

RAG là kỹ thuật truy xuất thông tin bên ngoài nhằm bổ sung dữ liệu chưa được đào tạo trong mô hình ngôn ngữ tiền huấn luyện (LLM) mà bạn sử dụng nhằm tăng cường phản hồi cho ứng dụng của bạn trong một lĩnh vực cụ thể mà không cần phải xây dựng mô hình mới hoặc tối ưu hoá mô hình đòi hỏi nhiều công sức cũng như hạ tầng tính toán.
Ý tưởng về RAG có vẻ khá đơn giản: tìm và lấy đoạn văn bản có liên quan nhất và đưa nó vào lời nhắc gốc cho LLM, để LLM có thể truy cập vào các đoạn văn bản tham chiếu đó và có thể sử dụng chúng để tạo phản hồi. Nhưng có thể khá khó để có được một đường ống RAG chất lượng cao tạo ra kết quả chính xác mà bạn muốn trong các sản phẩm sẵn sàng sản xuất.
Trong bài viết này, chúng ta hãy cùng khám phá các kỹ thuật để cải thiện kết quả RAG cho ứng dụng LLM của bạn, từ cơ bản nhất đến nâng cao hơn. Chúng tôi cũng sẽ cung cấp một số mẹo/trường hợp thực tế từ kinh nghiệm xây dựng sản phẩm bằng RAG của riêng chúng tôi qua các dự án thực tế được triển khai.
RAG cơ bản
Hãy bắt đầu với RAG cơ bản nhất dành cho những người mới bắt đầu sử dụng RAG. Đây là quy trình ba bước đơn giản: lập chỉ mục, truy xuất và tạo kết quả.
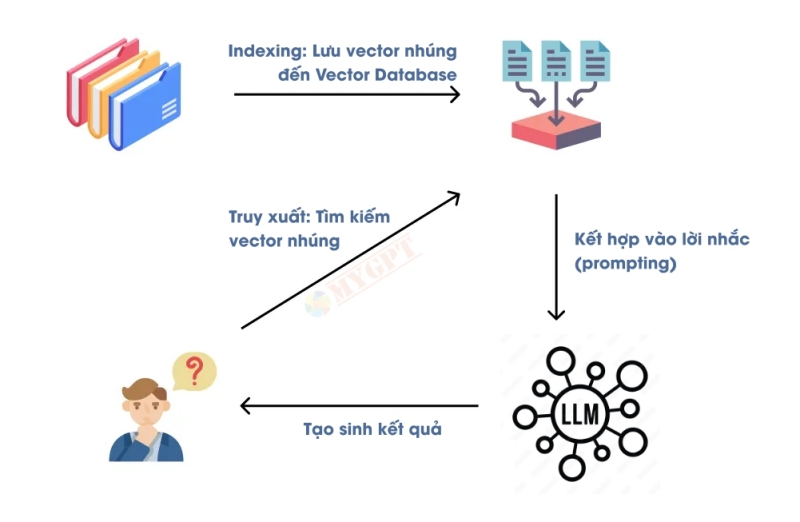
Quá trình lập chỉ mục là quá trình chuẩn bị dữ liệu của bạn cho quá trình truy xuất. Bạn nên thu thập mọi thứ bạn muốn LLM của mình biết, ví dụ như tài liệu sản phẩm, chính sách sản phẩm, trang web công ty, v.v., tùy thuộc vào những gì bạn muốn chatbot của mình thực hiện. Sau đó, bạn sẽ chia nhỏ dữ liệu thành các đoạn văn bản nhỏ hơn (để bạn có thể dễ dàng đưa các đoạn văn bản vào kích thước ngữ cảnh của LLM). Sau đó, bạn sẽ chuyển đổi các đoạn văn bản thành biểu diễn vectơ thông qua mô hình nhúng (để sau này bạn có thể dễ dàng tìm thấy các đoạn văn bản tương tự). Sau đó, bạn có thể lưu tất cả các cặp nhúng văn bản này trong cơ sở dữ liệu chỉ mục hoặc vectơ để sử dụng sau.
Quá trình truy xuất diễn ra khi người dùng truy vấn LLM. Sau khi người dùng đặt câu hỏi, bạn giữ lại truy vấn đó thay vì gửi trực tiếp đến LLM. Thay vào đó, bạn sẽ làm phong phú truy vấn bằng một số thông tin bổ sung từ các khối văn bản trong chỉ mục của mình. Bạn sẽ mã hóa truy vấn gốc của người dùng bằng cùng một mô hình nhúng, sau đó thực hiện tìm kiếm tương tự để tìm các khối văn bản tương tự nhất (và hầu hết thời gian là có liên quan nhất) trong cơ sở dữ liệu của mình.
Sau đó, để tạo sinh kết quả, bạn cần phối hợp các khối văn bản vào lời nhắc cùng các truy vấn gốc của người dùng (lịch sử trao đổi trước đó). LLM sẽ tạo câu trả lời với thông tin được cung cấp trong các khối văn bản đã truy xuất.
Sau đây là lời nhắc cơ bản với RAG:
Trả lời câu hỏi sau đây chỉ dựa trên thông tin đã cho. Nếu thông tin đã cho không đủ để trả lời câu hỏi, chỉ cần trả lời "Tôi không biết".
Câu hỏi: "<truy vấn gốc của người dùng>"
Thông tin đã cho: "<đoạn văn bản bạn lấy từ cơ sở dữ liệu>"Vì đây là một quy trình được công nhận rộng rãi hiện nay vì vậy đã có nhiều thư viện kết hợp tất cả các bước này cho các quy trình RAG. LlamaIndex và LangChain là hai thư viện phổ biến mà bạn có thể tìm thấy. Bản thân OpenAI cũng triển khai quy trình này trong GPT tùy chỉnh được hỗ trợ và tính năng trợ lý khi bạn tải tài liệu của mình lên. Nhiều cơ sở dữ liệu vector như Pinecone và Chroma cũng hỗ trợ việc tạo sinh và truy xuất dễ dàng trong RAG.
Quá trình này đơn giản và hiệu quả, nhưng trong thực tế, bạn sẽ phải đối mắt với vấn đề sau:
- RAG không thể lấy được các phần thông tin có liên quan nhất để tạo sinh. Khi lấy được một phần tương tự nhưng kết quả lại không liên quan, LLM có thể sẽ đưa ra câu trả lời không chính xác cho truy vấn ban đầu của người dùng.
- Các khối được RAG lấy ra không có ngữ cảnh chính xác. Đôi khi, các khối dữ liệu được lấy ra bỏ qua ngữ cảnh xung quanh chúng, khiến chúng trở nên vô dụng trong việc tạo ra các câu trả lời hữu ích hoặc thậm chí cung cấp thông tin trái ngược cho LLM.
- Các trường hợp truy vấn khác nhau của người dùng đòi hỏi các chiến lược truy xuất hoặc tạo sinh khác nhau.
- Cấu trúc dữ liệu của bạn có thể không phù hợp để tìm kiếm điểm tương tự thông qua các vector nhúng.
Ở phần tiếp theo, chúng ta sẽ tìm hiểu một số kỹ thuật để khắc phục những vấn đề này và cải thiện hiệu suất RAG.
Kỹ thuật cải thiện hiệu suất RAG
Qua nhiều dự án được triển khai thực tế với khách hàng, chúng tôi đã học được nhiều kỹ thuật để cải thiện hiệu suất RAG và tóm tắt một số bài học của khi sử dụng RAG. Trong phần này, chúng tôi sẽ trình bày nhiều kỹ thuật để cải thiện hiệu suất RAG ở 3 giai đoạn chính: trước khi truy xuất, trong khi truy xuất và sau khi truy xuất.
Kỹ thuật trước truy xuất
Các kỹ thuật truy xuất trước bao gồm các kỹ thuật có thể được sử dụng trong bước lập chỉ mục hoặc trước khi tìm kiếm các phần trong cơ sở dữ liệu.
Kỹ thuật đầu tiên là cải thiện chất lượng dữ liệu được lập chỉ mục của bạn. Trong lĩnh vực học máy, có một câu nói “rác vào, rác ra”. Nó cũng sẽ áp dụng đúng như vậy cho RAG, nhưng rất nhiều người đã bỏ qua bước nhàn chán, tỉ mỉ nhưng rất quan trọng này để tập trung vào việc tối ưu hóa cho các bước phía sau. Bạn không nên mong chờ đưa mọi tài liệu, dù có liên quan hay không, vào cơ sở dữ liệu vector của mình và hy vọng kết quả đầu ra điều tốt như nhau.
Để cải thiện chất lượng dữ liệu được lập chỉ mục, bạn nên: (1) xóa văn bản/tài liệu không liên quan cho tác vụ cụ thể của mình (2) định dạng lại dữ liệu được lập chỉ mục của bạn thành định dạng tương tự như những gì người dùng cuối của bạn có thể sử dụng (3) thêm siêu dữ liệu vào tài liệu của bạn để truy xuất hiệu quả và có mục tiêu.
Đây là một ví dụ từ kinh nghiệm của riêng chúng tôi. Các văn bản cần lấy là các bài tập toán, nhưng hai bài tập về các khái niệm khác nhau có thể giống nhau về mặt ngữ nghĩa. Ví dụ, nhiều bài tập có thể bắt đầu bằng câu “Nam có 8 quả táo vào ngày đầu tiên…”, nhưng chúng có thể sử dụng để kiểm tra các khái niệm toán học khác nhau như phép cộng, phép nhân và phép chia, mặc dù câu mở đầu giống nhau. Trong trường hợp này, tốt hơn là gắn thẻ các bài tập này bằng siêu dữ liệu về khái niệm cụ thể mà chúng kiểm tra (ví dụ: phép cộng, phép nhân, phép chia) và mức độ khó. Bằng cách này, chúng ta có thể xác định và chọn lọc bài tập dựa trên khái niệm chính xác và mức độ khó phù hợp, thay vì chỉ dựa vào câu mở đầu tương tự.
Một trường hợp rất điển hình khác là các khối có thể mất thông tin khi bị chia tách. Hãy xem xét một bài viết điển hình, trong đó các câu đầu tiên giới thiệu các thực thể bằng tên của chúng, trong khi các câu sau chỉ dựa vào đại từ để tham chiếu đến chúng. Các khối bị chia tách không chứa tên thực thể thực tế sẽ mất ý nghĩa ngữ nghĩa và sẽ không được truy xuất thông qua tìm kiếm vectơ. Do đó, việc thay thế đại từ bằng tên thực tế có thể cải thiện ý nghĩa ngữ nghĩa của các phần bị chia tách trong trường hợp này.
Kỹ thuật thứ hai là tối ưu hóa khối (chunk). Dựa trên nhiệm vụ phía sau của bạn là gì, bạn cần xác định độ dài tối ưu của khối là bao nhiêu và bạn muốn có bao nhiêu phần chồng chéo cho mỗi khối truy vấn nhận được. Nếu khối của bạn quá nhỏ, nó có thể không bao gồm tất cả thông tin mà LLM cần để trả lời truy vấn của người dùng; nếu khối quá lớn, nó có thể chứa quá nhiều thông tin không liên quan khiến LLM bối rối hoặc có thể quá lớn để phù hợp với kích thước ngữ cảnh.
Theo kinh nghiệm của riêng chúng tôi, bạn không cần phải tuân theo một phương pháp tối ưu hóa khối cho tất cả các bước trong quy trình của mình. Ví dụ, nếu quy trình của bạn bao gồm cả các tác vụ cấp cao như tóm tắt và các tác vụ cấp thấp như mã hóa dựa trên định nghĩa hàm, bạn có thể thử sử dụng kích thước khối lớn hơn để tóm tắt và sau đó là các khối nhỏ hơn để tham chiếu mã hóa.
Một kỹ thuật khác là viết lại truy vấn của người dùng trước khi cố gắng khớp nó trong cơ sở dữ liệu vector. Bản chất của bước này là chuyển đổi truy vấn của người dùng thành định dạng và nội dung tương tự như những gì có thể tìm thấy trong cơ sở dữ liệu vector của bạn. Kỹ thuật Query2Doc tạo ra các tài liệu giả và mở rộng truy vấn bằng các tài liệu như vậy. Tương tự như vậy, HyDE (nhúng tài liệu giả định) tạo ra một tài liệu giả định có liên quan đến truy vấn.
Sau đây là một số ví dụ về cách bạn có thể tạo tài liệu giả định:
# nếu tài liệu tham khảo của bạn là các bài viết trên blog.
prompt = f "Vui lòng tạo một đoạn văn từ bài viết trên blog về {user_query}"
# nếu tài liệu tham khảo của bạn là tài liệu mã ở định dạng markdown.
prompt = f "Vui lòng tạo tài liệu mã cho {user_query} ở định dạng markdown."Một nhược điểm khi sử dụng các kỹ thuật Query2Doc hoặc HyDE là các tài liệu giả định có thể trái ngược với các tài liệu thực tế hoặc hoàn toàn không đúng, điều này có thể dẫn đến việc truy xuất không chính xác. Để giải quyết vấn đề này, bạn có thể truy xuất các tài liệu có hoặc không có tài liệu giả định để bạn có thể áp dụng các kỹ thuật sau truy xuất mà tôi sẽ đề cập sau để tìm văn bản tham chiếu tốt nhất.
Khi truy vấn của người dùng phức tạp và có thể cần nhiều văn bản tham chiếu, bạn có thể chia nhỏ truy vấn thành nhiều truy vấn phụ bằng LLM rồi tìm các đoạn văn bản có liên quan cho từng truy vấn. Ví dụ, nếu người dùng hỏi một câu hỏi về hai điều khác nhau “Sự khác biệt giữa ChomaDB và Weaviate là gì?”, câu hỏi có thể được chia nhỏ thành “ChromaDB là gì?” và “Weaviate là gì?”.
Sau đây là một ví dụ để yêu cầu LLM của bạn phân tích các truy vấn:
Vui lòng diễn đạt lại truy vấn sau thành ba hoặc ít hơn các truy vấn phụ, sao cho mỗi truy vấn phụ chỉ chứa một chủ đề. Hiển thị mỗi truy vấn phụ trong mỗi dòng mới. Truy vấn: "<truy vấn người dùng gốc>"Nếu chatbot hoặc tác nhân của bạn có thể xử lý nhiều tác vụ hạ nguồn và các định dạng khác nhau của truy vấn người dùng, bạn có thể cân nhắc sử dụng định tuyến truy vấn, trong đó bạn định tuyến động truy vấn đến các quy trình RAG khác nhau. Ví dụ: nếu người dùng của bạn đang yêu cầu một câu trả lời cụ thể cho một câu hỏi, bạn có thể định tuyến họ đến các khối truy vấn cụ thể; nếu người dùng của bạn đang yêu cầu tóm tắt chung, bạn có thể định tuyến họ đến bản tóm tắt được tạo đệ quy của nhiều tài liệu đã truy xuất; nếu người dùng của bạn đang yêu cầu so sánh giữa hai tài liệu, bạn có thể cần sử dụng kỹ thuật truy vấn phụ được đề cập ở trên. Bạn có thể sử dụng chính LLM để định tuyến hoặc sử dụng tính năng ghép từ khóa/nhúng tương tự để định tuyến.
Kỹ thuật trong khi truy xuất
Sau khi đã hoàn tất các bước chuẩn bị truy xuất, bạn có thể cải thiện thêm kết quả truy xuất ở bước thứ hai trong quy trình RAG với các nội dung dưới đây.
Kỹ thuật đầu tiên thường bị bỏ qua vì mọi người chỉ làm theo những gì người khác đang làm – bám sát vào tìm kiếm tương tự trên các vectơ. Bạn có thể và nên cân nhắc sử dụng các phương pháp tìm kiếm thay thế để thay vì chỉ tìm kiếm tương tự vectơ thì bạn có thể bổ sung cho nó thông qua tìm kiếm kết hợp (SQL search, Graph search…). Mặc dù tìm kiếm tương tự vectơ có thể tìm thấy các tài liệu có liên quan trong hầu hết các trường hợp, tuy nhiên đối với một số trường hợp hoặc cấu trúc dữ liệu, tốt hơn là sử dụng tìm kiếm toàn văn bản, truy vấn có cấu trúc, tìm kiếm dựa trên đồ thị hoặc phương pháp tìm kiếm kết hợp để giải quyết vấn đề.
Ví dụ, nếu dữ liệu văn bản của bạn chứa nhiều đoạn rất giống nhau về mặt ngữ nghĩa chỉ khác nhau ở một số từ khóa hoặc nếu dữ liệu văn bản của bạn chứa quá nhiều văn bản chung không cụ thể, thì tốt hơn là tìm kiếm bằng cách khớp từ khóa chính xác. Ví dụ, tìm kiếm tên thuốc cụ thể chỉ khác nhau ở một nhóm chức năng hoặc hàng chục nghìn tên sản phẩm tương tự trong thương mại điện tử có thể được hưởng lợi từ các bộ lọc và tìm kiếm toàn văn (full-text search).
Một kỹ thuật khác thường bị bỏ qua là thử nghiệm và sử dụng các mô hình nhúng khác nhau cho nhiệm vụ cụ thể của bạn. Nhiều người thậm chí sẽ không nghĩ đến điều này vì các cơ sở dữ liệu hoặc framework vector có tùy chọn nhúng mặc định và họ chỉ sử dụng nó. Nhưng các mô hình nhúng khác nhau thực sự có thể nắm bắt thông tin ngữ nghĩa khác nhau và có thể phù hợp với các nhiệm vụ khác nhau. Một mô hình nhúng hữu ích là Nhúng có hướng dẫn (instruct model), cho phép bạn cung cấp các hướng dẫn cụ thể về loại dữ liệu bạn đang nhúng và nhiệm vụ của bạn. Bạn cũng có thể tham khảo bảng xếp hạng MTEB, đây là điểm chuẩn về các mô hình nhúng văn bản. Hãy đảm bảo kiểm tra các mô hình vì xếp hạng cao trên bảng xếp hạng không có nghĩa là chúng sẽ hoạt động tốt nhất cho nhiệm vụ cụ thể của bạn.
Bên cạnh đó, cũng có một số điều chỉnh mà bạn có thể thực hiện trong quá trình truy xuất của mình để làm cho quá trình truy xuất có liên quan hơn. Truy xuất Small2big, đệ quy hoặc nhận biết ngữ cảnh là các kỹ thuật ban đầu truy xuất các khối dữ liệu nhỏ hơn, có nhiều khả năng khớp với truy vấn hơn do có nhiều chi tiết và tính cụ thể hơn, sau đó tiếp tục truy xuất các tài liệu gốc hoặc các khối văn bản lớn hơn bao quanh các khối nhỏ hơn đó để bao gồm nhiều ngữ cảnh hơn. Chúng đảm bảo rằng bạn truy xuất các khối có liên quan cùng với tất cả ngữ cảnh cần thiết. Một số khuôn khổ cung cấp hỗ trợ cho loại truy xuất này, như ParentDocumentRetriever trong LangChain, cửa sổ Câu và tham chiếu nút trong LlamaIndex.
Nếu bạn có thể truy xuất tài liệu từ nhỏ đến lớn, bạn cũng có thể thực hiện theo cách khác với truy xuất phân cấp đi từ tổng quát hơn đến cụ thể hơn. Ví dụ, bạn có thể tạo hai lớp dữ liệu của mình, một lớp với các khối gốc và lớp còn lại với các bản tóm tắt của các khối. Trước tiên, bạn tìm kiếm chỉ mục tóm tắt để tìm các tài liệu có liên quan nhất và sau đó thực hiện tìm kiếm lại trong các tài liệu đó để tìm các khối cụ thể. Theo cách này, bạn có thể nhanh chóng lọc ra các tài liệu không liên quan trong lần chạy đầu tiên và sau đó tìm thông tin thực tế để trả lời câu hỏi trong lần chạy thứ hai.
Tương tự, bạn có thể sử dụng tìm kiếm đệ quy với tìm kiếm đồ thị. Phương pháp này kết hợp tìm kiếm tương tự với cấu trúc dữ liệu đồ thị. Trước tiên, bạn tìm khối có liên quan nhất với tìm kiếm tương tự vectơ và sau đó khám phá các nút liên quan đến các khối đó để khám phá thêm thông tin hữu ích. Ví dụ, nếu bạn có cơ sở dữ liệu với các tài liệu được liên kết như Notion hoặc Obsidian, bạn có thể dễ dàng tìm thấy các tài liệu liên quan cho LLM thông qua các liên kết. LlamaIndex hỗ trợ các tìm kiếm tương tự như thế này với mô-đun RecursiveRetriever.
Ngoài ra còn có nhiều cách tác nhân hơn để thực hiện truy xuất bằng cách tạo một tác nhân truy xuất trước tiên với một công cụ/chức năng để truy vấn tài liệu và để nó quyết định xem có nên tìm kiếm thêm thông tin hay chỉ trả về các khối đã truy xuất có liên quan cho tác nhân ban đầu để trả lời truy vấn của người dùng. Nhưng các kỹ thuật này thường đòi hỏi thời gian phản hồi lâu hơn nhiều và có thể không ổn định nên có thể không phải là lựa chọn tốt cho sản xuất. Hy vọng rằng, với các mô hình mạnh hơn và suy luận nhanh hơn, chúng ta có thể có được kết quả tốt hơn theo hướng này.
Kỹ thuật sau truy xuất
Sau khi bạn lấy được các khối dữ liệu liên quan từ cơ sở dữ liệu của mình, vẫn còn một số kỹ thuật khác để cải thiện chất lượng tạo sinh. Bạn có thể sử dụng một hoặc nhiều kỹ thuật sau dựa trên bản chất công việc và định dạng của các khối văn bản của bạn.
Nếu nhiệm vụ của bạn liên quan nhiều hơn đến một khối dữ liệu cụ thể, một kỹ thuật thường được sử dụng là xếp hạng lại hoặc chấm điểm. Như chúng tôi đã đề cập trước đó, điểm cao trong tìm kiếm độ tương đồng vectơ không có nghĩa là nó sẽ luôn có mức độ liên quan cao nhất. Bạn nên thực hiện vòng xếp hạng lại hoặc chấm điểm thứ hai để chọn ra các khối văn bản thực sự hữu ích cho việc tạo câu trả lời. Đối với việc xếp hạng lại hoặc chấm điểm, bạn có thể yêu cầu LLM xếp hạng mức độ liên quan của các tài liệu hoặc bạn có thể sử dụng một số phương pháp khác như tần suất từ khóa hoặc khớp siêu dữ liệu để tinh chỉnh lựa chọn trước khi chuyển các tài liệu đó cho LLM để tạo sinh câu trả lời cuối cùng.
Mặt khác, nếu nhiệm vụ của bạn liên quan đến nhiều khối dữ liệu – như tóm tắt hoặc so sánh. Bạn có thể thực hiện một số lần nén thông tin như một thao tác hậu xử lý trước khi chuyển thông tin đến LLM để giảm nhiễu hoặc vượt quá độ dài ngữ cảnh. Ví dụ, trước tiên bạn có thể tóm tắt, diễn giải hoặc trích xuất các điểm chính từ mỗi khối, sau đó chuyển thông tin đã tổng hợp, cô đọng đến LLM để phục vụ cho việc tạo sinh kết quả.
Cân bằng chất lượng và độ trễ phản hồi
Ngoài ra còn có một số mẹo khác mà chúng tôi thấy hữu ích trong việc cải thiện và cân bằng chất lượng thế hệ và độ trễ. Trong các sản phẩm thực tế, người dùng của bạn có thể không có thời gian để chờ quy trình RAG nhiều bước trong ứng dụng của bạn hoàn tất, đặc biệt là khi có một chuỗi các cuộc gọi đến LLM. Các lựa chọn sau đây có thể hữu ích nếu bạn muốn cải thiện độ trễ của ứng dụng RAG của mình.
Đầu tiên là sử dụng một mô hình nhỏ hơn, nhanh hơn cho một số bước. Bạn không nhất thiết phải sử dụng mô hình mạnh nhất (thường là chậm nhất) cho tất cả các bước trong quy trình RAG. Ví dụ, đối với một số truy vấn dễ viết lại, tạo tài liệu giả định hoặc tóm tắt một đoạn văn bản, bạn có thể sử dụng một mô hình nhanh hơn (như mô hình cục bộ 7B hoặc 13B). Một số mô hình này thậm chí có thể tạo ra đầu ra cuối cùng chất lượng cao cho người dùng.
Kỹ thuật tiếp theo là thực hiện một số bước trung gian chạy song song. Bạn không phải lúc nào cũng phải đợi một bước hoàn tất trước khi chuyển sang bước thứ hai. Bạn có thể thực hiện một số bước trung gian như tìm kiếm lai hoặc tóm tắt nhiều khối song song. Để thực hiện điều này, có thể bạn cần phải sửa đổi đáng kể các framework RAG hoặc tự tạo cách RAG riêng của mình, nhưng nó có thể giảm đáng kể thời gian cho đầu ra cuối cùng.
Kỹ thuật thứ ba là để LLM đưa ra nhiều lựa chọn thay vì tạo ra văn bản dài khi có thể. Ví dụ, trong việc xếp hạng lại/ghi điểm, bạn có thể yêu cầu LLM chỉ liệt kê điểm/xếp hạng của các đoạn văn bản thay vì tạo lại chúng hoặc bao gồm các giải thích chi tiết.
Một mẹo hữu ích khác là triển khai bộ nhớ đệm cho các câu hỏi thường gặp hoặc truy vấn phổ biến. Nếu truy vấn mới rất giống hoặc gần giống với truy vấn cũ, hệ thống có thể cung cấp câu trả lời ngay lập tức mà không cần trải qua toàn bộ quy trình RAG mỗi lần sử dụng. Nếu truy vấn mới có phần giống nhưng vẫn có liên quan, bạn thậm chí có thể đưa câu trả lời của truy vấn trước đó vào LLM làm tài liệu tham khảo để tạo câu trả lời mới.
Kết luận
Trong bài viết này, chúng tôi đã đề cập đến nhiều kỹ thuật có thể cải thiện quy trình RAG trong ứng dụng được LLM của bạn, bao gồm:
– Quy trình RAG cơ bản: lập chỉ mục, truy xuất và tạo sinh.
– Kỹ thuật trước truy xuất:
- Cải thiện chất lượng dữ liệu được lập chỉ mục của bạn
- Tối ưu hóa khối
- Viết lại truy vấn
– Kỹ thuật trong khi truy xuất
- Sử dụng phương pháp tìm kiếm thay thế
- Sử dụng các mô hình nhúng khác nhau
- Small2big, đệ quy hoặc truy xuất theo ngữ cảnh
- Truy xuất theo thứ bậc
– Kỹ thuật sau khi truy xuất
- Xếp hạng lại hoặc ghi điểm các khối đã lấy được
- Nén thông tin
– Cân bằng chất lượng và độ trễ
- Sử dụng các mô hình nhỏ hơn, nhanh hơn cho một số bước
- Làm cho các bước trung gian chạy song song
- Hãy để LLM đưa ra lựa chọn thay vì thế hệ
- Triển khai bộ nhớ đệm
Bạn có thể sử dụng một hoặc nhiều kỹ thuật này trong quy trình RAG của mình, nó sẽ giúp cho ứng dụng của bạn chính xác và hiệu quả hơn. Nếu bạn chưa thể triển khai nó, đừng ngại lên hệ với MyGPT, bằng kinh nghiệm của mình, chúng tôi có thể giúp tạo ra một ứng dụng RAG riêng của bạn với độ chính xác cao nhất trong khoảng thời gian ngắn nhất.