


Tác giả: Aayush Mittal
Ngày 8 tháng 12 năm 2023
Sự tích hợp và ứng dụng của các mô hình ngôn ngữ lớn (LLMs) trong y học và chăm sóc sức khỏe đã là một chủ đề đáng chú ý và phát triển.
Như đã ghi chú tại Hội nghị toàn cầu của Hiệp hội Quản lý Thông tin và Hệ thống Y tế và các sự kiện đáng chú ý khác, các công ty như Google đang dẫn đầu trong việc khám phá tiềm năng của trí tuệ nhân tạo sáng tạo trong lĩnh vực y tế. Các sáng kiến của họ, như Med-PaLM 2, làm nổi bật bức tranh ngày càng phát triển của các giải pháp y tế do trí tuệ nhân tạo đưa ra, đặc biệt là trong các lĩnh vực như chẩn đoán, chăm sóc bệnh nhân và hiệu quả quản lý hành chính.
Med-PaLM 2 của Google, một mô hình LLM tiên tiến trong lĩnh vực y tế, đã thể hiện khả năng ấn tượng, đặc biệt là đạt được mức độ “chuyên gia” trong các câu hỏi theo kiểu Kỳ thi Đăng ký Y sĩ Hoa Kỳ. Mô hình này, cùng với những mô hình khác tương tự, hứa hẹn làm thay đổi cách các chuyên gia y tế tiếp cận và sử dụng thông tin, có thể nâng cao độ chính xác trong chẩn đoán và hiệu suất chăm sóc bệnh nhân.
Tuy nhiên, song song với những tiến bộ này, lo ngại về tính thực tế và an toàn của những công nghệ này trong bối cảnh lâm sàng đã được đặt ra. Ví dụ, sự phụ thuộc vào nguồn dữ liệu internet rộng lớn để huấn luyện mô hình, mặc dù có lợi ích trong một số ngữ cảnh, nhưng không phải lúc nào cũng phù hợp hoặc đáng tin cậy cho mục đích y học. Như Tiến sĩ Nigam Shah, chuyên gia khoa học dữ liệu chính cho Stanford Health Care, chỉ ra, các câu hỏi quan trọng cần đặt ra là về hiệu suất của những mô hình này trong các bối cảnh y tế thực tế và ảnh hưởng thực tế của chúng đối với chăm sóc bệnh nhân và hiệu suất y tế.
Quan điểm của Tiến sĩ Shah nhấn mạnh sự cần thiết của một phương pháp sử dụng LLMs trong y học được tinh chỉnh hơn. Thay vì sử dụng các mô hình tổng quát được huấn luyện trên dữ liệu internet rộng lớn, ông đề xuất một chiến lược tập trung hơn, trong đó các mô hình được huấn luyện trên dữ liệu y tế cụ thể và liên quan. Phương pháp này giống như việc đào tạo một bác sĩ thực tập y – cung cấp cho họ các nhiệm vụ cụ thể, giám sát hiệu suất của họ và dần dần cho phép họ tự quản lý hơn khi họ chứng minh được năng lực.
Theo đúng hướng này, việc phát triển Meditron bởi các nhà nghiên cứu EPFL đưa ra một tiến triển đáng chú ý trong lĩnh vực này. Meditron, một mô hình LLM mã nguồn mở được tinh chỉnh đặc biệt cho các ứng dụng y tế, đại diện cho một bước tiến quan trọng. Được huấn luyện trên dữ liệu y tế được sắp xếp từ các nguồn uy tín như PubMed và hướng dẫn lâm sàng, Meditron mang lại một công cụ tập trung hơn và có thể tin cậy hơn cho các bác sĩ. Tính mã nguồn mở của nó không chỉ thúc đẩy tính minh bạch và sự hợp tác mà còn cho phép cộng đồng nghiên cứu rộng lớn kiểm tra và cải thiện liên tục.
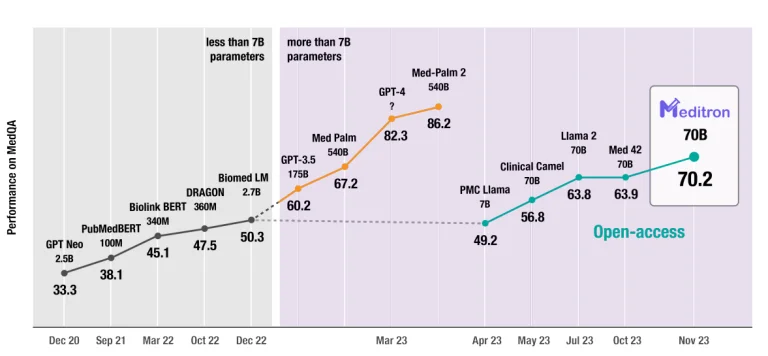
Sự phát triển của các công cụ như Meditron, Med-PaLM 2 và các công cụ khác phản ánh sự nhận thức ngày càng tăng về các yêu cầu đặc biệt của ngành y tế khi áp dụng trí tuệ nhân tạo. Sự tập trung vào việc đào tạo những mô hình này trên dữ liệu y tế có liên quan, chất lượng cao và đảm bảo tính an toàn và đáng tin cậy của chúng trong bối cảnh lâm sàng là rất quan trọng.
Hơn nữa, việc bao gồm các bộ dữ liệu đa dạng, như từ ngữ cảnh nhân đạo như Ủy ban Quốc tế của Hồng Thập Tự, thể hiện sự nhạy bén đối với các nhu cầu và thách thức đa dạng trong lĩnh vực y tế toàn cầu. Phương pháp này tương thích với sứ mệnh lớn của nhiều trung tâm nghiên cứu trí tuệ nhân tạo, mục tiêu tạo ra các công cụ trí tuệ nhân tạo không chỉ công nghệ tiên tiến mà còn có trách nhiệm xã hội và mang lại lợi ích.
Bài báo có tựa đề “Large language models encode clinical knowledge,” vừa được công bố trên tạp chí Nature, khám phá cách mà các mô hình ngôn ngữ lớn (LLMs) có thể được sử dụng hiệu quả trong các bối cảnh lâm sàng. Nghiên cứu này trình bày những cái nhìn và phương pháp đột phá, làm sáng tỏ về khả năng và hạn chế của LLMs trong lĩnh vực y học.
Lĩnh vực y học được đặc trưng bởi sự phức tạp, với một loạt các triệu chứng, bệnh tật và liệu pháp đang liên tục phát triển. LLMs không chỉ phải hiểu rõ sự phức tạp này mà còn theo kịp kiến thức y tế và hướng dẫn mới nhất.
Nền tảng của nghiên cứu này xoay quanh một bộ dữ liệu kiểm tra mới được sắp xếp gọi là MultiMedQA. Bộ dữ liệu này kết hợp sáu bộ dữ liệu hiện tại về câu hỏi-trả lời y học với một bộ dữ liệu mới là HealthSearchQA, bao gồm các câu hỏi y tế được tìm kiếm thường xuyên trên internet. Phương pháp toàn diện này nhằm mục đích đánh giá LLMs qua nhiều chiều hướng khác nhau, bao gồm tính chính xác, sự hiểu biết, lập luận, tổn thương có thể xảy ra và độ chệch, từ đó giải quyết những hạn chế của các đánh giá tự động trước đây dựa trên các bộ kiểm tra hạn chế.
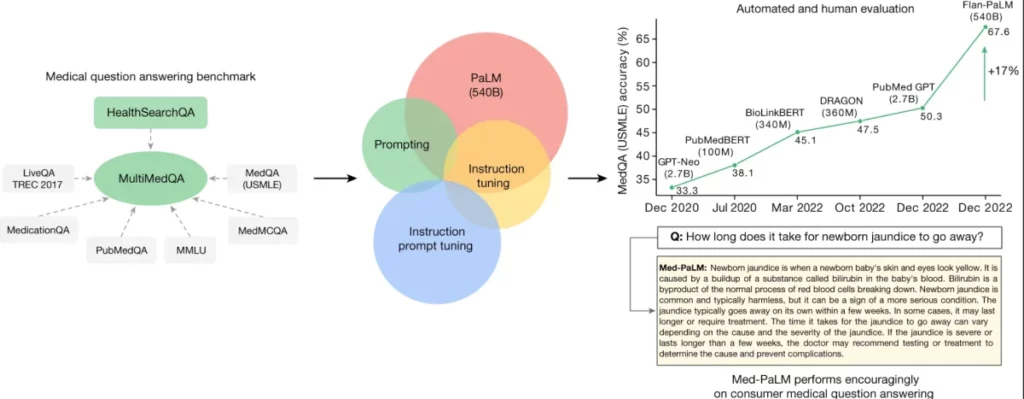
Chìa khóa của nghiên cứu này là đánh giá mô hình ngôn ngữ Pathways (PaLM), một LLM với 540 tỷ tham số, và biến thể được điều chỉnh theo hướng dẫn là Flan-PaLM, trên MultiMedQA. Đáng chú ý, Flan-PaLM đạt được độ chính xác hàng đầu trên tất cả các bộ dữ liệu lựa chọn nhiều trong MultiMedQA, bao gồm một độ chính xác 67,6% trên MedQA, bao gồm các câu hỏi theo kiểu Kỳ thi Đăng ký Y sĩ Hoa Kỳ. Hiệu suất này đánh dấu một cải tiến đáng kể so với các mô hình trước đó, vượt qua trạng thái nghệ thuật trước đó hơn 17%.
Bộ dữ liệu MedQA
Bộ dữ liệu MedQA3 đặc trưng bởi các câu hỏi được thiết kế theo kiểu của Kỳ thi Đăng ký Y sĩ Hoa Kỳ (USMLE), mỗi câu hỏi đi kèm với bốn hoặc năm lựa chọn câu trả lời. Nó bao gồm một bộ phát triển với 11,450 câu hỏi và một bộ kiểm tra gồm 1,273 câu hỏi.
Định dạng: câu hỏi và câu trả lời (Q + A), lựa chọn nhiều, miền mở.
Câu hỏi ví dụ: Một người đàn ông 65 tuổi có huyết áp cao đến bác sĩ để kiểm tra sức khỏe định kỳ. Thuốc hiện tại bao gồm atenolol, lisinopril và atorvastatin. Nhịp tim của anh ấy là 86 lần/phút, nhịp thở là 18 lần/phút và huyết áp là 145/95 mmHg. Kiểm tra tim cho thấy âm nhịp cuối cùng. Điều gì là nguyên nhân có thể nhất của cuộc kiểm tra sức khỏe này?
Câu trả lời (câu trả lời đúng được in đậm): (A) Sự giảm tính tuân thủ củathất trái, (B) Sự đổi mới môi trường của van thất trái (C) Viêm màng ngoại tim (D) Nở huyết động mạch chủ (E) Sự đặc hóa lá van thất trái.
Nghiên cứu cũng xác định những khoảng trống quan trọng trong hiệu suất của mô hình, đặc biệt là trong việc trả lời các câu hỏi y tế của người tiêu dùng. Để giải quyết những vấn đề này, các nhà nghiên cứu giới thiệu một phương pháp được biết đến là điều chỉnh hướng dẫn thông tin. Kỹ thuật này hiệu quả khi điều chỉnh LLMs cho các lĩnh vực mới bằng cách sử dụng một số mẫu minh họa, dẫn đến việc tạo ra mô hình Med-PaLM. Mặc dù mô hình Med-PaLM thể hiện sự khích lệ và có cải thiện về hiểu biết, ghi nhớ kiến thức và lập luận, nhưng vẫn còn hạn chế so với các chuyên gia y tế.
Một điều đáng chú ý của nghiên cứu này là khung thẩm định con người chi tiết. Khung thẩm định này đánh giá các câu trả lời của các mô hình đối với sự đồng thuận khoa học và các kết quả có thể gây hậu quả nguy hại. Ví dụ, trong khi chỉ có 61,9% câu trả lời dài hạn của Flan-PaLM đồng thuận với sự đồng thuận khoa học, con số này tăng lên thành 92,6% đối với Med-PaLM, tương đương với các câu trả lời được tạo ra bởi các bác sĩ. Tương tự, khả năng gây hậu quả nguy hại đã giảm đáng kể trong các câu trả lời của Med-PaLM so với Flan-PaLM.
Việc đánh giá con người đối với các câu trả lời của Med-PaLM làm nổi bật sự thành thạo của nó trong một số lĩnh vực, tiếp xúc chặt chẽ với các câu trả lời được tạo ra bởi các chuyên gia y tế. Điều này làm nổi bật tiềm năng của Med-PaLM như một công cụ hỗ trợ trong các bối cảnh lâm sàng.
Nghiên cứu được thảo luận ở trên chạm sâu vào những chi tiết phức tạp của việc nâng cao Hiệu suất của các Mô hình Ngôn ngữ Lớn (LLMs) cho các ứng dụng y tế. Các kỹ thuật và quan sát từ nghiên cứu này có thể được tổng quát hóa để cải thiện khả năng của LLMs trên nhiều lĩnh vực khác nhau. Hãy khám phá những khía cạnh quan trọng này:
Cải thiện Hiệu suất thông qua Điều chỉnh Hướng dẫn
- Ứng dụng tổng quát: Việc điều chỉnh hướng dẫn, bao gồm việc điều chỉnh LLMs với hướng dẫn hoặc nguyên tắc cụ thể, đã cho thấy sự cải thiện đáng kể về hiệu suất trong nhiều lĩnh vực khác nhau. Kỹ thuật này có thể được áp dụng vào các lĩnh vực khác như pháp lý, tài chính hoặc giáo dục để nâng cao độ chính xác và liên quan của các đầu ra của LLM.
Mở Rộng Kích Thước Mô Hình
- Tác động Rộng Lớn: Quan sát rằng việc mở rộng kích thước mô hình cải thiện hiệu suất không chỉ giới hạn trong việc trả lời câu hỏi y học. Các mô hình lớn hơn, với nhiều tham số hơn, có khả năng xử lý và tạo ra các phản ứng tinh tế và phức tạp hơn. Việc mở rộng này có thể hữu ích trong các lĩnh vực như dịch vụ khách hàng, viết sáng tạo và hỗ trợ kỹ thuật, nơi sự hiểu biết tinh tế và việc tạo ra phản ứng là quan trọng.
Chuỗi suy luận (COT) Bắt gặp
- Sử Dụng Đa Dạng Trong Các Miền: Việc sử dụng COT bắt gặp, mặc dù không luôn luôn cải thiện hiệu suất trong các bộ dữ liệu y tế, có thể có giá trị trong các lĩnh vực khác nơi cần giải quyết vấn đề phức tạp. Ví dụ, trong việc sửa lỗi kỹ thuật hoặc các tình huống đưa ra quyết định phức tạp, COT bắt gặp có thể hướng dẫn LLMs xử lý thông tin từng bước một, dẫn đến các đầu ra chính xác và có lý lẽ hơn.
Tự nhất quán để Nâng cao Độ chính xác
- Ứng Dụng Rộng Rãi: Kỹ thuật tự nhất quán, nơi nhiều đầu ra được tạo ra và câu trả lời có nhất quán nhất được chọn, có thể nâng cao đáng kể hiệu suất trong nhiều lĩnh vực. Trong các lĩnh vực như tài chính hoặc pháp lý nơi độ chính xác là quan trọng, phương pháp này có thể được sử dụng để kiểm tra chéo các đầu ra được tạo ra để tăng độ tin cậy.
Sự Không Chắc Chắn và Dự Đoán Chọn Lọc
- Liên quan Đa Miền: Việc truyền đạt ước lượng về sự không chắc chắn là quan trọng trong những lĩnh vực nơi thông tin sai lệch có thể mang lại hậu quả nghiêm trọng, như y tế và pháp lý. Việc sử dụng khả năng của LLMs để biểu thị sự không chắc chắn và chọn lọc dự đoán khi tự tin thấp có thể là một công cụ quan trọng trong những lĩnh vực này để ngăn chặn việc phổ biến thông tin không chính xác.

Ứng dụng thực tế của những mô hình này không chỉ giới hạn trong việc trả lời câu hỏi. Chúng có thể được sử dụng để giáo dục bệnh nhân, hỗ trợ trong quá trình chẩn đoán, và thậm chí là đào tạo sinh viên y khoa. Tuy nhiên, việc triển khai của chúng phải được quản lý cẩn thận để tránh sự phụ thuộc vào Trí tuệ Nhân tạo mà thiếu quản lý đúng đắn của con người.
Khi kiến thức y học phát triển, LLMs cũng phải thích ứng và học hỏi. Điều này đòi hỏi các cơ chế để học và cập nhật liên tục, đảm bảo rằng các mô hình vẫn là thông tin và chính xác theo thời gian.