


Tác giả: Aayush Mittal
ngày 3 tháng 6 năm 2024
Các mô hình ngôn ngữ lớn (LLMs) như GPT, LLaMA và những mô hình khác đã làm chấn động thế giới với khả năng hiểu và tạo ra văn bản giống con người đáng kinh ngạc. Tuy nhiên, mặc dù có những khả năng ấn tượng, phương pháp tiêu chuẩn để huấn luyện các mô hình này, được gọi là “dự đoán token tiếp theo”, vẫn có một số hạn chế cố hữu.
Trong dự đoán token tiếp theo, mô hình được huấn luyện để dự đoán từ tiếp theo trong một chuỗi dựa trên các từ đứng trước. Mặc dù phương pháp này đã chứng minh được hiệu quả, nhưng nó có thể dẫn đến các mô hình gặp khó khăn với các phụ thuộc dài hạn và các nhiệm vụ lý luận phức tạp. Hơn nữa, sự không khớp giữa chế độ huấn luyện theo phương pháp “teacher-forcing” và quá trình sinh tự hồi quy trong quá trình suy luận có thể dẫn đến hiệu suất không tối ưu.
Một bài báo nghiên cứu gần đây của Gloeckle và cộng sự (2024) từ Meta AI giới thiệu một mô hình huấn luyện mới gọi là “dự đoán đa token” nhằm giải quyết những hạn chế này và tăng cường hiệu suất của các mô hình ngôn ngữ lớn. Trong bài viết blog này, chúng ta sẽ đi sâu vào các khái niệm cốt lõi, chi tiết kỹ thuật và những tác động tiềm năng của nghiên cứu đột phá này.
Dự đoán đơn token: Phương pháp Truyền thống
Trước khi đi sâu vào chi tiết của dự đoán đa token, điều quan trọng là hiểu về phương pháp truyền thống đã làm việc chăm chỉ trong việc huấn luyện các mô hình ngôn ngữ lớn trong nhiều năm – dự đoán đơn token, còn được biết đến là dự đoán token tiếp theo.
Mô hình Dự đoán Token Tiếp theo
Trong mô hình dự đoán token tiếp theo, các mô hình ngôn ngữ được huấn luyện để dự đoán từ tiếp theo trong một chuỗi dựa trên ngữ cảnh trước đó. Cụ thể hơn, mô hình được giao nhiệm vụ tối đa hóa xác suất của token tiếp theo xt+1, cho trước các token trước đó x1, x2, …, xt. Thường thì điều này được thực hiện bằng cách giảm thiểu mất mát entropy chéo:
L = -Σt log P(xt+1 | x1, x2, …, xt)
Mục tiêu huấn luyện đơn giản nhưng mạnh mẽ này đã là nền tảng của nhiều mô hình ngôn ngữ lớn thành công, như GPT (Radford và cộng sự, 2018), BERT (Devlin và cộng sự, 2019), và các biến thể của chúng.
Teacher Forcing và Quá trình Sinh tự hồi quy
Dự đoán token tiếp theo dựa trên một kỹ thuật huấn luyện gọi là “teacher forcing” trong đó mô hình được cung cấp với thông tin đúng cho mỗi token trong tương lai trong quá trình huấn luyện. Điều này cho phép mô hình học từ ngữ cảnh và chuỗi mục tiêu chính xác, giúp việc huấn luyện trở nên ổn định và hiệu quả hơn.
Tuy nhiên, trong quá trình suy luận hoặc tạo ra văn bản, mô hình hoạt động theo cách tự hồi quy, dự đoán một token tại một thời điểm dựa trên các token đã được tạo ra trước đó. Sự không phù hợp giữa chế độ huấn luyện (teacher forcing) và chế độ suy luận (sinh tự hồi quy) có thể dẫn đến sự không nhất quán và hiệu suất không tối ưu, đặc biệt là đối với các chuỗi dài hơn hoặc các nhiệm vụ lý luận phức tạp.
Hạn chế của Dự đoán Token Tiếp theo
Mặc dù dự đoán token tiếp theo đã đạt được thành công đáng kinh ngạc, nhưng nó cũng có một số hạn chế cố hữu:
- Tập trung vào Ngắn hạn: Bằng cách chỉ dự đoán token tiếp theo, mô hình có thể gặp khó khăn trong việc nắm bắt các phụ thuộc xa và cấu trúc tổng thể và sự liên kết của văn bản, có thể dẫn đến sự không nhất quán hoặc việc tạo ra văn bản không có logic.
- Ràng buộc vào Mẫu Cục bộ: Các mô hình dự đoán token tiếp theo có thể ràng buộc vào các mẫu cục bộ trong dữ liệu huấn luyện, làm cho việc tổng quát hóa đến các kịch bản nằm ngoài phân phối hoặc các nhiệm vụ yêu cầu tư duy trừu tượng hơn trở nên khó khăn.
- Khả năng Lập luận: Đối với các nhiệm vụ liên quan đến việc lập luận đa bước, tư duy theo thuật toán hoặc các phép toán logic phức tạp, dự đoán token tiếp theo có thể không cung cấp đủ các độ nghiệm hoặc biểu diễn để hỗ trợ các khả năng này một cách hiệu quả.
- Hiệu suất Mẫu mẫu: Do tính cục bộ của dự đoán token tiếp theo, các mô hình có thể yêu cầu bộ dữ liệu huấn luyện lớn hơn để có được kiến thức và kỹ năng lập luận cần thiết, dẫn đến hiệu suất mẫu không hiệu quả.
Những hạn chế này đã thúc đẩy các nhà nghiên cứu khám phá các mô hình huấn luyện thay thế, như dự đoán đa token, mục tiêu là giải quyết một số hạn chế này và mở khóa các khả năng mới cho các mô hình ngôn ngữ lớn.
Bằng cách so sánh phương pháp truyền thống dự đoán token tiếp theo với kỹ thuật dự đoán đa token mới lạ, độc giả có thể hiểu rõ hơn động lực và lợi ích tiềm năng của phương pháp sau, mở đường cho việc khám phá sâu hơn về nghiên cứu đột phá này.
Multi-token Prediction là gì?
Ý tưởng chính đằng sau dự đoán đa token là huấn luyện các mô hình ngôn ngữ để dự đoán đồng thời nhiều token trong tương lai, thay vì chỉ dự đoán token tiếp theo. Cụ thể, trong quá trình huấn luyện, mô hình được giao nhiệm vụ dự đoán n token tiếp theo tại mỗi vị trí trong tập dữ liệu huấn luyện, sử dụng n đầu ra độc lập hoạt động trên đỉnh của một phần cơ sở mô hình được chia sẻ.
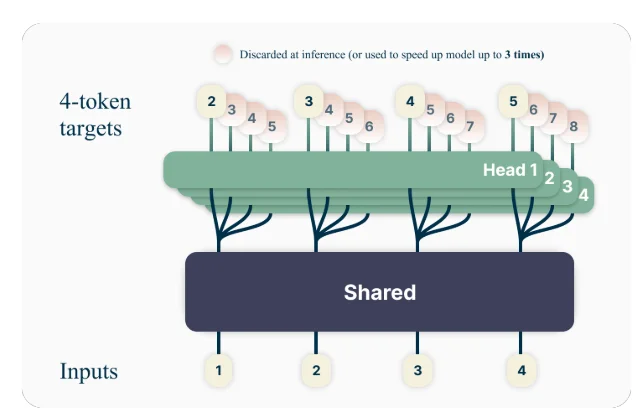
Ví dụ, với một cài đặt dự đoán 4 token, mô hình sẽ được huấn luyện để dự đoán cùng lúc 4 token tiếp theo, cho trước ngữ cảnh trước đó. Phương pháp này khuyến khích mô hình nắm bắt các phụ thuộc xa hơn và phát triển sự hiểu biết tốt hơn về cấu trúc tổng thể và sự liên kết của văn bản.
Một Ví Dụ Giả Lập
Để hiểu rõ hơn về khái niệm dự đoán đa token, hãy xem xét một ví dụ đơn giản. Giả sử chúng ta có câu sau đây:
“Con cáo nâu nhanh nhẹn nhảy qua chú chó lười biếng.”
Trong phương pháp dự đoán token tiếp theo tiêu chuẩn, mô hình sẽ được huấn luyện để dự đoán từ tiếp theo dựa trên ngữ cảnh trước đó. Ví dụ, cho trước ngữ cảnh “Con cáo nâu nhanh nhẹn nhảy qua,” mô hình sẽ được giao nhiệm vụ dự đoán từ tiếp theo, “chú chó.”
Tuy nhiên, với dự đoán đa token, mô hình sẽ được huấn luyện để dự đoán đồng thời nhiều từ trong tương lai. Ví dụ, nếu chúng ta đặt n=4, mô hình sẽ được huấn luyện để dự đoán 4 từ tiếp theo cùng một lúc. Cho trước cùng ngữ cảnh “Con cáo nâu nhanh nhẹn nhảy qua,” mô hình sẽ được giao nhiệm vụ dự đoán chuỗi “chú chó lười biếng .” (Lưu ý khoảng trắng sau “biếng” để chỉ kết thúc câu).
Bằng cách huấn luyện mô hình để dự đoán đồng thời nhiều token trong tương lai, nó được khuyến khích để nắm bắt các phụ thuộc xa và phát triển sự hiểu biết tốt hơn về cấu trúc tổng thể và sự liên kết của văn bản.
Chi Tiết Kỹ Thuật
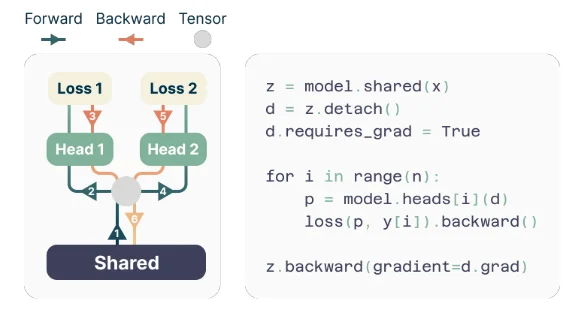
Các tác giả đề xuất một kiến trúc đơn giản nhưng hiệu quả cho việc triển khai dự đoán đa token. Mô hình bao gồm một phần chính transformer được chia sẻ tạo ra một biểu diễn ẩn của ngữ cảnh đầu vào, tiếp theo là n lớp transformer độc lập (đầu ra) dự đoán các token tương lai tương ứng.
Trong quá trình huấn luyện, các lượt tiến và lùi được điều chỉnh cẩn thận để giảm thiểu kích thước bộ nhớ GPU. Phần chính chia sẻ tính toán biểu diễn ẩn, sau đó mỗi đầu ra thực hiện lần lượt lượt tiến và lùi của mình, tích lũy gradient tại cấp độ phần chính. Phương pháp này tránh việc tạo ra tất cả các vector logit và gradient của chúng đồng thời, giảm bộ nhớ GPU cần sử dụng tối đa từ O(nV + d) xuống O(V + d), trong đó V là kích thước từ vựng và d là chiều của biểu diễn ẩn.
Triển Khai Tiết Kiệm Bộ Nhớ
Một trong những thách thức trong việc huấn luyện các bộ dự đoán đa token là giảm sử dụng bộ nhớ GPU của chúng. Vì kích thước từ vựng (V) thường lớn hơn nhiều so với kích thước của biểu diễn ẩn (d), các vector logit trở thành nút cổ chai trong việc sử dụng bộ nhớ GPU.
Để giải quyết thách thức này, các tác giả đề xuất một triển khai tiết kiệm bộ nhớ mà cẩn thận điều chỉnh chuỗi các thao tác tiến và lùi. Thay vì tạo ra tất cả các logit và gradient của chúng đồng thời, triển khai này tính toán tuần tự các lượt tiến và lùi cho mỗi đầu ra độc lập, tích lũy gradient tại cấp độ phần chính.
Phương pháp này tránh việc lưu trữ tất cả các vector logit và gradient của chúng trong bộ nhớ cùng một lúc, giảm thiểu sử dụng bộ nhớ GPU tối đa từ O(nV + d) xuống O(V + d), trong đó n là số lượng token tương lai được dự đoán.
Ưu Điểm của Dự Đoán Đa Token
Bài báo nghiên cứu trình bày một số ưu điểm hấp dẫn của việc sử dụng dự đoán đa token để huấn luyện các mô hình ngôn ngữ lớn:
- Tăng Hiệu Suất Mẫu: Bằng cách khuyến khích mô hình dự đoán đồng thời nhiều token trong tương lai, dự đoán đa token thúc đẩy mô hình điều chỉnh hiệu suất mẫu tốt hơn. Các tác giả chứng minh sự cải thiện đáng kể về hiệu suất trên các nhiệm vụ hiểu mã nguồn và tạo mã, với các mô hình có đến 13 tỷ tham số giải quyết khoảng 15% vấn đề nhiều hơn trung bình.
- Tăng Tốc Suy Luận: Các đầu ra phụ bổ sung được huấn luyện với dự đoán đa token có thể được sử dụng cho tự động giải mã tư duy, một biến thể của giải mã tư duy đa dạng cho phép dự đoán token song song. Điều này dẫn đến tăng tốc lên đến 3 lần thời gian suy luận trên một loạt các kích thước batch, ngay cả đối với các mô hình lớn.
- Khuyến Khích Phụ Thuộc Xa: Dự đoán đa token khuyến khích mô hình nắm bắt các phụ thuộc xa hơn và các mẫu trong dữ liệu, điều này đặc biệt có lợi cho các nhiệm vụ đòi hỏi hiểu và lập luận qua ngữ cảnh lớn hơn.
- Lập Luận Theo Thuật Toán: Các tác giả trình bày các thí nghiệm trên các nhiệm vụ tổng hợp mà chứng minh sự ưu việt của các mô hình dự đoán đa token trong việc phát triển các lớp đánh giá và khả năng lập luận theo thuật toán, đặc biệt là đối với kích thước mô hình nhỏ.
- Liên Kết và Nhất quán: Bằng cách huấn luyện mô hình dự đoán đồng thời nhiều token trong tương lai, dự đoán đa token khuyến khích sự phát triển của các biểu diễn nhất quán và nhất quán. Điều này đặc biệt có ích cho các nhiệm vụ đòi hỏi tạo ra văn bản dài, nhất quán hơn, như viết truyện, viết sáng tạo, hoặc tạo ra các hướng dẫn.
- Cải Thiện Tính Tổng Quát: Các thí nghiệm của tác giả trên các nhiệm vụ tổng hợp gợi ý rằng các mô hình dự đoán đa token có khả năng tổng quát tốt hơn, đặc biệt là trong các cài đặt ngoài phân phối. Điều này có thể do khả năng của mô hình nắm bắt các mẫu và phụ thuộc xa hơn, giúp nó suy luận một cách hiệu quả hơn đối với các tình huống chưa được quan sát.
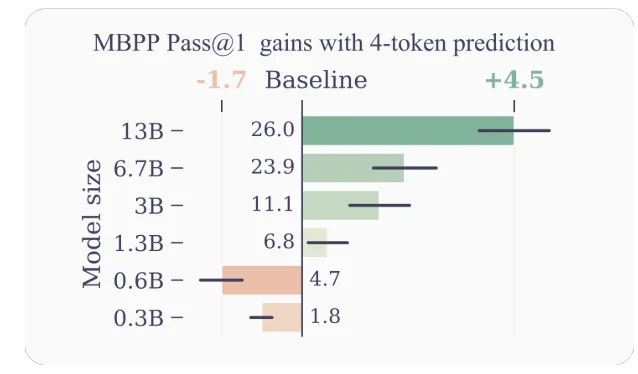
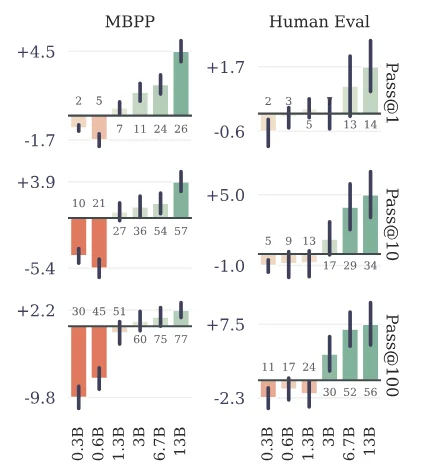
Các Ví dụ và Hiểu biết
Để cung cấp thêm hiểu biết về lý do tại sao dự đoán đa token lại hoạt động tốt đến vậy, hãy xem xét một số ví dụ:
- Tạo Mã: Trong ngữ cảnh của việc tạo mã, dự đoán nhiều token đồng thời có thể giúp mô hình hiểu và tạo ra các cấu trúc mã phức tạp hơn. Ví dụ, khi tạo ra một định nghĩa hàm, việc dự đoán chỉ token tiếp theo có thể không cung cấp đủ ngữ cảnh cho mô hình tạo ra toàn bộ chữ ký hàm một cách chính xác. Tuy nhiên, bằng cách dự đoán nhiều token đồng thời, mô hình có thể nắm bắt tốt hơn các phụ thuộc giữa tên hàm, tham số và kiểu trả về, dẫn đến việc tạo mã chính xác và nhất quán hơn.
- Lập luận bằng Ngôn ngữ Tự nhiên: Xem xét một tình huống trong đó một mô hình ngôn ngữ được giao nhiệm vụ trả lời một câu hỏi đòi hỏi suy luận qua nhiều bước hoặc thông tin. Bằng cách dự đoán nhiều token đồng thời, mô hình có thể nắm bắt tốt hơn các phụ thuộc giữa các thành phần khác nhau của quá trình suy luận, dẫn đến các phản ứng nhất quán và chính xác hơn.
- Tạo ra Văn bản Dài: Khi tạo ra văn bản dài, như truyện, bài báo hoặc báo cáo, duy trì sự nhất quán và nhất quán qua một khoảng thời gian dài có thể là một thách thức đối với các mô hình ngôn ngữ được huấn luyện với dự đoán token tiếp theo. Dự đoán đa token khuyến khích mô hình phát triển các biểu diễn để nắm bắt cấu trúc tổng thể và dòng chảy của văn bản, tiềm năng dẫn đến các bản tạo ra dài nhất quán và nhất quán hơn.
Hạn Chế và Hướng Phát Triển Tương Lai
Mặc dù các kết quả được trình bày trong bài báo là ấn tượng, nhưng có một số hạn chế và câu hỏi mở cần được nghiên cứu kỹ lưỡng hơn:
- Số lượng Token Tối Ưu: Bài báo khám phá các giá trị khác nhau của n (số lượng token tương lai cần dự đoán) và nhận thấy rằng n=4 hoạt động tốt cho nhiều nhiệm vụ. Tuy nhiên, giá trị tối ưu của n có thể phụ thuộc vào nhiệm vụ cụ thể, tập dữ liệu và kích thước mô hình. Phát triển các phương pháp có chủ đích để xác định n tối ưu có thể dẫn đến các cải tiến hiệu suất tiếp theo.
- Kích Thước Từ Vựng và Phân Loại Token: Các tác giả lưu ý rằng kích thước từ vựng tối ưu và chiến lược phân loại token cho các mô hình dự đoán đa token có thể khác biệt so với các mô hình dự đoán token tiếp theo. Khám phá khía cạnh này có thể dẫn đến sự cân nhắc tốt hơn giữa độ dài chuỗi nén và hiệu suất tính toán.
- Mất Mát Dự Đoán Phụ Trợ: Các tác giả gợi ý rằng công việc của họ có thể khơi mào sự quan tâm trong việc phát triển các mất mát dự đoán phụ trợ mới cho các mô hình ngôn ngữ lớn, vượt ra ngoài dự đoán token tiếp theo tiêu chuẩn. Nghiên cứu về các mất mát dự đoán phụ trợ thay thế và sự kết hợp của chúng với dự đoán đa token là một hướng nghiên cứu thú vị.
- Hiểu Biết Lí Thuyết: Mặc dù bài báo cung cấp một số hiểu biết và bằng chứng kinh nghiệm về hiệu quả của dự đoán đa token, một sự hiểu biết lí thuyết sâu sắc hơn về tại sao và làm thế nào phương pháp này hoạt động tốt đến vậy sẽ rất có giá trị.
Kết Luận
Bài báo nghiên cứu “Better & Faster Large Language Models via Multi-token Prediction” của Gloeckle và đồng nghiệp giới thiệu một mô hình huấn luyện mới mẻ có tiềm năng cải thiện đáng kể hiệu suất và khả năng của các mô hình ngôn ngữ lớn. Bằng cách huấn luyện mô hình để dự đoán đồng thời nhiều token trong tương lai, dự đoán đa token khuyến khích sự phát triển của các phụ thuộc xa, khả năng lập luận theo thuật toán và hiệu suất mẫu tốt hơn.
Cài đặt kỹ thuật được đề xuất bởi các tác giả là một phương pháp lịch lãm và tính toán hiệu quả, làm cho việc áp dụng phương pháp này vào việc huấn luyện mô hình ngôn ngữ quy mô lớn trở nên khả thi. Hơn nữa, khả năng tận dụng giải mã tự động tư duy để suy luận nhanh hơn là một ưu điểm thực tiễn đáng kể.
Mặc dù vẫn còn các câu hỏi mở và lĩnh vực để khám phá thêm, nghiên cứu này đại diện cho một bước tiến thú vị trong lĩnh vực các mô hình ngôn ngữ lớn. Khi nhu cầu về các mô hình ngôn ngữ hiệu quả và hiệu suất tiếp tục tăng, dự đoán đa token có thể trở thành một yếu tố chính trong thế hệ tiếp theo của các hệ thống AI mạnh mẽ này.