


Cơ sở dữ liệu Vector đã trở thành nơi lưu trữ và lập chỉ mục các cách biểu diễn dữ liệu có cấu trúc và phi cấu trúc. Những biểu diễn này, được gọi là nhúng vectơ, được tạo bằng các mô hình nhúng. Kho lưu trữ vectơ đóng một vai trò quan trọng trong việc phát triển các ứng dụng sử dụng mô hình học sâu, đặc biệt là các mô hình ngôn ngữ lớn.
Cơ sở dữ liệu Vector là gì?
Trong thế giới thực, không phải mọi dữ liệu đều nằm gọn trong các hàng và cột. Điều này đặc biệt đúng khi xử lý dữ liệu phức tạp, phi cấu trúc như hình ảnh, video và ngôn ngữ tự nhiên. Đó là nơi cơ sở dữ liệu vector xuất hiện.
Cơ sở dữ liệu vectơ là một loại cơ sở dữ liệu lưu trữ dữ liệu dưới dạng vectơ chiều cao, về cơ bản là danh sách các số đại diện cho các tính năng hoặc đặc điểm của một đối tượng. Mỗi vectơ tương ứng với một thực thể duy nhất, như một đoạn văn bản, hình ảnh hoặc video.
Nhưng tại sao lại sử dụng vectơ? Điều kỳ diệu nằm ở khả năng nắm bắt ý nghĩa ngữ nghĩa và sự tương đồng. Bằng cách biểu diễn dữ liệu dưới dạng vectơ, chúng ta có thể so sánh chúng về mặt toán học và xác định mức độ giống hoặc khác nhau của chúng. Điều này cho phép chúng ta thực hiện các truy vấn phức tạp như “tìm cho tôi những hình ảnh tương tự như hình ảnh này” hoặc “truy xuất các tài liệu có liên quan về mặt ngữ nghĩa với văn bản này”.
Tại sao cơ sở dữ liệu Vector có nhu cầu sử dụng rộng rãi?
Trong những năm gần đây, cơ sở dữ liệu vector ngày càng trở nên phổ biến, đặc biệt là trong lĩnh vực học máy (ML) và trí tuệ nhân tạo (AI). Sự phức tạp của các mô hình AI và ML đòi hỏi các phương pháp hiệu quả để lưu trữ, tìm kiếm và truy xuất khối lượng dữ liệu phi cấu trúc khổng lồ mà chúng xử lý.
Độ phức tạp và kích thước của dữ liệu vectơ thường có thể quá lớn đối với cơ sở dữ liệu truyền thống được xây dựng cho dữ liệu có cấu trúc. Ngược lại, cơ sở dữ liệu vector được thiết kế đặc biệt cho mục đích này. Chúng cung cấp các thuật toán tìm kiếm và lập chỉ mục chuyên biệt, ngay cả trong cơ sở dữ liệu có hàng tỷ đầu mục được đưa vào thì chúng ta vẫn có thể định vị các vectơ (so sánh) một cách nhanh chóng.
Các trường hợp sử dụng khác nhau của cơ sở dữ liệu vectơ
Các ứng dụng cho AI và ML được mở rộng đáng kể nhờ khả năng tìm kiếm các vectơ tương đương. Các trường hợp sử dụng điển hình bao gồm:
- Hệ thống RAG: Cơ sở dữ liệu vectơ có thể được kết hợp cùng với Mô hình ngôn ngữ lớn (LLM) để xây dựng các ứng dụng AI ngôn ngữ dựa trên kiến thức.
- Hệ thống đề xuất: Các công cụ đề xuất được cá nhân hóa cao có thể được cung cấp bởi cơ sở dữ liệu vectơ, thể hiện sở thích của người dùng và thuộc tính vật phẩm dưới dạng vectơ.
- Truy xuất nội dung hình ảnh, video: Cơ sở dữ liệu vectơ đã cách mạng hóa việc truy xuất dựa trên nội dung bằng cách cho phép tìm kiếm các hình ảnh hoặc video có liên quan trực quan.
- Xử lý ngôn ngữ tự nhiên: Cơ sở dữ liệu vectơ cung cấp tìm kiếm ngữ nghĩa, mô hình hóa chủ đề và nhóm tài liệu bằng cách chuyển đổi văn bản thành vectơ.
- Phát hiện gian lận: Để hỗ trợ xác định các xu hướng và sự bất thường trong giao dịch tài chính, có thể sử dụng cơ sở dữ liệu vectơ.
So sánh cơ sở dữ liệu Vector
Có một số Cơ sở dữ liệu Vectores hiện có đến thời điểm này như Qdrant, Pinecone, Milvus, Chroma, Weaviate, v.v. Mỗi cơ sở dữ liệu đều có điểm mạnh, sự cân bằng và trường hợp sử dụng lý tưởng riêng. Tại đây, chúng ta sẽ đi sâu vào so sánh toàn diện giữa các cơ sở dữ liệu vectơ phổ biến, bao gồm Pinecone, Milvus, Chroma, Weaviate, Faiss, Elasticsearch và Qdrant.
Khả năng triển khai
Pinecone là một trong những điều kỳ lạ về mặt này. Vì Pinecone là dịch vụ đám mây hoàn toàn vì lý do hiệu suất và khả năng mở rộng nên bạn không thể chạy phiên bản cục bộ. Milvus, Chroma, Weaviate, Faiss, Elaticsearch và Qdrant đều có thể chạy cục bộ; hầu hết đều cung cấp hình ảnh Docker để làm như vậy.

Khả năng mở rộng
Qdrant cung cấp phân mảnh tĩnh; nếu dữ liệu của bạn phát triển vượt quá khả năng của máy chủ, bạn sẽ cần thêm nhiều máy hơn vào cụm và phân chia lại tất cả dữ liệu của mình. Đây có thể là một quá trình tốn thời gian và phức tạp. Ngoài ra, các phân đoạn mất cân bằng có thể gây tắc nghẽn và làm giảm hiệu quả của hệ thống.
Pinecone hỗ trợ phân tách điện toán và lưu trữ với Cấp độ không phục vụ của chúng. Đối với các cụm dựa trên POD, Pinecone sử dụng tính năng phân chia tĩnh, yêu cầu người dùng phân chia lại dữ liệu theo cách thủ công khi mở rộng quy mô cụm.
Weaviate cung cấp sharding tĩnh. Nếu không có bất kỳ sự thay thế dữ liệu phân tán nào, Chroma không thể mở rộng quy mô ra ngoài một nốt duy nhất

Hiệu suất
- Qdrant đạt được RPS cao nhất và độ trễ thấp nhất trong hầu hết các trường hợp, bất kể ngưỡng chính xác và số liệu chúng tôi chọn. Nó cũng cho thấy mức tăng RPS gấp 4 lần trên một trong các tập dữ liệu.
- Elaticsearch đã trở nên nhanh chóng đáng kể đối với nhiều trường hợp sử dụng nhưng lại rất chậm về thời gian lập chỉ mục. Nó có thể chậm hơn gấp 10 lần khi lưu trữ hơn 10M vectơ 96 chiều! (32 phút so với 5,5 giờ)
- Milvus là nhanh nhất khi nói đến thời gian lập chỉ mục và duy trì độ chính xác tốt. Tuy nhiên, nó không ngang bằng với những cái khác khi nói đến RPS hoặc độ trễ, khi bạn có các phần nhúng thứ nguyên cao hơn hoặc nhiều vectơ hơn.
- Redis có thể đạt được RPS tốt nhưng chủ yếu có độ chính xác thấp hơn. Nó cũng đạt được độ trễ thấp chỉ với một luồng duy nhất; tuy nhiên độ trễ của nó tăng lên nhanh chóng với nhiều yêu cầu song song hơn. Một phần của tốc độ tăng này đến từ giao thức tùy chỉnh của nó.
- Weaviate đã được cải thiện ít nhất theo thời gian. Do những cải tiến tương đối ở các công cụ khác, nó đã trở thành một trong những công cụ chậm nhất về RPS cũng như độ trễ.

Quản lý dữ liệu

Tìm kiếm vectơ tương tự
Một trong những lý do khiến cơ sở dữ liệu vectơ rất hữu ích là vì chúng có thể cho chúng ta biết về mối quan hệ giữa các sự vật và mức độ giống hoặc khác nhau của chúng. Có nhiều số liệu khoảng cách cho phép cơ sở dữ liệu vectơ thực hiện việc này và các cơ sở dữ liệu vectơ khác nhau sẽ triển khai các số liệu khoảng cách khác nhau.

Tích hợp và API
Mặc dù API REST thường gặp hơn, nhưng API GRPC lại hướng đến hiệu suất và thông lượng trong các tình huống quan trọng về độ trễ hoặc khi cần di chuyển lượng lớn dữ liệu một cách nhanh chóng. Tùy thuộc vào yêu cầu và mạng của bạn, GRPC có thể nhanh hơn REST vài lần.

Cộng đồng và hệ sinh thái
Nguồn mở có nghĩa là chúng ta có thể duyệt qua mã nguồn cho cơ sở dữ liệu cốt lõi và DB vectơ cũng như nó có mô hình cấp phép linh hoạt.

Giá thành

Lọc metadata
Siêu dữ liệu là một khái niệm cực kỳ mạnh mẽ, bổ sung cho các tính năng cơ sở dữ liệu vectơ cốt lõi; đó là mối liên kết giữa ngôn ngữ mơ hồ của con người và dữ liệu có cấu trúc. Đây là nền tảng của kiến trúc nơi người dùng yêu cầu một sản phẩm và trợ lý mua sắm AI sẽ ngay lập tức phản hồi với các mặt hàng họ mô tả.

Chức năng cơ sở dữ liệu vectơ
- Qdrant: Qdrant sử dụng ba loại chỉ mục để cung cấp năng lượng cho cơ sở dữ liệu của nó. Ba chỉ mục này là chỉ mục Tải trọng, tương tự như chỉ mục trong cơ sở dữ liệu hướng tài liệu thông thường; chỉ mục toàn văn bản cho tải trọng chuỗi; và một chỉ số vectơ. Phương pháp tìm kiếm kết hợp của họ là sự kết hợp giữa tìm kiếm vectơ với lọc thuộc tính.
- Pinecone: RBAC là không đủ cho các tổ chức lớn. Tối ưu hóa bộ nhớ (S1) có một số thách thức về hiệu suất và chỉ có thể nhận được 10–50 QPS. Số lượng không gian tên bị giới hạn và người dùng nên cẩn thận khi sử dụng tính năng lọc siêu dữ liệu như một cách khắc phục hạn chế này vì nó sẽ có tác động lớn đến hiệu suất. Hơn nữa, cách ly dữ liệu không có sẵn với phương pháp này.
- Weaviate: Weaviate sử dụng hai loại chỉ mục để cung cấp năng lượng cho cơ sở dữ liệu của nó. Một chỉ mục đảo ngược, ánh xạ các thuộc tính đối tượng dữ liệu tới vị trí của nó trong cơ sở dữ liệu và một chỉ mục vectơ để hỗ trợ truy vấn hiệu suất cao. Ngoài ra, phương pháp tìm kiếm kết hợp của nó sử dụng các vectơ dày đặc để hiểu ngữ cảnh của truy vấn và kết hợp nó với các vectơ thưa thớt để khớp từ khóa.
- Chroma: Chroma sử dụng thuật toán HNSW để hỗ trợ tìm kiếm kNN.
- Milvus: Milvus hỗ trợ nhiều chỉ mục trong bộ nhớ và phân vùng cấp bảng mang lại hiệu suất cao cần thiết cho các hệ thống truy xuất thông tin theo thời gian thực. Hỗ trợ RBAC là yêu cầu bắt buộc đối với các ứng dụng cấp doanh nghiệp. Đối với phân vùng, bằng cách giới hạn tìm kiếm trong một hoặc một số tập hợp con của cơ sở dữ liệu, phân vùng có thể cung cấp cách lọc dữ liệu hiệu quả hơn so với phân vùng tĩnh, vốn có thể gây tắc nghẽn và yêu cầu phân vùng lại khi dữ liệu vượt quá khả năng của máy chủ. Phân vùng là một cách tuyệt vời để quản lý dữ liệu của bạn bằng cách nhóm dữ liệu thành các tập hợp con dựa trên danh mục hoặc phạm vi thời gian. Điều này có thể giúp bạn dễ dàng lọc và tìm kiếm trong lượng lớn dữ liệu mà không cần phải tìm kiếm trong toàn bộ cơ sở dữ liệu mỗi lần. Không có loại Chỉ mục nào có thể phù hợp với tất cả các trường hợp sử dụng vì mỗi trường hợp sử dụng sẽ có sự cân bằng khác nhau. Với nhiều loại chỉ mục được hỗ trợ hơn, bạn có thể linh hoạt hơn để tìm sự cân bằng giữa độ chính xác, hiệu suất và chi phí.
- Faiss: FAISS là thuật toán hỗ trợ tìm kiếm kNN
So sánh tổng thể
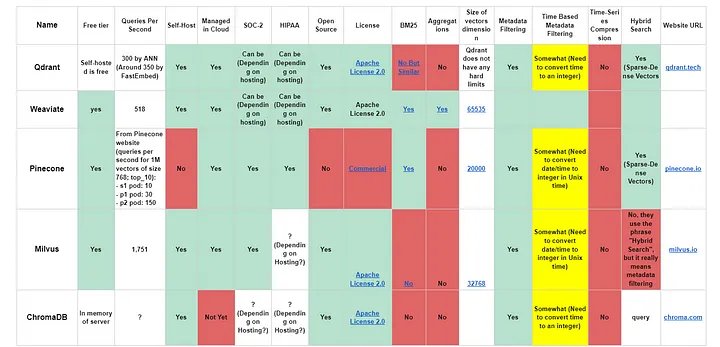
Tại sao tôi chọn Qdrant
Qdrant cung cấp dịch vụ sẵn sàng sản xuất được xây dựng bằng Rust, ngôn ngữ nổi tiếng về tính an toàn. Qdrant đi kèm với API thân thiện với người dùng được thiết kế để lưu trữ, tìm kiếm và quản lý Điểm có chiều cao (Điểm không là gì ngoài Vector nhúng) được làm giàu bằng siêu dữ liệu được gọi là tải trọng. Những tải trọng này trở thành những thông tin có giá trị, cải thiện độ chính xác của tìm kiếm và cung cấp dữ liệu sâu sắc cho người dùng. Nếu bạn đã quen thuộc với Cơ sở dữ liệu Vector khác như Chroma, thì Tải trọng tương tự như siêu dữ liệu; nó chứa thông tin về các vectơ.
Việc được viết bằng Rust khiến Qdrant trở thành một kho lưu trữ vectơ nhanh và đáng tin cậy ngay cả khi tải nặng. Điều khác biệt của Qdrant với các cơ sở dữ liệu khác là số lượng API máy khách mà nó cung cấp. Hiện tại Qdrant hỗ trợ Python, TypeSciprt/JavaScript, Rust và Go. Nó sử dụng HSNW (Biểu đồ thế giới nhỏ có thể điều hướng theo cấp bậc) để lập chỉ mục vectơ và đi kèm với nhiều số liệu khoảng cách như Cosine, Dot và Euclidean. Nó đi kèm với một API đề xuất ngay lập tức.
Một số điểm quan trọng khi xem xét Qdrant bao gồm:
- Được chế tạo bằng Rust, Qdrant đảm bảo cả tốc độ và độ tin cậy, ngay cả khi chịu tải nặng, khiến nó trở thành lựa chọn tốt nhất cho các cửa hàng vectơ hiệu suất cao.
- Điều làm nên sự khác biệt của Qdrant là sự hỗ trợ của nó dành cho các API máy khách, phục vụ cho các nhà phát triển bằng Python, TypeScript/JavaScript, Rust và Go.
- Qdrant tận dụng thuật toán HSNW và đưa ra các số liệu khoảng cách khác nhau, bao gồm Dot, Cosine và Euclidean, trao quyền cho các nhà phát triển chọn số liệu phù hợp với các trường hợp sử dụng cụ thể của họ.
- Qdrant chuyển đổi liền mạch sang đám mây bằng dịch vụ đám mây có thể mở rộng, cung cấp tùy chọn khám phá ở cấp độ miễn phí. Kiến trúc dựa trên nền tảng đám mây của nó đảm bảo hiệu suất tối ưu, bất kể khối lượng dữ liệu.
Ưu điểm của Qdrant
- Tìm kiếm tương tự hiệu quả – Qdrant được thiết kế đặc biệt cho các hoạt động tìm kiếm tương tự. Nó rất nhanh và chính xác để tìm các phần nhúng tương tự trên một lượng lớn dữ liệu.
- Khả năng mở rộng – Qdrant có khả năng mở rộng vì nó có thể xử lý hiệu quả khối lượng vectơ lớn.
- Dễ sử dụng – Cơ sở dữ liệu Qdrant cung cấp API thân thiện với người dùng giúp dễ dàng thiết lập, chèn dữ liệu và thực hiện các tìm kiếm tương tự.
- Nguồn mở – Qdrant là một dự án nguồn mở, có nghĩa là chúng tôi có quyền truy cập vào mã nguồn và có thể đóng góp vào sự phát triển của nó.
- Tính linh hoạt – Cơ sở dữ liệu Qdrant hỗ trợ Lược đồ linh hoạt, có nghĩa là chúng ta có thể xác định các loại trường vectơ khác nhau, đồng thời lưu trữ và tìm kiếm các loại dữ liệu khác nhau như hình ảnh, văn bản, âm thanh, v.v.
Kết luận
Qdrant là một công cụ mạnh mẽ có thể giúp các doanh nghiệp khai thác sức mạnh của việc nhúng ngữ nghĩa và cách mạng hóa việc tìm kiếm văn bản. Nó cung cấp một giải pháp đáng tin cậy và có thể mở rộng để quản lý dữ liệu nhiều chiều với hiệu suất truy vấn tuyệt vời và dễ tích hợp. Cơ sở dữ liệu nguồn mở của nó cho phép phát triển liên tục, sửa lỗi và cải tiến.
Qdrant cung cấp các tùy chọn triển khai linh hoạt (tự lưu trữ hoặc quản lý trên nền tảng đám mây), hiệu suất cao, không có giới hạn cứng về kích thước vectơ, lọc siêu dữ liệu, khả năng tìm kiếm kết hợp và phiên bản tự lưu trữ miễn phí.