


Tác giả: Pier Paolo Ippolito
Xuất bản trên Towards Data Science
Giới thiệu
Kể từ khi ChatGPT trỗi dậy, các Mô hình Ngôn ngữ Lớn (LLMs) đã trở nên ngày càng phổ biến hơn đối với cả những người không chuyên về công nghệ. Tuy nhiên, LLMs một mình chưa thể cung cấp một sản phẩm hoàn chỉnh sẵn sàng để phục vụ cho một đối tượng khán giả rộng lớn. Như một phần của bài viết này, chúng tôi sẽ đề cập đến một số yếu tố chính được sử dụng để làm cho LLMs sẵn sàng cho sản xuất.
Tinh chỉnh
Bộ dữ liệu
Các mô hình như LLAMA có khả năng dự đoán các token tiếp theo trong một chuỗi, tuy nhiên điều này không nhất thiết làm cho chúng phù hợp cho các nhiệm vụ như trả lời câu hỏi. Do đó, để tối ưu hóa các mô hình này, có thể sử dụng các loại bộ dữ liệu khác nhau:
- Hoàn thành nguyên bản: nếu mục tiêu là dự đoán token tiếp theo, chúng ta cung cấp một số văn bản đầu vào và cho phép mô hình dự đoán các bước tiếp theo dần dần.
- Điền vào mục tiêu ở giữa: trong trường hợp này, chúng ta có một số văn bản bắt đầu và kết thúc và mô hình đang học để điền vào khoảng trống. Phương pháp này khá phổ biến để tạo ra các mô hình hoàn thành mã như Codex.
- Bộ dữ liệu hướng dẫn: mục tiêu ở đây là dạy mô hình cách trả lời câu hỏi. Chúng ta có câu hỏi (hướng dẫn) làm đầu vào và câu trả lời làm đầu ra.
- Bộ dữ liệu ưu tiên: thường được sử dụng với Học tăng cường để xếp hạng các câu trả lời khả thi khác nhau cho một câu hỏi. Trong trường hợp này, có thể có nhiều câu trả lời hợp lý cho một câu hỏi và mục tiêu là tìm ra kết quả tốt nhất.
- Bộ dữ liệu phân loại: Bằng cách thêm một phần đầu cuối phân loại và tinh chỉnh LLMs với một bộ dữ liệu phân loại, chúng ta cuối cùng có thể làm cho mô hình hoạt động như một bộ phân loại.
Các Kỹ thuật
Có hai phương pháp chính để tinh chỉnh LLMs: Tinh chỉnh được Giám sát và Học tăng cường từ Phản hồi của Con người.
- Tinh chỉnh được Giám sát: LLM được huấn luyện trên một tập hợp các cặp đầu vào-đầu ra và các trọng số được điều chỉnh lặp lại để giảm thiểu sự khác biệt giữa dự đoán và đầu ra thực tế. Các tập hợp nhỏ chất lượng cao của các cặp đầu vào-đầu ra có thể dẫn đến cải tiến lớn của mô hình so với các tập hợp lớn không được sắp xếp cẩn thận hơn. Ba tùy chọn phổ biến nhất để thực hiện tinh chỉnh được giám sát là: tinh chỉnh đầy đủ, LoRA, và LoRA được lượng tử hóa.
- Học tăng cường từ Phản hồi của Con người: LLM học bằng cách tương tác với môi trường và nhận phản hồi. Mục tiêu là tối đa hóa phần thưởng tổng thể, trong trường hợp này được cung cấp bởi các nhà đánh giá con người đánh giá các dự đoán.
Nếu được thiết kế đúng cách, Học tăng cường từ Phản hồi của Con người thường có thể mang lại kết quả tốt hơn so với Tinh chỉnh được Giám sát tuy nhiên có thể khó để thiết lập đúng (ví dụ: hệ thống phần thưởng) và đảm bảo phản hồi của con người luôn nhất quán. Do đó, một phần lớn sự tập trung nghiên cứu hiện tại đang được đặt vào việc phát triển các cơ chế học ưu tiên trên các mô hình Tinh chỉnh được Giám sát.
Chiến lược Giải mã
Chiến lược Giải mã của LLMs là một trong những tham số chính được bỏ qua nhất để quyết định văn bản sẽ được tạo ra. Có 4 loại chiến lược Giải mã chính đang được sử dụng:
- Tìm kiếm Greedy: token có khả năng cao nhất luôn được chọn làm token tiếp theo được lựa chọn. Phương pháp này tối đa hóa do đó phần thưởng ngắn hạn qua kết quả dài hạn, làm cho việc tìm ra giá trị cực đại toàn cầu trở nên khó khăn. Với Tìm kiếm Greedy, thực tế, chúng ta không quan tâm đến việc tính toán các chuỗi từ khả năng có thể khác nhau và chọn ra chuỗi tốt nhất mà chỉ đơn giản là chọn từ có khả năng cao nhất ở mỗi bước. Tuy nhiên, điều này làm cho phương pháp này trở nên hiệu quả tính toán và nhanh chóng.
- Lấy mẫu Top-k: cải thiện Tìm kiếm Greedy, chúng ta có thể tận dụng phân phối xác suất được tạo ra bởi LLM khi dự đoán token tiếp theo bằng cách chọn K token có khả năng cao nhất và lấy mẫu một token từ đó làm lựa chọn của chúng ta. Bằng cách này, chúng ta có thể làm cho chuỗi đầu ra của chúng ta ít dễ đoán hơn. Một cách khác để tăng tính ngẫu nhiên là bằng cách biến đổi thông số Nhiệt độ (do đó làm thay đổi xác suất).
- Lấy mẫu Nucleus: một cách khác để tận dụng các xác suất là thay vào đó sắp xếp các token theo khả năng của chúng và giữ lại N token đầu tiên có tổng giá trị xác suất được chọn (ví dụ: giữ lại các token hàng đầu mà tổng xác suất của chúng cộng lại đến 90%). Kết quả có thể được lựa chọn bằng cách lấy mẫu ngẫu nhiên từ danh sách này. Bởi vì xác suất được sử dụng để xác định độ dài của danh sách, việc áp dụng phương pháp này có thể dẫn đến sự biến đổi lớn hơn trong đầu ra.
- Tìm kiếm Beam: trong trường hợp này, chúng ta tạo ra N “bước sóng” của các token có khả năng cao nhất. Độ dài của mỗi chuỗi sau đó có thể được xác định bởi một độ dài tối đa hoặc token kết thúc câu. Bước sóng có điểm số cao nhất sau đó được chọn làm chuỗi lựa chọn.
Triển khai LLMs Hiệu quả
Hai trong số các rào cản chính của LLMs là yêu cầu về bộ nhớ/ tính toán và khả năng song song thấp (ví dụ: sinh đầu ra tự động).
Một phương pháp phổ biến để giải quyết vấn đề đầu tiên là sử dụng tỉ lệ giảm (giảm độ chính xác của các tham số của LLMs xuống ví dụ 8 hoặc 4 bit). Có 2 phương pháp chính để thực hiện tỉ lệ giảm: Tỉ lệ Giảm sau Huấn luyện (PTQ) và Huấn luyện Nhận thức về Tỉ lệ (QAT). Với PTQ, chúng ta lấy các trọng số của một mô hình đã được huấn luyện trước và giảm độ chính xác của chúng. Trong QAT, chúng ta thực hiện quá trình tỉ lệ giảm trực tiếp trong quá trình huấn luyện/tinh chỉnh. Điều này tất nhiên tốn kém hơn để thực hiện nhưng thường cũng mang lại kết quả chính xác tốt hơn. Thông tin chi tiết về các kỹ thuật tỉ lệ giảm có thể được tìm thấy trong bài viết này. Ngoài tỉ lệ giảm, cũng có thể áp dụng cắt tỉa LLM (có cấu trúc/không cấu trúc) hoặc chưng cất.
Để cải thiện các vấn đề về khả năng song song thấp, chúng ta có thể tập trung chủ yếu vào việc cải thiện kiến trúc của LLMs. Một số phương pháp phổ biến bao gồm: Sự Chú Ý Đa Truy Vấn, Sự Chú Ý Truy Vấn Nhóm, Nhúng Điều Chỉnh, vv… Cuối cùng, độ trễ của LLMs nói chung có thể được giảm bằng cách tăng tính thưa thớt (ví dụ: Tích hợp các chuyên gia, Cắt tỉa có cấu trúc), hợp nhất các toán tử liền kề và lưu trữ cache (ví dụ: lưu các khóa/giá trị trung gian của các lớp chú ý).
Guardrails
Do các LLM được huấn luyện trên nhiều dữ liệu có sẵn công khai trên internet, chúng có thể tiềm ẩn khả năng được sử dụng để thực hiện các nhiệm vụ độc hại như việc hỗ trợ thực hiện các hình thức tội phạm khác nhau. Ngoài ra, các LLM cũng được huấn luyện đặc biệt để hỗ trợ người dùng (kể cả khi họ có thể không có câu trả lời đúng) và do đó có thể tạo ra những ảo tưởng. Để tránh những vấn đề này, các nhà cung cấp LLM được quản lý đã thực hiện triển khai các hình thức rào cản khác nhau để điều hướng LLM theo hướng đúng.
Rào cản có thể được áp dụng ở đầu vào (báo cáo nội dung độc hại trước khi thực sự hiển thị cho LLM) hoặc đầu ra (kiểm tra phản hồi của LLM trước khi hiển thị cho người dùng). Quan trọng là nhận thấy rằng mỗi khi chúng ta thêm bất kỳ loại rào cản nào, chúng ta đều đang giới thiệu độ trễ và tăng tổng chi phí của việc trả lời một truy vấn (Xem Hình 1).
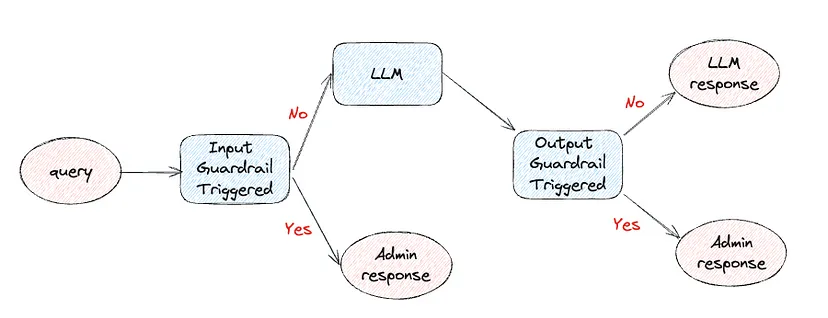
Một số ví dụ về nơi có thể áp dụng rào cản đầu vào là: xác định các câu hỏi không liên quan và chuyển hướng người dùng để chỉ đặt câu hỏi phù hợp, ngăn chặn các cố gắng phá vỡ hạn chế ghi đè lên lời nhắc, tránh tiêm mã độc (ví dụ: người dùng yêu cầu LLM xác nhận/thực thi một số mã độc hại).
Một cách để giảm độ trễ khi làm việc với rào cản đầu vào là kích hoạt bất đồng bộ kiểm tra rào cản và cuộc gọi LLM và trả lại kiểm tra rào cản nếu được kích hoạt thay vì đầu ra của LLM.
Cuối cùng, một số ví dụ về rào cản đầu ra bao gồm:
- Ngăn chặn ảo tưởng bằng cách cung cấp cho LLM một số ngữ cảnh bổ sung về truy vấn hoặc về các ví dụ trước đó của các phản ứng ảo tưởng để không lặp lại.
- Kiểm tra xem cú pháp đầu ra có nhất quán không (ví dụ: mã được cung cấp có thể thực thi, đầu ra JSON/CSV có cấu trúc tốt, vv.)
- Giới thiệu các quy định đầu ra để phù hợp với nhận diện thương hiệu và chính sách cụ thể của công ty cung cấp các dịch vụ được hỗ trợ bởi LLM.
Triển khai LLMs Hiệu quả
Hai trong số các rào cản chính của LLMs là yêu cầu về bộ nhớ/tính toán và khả năng song song thấp (ví dụ: sinh đầu ra tự động).
Một phương pháp phổ biến để giải quyết vấn đề đầu tiên là sử dụng tỉ lệ giảm (giảm độ chính xác của các tham số của LLMs xuống ví dụ 8 hoặc 4 bit). Có 2 phương pháp chính để thực hiện tỉ lệ giảm: Tỉ lệ Giảm sau Huấn luyện (PTQ) và Huấn luyện Nhận thức về Tỉ lệ (QAT). Với PTQ, chúng ta lấy các trọng số của một mô hình đã được huấn luyện trước và giảm độ chính xác của chúng. Trong QAT, chúng ta thực hiện quá trình tỉ lệ giảm trực tiếp trong quá trình huấn luyện/tinh chỉnh. Điều này tất nhiên tốn kém hơn để thực hiện nhưng thường cũng mang lại kết quả chính xác tốt hơn. Thông tin chi tiết về các kỹ thuật tỉ lệ giảm có thể được tìm thấy trong bài viết này. Ngoài tỉ lệ giảm, cũng có thể áp dụng cắt tỉa LLM (có cấu trúc/không cấu trúc) hoặc chưng cất.
Để cải thiện các vấn đề về khả năng song song thấp, chúng ta có thể tập trung chủ yếu vào việc cải thiện kiến trúc của LLMs. Một số phương pháp phổ biến bao gồm: Chú Ý Đa Truy Vấn, Chú Ý Truy Vấn Nhóm, Nhúng Điều Chỉnh, vv… Cuối cùng, độ trễ của LLMs nói chung có thể được giảm bằng cách tăng tính thưa thớt (ví dụ: Hỗn hợp các Chuyên gia, Cắt tỉa có cấu trúc), hợp nhất các toán tử liền kề và lưu trữ cache (ví dụ: lưu trữ các khóa/giá trị trung gian của các lớp chú ý).
Một số ví dụ nơi các giới hạn đầu vào có thể được áp dụng là: xác định các câu hỏi ngoài lề và chuyển hướng người dùng để chỉ hỏi các câu hỏi phù hợp, ngăn chặn các nỗ lực phá vỡ hệ thống bằng cách ghi đè lên thông báo, tránh việc nhập các mã độc hại (ví dụ: một người dùng yêu cầu một LLM để xác thực/thực thi một số mã độc hại).
Một cách để giảm độ trễ khi làm việc với các giới hạn đầu vào là kích hoạt bất đồng bộ việc kiểm tra giới hạn và cuộc gọi LLM và trả lại kiểm tra giới hạn nếu kích hoạt thay vì đầu ra LLM.
Cuối cùng, một số ví dụ về các giới hạn đầu ra bao gồm:
- Ngăn chặn ảo tưởng bằng cách cung cấp LLM với một số ngữ cảnh bổ sung về truy vấn hoặc với các ví dụ trước đó về các phản hồi ảo tưởng để không lặp lại.
- Kiểm tra xem cú pháp đầu ra có nhất quán không (ví dụ: mã được cung cấp có thể thực thi được, đầu ra JSON/CSV có cấu trúc tốt, vv.)
- Giới thiệu các thông số đầu ra để đồng ý với việc xây dựng và các chính sách cụ thể của công ty (cung cấp các dịch vụ được cung cấp bởi công ty sử dụng LLMs).
Các Chỉ số Dịch vụ LLM
Sau khi triển khai một LLM, quan trọng là không chỉ theo dõi hiệu suất của mô hình trong việc đưa ra các câu trả lời tốt mà còn các chỉ số phụ khác có thể ảnh hưởng đến trải nghiệm tổng thể của người dùng (ví dụ: tốc độ suy luận). Một số ví dụ về các chỉ số phổ biến cần lưu ý (đặc biệt là đối với hệ thống thời gian thực) bao gồm:
- Thời gian cho đến token đầu tiên: thời gian mà người dùng phải chờ đợi để thấy token đầu tiên xuất hiện. Quan trọng là nhận thấy rằng việc tăng lưu lượng của hệ thống có thể giúp chúng ta xử lý nhiều yêu cầu cùng một lúc hơn nhưng như một hiệu ứng phụ, chúng ta cũng có thể tăng thời gian cho đến token đầu tiên.
- Thời gian cho mỗi token đầu ra: sau khi token đầu tiên xuất hiện, chúng ta có thể đo lường thời gian cần để tạo ra một token cho mỗi người dùng sử dụng hệ thống.
- Độ trễ: đo lường tổng thời gian để nhận được một phản hồi đầy đủ. Điều này có thể được tính bằng cách nhân thời gian cho mỗi token đầu ra vào số lượng token được tạo ra và cộng kết quả vào thời gian cho đến token đầu tiên.

RAG Nâng cao
Retrieval-augmented Generation (RAG) đã trở thành một trong những phương pháp chính để phát triển các trường hợp sử dụng Trí tuệ Nhân tạo Sinh học trong bối cảnh doanh nghiệp. Thực tế, RAG có thể hiệu quả về mặt tính toán/chi phí nhiều hơn trong ngắn hạn so với việc tinh chỉnh một LLM trên một chủ đề cụ thể của doanh nghiệp và cũng có thể giúp giảm đáng kể khả năng ảo tưởng.
Để tận dụng tốt nhất từ RAG, điều quan trọng là cần phải xây dựng một cơ sở hạ tầng có thể đảm bảo cung cấp ngữ cảnh tốt nhất có thể để hỗ trợ đầu vào của LLM.
Phương pháp cơ bản nhất cho RAG liên quan đến việc lấy dữ liệu độc quyền của công ty của bạn, chia nó thành các phần khác nhau, tạo ra một biểu diễn nhúng cho mỗi phần, và lập chỉ mục kết quả trong một cơ sở dữ liệu/lưu trữ vector. Khi một truy vấn mới đến, chúng ta có thể xem xét cơ sở dữ liệu của chúng tôi để tìm nội dung liên quan và truyền nó đến LLM cùng với truy vấn ban đầu của người dùng. Như một phần của quá trình, ngữ cảnh được cung cấp cho LLM có thể được sắp xếp lại tùy chọn để đáp ứng một số quy tắc/ưu tiên kinh doanh rõ ràng.
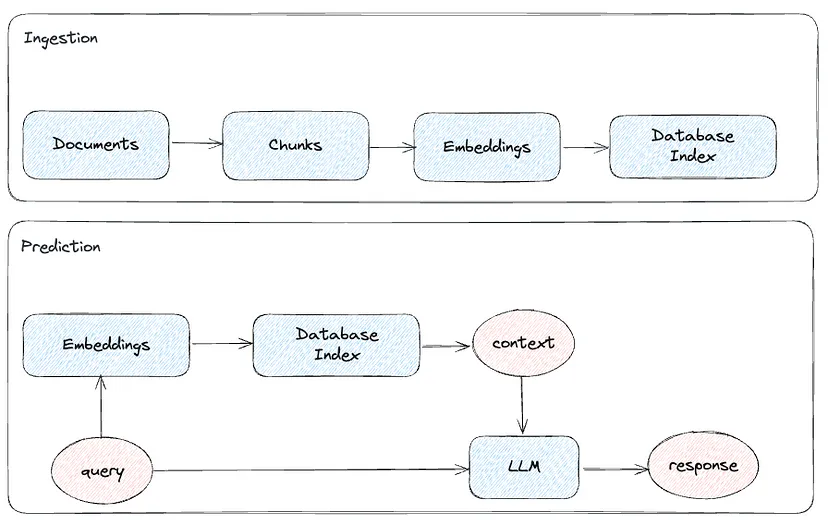
Từ biểu đồ trên, chúng ta có thể suy luận có 3 biến chính chúng ta có thể điều chỉnh để cải thiện hiệu suất của hệ thống của chúng ta: truy vấn (làm cho đầu vào dễ hiểu hơn cho một LLM), ngữ cảnh (cung cấp ngữ cảnh liên quan và được cấu trúc tốt) và phản hồi LLM (đảm bảo phản hồi được hỗ trợ đúng đắn bởi ngữ cảnh và liên quan đến truy vấn ban đầu).
Các truy vấn đầu vào có thể được cải thiện bằng cách: phân rã truy vấn ban đầu thành nhiều truy vấn con để giải quyết theo thứ tự hoặc chuyển đổi truy vấn ban đầu thành một phiên bản tổng quát hơn và sử dụng đầu ra như ngữ cảnh để trả lời truy vấn ban đầu.
Có một số phương pháp để cải thiện ngữ cảnh RAG như sau:
- Truy xuất cửa sổ câu: Chúng ta không chỉ cung cấp cho LLM phần dữ liệu nhận được từ tìm kiếm mà còn truyền một số câu trước và sau phần dữ liệu để cung cấp thêm ngữ cảnh. Điều này tốt hơn việc sử dụng các phần dữ liệu dài hơn và chồng lên từ đầu vì với các phần dữ liệu nhỏ hơn, chúng ta có thể chắc chắn hơn về việc tìm phần dữ liệu phù hợp nhất trong quá trình truy xuất.
- Tự động hợp nhất truy xuất: Một cấu trúc phân cấp của các phần dữ liệu cha-con được xác định và nếu một số lượng tốt các phần dữ liệu con được truy xuất liên kết với cùng một phần dữ liệu cha thì phần dữ liệu cha sẽ được sử dụng làm ngữ cảnh cho LLM thay vì các phần dữ liệu con.
Ngoài ra, các phần khác của ống dẫn cũng có thể được tối ưu hóa bằng cách thử nghiệm các kích thước phần dữ liệu khác nhau, thử nghiệm các loại nhúng để sử dụng để xử lý các phần dữ liệu, hoặc các cơ chế chỉ mục tìm kiếm (ví dụ: chỉ mục phẳng brute-force, FAISS, ANNOY, HNSW, ElasticSearch, Pinecone, vv.). Đặc biệt, nếu làm việc với cơ sở dữ liệu lớn các tài liệu, việc có nhiều chỉ mục phân cấp thay vì chỉ một chỉ mục có thể rất hữu ích để tăng tốc quá trình tìm kiếm cho ngữ cảnh để truyền cho LLM. Ví dụ, trong chỉ mục đầu tiên, chúng ta có thể lưu trữ tóm tắt của mỗi tài liệu (hoặc các câu hỏi giả định một ai đó có thể hỏi về tài liệu đó) và trong chỉ mục thứ hai, các phần dữ liệu khác nhau tạo nên tài liệu cụ thể đó và truy xuất từ đó chỉ các phần dữ liệu phù hợp.
Cuối cùng, quan trọng là nhớ rằng tìm kiếm dựa trên từ khóa (ví dụ: TF-IDF) luôn là một lựa chọn và nó cũng có thể được sử dụng dưới dạng kết hợp để tăng cường Tìm kiếm ngữ nghĩa dựa trên Trí tuệ sinh học.
Sau khi hệ thống của chúng ta đã được triển khai, chúng ta có thể sử dụng phản hồi của người dùng để cải thiện quá trình truy xuất bằng cách huấn luyện một bộ chuyển đổi nhúng (một mạng nơ-ron nhỏ có thể được chèn vào mô hình lớn đã được huấn luyện).
Thay lời kết
Như một phần của bài viết này, chúng tôi chỉ giới thiệu một số điểm cần lưu ý khi làm việc với LLMs, mặc dù khi lĩnh vực này tiếp tục phát triển, luôn có thêm điều gì đó có thể thực hiện được (ví dụ: Kết hợp Mô hình, Hỗn hợp các Chuyên gia, Mô hình Không gian Trạng thái như Jamba, Tác nhân, Tối ưu hóa Phần cứng, vv.). Nếu bạn có bất kỳ điểm chú ý nào khác bạn muốn thêm vào, đừng ngần ngại để lại một bình luận dưới đây!