu chí đánh giá tổng quát, các mô hình LLM nguồn mở đã thể hiện sự tiến triển đáng kể. Llama-2-70B, ví dụ, đã đạt được kết quả ấn tượng, đặc biệt sau khi được điều chỉnh tốt với dữ liệu hướng dẫn. Biến thể của nó, Llama-2-chat-70B, xuất sắc trong AlpacaEval với tỷ lệ chiến thắng là 92,66%, vượt qua GPT-3.5-turbo. Tuy nhiên, GPT-4 vẫn là người dẫn đầu với tỷ lệ chiến thắng là 95,28%.
Zephyr-7B, một mô hình nhỏ hơn, đã thể hiện khả năng tương đương với các LLM lớn hơn 70B, đặc biệt là trong AlpacaEval và MT-Bench. Trong khi đó, WizardLM-70B, được điều chỉnh tốt với một loạt các dữ liệu hướng dẫn đa dạng, đạt điểm cao nhất trong số LLM nguồn mở trên MT-Bench. Tuy nhiên, nó vẫn đứng sau GPT-3.5-turbo và GPT-4.
Một đối tượng thú vị, GodziLLa2-70B, đạt điểm cạnh tranh trên Bảng xếp hạng Open LLM, cho thấy tiềm năng của các mô hình thử nghiệm kết hợp các bộ dữ liệu đa dạng. Tương tự, Yi-34B, được phát triển từ đầu, nổi bật với điểm tương đương với GPT-3.5-turbo và chỉ ít kém hơn GPT-4.
UltraLlama, với việc điều chỉnh tốt trên các dữ liệu đa dạng và chất lượng cao, so sánh với GPT-3.5-turbo theo các tiêu chí đề xuất và thậm chí vượt qua ở các lĩnh vực kiến thức thế giới và chuyên nghiệp.
Sự xuất hiện liên tiếp các mô hình LLM khổng lồ
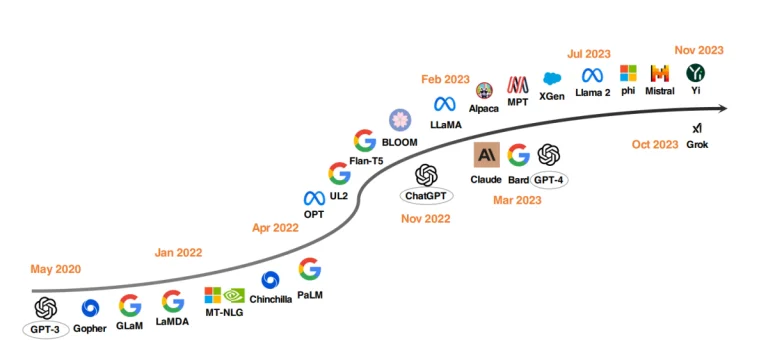
Một xu hướng đáng chú ý trong phát triển LLM là việc tăng kích thước của các tham số mô hình. Các mô hình như Gopher, GLaM, LaMDA, MT-NLG và PaLM đã đẩy ranh giới, dẫn đến các mô hình có đến 540 tỷ tham số. Các mô hình này đã thể hiện khả năng xuất sắc, nhưng tính đóng cửa của chúng đã hạn chế sự ứng dụng rộng rãi. Hạn chế này đã khuyến khích sự quan tâm trong việc phát triển các LLM nguồn mở, một xu hướng đang ngày càng trở nên mạnh mẽ.
Song song với việc tăng kích thước mô hình, các nhà nghiên cứu đã khám phá các chiến lược thay thế. Thay vì chỉ làm cho mô hình lớn hơn, họ đã tập trung vào việc cải thiện quá trình tiền đào tạo của các mô hình nhỏ hơn. Các ví dụ bao gồm Chinchilla và UL2, đã chỉ ra rằng việc làm cho mô hình lớn hơn không luôn là tốt; các chiến lược thông minh cũng có thể mang lại kết quả hiệu quả. Hơn nữa, đã có sự chú ý đáng kể vào việc điều chỉnh hướng dẫn của các mô hình ngôn ngữ, với các dự án như FLAN, T0 và Flan-T5 đóng góp đáng kể cho lĩnh vực này.
ChatGPT – Động lực thúc đẩy
Sự ra đời của ChatGPT từ OpenAI đánh dấu một điểm quay trong nghiên cứu xử lý ngôn ngữ tự nhiên (NLP). Để cạnh tranh với OpenAI, các công ty như Google và Anthropic đã tung ra các mô hình riêng của họ, lần lượt là Bard và Claude. Mặc dù những mô hình này có hiệu suất tương đương với ChatGPT trong nhiều nhiệm vụ, chúng vẫn kém hơn mô hình mới nhất từ OpenAI, GPT-4. Sự thành công của những mô hình này chủ yếu được quy cho học củng cố thông qua phản hồi từ con người (RLHF), một kỹ thuật đang nhận được sự tập trung nghiên cứu ngày càng nhiều để cải thiện hơn nữa.
Các phỏng đoán về mô hình siêu trí tuệ Q* của OpenAI

Các báo cáo gần đây gợi ý rằng các nhà nghiên cứu tại OpenAI có thể đã đạt được một tiến bộ đáng kể trong lĩnh vực Trí tuệ Nhân tạo với việc phát triển một mô hình mới được gọi là Q* (phát âm là Q star). Theo người ta cho biết, Q* có khả năng thực hiện các phép toán toán học ở mức độ trung học cơ bản, một thành tựu đã gây ra các cuộc thảo luận giữa các chuyên gia về tiềm năng của nó như một cột mốc hướng đến Trí tuệ Nhân tạo tổng quát (AGI). Mặc dù OpenAI chưa bình luận về những báo cáo này, những khả năng được đồn đại của Q* đã tạo nên nhiều sự hứng thú và suy đoán trên mạng xã hội và trong cộng đồng người hâm mộ Trí tuệ Nhân tạo.
Sự phát triển của Q* đáng chú ý bởi vì các mô hình ngôn ngữ hiện tại như ChatGPT và GPT-4, mặc dù có khả năng thực hiện một số nhiệm vụ toán học, nhưng không đặc biệt khéo léo trong việc xử lý chúng một cách đáng tin cậy. Thách thức nằm ở việc cần cho các mô hình Trí tuệ Nhân tạo không chỉ nhận diện mẫu, như hiện tại chúng làm thông qua học sâu và bộ biến đổi, mà còn phải lý luận và hiểu các khái niệm trừu tượng. Toán học, là một thước đo cho lý luận, đòi hỏi Trí tuệ Nhân tạo phải lập kế hoạch và thực hiện nhiều bước, thể hiện sự hiểu sâu về các khái niệm trừu tượng. Khả năng này sẽ đánh dấu một bước nhảy đáng kể trong khả năng của Trí tuệ Nhân tạo, có thể mở rộng ra ngoài lĩnh vực toán học đến các nhiệm vụ phức tạp khác.
Tuy nhiên, các chuyên gia cảnh báo không nên phóng đại quá mức về sự phát triển này. Mặc dù một hệ thống Trí tuệ Nhân tạo có khả năng giải quyết đáng tin cậy các vấn đề toán học sẽ là một thành tựu ấn tượng, điều này không nhất thiết có nghĩa là sự xuất hiện của Trí tuệ Nhân tạo siêu thông minh hoặc AGI. Nghiên cứu Trí tuệ Nhân tạo hiện tại, bao gồm cả những nỗ lực của OpenAI, đã tập trung vào các vấn đề cơ bản, với các mức độ thành công khác nhau trong các nhiệm vụ phức tạp hơn.
Các ứng dụng tiềm năng của những tiến bộ như Q* là rộng lớn, từ hướng dẫn cá nhân đến hỗ trợ nghiên cứu khoa học và kỹ thuật. Tuy nhiên, cũng quan trọng là phải quản lý kỳ vọng và nhận ra những hạn chế và rủi ro an toàn liên quan đến những tiến bộ như vậy. Những lo ngại về việc Trí tuệ Nhân tạo đặt ra rủi ro tồn tại, một lo lắng cơ bản của OpenAI, vẫn đang có tính thời sự, đặc biệt là khi các hệ thống Trí tuệ Nhân tạo bắt đầu tương tác nhiều hơn với thế giới thực.
Sự chuyển dịch mạnh mẽ khu vực Nguồn mở LLM
Để thúc đẩy nghiên cứu LLM nguồn mở, Meta đã phát hành các mô hình trong loạt Llama, kích thích một làn sóng các phát triển mới dựa trên Llama. Điều này bao gồm các mô hình được điều chỉnh tốt với dữ liệu hướng dẫn, như Alpaca, Vicuna, Lima và WizardLM. Nghiên cứu cũng mở rộng vào việc cải thiện khả năng của đại lý, lý luận hợp lý và mô hình hóa ngữ cảnh dài trong khung Llama.
Hơn nữa, có một xu hướng ngày càng phát triển các LLM mạnh mẽ từ đầu, với các dự án như MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok và Yi. Những nỗ lực này phản ánh cam kết chung để làm cho khả năng của các LLM đóng cửa nguồn mở hơn, tạo ra các công cụ Trí tuệ Nhân tạo tiên tiến trở nên dễ tiếp cận và hiệu quả hơn.
Tác Động của ChatGPT và các mô hình nguồn mở ứng dụng vào lĩnh vực Y tế

Chúng ta đang nhìn vào một tương lai nơi các LLM hỗ trợ việc ghi chú lâm sàng, điền các biểu mẫu đền bù, và hỗ trợ bác sĩ trong việc chẩn đoán và lập kế hoạch điều trị. Điều này đã thu hút sự chú ý của cả các công ty công nghệ lớn và các tổ chức y tế.
Các cuộc đàm phán giữa Microsoft và Epic, một trong những nhà cung cấp phần mềm hồ sơ y tế điện tử hàng đầu, là dấu hiệu cho việc tích hợp LLM vào lĩnh vực y tế. Các sáng kiến đã được triển khai tại UC San Diego Health và Trung tâm Y học của Đại học Stanford. Tương tự, các đối tác của Google với Mayo Clinic và việc Amazon Web Services ra mắt HealthScribe, một dịch vụ tài liệu lâm sàng AI, là những bước tiến quan trọng trong hướng này.
Tuy nhiên, việc triển khai nhanh chóng này gây ra lo ngại về việc nhượng quyền kiểm soát y tế cho lợi ích của các doanh nghiệp. Tính đặc quyền của những LLM này làm cho việc đánh giá chúng trở nên khó khăn. Khả năng sửa đổi hoặc ngừng sử dụng chúng vì lý do lợi nhuận có thể đe dọa chăm sóc bệnh nhân, quyền riêng tư và an toàn.
Nhu cầu cấp bách là tiếp cận một cách mở và bao hàm trong phát triển LLM trong lĩnh vực y tế. Các tổ chức y tế, nhà nghiên cứu, bác sĩ và bệnh nhân phải hợp tác toàn cầu để xây dựng các LLM nguồn mở cho lĩnh vực y tế. Phương pháp này, tương tự như Hội đồng Nghìn Tỷ Tham số, sẽ cho phép kết hợp nguồn lực tính toán, tài chính và chuyên môn.