


Tác giả: Aayush Mittal
Cập nhật vào ngày 29 tháng 3 năm 2024
Khi các ứng dụng của các mô hình ngôn ngữ lớn mở rộng vào các lĩnh vực chuyên sâu, nhu cầu về các kỹ thuật điều chỉnh hiệu quả và hiệu quả trở nên ngày càng quan trọng. RAFT (Retrieval Augmented Fine Tuning) ra đời, một phương pháp mới kết hợp sức mạnh của việc tăng cường truy xuất (RAG) và điều chỉnh tinh chỉnh, được điều chỉnh đặc biệt cho các nhiệm vụ trả lời câu hỏi trong lĩnh vực cụ thể.
Thách thức của Điều Chỉnh Chuyên ngành
Trong khi các LLM được tiền huấn luyện trên lượng lớn dữ liệu, khả năng của chúng để thực hiện tốt trong các lĩnh vực chuyên sâu như nghiên cứu y học, tài liệu pháp lý hoặc cơ sở kiến thức cụ thể của doanh nghiệp thường bị hạn chế. Hạn chế này phát sinh vì dữ liệu tiền huấn luyện có thể không đại diện đủ cho những sự tinh tế và phức tạp của các lĩnh vực chuyên ngành. Để giải quyết thách thức này, các nhà nghiên cứu truyền thống đã sử dụng hai kỹ thuật chính: tăng cường truy xuất (RAG) và tinh chỉnh.
Tăng Cường Truy Xuất (RAG)
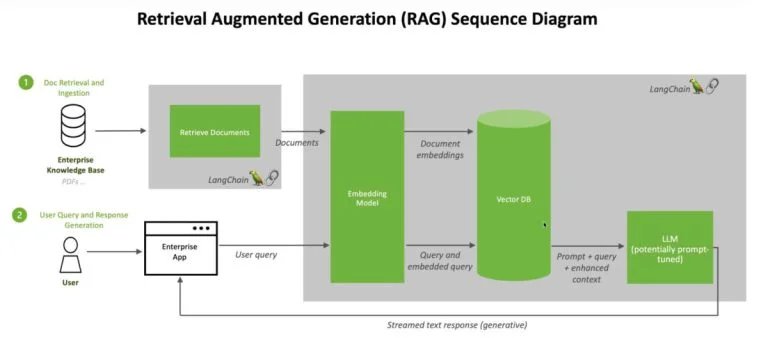
RAG là một kỹ thuật cho phép các LLM truy cập và sử dụng các nguồn kiến thức bên ngoài trong quá trình suy luận.
Nó đạt được điều này bằng cách tích hợp việc truy xuất dữ liệu thời gian thực vào quá trình tạo ra, từ đó làm cho các đầu ra của mô hình chính xác và cập nhật hơn. RAG bao gồm ba bước cốt lõi: truy xuất, nơi các tài liệu liên quan được thu thập; tạo ra, nơi mô hình tạo ra một đầu ra dựa trên dữ liệu được truy xuất; và bổ sung, giúp làm rõ đầu ra hơn nữa.
Quá trình truy xuất trong RAG bắt đầu bằng một truy vấn của người dùng. Các LLM phân tích truy vấn và lấy thông tin liên quan từ cơ sở dữ liệu bên ngoài, trình bày một bể dữ liệu mà mô hình có thể rút ra để định hình câu trả lời của mình. Các giai đoạn tạo ra sau đó tổng hợp đầu vào này thành một câu chuyện hoặc câu trả lời có logic. Bước bổ sung sau đó làm cho quá trình tạo ra trở nên rõ ràng hơn bằng cách thêm ngữ cảnh hoặc điều chỉnh để đảm bảo sự mạch lạc và liên quan.
Các mô hình RAG có thể được đánh giá bằng nhiều phương tiện khác nhau, đánh giá khả năng của chúng cung cấp thông tin chính xác, liên quan và cập nhật.
Tinh chỉnh
Tinh chỉnh, ngược lại, liên quan đến việc điều chỉnh một LLM đã được tiền huấn luyện cho một nhiệm vụ hoặc miền cụ thể bằng cách tiếp tục huấn luyện nó trên một tập dữ liệu nhỏ hơn, cụ thể cho nhiệm vụ đó. Phương pháp này cho phép mô hình học các mẫu và điều chỉnh đầu ra của nó sao cho phù hợp với nhiệm vụ hoặc miền mong muốn. Mặc dù tinh chỉnh có thể cải thiện hiệu suất của mô hình, thường thất bại trong việc tích hợp hiệu quả các nguồn kiến thức bên ngoài hoặc đối phó với các sai sót trong quá trình truy xuất trong suy luận.
Phương pháp RAFT
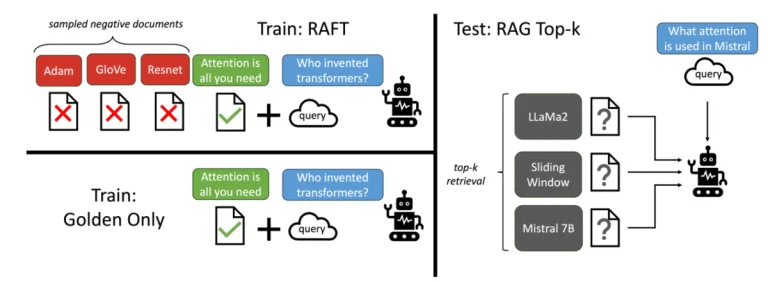
RAFT viết tắt của Retrieval-Aware Fine-Tuning, là một phương pháp đào tạo đổi mới được tinh chỉnh cho các mô hình ngôn ngữ nhằm nâng cao hiệu suất của chúng trong các nhiệm vụ cụ thể cho miền, đặc biệt là trong các kỳ thi sách mở. RAFT khác biệt với tinh chỉnh tiêu chuẩn bằng cách chuẩn bị dữ liệu huấn luyện bao gồm các câu hỏi với sự kết hợp của các tài liệu liên quan và không liên quan, cùng với các câu trả lời được phối hợp theo chuỗi suy nghĩ tạo ra từ các văn bản liên quan. Phương pháp này nhằm mục đích cải thiện khả năng của các mô hình không chỉ trong việc ghi nhớ thông tin mà còn trong việc suy luận và rút ra câu trả lời từ nội dung được cung cấp.
Về bản chất, RAFT điều chỉnh các mô hình ngôn ngữ để trở nên thành thạo hơn trong các nhiệm vụ liên quan đến việc hiểu đọc và trích xuất kiến thức từ một tập hợp các tài liệu. Bằng cách huấn luyện với cả các tài liệu “thần linh” (chứa câu trả lời) và các tài liệu “gây nhiễu” (không chứa câu trả lời), mô hình học được phân biệt và sử dụng thông tin liên quan một cách hiệu quả hơn.
Chuẩn bị Dữ liệu Huấn luyện
Quá trình huấn luyện trong RAFT bao gồm một tỷ lệ dữ liệu chứa các tài liệu “thần linh” trực tiếp liên quan đến câu trả lời, trong khi phần còn lại của dữ liệu chỉ bao gồm các tài liệu “gây nhiễu”. Việc tinh chỉnh khuyến khích mô hình học khi nào nên dựa vào kiến thức nội tại của mình (tương tự như việc ghi nhớ) và khi nào nên trích xuất thông tin từ ngữ cảnh được cung cấp.
Chế độ huấn luyện của RAFT cũng nhấn mạnh việc tạo ra các quá trình suy luận, không chỉ giúp hình thành câu trả lời mà còn trích dẫn nguồn, tương tự như cách một con người sẽ giải thích câu trả lời của họ bằng cách tham khảo tài liệu họ đã đọc. Phương pháp này không chỉ chuẩn bị mô hình cho một cài đặt RAG (Retrieval Augmented Generation) nơi nó phải xem xét các tài liệu được lấy ra hàng đầu mà còn đảm bảo rằng quá trình huấn luyện của mô hình độc lập với retriever được sử dụng, cho phép áp dụng linh hoạt trên các hệ thống truy xuất khác nhau.
Phương pháp này phục vụ nhiều mục đích:
- Nó huấn luyện mô hình nhận biết và sử dụng thông tin liên quan từ ngữ cảnh được cung cấp, bắng cách mô phỏng cài đặt kỳ thi sách mở.
- Nó tăng cường khả năng của mô hình phớt lờ thông tin không liên quan, một kỹ năng quan trọng cho việc thực hiện hiệu quả RAG.
- Nó tiếp xúc mô hình với các tình huống mà câu trả lời không có trong ngữ cảnh, khuyến khích nó dựa vào kiến thức của mình khi cần thiết.
Một khía cạnh quan trọng khác của RAFT là việc kết hợp suy luận theo chuỗi ý tưởng vào quá trình huấn luyện. Thay vì chỉ cung cấp các cặp câu hỏi và câu trả lời, RAFT tạo ra các giải thích suy luận chi tiết mà bao gồm trích dẫn trực tiếp từ các tài liệu liên quan. Những giải thích này, được trình bày theo định dạng chuỗi ý tưởng, hướng dẫn mô hình qua các bước logic cần thiết để đạt được câu trả lời đúng.
Bằng cách huấn luyện mô hình trên những chuỗi suy luận này, RAFT khuyến khích sự phát triển của khả năng suy luận mạnh mẽ và nâng cao sự hiểu biết của mô hình về cách tận dụng hiệu quả các nguồn kiến thức bên ngoài.
Đánh giá và Kết quả
Các tác giả của bài báo về RAFT đã tiến hành các đánh giá mở rộng trên các tập dữ liệu khác nhau, bao gồm PubMed (nghiên cứu y sinh học), HotpotQA (trả lời câu hỏi miền mở), và Gorilla APIBench (tạo mã). Kết quả của họ đã chứng minh rằng RAFT luôn vượt qua các chỉ số cơ sở, chẳng hạn như tinh chỉnh tinh chỉnh cho miền cụ thể có và không có RAG, cũng như các mô hình lớn hơn như GPT-3.5 với RAG.
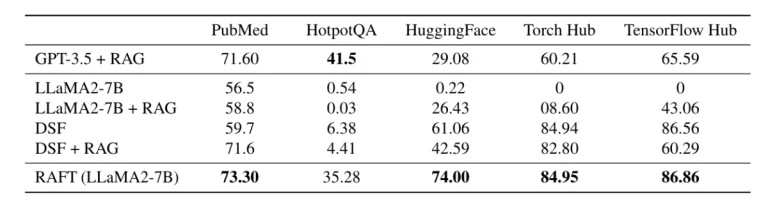
Ví dụ, trên tập dữ liệu của HuggingFace, RAFT đạt được độ chính xác là 74%, một cải thiện đáng kể là 31.41% so với tinh chỉnh tinh chỉnh cho miền cụ thể (DSF) và 44.92% so với GPT-3.5 với RAG. Tương tự, trên tập dữ liệu HotpotQA, RAFT đã thể hiện một sự tăng đáng kể với độ chính xác là 28.9% so với DSF.
Một trong những ưu điểm chính của RAFT là sự mạnh mẽ trước các sai sót trong việc truy xuất. Bằng cách huấn luyện mô hình với một sự kết hợp của các tài liệu có liên quan và không liên quan, RAFT cải thiện khả năng của mô hình phân biệt và ưu tiên thông tin có liên quan, ngay cả khi mô-đun truy xuất trả về kết quả không tối ưu.
Các tác giả đã chứng minh rằng việc tinh chỉnh chỉ với các tài liệu “thần linh” thường dẫn đến hiệu suất kém hơn so với các cấu hình bao gồm các tài liệu “gây nhiễu”. Kết luận này nhấn mạnh tầm quan trọng của việc tiếp xúc mô hình với các kịch bản truy xuất khác nhau trong quá trình huấn luyện, đảm bảo sự chuẩn bị cho ứng dụng thực tế.
Ứng dụng Thực Tiễn và Hướng Phát Triển Tương Lai

Kỹ thuật RAFT có những ảnh hưởng đáng kể đối với một loạt các ứng dụng thực tiễn, bao gồm:
- Hệ thống Trả lời Câu hỏi: RAFT có thể được sử dụng để xây dựng các hệ thống trả lời câu hỏi cụ thể cho miền, tận dụng cả kiến thức đã học của mô hình và các nguồn kiến thức bên ngoài.
- Quản lý Kiến thức Doanh nghiệp: Các tổ chức có cơ sở kiến thức lớn có thể tận dụng RAFT để phát triển các hệ thống trả lời câu hỏi tùy chỉnh, giúp nhân viên truy cập và sử dụng thông tin phù hợp một cách nhanh chóng.
- Nghiên cứu Y học và Khoa học: RAFT có thể đặc biệt quý giá trong các lĩnh vực như nghiên cứu y sinh học, nơi việc truy cập vào các phát hiện và tài liệu mới nhất là quan trọng để tiến bộ trong hiểu biết khoa học.
- Dịch vụ Pháp lý và Tài chính: RAFT có thể hỗ trợ các chuyên gia trong các lĩnh vực này bằng cách cung cấp các phản hồi chính xác và nhận thức bối cảnh dựa trên các tài liệu pháp lý hoặc báo cáo tài chính liên quan.
Khi nghiên cứu trong lĩnh vực này tiếp tục, chúng ta có thể mong đợi những tiến bộ và điều chỉnh tiếp theo cho kỹ thuật RAFT. Các hướng phát triển tiềm năng bao gồm:
- Khám phá các mô-đun truy xuất hiệu quả và hiệu quả hơn, được tùy chỉnh cho các miền hoặc cấu trúc tài liệu cụ thể.
- Tích hợp thông tin đa phương tiện, như hình ảnh hoặc bảng biểu, vào khung RAFT để hiểu ngữ cảnh tăng cường.
- Phát triển các kiến trúc suy luận chuyên sâu có thể tận dụng tốt hơn các giải thích theo chuỗi suy nghĩ được tạo ra trong quá trình huấn luyện.
- Điều chỉnh RAFT cho các nhiệm vụ ngôn ngữ tự nhiên khác ngoài việc trả lời câu hỏi, như tóm tắt, dịch hoặc hệ thống đối thoại.
Kết Luận
RAFT đại diện cho một bước tiến lớn trong lĩnh vực trả lời câu hỏi cụ thể cho miền với các mô hình ngôn ngữ. Bằng cách hòa hợp mạnh mẽ giữa các ưu điểm của việc tăng cường truy xuất và tinh chỉnh, RAFT trang bị cho các LLM khả năng tận dụng hiệu quả các nguồn kiến thức bên ngoài trong khi cũng điều chỉnh đầu ra của chúng theo các mẫu và ưu tiên cụ thể cho miền.
Thông qua việc tạo ra dữ liệu huấn luyện sáng tạo, tích hợp suy luận theo chuỗi ý tưởng và sự mạnh mẽ đối với các sai sót trong việc truy xuất, RAFT cung cấp một giải pháp mạnh mẽ cho các tổ chức và nhà nghiên cứu đang tìm cách mở khóa tiềm năng toàn diện của các LLM trong các lĩnh vực chuyên sâu.
Khi nhu cầu về khả năng xử lý ngôn ngữ tự nhiên cụ thể cho miền tiếp tục tăng lên, các kỹ thuật như RAFT sẽ đóng vai trò quan trọng trong việc cho phép các mô hình ngôn ngữ chính xác hơn, nhận thức bối cảnh hơn và linh hoạt hơn, mở đường cho một tương lai nơi giao tiếp giữa con người và máy móc trở nên thực sự mượt mà và không phụ thuộc vào miền.