


Tác giả: Jay Mishra, COO tại Astera
Được xuất bản 5 giờ trước vào ngày 29 tháng 5 năm 2024
Những tiến bộ gần đây trong phần cứng như GPU Nvidia H100 đã tăng cường đáng kể khả năng tính toán. Với tốc độ nhanh gấp chín lần Nvidia A100, các GPU này vượt trội trong việc xử lý các khối lượng công việc học sâu. Sự tiến bộ này đã thúc đẩy việc sử dụng AI sáng tạo trong xử lý ngôn ngữ tự nhiên (NLP) và thị giác máy tính, cho phép trích xuất dữ liệu tự động và thông minh. Các doanh nghiệp giờ đây có thể dễ dàng chuyển đổi dữ liệu phi cấu trúc thành những thông tin có giá trị, đánh dấu một bước tiến lớn trong việc tích hợp công nghệ.
Các Phương Pháp Truyền Thống của Việc Trích Xuất Dữ Liệu Nhập Dữ Liệu Thủ Công
Thật ngạc nhiên, nhiều công ty vẫn dựa vào việc nhập dữ liệu thủ công, mặc dù có sẵn các công nghệ tiên tiến hơn. Phương pháp này bao gồm việc nhập thông tin bằng tay trực tiếp vào hệ thống mục tiêu. Nó thường dễ chấp nhận hơn do chi phí ban đầu thấp hơn. Tuy nhiên, nhập dữ liệu thủ công không chỉ tẻ nhạt và tốn thời gian mà còn rất dễ mắc lỗi. Ngoài ra, nó còn đặt ra rủi ro bảo mật khi xử lý dữ liệu nhạy cảm, khiến nó trở thành một lựa chọn kém hấp dẫn trong thời đại của tự động hóa và an ninh kỹ thuật số.
Nhận Dạng Ký Tự Quang Học (OCR)
Công nghệ OCR, chuyển đổi hình ảnh và nội dung viết tay thành dữ liệu có thể đọc được bằng máy, cung cấp giải pháp nhanh hơn và tiết kiệm chi phí hơn cho việc trích xuất dữ liệu. Tuy nhiên, chất lượng có thể không đáng tin cậy. Ví dụ, các ký tự như “S” có thể bị hiểu nhầm thành “8” và ngược lại.
Hiệu suất của OCR bị ảnh hưởng đáng kể bởi độ phức tạp và đặc điểm của dữ liệu đầu vào; nó hoạt động tốt với các hình ảnh quét có độ phân giải cao, không gặp phải các vấn đề như nghiêng, watermark, hoặc viết đè. Tuy nhiên, OCR gặp khó khăn với văn bản viết tay, đặc biệt khi các hình ảnh phức tạp hoặc khó xử lý. Các điều chỉnh có thể cần thiết để cải thiện kết quả khi xử lý văn bản. Các công cụ trích xuất dữ liệu trên thị trường với công nghệ OCR cơ bản thường thêm nhiều lớp xử lý hậu kỳ để cải thiện độ chính xác của dữ liệu trích xuất. Nhưng các giải pháp này không thể đảm bảo kết quả chính xác 100%.
Khớp Mẫu Văn Bản
Khớp mẫu văn bản là phương pháp xác định và trích xuất thông tin cụ thể từ văn bản bằng cách sử dụng các quy tắc hoặc mẫu được định sẵn. Nó nhanh hơn và mang lại ROI cao hơn so với các phương pháp khác. Phương pháp này hiệu quả ở mọi mức độ phức tạp và đạt độ chính xác 100% cho các tập tin có bố cục tương tự.
Tuy nhiên, tính cứng nhắc trong việc khớp từng từ một có thể hạn chế khả năng thích ứng, yêu cầu khớp chính xác 100% để trích xuất thành công. Các thách thức với từ đồng nghĩa có thể dẫn đến khó khăn trong việc xác định các thuật ngữ tương đương, như phân biệt “weather” và “climate”. Thêm vào đó, Khớp Mẫu Văn Bản thể hiện sự nhạy cảm về ngữ cảnh, thiếu nhận thức về nhiều nghĩa khác nhau trong các ngữ cảnh khác nhau. Việc tìm được sự cân bằng đúng giữa tính cứng nhắc và khả năng thích ứng vẫn là một thách thức liên tục trong việc sử dụng phương pháp này một cách hiệu quả.
Nhận Diện Thực Thể (NER)
Nhận diện thực thể (NER), một kỹ thuật trong xử lý ngôn ngữ tự nhiên (NLP), xác định và phân loại thông tin quan trọng trong văn bản.
Các trích xuất của NER bị giới hạn ở các thực thể được định sẵn như tên tổ chức, địa điểm, tên cá nhân và ngày tháng. Nói cách khác, các hệ thống NER hiện tại thiếu khả năng nội tại để trích xuất các thực thể tùy chỉnh ngoài bộ định sẵn này, điều này có thể cụ thể cho một lĩnh vực hoặc trường hợp sử dụng cụ thể. Thứ hai, sự tập trung của NER vào các giá trị chính liên quan đến các thực thể được nhận dạng không mở rộng đến việc trích xuất dữ liệu từ các bảng, làm hạn chế khả năng áp dụng của nó đối với các loại dữ liệu phức tạp hoặc có cấu trúc hơn.
Khi các tổ chức phải xử lý lượng dữ liệu phi cấu trúc ngày càng tăng, những thách thức này làm nổi bật nhu cầu về một phương pháp trích xuất toàn diện và có khả năng mở rộng.
Khai Phá Dữ Liệu Phi Cấu Trúc với LLMs
Tận dụng các mô hình ngôn ngữ lớn (LLMs) để trích xuất dữ liệu phi cấu trúc là một giải pháp hấp dẫn với những ưu điểm riêng biệt nhằm giải quyết các thách thức quan trọng.
Trích Xuất Dữ Liệu Nhận Biết Ngữ Cảnh
LLMs sở hữu khả năng hiểu ngữ cảnh mạnh mẽ, được rèn luyện qua quá trình huấn luyện rộng rãi trên các tập dữ liệu lớn. Khả năng của chúng không chỉ dừng lại ở bề mặt mà còn hiểu được các phức tạp của ngữ cảnh, làm cho chúng trở nên có giá trị trong việc xử lý các nhiệm vụ trích xuất thông tin đa dạng. Ví dụ, khi được giao nhiệm vụ trích xuất các giá trị thời tiết, chúng không chỉ nắm bắt thông tin mong muốn mà còn xem xét các yếu tố liên quan như các giá trị khí hậu, tích hợp một cách liền mạch các từ đồng nghĩa và ngữ nghĩa. Mức độ hiểu biết nâng cao này làm cho LLMs trở thành lựa chọn động và thích ứng trong lĩnh vực trích xuất dữ liệu.
Tận Dụng Khả Năng Xử Lý Song Song
LLMs sử dụng xử lý song song, làm cho các nhiệm vụ trở nên nhanh chóng và hiệu quả hơn. Không giống như các mô hình tuần tự, LLMs tối ưu hóa việc phân bổ tài nguyên, dẫn đến việc tăng tốc các nhiệm vụ trích xuất dữ liệu. Điều này không chỉ cải thiện tốc độ mà còn nâng cao hiệu suất tổng thể của quá trình trích xuất.
Thích Ứng Với Các Loại Dữ Liệu Đa Dạng
Trong khi một số mô hình như Mạng Nơ-ron Tái hồi (RNNs) bị giới hạn ở các chuỗi cụ thể, LLMs có thể xử lý dữ liệu không thuộc chuỗi cụ thể, dễ dàng thích ứng với các cấu trúc câu đa dạng. Sự linh hoạt này bao gồm nhiều dạng dữ liệu khác nhau như bảng và hình ảnh.
Nâng Cao Các Quy Trình Xử Lý
Việc sử dụng LLMs đánh dấu một sự thay đổi đáng kể trong việc tự động hóa cả các giai đoạn tiền xử lý và hậu xử lý. LLMs giảm thiểu sự cần thiết của công sức thủ công bằng cách tự động hóa chính xác các quá trình trích xuất, đơn giản hóa việc xử lý dữ liệu phi cấu trúc. Với quá trình huấn luyện rộng rãi trên các tập dữ liệu đa dạng, chúng có thể xác định các mẫu và mối liên hệ mà các phương pháp truyền thống bỏ qua.
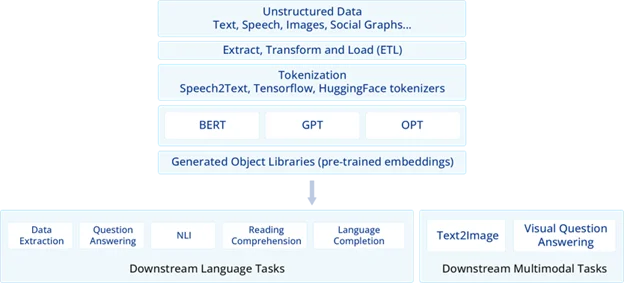
Hình minh họa về một quy trình AI sáng tạo này cho thấy khả năng ứng dụng của các mô hình như BERT, GPT và OPT trong việc trích xuất dữ liệu. Các LLMs này có thể thực hiện nhiều thao tác NLP khác nhau, bao gồm trích xuất dữ liệu. Thông thường, mô hình AI sáng tạo cung cấp một gợi ý mô tả dữ liệu mong muốn, và phản hồi sau đó sẽ chứa dữ liệu được trích xuất. Ví dụ, một gợi ý như “Trích xuất tên của tất cả các nhà cung cấp từ đơn đặt hàng này” có thể mang lại phản hồi chứa tất cả tên nhà cung cấp có trong báo cáo bán cấu trúc. Sau đó, dữ liệu được trích xuất có thể được phân tích và tải vào một bảng cơ sở dữ liệu hoặc tệp phẳng, tạo điều kiện tích hợp liền mạch vào quy trình làm việc của tổ chức.
Các Khung AI Phát Triển: Từ RNNs đến Transformers trong Trích Xuất Dữ Liệu Hiện Đại
AI sáng tạo hoạt động trong một khung mã hóa-giải mã với sự hợp tác của hai mạng nơ-ron. Bộ mã hóa xử lý dữ liệu đầu vào, nén các đặc điểm quan trọng thành một “Context Vector.” Vector này sau đó được bộ giải mã sử dụng cho các nhiệm vụ sáng tạo, như dịch ngôn ngữ. Kiến trúc này, tận dụng các mạng nơ-ron như RNNs và Transformers, được ứng dụng trong nhiều lĩnh vực, bao gồm dịch máy, tạo hình ảnh, tổng hợp giọng nói và trích xuất thực thể dữ liệu. Các mạng này xuất sắc trong việc mô hình hóa các mối quan hệ và phụ thuộc phức tạp trong các chuỗi dữ liệu.
Mạng Nơ-ron Tái hồi (RNNs)
Mạng Nơ-ron Tái hồi (RNNs) được thiết kế để giải quyết các nhiệm vụ chuỗi như dịch và tóm tắt, xuất sắc trong một số ngữ cảnh nhất định. Tuy nhiên, chúng gặp khó khăn về độ chính xác trong các nhiệm vụ liên quan đến phụ thuộc dài hạn.
RNNs xuất sắc trong việc trích xuất các cặp khóa-giá trị từ các câu, nhưng gặp khó khăn với các cấu trúc giống như bảng. Việc giải quyết vấn đề này đòi hỏi xem xét kỹ lưỡng về chuỗi và vị trí, yêu cầu các phương pháp chuyên biệt để tối ưu hóa việc trích xuất dữ liệu từ các bảng. Tuy nhiên, việc áp dụng chúng bị hạn chế do ROI thấp và hiệu suất kém trong hầu hết các nhiệm vụ xử lý văn bản, ngay cả sau khi được huấn luyện trên khối lượng lớn dữ liệu.
Mạng Bộ Nhớ Ngắn Hạn Dài (LSTMs)
Mạng Bộ Nhớ Ngắn Hạn Dài (LSTMs) xuất hiện như một giải pháp giải quyết các hạn chế của RNNs, đặc biệt thông qua cơ chế cập nhật và quên chọn lọc. Giống như RNNs, LSTMs xuất sắc trong việc trích xuất các cặp khóa-giá trị từ các câu, nhưng gặp những thách thức tương tự với các cấu trúc giống như bảng, đòi hỏi sự xem xét chiến lược về chuỗi và các yếu tố vị trí.
GPU lần đầu tiên được sử dụng cho học sâu vào năm 2012 để phát triển mô hình AlexNet CNN nổi tiếng. Sau đó, một số RNNs cũng được huấn luyện bằng GPU, mặc dù không mang lại kết quả tốt. Ngày nay, mặc dù GPU đã có sẵn, các mô hình này phần lớn đã bị thay thế bởi các LLMs dựa trên transformer.
Transformer – Cơ Chế Attention
Sự ra đời của transformers, được giới thiệu trong bài báo mang tính đột phá “Attention is All You Need” (2017), đã cách mạng hóa NLP bằng việc đề xuất kiến trúc ‘transformer’. Kiến trúc này cho phép tính toán song song và nắm bắt tốt các phụ thuộc dài hạn, mở ra các khả năng mới cho các mô hình ngôn ngữ. Các LLM như GPT, BERT và OPT đã tận dụng công nghệ transformers. Trọng tâm của transformers là cơ chế “attention”, một yếu tố quan trọng góp phần nâng cao hiệu suất trong xử lý dữ liệu chuỗi.
Cơ chế “attention” trong transformers tính toán một tổng trọng số của các giá trị dựa trên sự tương thích giữa ‘query’ (câu hỏi nhắc nhở) và ‘key’ (sự hiểu biết của mô hình về từng từ). Phương pháp này cho phép tập trung sự chú ý trong quá trình tạo chuỗi, đảm bảo trích xuất chính xác. Hai thành phần quan trọng trong cơ chế attention là Self-Attention, nắm bắt tầm quan trọng giữa các từ trong chuỗi đầu vào, và Multi-Head Attention, cho phép các mẫu chú ý đa dạng cho các mối quan hệ cụ thể.
Trong ngữ cảnh Trích Xuất Hóa Đơn, Self-Attention nhận ra tầm quan trọng của ngày tháng đã được đề cập trước đó khi trích xuất các khoản thanh toán, trong khi Multi-Head Attention tập trung độc lập vào các giá trị số (số tiền) và các mẫu văn bản (tên nhà cung cấp). Không giống như RNNs, transformers không tự nhiên hiểu được thứ tự của các từ. Để giải quyết điều này, chúng sử dụng mã hóa vị trí để theo dõi vị trí của mỗi từ trong một chuỗi. Kỹ thuật này được áp dụng cho cả nhúng đầu vào và đầu ra, giúp xác định các keys và giá trị tương ứng của chúng trong một tài liệu.
Sự kết hợp giữa các cơ chế attention và mã hóa vị trí là rất quan trọng cho khả năng của một mô hình ngôn ngữ lớn trong việc nhận ra cấu trúc dạng bảng, xem xét nội dung, khoảng cách và các dấu hiệu văn bản. Kỹ năng này làm cho nó khác biệt so với các kỹ thuật trích xuất dữ liệu phi cấu trúc khác.
Xu Hướng và Phát Triển Hiện Tại
Lĩnh vực AI đang mở ra những xu hướng và phát triển đầy hứa hẹn, định hình lại cách chúng ta trích xuất thông tin từ dữ liệu phi cấu trúc. Hãy cùng đi sâu vào các khía cạnh chính đang định hình tương lai của lĩnh vực này.
Tiến Bộ trong Các Mô Hình Ngôn Ngữ Lớn (LLMs)
AI sáng tạo đang trải qua một giai đoạn biến đổi, với LLMs chiếm vị trí trung tâm trong việc xử lý các tập dữ liệu phức tạp và đa dạng cho việc trích xuất dữ liệu phi cấu trúc. Hai chiến lược đáng chú ý đang thúc đẩy những tiến bộ này:
- Học Đa Phương Thức (Multimodal Learning): LLMs đang mở rộng khả năng của chúng bằng cách xử lý đồng thời nhiều loại dữ liệu khác nhau, bao gồm văn bản, hình ảnh và âm thanh. Sự phát triển này nâng cao khả năng của chúng trong việc trích xuất thông tin có giá trị từ nhiều nguồn khác nhau, tăng cường tính hữu ích của chúng trong việc trích xuất dữ liệu phi cấu trúc. Các nhà nghiên cứu đang khám phá những cách sử dụng hiệu quả các mô hình này, nhằm loại bỏ sự cần thiết của GPU và cho phép vận hành các mô hình lớn với tài nguyên hạn chế.
- Ứng Dụng RAG (Retrieval Augmented Generation): Retrieval Augmented Generation (RAG) là một xu hướng mới nổi kết hợp các mô hình ngôn ngữ lớn đã được huấn luyện với các cơ chế tìm kiếm bên ngoài để nâng cao khả năng của chúng. Bằng cách truy cập vào một kho tài liệu rộng lớn trong quá trình tạo, RAG biến các mô hình ngôn ngữ cơ bản thành các công cụ động phù hợp cho cả ứng dụng kinh doanh và tiêu dùng.
Các Phát Triển Khác
Ngoài ra, các xu hướng và phát triển khác cũng đang định hình lĩnh vực trích xuất dữ liệu phi cấu trúc, bao gồm sự tiến bộ trong các kỹ thuật học sâu, cải tiến trong cơ sở hạ tầng tính toán, và những ứng dụng mới của AI trong các ngành công nghiệp khác nhau. Những tiến bộ này không chỉ cải thiện độ chính xác và hiệu quả của việc trích xuất dữ liệu mà còn mở rộng phạm vi ứng dụng của AI trong việc giải quyết các vấn đề phức tạp liên quan đến dữ liệu phi cấu trúc.
Đánh Giá Hiệu Suất Các Mô Hình Ngôn Ngữ Lớn (LLMs)
Thách thức của việc đánh giá hiệu suất các mô hình LLMs được giải quyết bằng cách tiếp cận chiến lược, kết hợp các chỉ số đánh giá cụ thể cho từng nhiệm vụ và các phương pháp đánh giá sáng tạo. Những phát triển chính trong lĩnh vực này bao gồm:
- Các Chỉ Số Tinh Chỉnh: Các chỉ số đánh giá được tùy chỉnh đang nổi lên để đánh giá chất lượng của các nhiệm vụ trích xuất thông tin. Các chỉ số như độ chính xác (Precision), độ bao phủ (Recall) và F1-score đang chứng tỏ hiệu quả, đặc biệt trong các nhiệm vụ như trích xuất thực thể.
- Đánh Giá Bởi Con Người: Đánh giá bởi con người vẫn đóng vai trò quan trọng bên cạnh các chỉ số tự động, đảm bảo một đánh giá toàn diện về LLMs. Bằng cách tích hợp các chỉ số tự động với đánh giá của con người, các phương pháp đánh giá kết hợp cung cấp cái nhìn tinh tế về độ đúng đắn và liên quan ngữ cảnh của thông tin được trích xuất.
Các Phát Triển Chính
- Fine-Tuned Metrics: Sử dụng các chỉ số tinh chỉnh để đánh giá hiệu suất của các mô hình trên các nhiệm vụ cụ thể, chẳng hạn như trích xuất thực thể, giúp đánh giá chính xác hơn khả năng của mô hình.
- Human Evaluation: Kết hợp đánh giá của con người với các chỉ số tự động để cung cấp một cái nhìn toàn diện hơn về hiệu suất của mô hình, bao gồm cả độ chính xác và sự liên quan ngữ cảnh.
Những phương pháp đánh giá này giúp cải thiện độ tin cậy và hiệu quả của các mô hình ngôn ngữ lớn, đảm bảo rằng chúng không chỉ thực hiện tốt về mặt kỹ thuật mà còn phù hợp và chính xác trong các ngữ cảnh thực tế.
Xử Lý Hình Ảnh và Tài Liệu
Các LLM đa dạng đã hoàn toàn thay thế OCR. Người dùng có thể chuyển đổi văn bản quét từ hình ảnh và tài liệu thành văn bản có thể đọc được bằng máy, có khả năng nhận diện và trích xuất thông tin trực tiếp từ nội dung hình ảnh bằng các mô-đun dựa trên thị giác.
Trích Xuất Dữ Liệu từ Liên Kết và Trang Web
LLMs đang tiến triển để đáp ứng nhu cầu ngày càng tăng về trích xuất dữ liệu từ các trang web và liên kết web. Các mô hình này ngày càng thành thạo hơn trong việc trích xuất dữ liệu từ các trang web, chuyển đổi dữ liệu từ các trang web thành các định dạng có cấu trúc. Xu hướng này vô cùng quý giá cho các nhiệm vụ như tổng hợp tin tức, thu thập dữ liệu thương mại điện tử và thông tin tình đối thủ, nâng cao sự hiểu biết ngữ cảnh và trích xuất dữ liệu liên quan từ web.
Sự Nổi Lên của Các “Gã Khổng Lồ Nhỏ” trong AI Sáng Tạo
Nửa đầu năm 2023 chứng kiến sự tập trung vào việc phát triển các mô hình ngôn ngữ lớn dựa trên giả định “càng lớn càng tốt”. Tuy nhiên, các kết quả gần đây cho thấy các mô hình nhỏ hơn như TinyLlama và Dolly-v2-3B, có ít hơn 3 tỷ tham số, xuất sắc trong các nhiệm vụ như lý luận và tóm tắt, đoạt được danh hiệu “gã khổng lồ nhỏ”. Các mô hình này sử dụng ít tài nguyên tính toán và lưu trữ hơn, làm cho AI trở nên dễ tiếp cận hơn đối với các công ty nhỏ mà không cần thiết bị GPU đắt tiền.
Kết Luận
Các mô hình AI sáng tạo ban đầu, bao gồm mạng nơ-ron sáng tạo đối địch (GANs) và bộ mã hóa tự động biến đổi (VAEs), đã giới thiệu các phương pháp mới mẻ để quản lý dữ liệu dựa trên hình ảnh. Tuy nhiên, sự đột phá thực sự đến từ các mô hình ngôn ngữ lớn dựa trên transformer. Những mô hình này vượt qua tất cả các kỹ thuật trước đó trong xử lý dữ liệu phi cấu trúc nhờ cấu trúc mã hóa-giải mã, cơ chế tự chú ý và chú ý đa đầu, mang lại cho chúng hiểu biết sâu sắc về ngôn ngữ và khả năng lý luận giống con người.
Mặc dù AI sáng tạo mang lại một bắt đầu hứa hẹn trong việc khai thác dữ liệu văn bản từ các báo cáo, tính mở rộng của các phương pháp như vậy bị hạn chế. Các bước đầu tiên thường liên quan đến xử lý OCR, có thể dẫn đến lỗi, và các thách thức vẫn tồn tại trong việc trích xuất văn bản từ hình ảnh trong các báo cáo.
Trong khi đó, việc trích xuất văn bản bên trong các hình ảnh trong các báo cáo là một thách thức khác. Việc chấp nhận các giải pháp như xử lý dữ liệu đa dạng và mở rộng giới hạn token trong GPT-4, Claud3, Gemini mở ra một con đường hứa hẹn. Tuy nhiên, cần lưu ý rằng các mô hình này chỉ có thể truy cập thông qua các API. Mặc dù việc sử dụng API để trích xuất dữ liệu từ tài liệu là hiệu quả và tiết kiệm chi phí, nhưng nó cũng đi kèm với một loạt các hạn chế như độ trễ, kiểm soát hạn chế và nguy cơ an ninh.
Một giải pháp an toàn và có thể tùy chỉnh hơn nằm trong việc điều chỉnh tinh chỉnh một mô hình LLM trong nhà. Phương pháp này không chỉ giảm thiểu các lo ngại về quyền riêng tư và an ninh dữ liệu mà còn tăng cường kiểm soát về quy trình trích xuất dữ liệu. Tinh chỉnh một LLM cho việc hiểu cấu trúc tài liệu và hiểu nghĩa của văn bản dựa trên ngữ cảnh của nó cung cấp một phương pháp mạnh mẽ cho việc trích xuất các cặp khóa-giá trị và các mục trong dòng. Tận dụng học không cần hướng dẫn và học từ vài mẫu, một mô hình được điều chỉnh có thể thích nghi với các cấu trúc tài liệu đa dạng, đảm bảo trích xuất dữ liệu phi cấu trúc hiệu quả và chính xác trên các lĩnh vực khác nhau.