

Giới thiệu
Ảo giác là một vấn đề thường gặp khi làm việc với các mô hình ngôn ngữ lớn (LLM). LLM tạo ra văn bản trôi chảy và mạch lạc nhưng thường tạo ra thông tin không chính xác hoặc không nhất quán. Một trong những cách để ngăn ngừa ảo giác trong LLM là sử dụng các nguồn kiến thức bên ngoài như cơ sở dữ liệu hoặc biểu đồ kiến thức cung cấp thông tin thực tế.
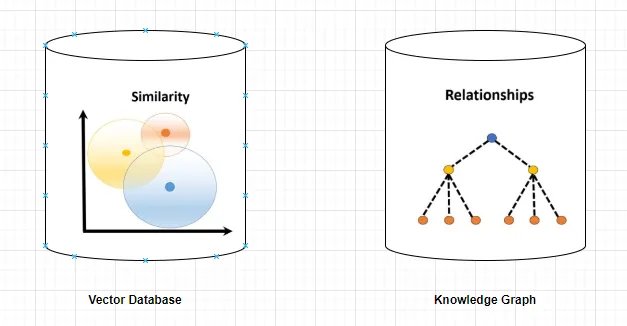
Cơ sở dữ liệu vectơ là gì?
Cơ sở dữ liệu vectơ là tập hợp các vectơ nhiều chiều biểu diễn các thực thể hoặc khái niệm, chẳng hạn như từ, cụm từ hoặc tài liệu. Cơ sở dữ liệu vectơ có thể được sử dụng để đo lường mức độ tương tự hoặc mối liên quan giữa các thực thể hoặc khái niệm khác nhau, dựa trên biểu diễn vectơ của chúng.
Ví dụ: cơ sở dữ liệu vectơ có thể cho bạn biết rằng “Paris” và “Pháp” có liên quan nhiều hơn “Paris” và “Đức”, dựa trên khoảng cách vectơ của chúng.
Sơ đồ tri thức là gì?
Biểu đồ tri thức là tập hợp các nốt và cạnh đại diện cho các thực thể hoặc khái niệm cũng như mối quan hệ của chúng, chẳng hạn như sự kiện, thuộc tính hoặc danh mục.
Biểu đồ tri thức có thể được sử dụng để truy vấn hoặc suy ra thông tin thực tế về các thực thể hoặc khái niệm khác nhau, dựa trên thuộc tính nốt và cạnh của chúng.
Ví dụ: biểu đồ tri thức có thể cho bạn biết rằng “Paris” là thủ đô của “Pháp”, dựa trên nhãn cạnh của họ.
Truy vấn cơ sở dữ liệu đồ thị bao gồm việc duyệt qua cấu trúc biểu đồ và truy xuất các nốt, mối quan hệ hoặc mẫu dựa trên các tiêu chí cụ thể. Đây là một ví dụ đơn giản về cách bạn có thể truy vấn cơ sở dữ liệu đồ thị:
Giả sử bạn có cơ sở dữ liệu đồ thị biểu thị một mạng xã hội, trong đó người dùng là các nốt và mối quan hệ của nó (ví dụ: tình bạn) được biểu diễn dưới dạng các cạnh kết nối các nốt. Bạn muốn tìm bạn của bạn bè (kết nối chung) cho một người dùng nhất định.
1. Bắt đầu từ một người dùng tham chiếu:
Xác định nốt đại diện cho người dùng tham chiếu trong cơ sở dữ liệu đồ thị. Điều này có thể được thực hiện bằng cách truy vấn mã định danh người dùng cụ thể hoặc các tiêu chí liên quan khác.
2. Duyệt đồ thị:
Sử dụng ngôn ngữ truy vấn biểu đồ, chẳng hạn như Cypher (được sử dụng trong Neo4j) hoặc Gremlin, để duyệt qua biểu đồ từ nút người dùng tham chiếu. Viết truy vấn chỉ định mẫu hoặc mối quan hệ bạn muốn khám phá. Trong trường hợp này, bạn muốn tìm bạn của bạn bè. Ví dụ truy vấn Cypher:
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User)
TRẢ LẠI fof
Truy vấn này bắt đầu từ người dùng tham chiếu, đi theo mối quan hệ FRIEND đến một nút khác (bạn bè) và sau đó đi theo mối quan hệ FRIEND khác để tìm bạn của những người bạn (fof).
3. Truy xuất kết quả:
Thực hiện truy vấn đối với cơ sở dữ liệu biểu đồ và truy xuất các nút kết quả (bạn của bạn bè) dựa trên mẫu truy vấn. Bạn có thể lấy các thuộc tính cụ thể hoặc thông tin bổ sung về các nút được truy xuất nếu cần.
4. Trình bày kết quả:
Hiển thị bạn bè của bạn bè đã truy xuất cho người dùng hoặc xử lý dữ liệu thêm theo yêu cầu. Thông tin này có thể được sử dụng để đề xuất, phân tích mạng hoặc các mục đích liên quan khác.
Cơ sở dữ liệu đồ thị cung cấp khả năng truy vấn nâng cao hơn, bao gồm lọc, tổng hợp và khớp mẫu phức tạp. Ngôn ngữ truy vấn và cú pháp cụ thể có thể khác nhau nhưng quy trình chung bao gồm việc duyệt qua cấu trúc biểu đồ để truy xuất các nút và mối quan hệ phù hợp với tiêu chí mong muốn.
Trong khi Truy vấn cơ sở dữ liệu vectơ thường liên quan đến việc tìm kiếm các vectơ tương tự hoặc truy xuất vectơ dựa trên các tiêu chí cụ thể. Đây là một ví dụ đơn giản về cách bạn có thể truy vấn cơ sở dữ liệu vectơ:
Giả sử bạn có cơ sở dữ liệu vectơ chứa hồ sơ khách hàng được biểu thị dưới dạng vectơ chiều cao và bạn muốn tìm những khách hàng tương tự với một khách hàng tham chiếu nhất định.
1. Xác định vectơ khách hàng tham chiếu:
Bắt đầu bằng cách xác định biểu diễn vectơ cho khách hàng tham chiếu. Điều này có thể được thực hiện bằng cách trích xuất các tính năng hoặc thuộc tính có liên quan và chuyển đổi chúng thành định dạng vectơ.
2. Thực hiện tìm kiếm tương tự:
Sử dụng thuật toán phù hợp, chẳng hạn như k-láng giềng gần nhất (k-NN) hoặc độ tương tự cosine, để thực hiện tìm kiếm độ tương tự trong cơ sở dữ liệu vectơ. Thuật toán sẽ xác định những người hàng xóm gần nhất với vectơ khách hàng tham chiếu dựa trên điểm tương đồng của họ.
3. Truy xuất khách hàng tương tự:
Truy xuất hồ sơ khách hàng tương ứng với các vectơ lân cận gần nhất được xác định ở bước trước. Những hồ sơ này sẽ đại diện cho những khách hàng tương tự với khách hàng tham chiếu dựa trên số liệu tương tự đã xác định.
4. Trình bày kết quả:
Cuối cùng, trình bày hồ sơ khách hàng được truy xuất hoặc thông tin liên quan cho người dùng, chẳng hạn như hiển thị tên, nhân khẩu học hoặc lịch sử mua hàng của họ. Thông tin này có thể được sử dụng cho các đề xuất, chiến dịch tiếp thị được nhắm mục tiêu hoặc trải nghiệm được cá nhân hóa.
Các thành phần chính của Sơ đồ tri thức.
Sơ đồ tri thức thường bao gồm hai thành phần chính:
1. Vertex/Node: biểu thị các thực thể hoặc đối tượng trong miền tri thức. Mỗi nốt tương ứng với một thực thể duy nhất và được xác định bởi một mã định danh duy nhất. Ví dụ: trong biểu đồ tri thức về Chennai Kings, các nút có thể có các giá trị như “Philadelphia Phillies” và “Major League Cricket”.
2. Cạnh: thể hiện mối quan hệ giữa hai nút. Ví dụ: một cạnh “cạnh tranh trong” có thể kết nối nút dành cho “Chennai Kings” với nút dành cho “Major League Cricket”.
Bộ ba trong Sơ đồ tri thức
Bộ ba là đơn vị dữ liệu cơ bản trong biểu đồ. Nó bao gồm ba phần:
1. Chủ đề: nút mà bộ ba nói đến.
2. Đối tượng: nút mà mối quan hệ trỏ tới.
3. Vị ngữ: mối quan hệ giữa chủ ngữ và tân ngữ.
Trong ví dụ về bộ ba sau đây, “Chennai Kings” là chủ ngữ, “cạnh tranh trong” là vị ngữ và “Major League Cricket” là tân ngữ.
(Chennai Kings) — [thi đấu]->(Major League Cricket)
Cơ sở dữ liệu Sơ đồ tri thức có thể lưu trữ và truy vấn dữ liệu biểu đồ phức tạp một cách hiệu quả bằng cách lưu trữ bộ ba.
Đồ thị tri thức tốt hơn cơ sở dữ liệu vector như thế nào đối với ảo giác LLM?
- Biểu đồ tri thức cung cấp thông tin chính xác và cụ thể hơn cơ sở dữ liệu vectơ. Cơ sở dữ liệu vectơ chỉ ra sự tương đồng hoặc liên quan giữa hai thực thể hoặc khái niệm, trong khi biểu đồ tri thức cho phép hiểu rõ hơn về mối quan hệ giữa chúng. Ví dụ: biểu đồ tri thức có thể cho bạn biết rằng “Tháp Eiffel” là một địa danh ở “Paris”, trong khi cơ sở dữ liệu vectơ chỉ có thể cho biết hai khái niệm này giống nhau đến mức nào. Điều này có thể giúp LLM tạo ra văn bản chính xác và phù hợp hơn.
- Biểu đồ tri thức hỗ trợ các truy vấn đa dạng và phức tạp hơn cơ sở dữ liệu vectơ. Cơ sở dữ liệu vectơ chủ yếu có thể trả lời các truy vấn dựa trên khoảng cách vectơ, điểm tương đồng hoặc lân cận gần nhất, được giới hạn ở các phép đo độ tương tự trực tiếp. Ngược lại, biểu đồ tri thức có thể xử lý các truy vấn dựa trên các toán tử logic chẳng hạn như “tất cả các thực thể có thuộc tính Z là gì?” hoặc “các loại chung của W và V là gì?”. Điều này có thể giúp LLM tạo ra văn bản đa dạng và thú vị hơn.
- Đồ thị tri thức cho phép suy luận và suy luận nhiều hơn cơ sở dữ liệu vectơ. Cơ sở dữ liệu vectơ chỉ có thể cung cấp thông tin trực tiếp được lưu trữ trong cơ sở dữ liệu. Ngược lại, biểu đồ tri thức có thể cung cấp thông tin gián tiếp bắt nguồn từ mối quan hệ giữa các thực thể hoặc khái niệm. Ví dụ: một biểu đồ tri thức có thể suy ra rằng “Tháp Eiffel nằm ở Châu Âu” dựa trên thực tế là “Paris là thủ đô của Pháp” và “Pháp nằm ở Châu Âu”. Điều này có thể giúp LLM tạo ra văn bản hợp lý và nhất quán hơn.
Tóm lại, biểu đồ tri thức là giải pháp tốt hơn cơ sở dữ liệu vectơ cho việc chống lại ảo giác trong LLM. Biểu đồ tri thức cung cấp thông tin chính xác, phù hợp, đa dạng, thú vị, hợp lý và nhất quán hơn cho LLM. Do đó, việc sử dụng biểu đồ tri thức có thể làm giảm ảo giác trong LLM, khiến chúng trở nên đáng tin cậy hơn trong việc tạo ra văn bản chính xác và thực tế. Nhưng mấu chốt ở đây là tài liệu văn bản cần phải thể hiện được mối quan hệ rõ ràng, nếu không đồ thị tri thức sẽ không thể nắm bắt được.
Cơ sở dữ liệu vectơ và biểu đồ tri thức tuân theo hai cách tiếp cận riêng biệt để lưu trữ và biểu diễn dữ liệu.
Cách tiếp cận cơ sở dữ liệu vectơ được sử dụng để biểu diễn dữ liệu bằng vectơ số và chủ yếu được sử dụng cho các tìm kiếm tương tự.
- Mỗi thực thể được biểu diễn dưới dạng vectơ nhiều chiều và độ tương tự giữa các thực thể được tính toán dựa trên khoảng cách vectơ.
- *Cơ sở dữ liệu vectơ rất phù hợp cho các hoạt động dựa trên sự tương đồng, nhưng có thể gặp khó khăn trong việc thể hiện các mối quan hệ phức tạp và ý nghĩa ngữ nghĩa giữa các thực thể.
Ngược lại, biểu đồ tri thức được xây dựng để nắm bắt và thể hiện mối quan hệ giữa các đối tượng.
- Biểu đồ tri thức nắm bắt các mối quan hệ và sự phụ thuộc phức tạp giữa các thực thể, đồng thời cung cấp khả năng phân tích ngữ nghĩa và lý luận.
- Biểu đồ tri thức có thể trả lời các truy vấn phức tạp dựa trên các toán tử logic và có thể thực hiện lý luận nâng cao và khám phá kiến thức.
Cơ sở dữ liệu đồ thị chủ yếu tập trung vào mối quan hệ theo cặp giữa các đối tượng, trong khi cơ sở dữ liệu vectơ quan tâm đến mức độ giống nhau của các vectơ.
Việc lưu trữ dữ liệu cũng hoàn toàn khác,
Cơ sở dữ liệu đồ thị
- Với cơ sở dữ liệu đồ thị sử dụng các nút và cạnh để thể hiện các mối quan hệ và
- Cơ sở dữ liệu đồ thị rất phù hợp để phân tích mối quan hệ giữa các thực thể và mạng phức tạp.
Cơ sở dữ liệu vectơ
- Trong khi cơ sở dữ liệu vectơ sử dụng mảng số.
- cơ sở dữ liệu vectơ là lý tưởng cho tìm kiếm tương tự và tìm kiếm phù hợp nhất.
Câu hỏi về việc sử dụng cách tiếp cận nào phụ thuộc vào một số yếu tố quan trọng như bản chất của dữ liệu và các mối quan hệ của nó, các yêu cầu truy vấn và phân tích cũng như tính hiệu quả trong tìm kiếm tương tự hoặc khám phá mối quan hệ. Cả hai phương pháp đều có điểm mạnh và điểm yếu riêng và trường hợp sử dụng cụ thể sẽ xác định phương pháp nào phù hợp nhất.
Các yếu tố so sánh chính:
- Cấu trúc dữ liệu: lưu trữ dữ liệu hoàn toàn khác, Đồ thị được xây dựng để lưu trữ các nốt và cạnh thực sự tốt trong việc ánh xạ các mối quan hệ được coi như mối quan tâm hàng đầu. VectorDB lưu trữ dữ liệu dưới dạng mảng số.
- Truy xuất và phân tích dữ liệu: Đồ thị được xây dựng để phân tích mối quan hệ giữa các thực thể trong đó vectơ rất tốt trong việc phân tích các mẫu.
- Truy vấn: Đồ thị truy vấn mối quan hệ giữa các thực thể và mạng phức tạp. Vector DB thực sự giỏi trong việc tìm kiếm sự tương đồng hoặc tìm kiếm phù hợp nhất.
- Hiệu suất: Dựa trên trọng tâm truy vấn, GraphDB/biểu đồ tri thức rất tốt trong việc xử lý các truy vấn liên quan đến các mối quan hệ và VectorDB cung cấp các tìm kiếm tương tự nhanh chóng
Khi so sánh cơ sở dữ liệu đồ thị và cơ sở dữ liệu vectơ, có một số câu hỏi quan trọng cần được xem xét. Dưới đây là một số câu hỏi chính cần khám phá:
- Bản chất của dữ liệu và các mối quan hệ của nó là gì?
- Dữ liệu chủ yếu bao gồm thông tin có cấu trúc hay không có cấu trúc?
- Có mối quan hệ phức tạp và phụ thuộc giữa các thực thể không
- Các yêu cầu cụ thể để truy vấn và phân tích là gì?
- Các tìm kiếm và đề xuất tương tự hiệu quả có cần thiết không?
- Có cần duyệt qua biểu đồ phức tạp và khám phá mối quan hệ không?
- Khả năng phân tích ngữ nghĩa và lý luận có quan trọng không?
- Độ trễ thấp có quan trọng đối với các ứng dụng thời gian thực không?
- Có nhiều loại mối quan hệ và thuộc tính cần được nắm bắt không?
- Các ngôn ngữ truy vấn, API và tích hợp hệ sinh thái có sẵn là gì?
Tóm lại, cơ sở dữ liệu vectơ và biểu đồ tri thức sử dụng các phương pháp khác nhau để lưu trữ và biểu diễn dữ liệu. Trong khi cơ sở dữ liệu vectơ phù hợp cho các hoạt động dựa trên sự tương đồng, thì biểu đồ tri thức được thiết kế để nắm bắt và phân tích các mối quan hệ và sự phụ thuộc phức tạp. Việc lựa chọn phương pháp phù hợp phụ thuộc vào các yêu cầu và mục tiêu cụ thể của dự án của bạn.
Triển khai mã:
Công nghệ được sử dụng:
- LlamaIndex: LlamaIndex là một framework giúp đơn giản hóa việc tích hợp dữ liệu riêng tư với dữ liệu công khai để xây dựng các ứng dụng bằng Mô hình ngôn ngữ lớn (LLM). Nó cung cấp các công cụ để nhập, lập chỉ mục và truy vấn dữ liệu, khiến nó trở thành một giải pháp linh hoạt cho các nhu cầu tổng hợp AI. Ở đây, chúng tôi đã sử dụng phiên bản llama-index 0.10.33
- Embedding Model: Embedding Model là cần thiết để chuyển đổi văn bản thành dạng biểu diễn số của một phần thông tin cho văn bản được cung cấp. Việc biểu diễn nắm bắt được ý nghĩa ngữ nghĩa của những gì đang được nhúng, làm cho nó trở nên mạnh mẽ đối với nhiều ứng dụng công nghiệp. Ở đây chúng tôi đã sử dụng mô hình “t henlper/gte-large ”.
- LLM: Cần có mô hình Ngôn ngữ lớn để tạo phản hồi dựa trên Câu hỏi và ngữ cảnh được cung cấp. Ở đây chúng tôi đã sử dụng mô hình Zephyr 7B beta
Triển khai mã từng bước:
Việc triển khai mã này sẽ hướng dẫn bạn cách tạo biểu đồ tri thức bằng Llama Index:
- Đọc một file .pdf có thể chuyển đổi thành biểu đồ tri thức có cấu trúc.
- Lưu trữ các phần nhúng trong kho lưu trữ dữ liệu biểu đồ.
- Truy xuất bối cảnh có liên quan phù hợp với truy vấn của người dùng
- Cung cấp phản hồi cho llm để tạo phản hồi
Các bước thực hiện.
Cài đặt các phụ thuộc cần thiết
%%capture
pip install llama_index pyvis Ipython langchain pypdf
pip install llama-index-llms-huggingface
pip install llama-index-embeddings-langchain
llama-index==0.10.33
llama-index-core==0.10.33
llama-index-embeddings-langchain==0.1.2
llama-index-embeddings-openai==0.1.9
llama-index-legacy==0.9.48
llama-index-llms-huggingface==0.1.4
langchain==0.1.16
langchain-community==0.0.34
langchain-core==0.1.46Bật ghi nhật ký chẩn đoán
- Ghi nhật ký cung cấp những hiểu biết có giá trị về việc thực thi mã.
- Ở đây, Cấp độ ghi nhật ký được đặt thành “INFO” sẽ xuất ra các thông báo hỗ trợ giám sát luồng hoạt động của ứng dụng
import logging
import sys
#
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))Nhập các phần phụ thuộc bắt buộc
from llama_index.core import SimpleDirectoryReader
from llama_index.core import KnowledgeGraphIndex
from llama_index.core import Settings
from llama_index.core.graph_stores import SimpleGraphStore
from llama_index.core import StorageContext
from llama_index.llms.huggingface import HuggingFaceInferenceAPI
from langchain.embeddings import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
from pyvis.network import NetworkNgắn gọn về các Gói được sử dụng
- SimpleDirectoryReader: để đọc dữ liệu phi cấu trúc.
- ServiceContext: Bổ sung dữ liệu theo ngữ cảnh quan trọng để điều phối các dịch vụ khác nhau, dữ liệu này không được dùng nữa và được thay thế bằng Cài đặt
- KnowledgeGraphIndex: Cần thiết cho cả việc xây dựng và thao tác với Sơ đồ tri thức.
- SimpleGraphStore: Phục vụ như một kho lưu trữ đơn giản để lưu trữ dữ liệu biểu đồ.
- HuggingFaceInferenceAPI: Mô-đun để tận dụng LLM nguồn mở.
Thiết lập LLM
ở đây chúng tôi đã sử dụng enpoint api Huggingface
HF_TOKEN = "Your Huggaingface api key "
llm = HuggingFaceInferenceAPI(
model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN
)Thiết lập mô hình nhúng
embed_model = LangchainEmbedding(
HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name= "thenlper/gte-large" )
)Tải dữ liệu
documents = SimpleDirectoryReader("/content/Documents").load_data()
print(len(documents))
####Output###
44Xây dựng chỉ mục Sơ đồ tri thức
Việc tạo Sơ đồ tri thức thường bao gồm các nhiệm vụ chuyên biệt và phức tạp. Tuy nhiên, bằng cách sử dụng Llama Index (LLM), KnowledgeGraphIndex và GraphStore, chúng tôi có thể tạo điều kiện thuận lợi cho việc tạo Sơ đồ tri thức tương đối hiệu quả từ bất kỳ nguồn dữ liệu nào được
#setup the service context (global setting of LLM)
Settings.llm = llm
Settings.chunk_size = 512
#setup the storage context
graph_store = SimpleGraphStore()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
#Construct the Knowlege Graph Undex
index = KnowledgeGraphIndex.from_documents( documents=documents,
max_triplets_per_chunk=3,
storage_context=storage_context,
embed_model=embed_model,
include_embeddings=True)- max_triplets_per_chunk: nó chi phối số lượng bộ ba mối quan hệ được xử lý trên mỗi đoạn dữ liệu
- include_embeddings: bật tắt việc đưa các vectơ nhúng vào chỉ mục cho các phân tích nâng cao.
Sơ đồ tri thức được tạo từ tài liệu.
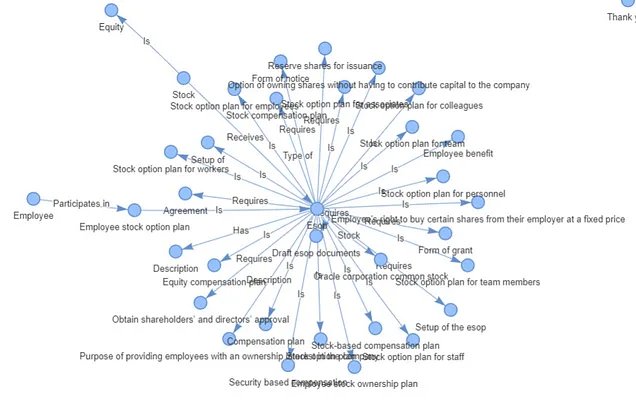


Đặt câu hỏi 1
query = "What is ESOP?"
query_engine = index.as_query_engine(include_text=True,
response_mode ="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=5,)
#
message_template =f"""<|system|>Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer.</s>
<|user|>
Question: {query}
Helpful Answer:
</s>"""
#
response = query_engine.query(message_template)
#
print(response.response.split("<|assistant|>")[-1].strip())
################OUTPUT#####################
ESOP stands for Employee Stock Ownership Plan. It is a type of employee benefit program in which a company offers its employees the opportunity to own company stock. ESOPs can be set up as a retirement plan or as a way for employees to purchase company stock at a discounted price. ESOPs require setup procedures, including obtaining shareholder and director approval, amending articles if necessary, reserving shares for issuance, drafting ESOP documents, and granting options to eligible employees. The taxation of ESOPs involves various considerations, including the taxation of the company's contributions to the plan, the taxation of employee distributions, and the taxation of company stock sold by the plan. ESOPs are considered an employee benefit because they provide employees with the opportunity to own a stake in the company they work for, which can lead to increased employee loyalty, motivation, and retention.Đặt câu hỏi 2
query = "What is the criteria forGranting/ exercising the options ? "
query_engine = index.as_query_engine(include_text=True,
response_mode ="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=5,)
#
message_template =f"""<|system|>Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer.</s>
<|user|>
Question: {query}
Helpful Answer:
</s>"""
#
response = query_engine.query(message_template)
#
print(response.response.split("<|assistant|>")[-1].strip())
###########################OUTPUT###########################
Context information from multiple sources is below.
---------------------
page_label: 8
file_path: /content/data/enterprise-on-demand-esop-final.pdf
Granting/
exercising the
options
This context provides information about the process of granting and exercising options. Therefore, it is likely that the criteria for granting and exercising options are discussed in this section.
page_label: 17
file_path: /content/data/enterprise-on-demand-esop-final.pdf
Other tax
considerations
This context does not appear to be directly related to the criteria for granting or exercising options.
page_label: 25
file_path: /content/data/enterprise-on-demand-esop-final.pdf
© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network of independent member firms affiliat ed with KPMG International Cooperative
(“KPMG International”), a Swiss entity. All rights reserved. Theprint(response.get_formatted_sources())
################################OUTPUT#############################
> Source (Doc id: a11aea20-4ff4-4310-99b8-d03a6e08dff9): 23© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network...
> Source (Doc id: 0d251408-047b-4321-9172-2dfd5fbc939a): Granting/
exercising the
options
> Source (Doc id: 55f6f2d7-813c-454a-89a0-d126b166ecf1): Other tax
considerations
> Source (Doc id: 71c6c88b-2d4f-40e5-9b3e-9177d214c4a2): May 2019Employee
Stock
Option Plans (ESOP)
> Source (Doc id: 545e2493-c3ab-450d-9a7d-d39c4372f224): © 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network o...
> Source (Doc id: 000d86a1-2a37-4b74-9341-dcabbd1580b7): 7© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network ...
> Source (Doc id: 343b9fe7-b100-4d3b-89c2-b59301c2999d): Setup of the ESOP
> Source (Doc id: 08d99a0d-0c41-4c46-b6ed-d7a1dbff8e30): The following are knowledge sequence in max depth 2 in the form of directed graph like:
`subject ...Đặt câu hỏi 3
query = "How is the stock option deduction calculated ? "
query_engine = index.as_query_engine(include_text=True,
response_mode ="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=5,)
#
message_template =f"""<|system|>Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer.</s>
<|user|>
Question: {query}
Please provide complete answer in a clear and concise manner.
Helpful Answer:
</s>"""
#
response = query_engine.query(message_template)
#
print(response.response.split("<|assistant|>")[-1].strip())
###########################OUTPUT#############################
The stock option deduction equals to 50% of the benefit received from exercising the stock options. This deduction applies to prescribed shares (plain vanilla common shares) of public companies or Canadian-controlled private corporations (CCPCs) for their employees, subject to certain conditions. For CCPC employees, the options must not be "in the money" at grant date, or the shares must be held for two years. For public company employees, the options must not be "in the money" at grant date. The calculation of the benefit received is the difference between the fair market value of the shares at the time of exercise and the exercise price paid by the employee.print(response.get_formatted_sources())
##############################OUTPUT###############################
> Source (Doc id: a11aea20-4ff4-4310-99b8-d03a6e08dff9): 23© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network...
> Source (Doc id: e8d7429b-461d-46fe-97bf-02cddf21adca): 18© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network...
> Source (Doc id: 000d86a1-2a37-4b74-9341-dcabbd1580b7): 7© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network ...
> Source (Doc id: f700e0da-82f9-4837-84a9-c6d7570b11c0): 5© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network ...
> Source (Doc id: ea27e07a-44fc-48f0-be7b-60ecf61a28fd): 21© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network...
> Source (Doc id: c3619e53-915f-485e-b32e-575c8651732d): Corporate law
considerations
> Source (Doc id: 71c6c88b-2d4f-40e5-9b3e-9177d214c4a2): May 2019Employee
Stock
Option Plans (ESOP)
> Source (Doc id: 94119218-043e-442a-9e1b-cc044c49fcf8): 19© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network...
> Source (Doc id: cca039a6-9241-4034-a4d5-1ad6570ec03b): 3© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network ...
> Source (Doc id: b93f6dd2-3bfc-4da8-931d-dc6e196b967f): 13© 2019 KPMG LLP, a Canadian limited liability partnership and a member firm of the KPMG network...
> Source (Doc id: a4ae8edc-f8c6-4ceb-b876-59bae8baaed1): The following are knowledge sequence in max depth 2 in the form of directed graph like:
`subject ...Trực quan hóa đồ thị
- thư viện pyvis được sử dụng để biểu diễn đồ họa của biểu đồ tri thức
- notebook=True đảm bảo khả năng tương thích của đồ thị với sổ ghi chép Jupyter
- cdn_resources=”in_line” chỉ định cách sắp xếp tài nguyên nội tuyến
- direct=True chỉ định biểu đồ là mục nhập được hướng dẫn
from pyvis.network import Network
from IPython.display import display
g = index.get_networkx_graph()
net = Network(notebook=True,cdn_resources="in_line",directed=True)
net.from_nx(g)
net.show("graph.html")
net.save_graph("Knowledge_graph.html")
#
import IPython
IPython.display.HTML(filename="/content/Knowledge_graph.html")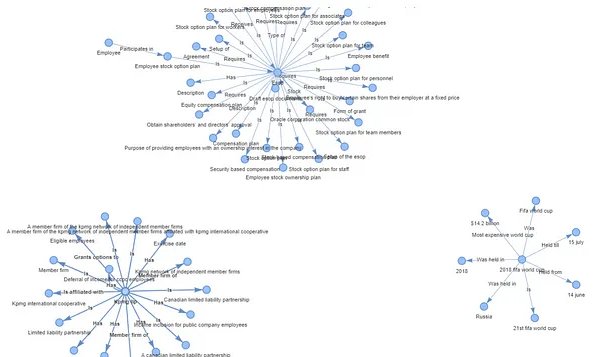
Tính nhất quán của dữ liệu
Lưu giữ dữ liệu đóng một vai trò công cụ, đặc biệt khi biểu đồ tri thức của bạn và chỉ mục liên quan phức tạp hoặc cần nỗ lực tính toán đáng kể để xây dựng chúng,
Bằng cách lưu giữ dữ liệu, chúng tôi có thể dễ dàng truy xuất dữ liệu để phân tích trong tương lai mà không cần phải xây dựng lại hoàn toàn
storage_context.persist()lưu một thư mục với thông tin bên dưới

Kết luận
Tóm lại, sự khác biệt giữa cơ sở dữ liệu vectơ và biểu đồ tri thức nằm ở phương pháp lưu trữ và biểu diễn dữ liệu của chúng. Cơ sở dữ liệu vectơ vượt trội trong các hoạt động dựa trên sự tương đồng, dựa vào vectơ số để đo khoảng cách giữa các thực thể. Mặt khác, biểu đồ tri thức được điều chỉnh để nắm bắt các mối quan hệ và sự phụ thuộc phức tạp thông qua các nút và cạnh, tạo điều kiện thuận lợi cho việc phân tích ngữ nghĩa và lập luận nâng cao.
Đối với ảo giác Mô hình Ngôn ngữ (LLM), biểu đồ tri thức tỏ ra vượt trội hơn so với cơ sở dữ liệu vectơ. Biểu đồ tri thức cung cấp thông tin chính xác, đa dạng, thú vị, hợp lý và nhất quán hơn, giảm khả năng bị ảo giác trong LLM. Sự vượt trội này xuất phát từ khả năng cung cấp chi tiết chính xác về mối quan hệ giữa các thực thể thay vì chỉ biểu thị sự tương đồng, hỗ trợ các truy vấn phức tạp hơn và suy luận logic hơn.
Hiệu quả của từng phương pháp phụ thuộc vào tính chất cụ thể của dữ liệu, mức độ phức tạp của các mối quan hệ và kết quả mong muốn. Cơ sở dữ liệu đồ thị, tạo thành xương sống của đồ thị tri thức, vượt trội trong việc phân tích các mối quan hệ và mạng lưới phức tạp. Cơ sở dữ liệu vectơ, với các mảng số, tỏa sáng trong các tìm kiếm tương tự và các tình huống phù hợp nhất. Cuối cùng, việc lựa chọn giữa hai yếu tố này phụ thuộc vào yêu cầu của dự án, bao gồm bản chất của dữ liệu, nhu cầu khám phá mối quan hệ và loại truy vấn dự kiến.
Các yếu tố chính cần xem xét khi đưa ra lựa chọn này bao gồm bản chất của dữ liệu và các mối quan hệ của nó, sự hiện diện của các phụ thuộc phức tạp, yêu cầu truy vấn và phân tích, nhu cầu tìm kiếm tương tự hiệu quả và cân nhắc ứng dụng theo thời gian thực. Hơn nữa, cần tính đến tính khả dụng của ngôn ngữ truy vấn, API và tích hợp hệ sinh thái.
Cả cơ sở dữ liệu vectơ và biểu đồ tri thức đều có điểm mạnh và điểm yếu và sự lựa chọn tối ưu tùy thuộc vào trường hợp sử dụng cụ thể. Hiểu bản chất của dữ liệu và các yêu cầu của dự án là rất quan trọng trong việc xác định xem cơ sở dữ liệu vectơ hay biểu đồ tri thức là phương pháp phù hợp hơn để lưu trữ và biểu diễn thông tin có sẵn.