

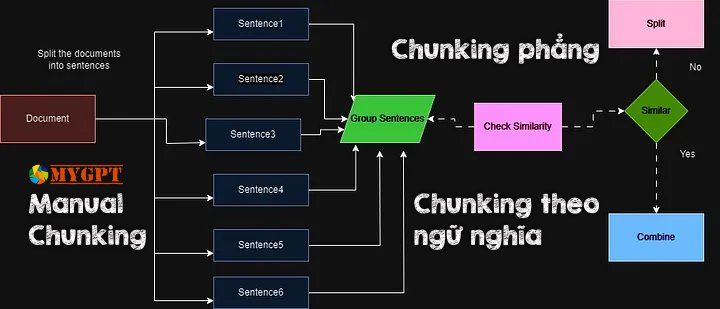
Chunking là gì?
Chúng ta biết rằng, các mô hình ngôn ngữ đều cung cấp một cửa sổ ngữ cảnh cố định để quy định kích thước prompt đầu vào trước khi suy diễn, vì vậy để đáp ứng yêu cầu này khi xử lý những dữ liệu có kích thước lớn hơn quy định của một cửa sổ ngữ cảnh thì chúng ta thường sẽ phải chia nhỏ dữ liệu thành các phân đoạn nhỏ hơn phù hợp với ngữ cảnh. Kỹ thuật này được gọi là chunking.
RAG là gì?
Mô hình ngôn ngữ lớn (LLM), mặc dù có khả năng tạo ra văn bản vừa có ý nghĩa vừa đúng ngữ pháp, nhưng những LLM này lại gặp phải một vấn đề gọi là ảo giác. Ảo giác trong LLM là khái niệm trong đó LLM tự tin tạo ra các câu trả lời sai, nghĩa là nó tạo ra các câu trả lời sai theo cách khiến chúng ta tin rằng đó là sự thật. Đây là một vấn đề lớn kể từ khi LLM được giới thiệu. Những ảo giác này dẫn đến những câu trả lời sai và sai về mặt thực tế. Do đó giải pháp tăng cường truy xuất (RAG) đã được giới thiệu.
Trong kỹ thuật RAG, chúng ta đưa các phân đoạn dữ liệu sau khi được chặt thành dạng biểu diễn bằng số gọi là nhúng vectơ, trong đó một vectơ nhúng đại diện cho một đoạn tài liệu (chunk) và lưu trữ chúng trong cơ sở dữ liệu được gọi là kho lưu trữ vectơ. Các mô hình cần thiết để mã hóa các đoạn này thành các phần nhúng được gọi là mô hình mã hóa hoặc bộ mã hóa kép. Các bộ mã hóa này được đào tạo trên một kho dữ liệu lớn, do đó làm cho chúng đủ mạnh để mã hóa các khối tài liệu trong một biểu diễn nhúng vectơ duy nhất.
Việc truy xuất phụ thuộc rất nhiều vào cách các khối được biểu thị và lưu trữ trong kho vector. Nói chung, việc tìm kích thước đoạn văn phù hợp cho bất kỳ văn bản cụ thể nào là một vấn đề khó.
Cải thiện việc truy xuất và kho vector nhúng có thể được thực hiện bằng nhiều phương pháp truy xuất khác nhau. Nhưng nó cũng có thể được thực hiện bằng chiến lược chunking tốt hơn.
Các phương pháp phân đoạn khác nhau bao gồm:
- Phân chia kích thước cố định
- Phân đoạn đệ quy
- Phân đoạn tài liệu cụ thể
- Phân đoạn ngữ nghĩa
- Phân đoạn tác nhân
Phân đoạn kích thước cố định: Đây là cách tiếp cận phổ biến và đơn giản nhất để phân đoạn, chúng ta chỉ cần quyết định số lượng ký tự trong phân đoạn của mình tùy ý, cùng với một mức độ trùng lặp nhất định. Việc giữ lại một số điểm trùng lặp giữa các khối sẽ đảm bảo tính liên tục giữa của ngữ cảnh không bị mất đi.
Phân đoạn có kích thước cố định là cách thức tốt nhất trong hầu hết các trường hợp phổ biến. So với các hình thức chunking khác, chunking có kích thước cố định rẻ về mặt tính toán và sử dụng đơn giản vì nó không yêu cầu sử dụng bất kỳ thư viện NLP nào.
Phân đoạn đệ quy: Phân đoạn đệ quy chia văn bản đầu vào thành các phần cơ bản nhỏ hơn về cấu trúc bằng cách phân cấp và lặp lại bằng cách sử dụng một bộ dấu phân cách. Nếu nỗ lực phân tách văn bản ban đầu không tạo ra các khối có kích thước hoặc cấu trúc mong muốn thì phương thức sẽ tự gọi đệ quy trên các khối kết quả bằng một dấu phân cách hoặc tiêu chí khác cho đến khi đạt được kích thước hoặc cấu trúc khối mong muốn. Điều này có nghĩa là mặc dù các khối không có cùng kích thước nhưng chúng vẫn có kích thước tương tự. Tận dụng những ưu điểm của khối có kích thước cố định và sự chồng chéo.
Phân đoạn tài liệu cụ thể: Chiến thuật này tính đến cấu trúc của tài liệu. Thay vì sử dụng một số ký tự nhất định hoặc quy trình đệ quy, chúng ta tạo ra các đoạn phù hợp với các phần logic của tài liệu như đoạn văn hoặc phần phụ. Bằng cách này, ta sẽ duy trì được tổ chức nội dung gốc của tài liệu, từ đó giữ cho văn bản mạch lạc. Cách này sẽ làm cho thông tin được truy xuất phù hợp và hữu ích hơn, đặc biệt đối với các tài liệu có cấu trúc với các phần được xác định rõ ràng. Nó có thể xử lý các định dạng như Markdown, Html, v.v.
Phân đoạn ngữ nghĩa: Phân đoạn ngữ nghĩa xem xét các mối quan hệ trong văn bản. Nó chia văn bản thành các phần có ý nghĩa và hoàn chỉnh về mặt ngữ nghĩa. Cách tiếp cận này đảm bảo tính toàn vẹn của thông tin trong quá trình truy xuất, dẫn đến kết quả chính xác hơn và phù hợp với ngữ cảnh hơn. Phương pháp này chậm hơn so với chiến lược chunking trước đó.
Agentic Chunk: Giả thuyết ở đây là xử lý tài liệu theo cách mà con người vẫn làm.
- Chúng ta bắt đầu từ đầu tài liệu, coi phần đầu tiên là một đoạn.
- Chúng ta tiếp tục đi xuống tài liệu, quyết định xem một câu hoặc đoạn thông tin mới có thuộc về đoạn đầu tiên hay nên bắt đầu một đoạn mới
- Chúng ta tiếp tục điều này cho đến khi đi đến cuối tài liệu.
Cách tiếp cận này vẫn đang được thử nghiệm và chưa hoàn toàn sẵn sàng cho các giải đấu lớn do cần có thời gian để xử lý và nhiều lệnh gọi LLM từ đó làm tăng chi phí của hệ thống. Hiện chưa có triển khai nào trong các thư viện công cộng được công bố.
Trong bài viết này, chúng ta sẽ tiến hành thử nghiệm với Ngữ nghĩa và Đệ quy.
Đánh giá các phương pháp:
- Tải tài liệu
- Phân đoạn Tài liệu bằng hai phương pháp sau: Phân đoạn ngữ nghĩa và Truy xuất đệ quy .
- Đánh giá các cải tiến về chất và lượng với RAGAS
Phân đoạn ngữ nghĩa
Phân đoạn ngữ nghĩa bao gồm việc lấy các phần nhúng của mỗi câu trong tài liệu, so sánh sự giống nhau của tất cả các câu với nhau và sau đó nhóm các câu có phần nhúng tương tự nhất lại với nhau.
Bằng cách tập trung vào ý nghĩa và ngữ cảnh của văn bản, Phân đoạn ngữ nghĩa nâng cao đáng kể chất lượng truy xuất. Đó là một lựa chọn hàng đầu khi việc duy trì tính toàn vẹn ngữ nghĩa của văn bản là rất quan trọng.
Giả thuyết ở đây là chúng ta có thể sử dụng cách nhúng các câu riêng lẻ để tạo ra các đoạn có ý nghĩa hơn. Ý tưởng cơ bản như sau: –
- Chia tài liệu thành các câu dựa trên dấu phân cách (.,?,!)
- Lập chỉ mục từng câu dựa trên vị trí.
- Nhóm: Chọn số lượng câu ở mỗi bên. Thêm bộ đệm các câu ở hai bên câu đã chọn của chúng tôi.
- Tính khoảng cách giữa các nhóm câu.
- Hợp nhất các nhóm dựa trên sự tương đồng, tức là giữ các câu tương tự lại với nhau.
- Tách các câu không giống nhau.
Công nghệ được sử dụng
- Langchain: LangChain là một framework mã nguồn mở được thiết kế để đơn giản hóa việc tạo các ứng dụng bằng mô hình ngôn ngữ lớn (LLM). Nó cung cấp giao diện chuẩn cho chuỗi, nhiều tích hợp với các công cụ khác và chuỗi đầu cuối cho các ứng dụng phổ biến.
- LLM: Bộ xử lý ngôn ngữ (LPU) của Groq là một công nghệ tiên tiến được thiết kế để nâng cao đáng kể hiệu suất tính toán AI, đặc biệt là cho các Mô hình ngôn ngữ lớn (LLM). Mục tiêu chính của hệ thống Groq LPU là cung cấp trải nghiệm thời gian thực, độ trễ thấp với hiệu suất suy luận vượt trội.
- Mô hình nhúng: FastEmbed là một thư viện Python nhỏ, nhẹ, nhanh, được xây dựng để tạo nhúng.
- Đánh giá: Ragas cung cấp các số liệu được thiết kế riêng để đánh giá từng thành phần trong quy trình RAG của bạn một cách riêng biệt.
Triển khai mã
Cài đặt các thành phần phụ thuộc cần thiết:
!pip cài đặt -qU langchain_thử nghiệm langchain_openai langchain_community langchain ragas chromadb langchain-groq fastembed pypdf openailangchain==0.1.16
langchain-community==0.0.34
langchain-core==0.1.45
langchain-experimental==0.0.57
langchain-groq==0.1.2
langchain-openai==0.1.3
langchain-text-splitters==0.0.1
langcodes==3.3.0
langsmith==0.1.49
chromadb==0.4.24
ragas==0.1.7
fastembed==0.2.6Tải tài liệu
! wget "https://arxiv.org/pdf/1810.04805.pdf"Xử lý nội dung PDF tải về
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
#
loader = PyPDFLoader("1810.04805.pdf")
documents = loader.load()
#
print(len(documents))Thực hiện chặt bằng thư viện RecursiveCharacterTextSplitting
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
length_function=len,
is_separator_regex=False
)
#
naive_chunks = text_splitter.split_documents(documents)
for chunk in naive_chunks[10:15]:
print(chunk.page_content+ "\n")
###########################RESPONSE###############################
BERT BERT
E[CLS] E1 E[SEP] ... ENE1’... EM’
C
T1
T[SEP] ...
TN
T1’...
TM’
[CLS] Tok 1 [SEP] ... Tok NTok 1 ... TokM
Question Paragraph Start/End Span
BERT
E[CLS] E1 E[SEP] ... ENE1’... EM’
C
T1
T[SEP] ...
TN
T1’...
TM’
[CLS] Tok 1 [SEP] ... Tok NTok 1 ... TokM
Masked Sentence A Masked Sentence B
Pre-training Fine-Tuning NSP Mask LM Mask LM
Unlabeled Sentence A and B Pair SQuAD
Question Answer Pair NER MNLI Figure 1: Overall pre-training and fine-tuning procedures for BERT. Apart from output layers, the same architec-
tures are used in both pre-training and fine-tuning. The same pre-trained model parameters are used to initialize
models for different down-stream tasks. During fine-tuning, all parameters are fine-tuned. [CLS] is a special
symbol added in front of every input example, and [SEP] is a special separator token (e.g. separating ques-
tions/answers).
ing and auto-encoder objectives have been used
for pre-training such models (Howard and Ruder,
2018; Radford et al., 2018; Dai and Le, 2015).
2.3 Transfer Learning from Supervised Data
There has also been work showing effective trans-
fer from supervised tasks with large datasets, such
as natural language inference (Conneau et al.,
2017) and machine translation (McCann et al.,
2017). Computer vision research has also demon-
strated the importance of transfer learning from
large pre-trained models, where an effective recipe
is to fine-tune models pre-trained with Ima-
geNet (Deng et al., 2009; Yosinski et al., 2014).
3 BERT
We introduce BERT and its detailed implementa-
tion in this section. There are two steps in our
framework: pre-training and fine-tuning . Dur-
ing pre-training, the model is trained on unlabeled
data over different pre-training tasks. For fine-
tuning, the BERT model is first initialized with
the pre-trained parameters, and all of the param-
eters are fine-tuned using labeled data from the
downstream tasks. Each downstream task has sep-
arate fine-tuned models, even though they are ini-
tialized with the same pre-trained parameters. The
question-answering example in Figure 1 will serve
as a running example for this section.
A distinctive feature of BERT is its unified ar-
chitecture across different tasks. There is mini-mal difference between the pre-trained architec-
ture and the final downstream architecture.
Model Architecture BERT’s model architec-
ture is a multi-layer bidirectional Transformer en-
coder based on the original implementation de-
scribed in Vaswani et al. (2017) and released in
thetensor2tensor library.1Because the use
of Transformers has become common and our im-
plementation is almost identical to the original,
we will omit an exhaustive background descrip-
tion of the model architecture and refer readers to
Vaswani et al. (2017) as well as excellent guides
such as “The Annotated Transformer.”2
In this work, we denote the number of layers
(i.e., Transformer blocks) as L, the hidden size as
H, and the number of self-attention heads as A.3
We primarily report results on two model sizes:
BERT BASE (L=12, H=768, A=12, Total Param-
eters=110M) and BERT LARGE (L=24, H=1024,
A=16, Total Parameters=340M).
BERT BASE was chosen to have the same model
size as OpenAI GPT for comparison purposes.
Critically, however, the BERT Transformer uses
bidirectional self-attention, while the GPT Trans-
former uses constrained self-attention where every
token can only attend to context to its left.4
1https://github.com/tensorflow/tensor2tensor
2http://nlp.seas.harvard.edu/2018/04/03/attention.html
3In all cases we set the feed-forward/filter size to be 4H,
i.e., 3072 for the H= 768 and 4096 for the H= 1024 .
4We note that in the literature the bidirectional Trans-
Input/Output Representations To make BERT
handle a variety of down-stream tasks, our input
representation is able to unambiguously represent
both a single sentence and a pair of sentences
(e.g.,⟨Question, Answer⟩) in one token sequence.
Throughout this work, a “sentence” can be an arbi-
trary span of contiguous text, rather than an actual
linguistic sentence. A “sequence” refers to the in-
put token sequence to BERT, which may be a sin-
gle sentence or two sentences packed together.
We use WordPiece embeddings (Wu et al.,
2016) with a 30,000 token vocabulary. The first
token of every sequence is always a special clas-
sification token ( [CLS] ). The final hidden state
corresponding to this token is used as the ag-
gregate sequence representation for classification
tasks. Sentence pairs are packed together into a
single sequence. We differentiate the sentences in
two ways. First, we separate them with a special
token ( [SEP] ). Second, we add a learned embed-Triển khai embedding
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
embed_model = FastEmbedEmbeddings(model_name="BAAI/bge-base-en-v1.5")Thiết lập API key đến mô hình
from google.colab import userdata
from groq import Groq
from langchain_groq import ChatGroq
#
groq_api_key = userdata.get("GROQ_API_KEY")Thực hiện chặt phân đoạn ngữ nghĩa bằng thư viện SemanticChunker:
# This is a long document we can split up.
with open("../../state_of_the_union.txt") as f:
state_of_the_union = f.read()
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
text_splitter = SemanticChunker(OpenAIEmbeddings())
docs = text_splitter.create_documents([state_of_the_union])
print(docs[0].page_content)Xem thêm hướng dẫn về Langchain Sematic chunking: Xem thêm
Ở đây chúng ta sẽ sử dụng ngưỡng `phần trăm` làm ví dụ – nhưng có ba chiến lược khác nhau mà bạn có thể sử dụng trên Phân đoạn ngữ nghĩa):
– percentile (mặc định) – Trong phương pháp này, tất cả sự khác biệt giữa các câu đều được tính toán và sau đó bất kỳ sự khác biệt nào lớn hơn phân vị X sẽ được phân chia.
– standard_deviation – Trong phương pháp này, bất kỳ chênh lệch nào lớn hơn X độ lệch chuẩn đều được phân chia.
– interquartile – Trong phương pháp này, khoảng cách liên tứ phân vị được sử dụng để phân chia các khối.
LƯU Ý: Phương pháp này hiện đang thử nghiệm và không ở dạng cuối cùng ổn định – mong đợi các bản cập nhật và cải tiến trong những tháng tới
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
semantic_chunker = SemanticChunker(embed_model, breakpoint_threshold_type="percentile")
#
semantic_chunks = semantic_chunker.create_documents([d.page_content for d in documents])
#
for semantic_chunk in semantic_chunks:
if "Effect of Pre-training Tasks" in semantic_chunk.page_content:
print(semantic_chunk.page_content)
print(len(semantic_chunk.page_content))
#############################RESPONSE###############################
Dev Set
Tasks MNLI-m QNLI MRPC SST-2 SQuAD
(Acc) (Acc) (Acc) (Acc) (F1)
BERT BASE 84.4 88.4 86.7 92.7 88.5
No NSP 83.9 84.9 86.5 92.6 87.9
LTR & No NSP 82.1 84.3 77.5 92.1 77.8
+ BiLSTM 82.1 84.1 75.7 91.6 84.9
Table 5: Ablation over the pre-training tasks using the
BERT BASE architecture. “No NSP” is trained without
the next sentence prediction task. “LTR & No NSP” is
trained as a left-to-right LM without the next sentence
prediction, like OpenAI GPT. “+ BiLSTM” adds a ran-
domly initialized BiLSTM on top of the “LTR + No
NSP” model during fine-tuning. ablation studies can be found in Appendix C. 5.1 Effect of Pre-training Tasks
We demonstrate the importance of the deep bidi-
rectionality of BERT by evaluating two pre-
training objectives using exactly the same pre-
training data, fine-tuning scheme, and hyperpa-
rameters as BERT BASE :
No NSP : A bidirectional model which is trained
using the “masked LM” (MLM) but without the
“next sentence prediction” (NSP) task. LTR & No NSP : A left-context-only model which
is trained using a standard Left-to-Right (LTR)
LM,
Khởi tạo Vectorstore
from langchain_community.vectorstores import Chroma
semantic_chunk_vectorstore = Chroma.from_documents(semantic_chunks, embedding=embed_model)Chúng tôi sẽ “giới hạn” trình truy xuất ngữ nghĩa của mình ở mức k = 1 để chứng minh sức mạnh của chiến lược phân đoạn ngữ nghĩa trong khi vẫn duy trì số lượng mã thông báo tương tự giữa bối cảnh được truy xuất ngữ nghĩa và ngữ cảnh đơn giản.
Khởi tạo bước truy xuất
semantic_chunk_retriever = semantic_chunk_vectorstore.as_retriever(search_kwargs={"k" : 1})
semantic_chunk_retriever.invoke("Describe the Feature-based Approach with BERT?")
########################RESPONSE###################################
[Document(page_content='The right part of the paper represents the\nDev set results. For the feature-based approach,\nwe concatenate the last 4 layers of BERT as the\nfeatures, which was shown to be the best approach\nin Section 5.3. From the table it can be seen that fine-tuning is\nsurprisingly robust to different masking strategies. However, as expected, using only the M ASK strat-\negy was problematic when applying the feature-\nbased approach to NER. Interestingly, using only\nthe R NDstrategy performs much worse than our\nstrategy as well.')]Khởi tạo bước tăng cường (Augmentation)
from langchain_core.prompts import ChatPromptTemplate
rag_template = """\
Use the following context to answer the user's query. If you cannot answer, please respond with 'I don't know'.
User's Query:
{question}
Context:
{context}
"""
rag_prompt = ChatPromptTemplate.from_template(rag_template)Khởi tạo bước sản sinh câu trả lời
chat_model = ChatGroq(temperature=0,
model_name="mixtral-8x7b-32768",
api_key=userdata.get("GROQ_API_KEY"),)Tại RAG Pipeline cho Sematic Chunking
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
semantic_rag_chain = (
{"context" : semantic_chunk_retriever, "question" : RunnablePassthrough()}
| rag_prompt
| chat_model
| StrOutputParser()
)Câu hỏi 1
semantic_rag_chain.invoke("Describe the Feature-based Approach with BERT?")
################ RESPONSE ###################################
The feature-based approach with BERT, as mentioned in the context, involves using BERT as a feature extractor for a downstream natural language processing task, specifically Named Entity Recognition (NER) in this case.
To use BERT in a feature-based approach, the last 4 layers of BERT are concatenated to serve as the features for the task. This was found to be the most effective approach in Section 5.3 of the paper.
The context also mentions that fine-tuning BERT is surprisingly robust to different masking strategies. However, when using the feature-based approach for NER, using only the MASK strategy was problematic. Additionally, using only the RND strategy performed much worse than the proposed strategy.
In summary, the feature-based approach with BERT involves using the last 4 layers of BERT as features for a downstream NLP task, and fine-tuning these features for the specific task. The approach was found to be robust to different masking strategies, but using only certain strategies was problematic for NER.Câu hỏi 2
semantic_rag_chain.invoke("What is SQuADv2.0?")
################ RESPONSE ###################################
SQuAD v2.0, or Squad Two Point Zero, is a version of the Stanford Question Answering Dataset (SQuAD) that extends the problem definition of SQuAD 1.1 by allowing for the possibility that no short answer exists in the provided paragraph. This makes the problem more realistic, as not all questions have a straightforward answer within the provided text. The SQuAD 2.0 task uses a simple approach to extend the SQuAD 1.1 BERT model for this task, by treating questions that do not have an answer as having an answer span with start and end at the [CLS] token, and comparing the score of the no-answer span to the score of the best non-null span for prediction. The document also mentions that the BERT ensemble, which is a combination of 7 different systems using different pre-training checkpoints and fine-tuning seeds, outperforms all existing systems by a wide margin in SQuAD 2.0, even when excluding entries that use BERT as one of their components.Câu hỏi 3
semantic_rag_chain.invoke("What is the purpose of Ablation Studies?")
################ RESPONSE ###################################
Ablation studies are used to understand the impact of different components or settings of a machine learning model on its performance. In the provided context, ablation studies are used to answer questions about the effect of the number of training steps and masking procedures on the performance of the BERT model. By comparing the performance of the model under different conditions, researchers can gain insights into the importance of these components or settings and how they contribute to the overall performance of the model.Tại RAG Pipeline cho Chunking cơ bản
naive_chunk_vectorstore = Chroma.from_documents(naive_chunks, embedding=embed_model)
naive_chunk_retriever = naive_chunk_vectorstore.as_retriever(search_kwargs={"k" : 5})
naive_rag_chain = (
{"context" : naive_chunk_retriever, "question" : RunnablePassthrough()}
| rag_prompt
| chat_model
| StrOutputParser()
)Trong triển khai này chúng tôi sử dụng k = 5 để so sánh
Câu hỏi 1
naive_rag_chain.invoke("Describe the Feature-based Approach with BERT?")
#############################RESPONSE##########################
The Feature-based Approach with BERT involves extracting fixed features from the pre-trained BERT model, as opposed to the fine-tuning approach where all parameters are jointly fine-tuned on a downstream task. The feature-based approach has certain advantages, such as being applicable to tasks that cannot be easily represented by a Transformer encoder architecture, and providing major computational benefits by pre-computing an expensive representation of the training data once and then running many experiments with cheaper models on top of this representation. In the context provided, the feature-based approach is compared to the fine-tuning approach on the CoNLL-2003 Named Entity Recognition (NER) task, with the feature-based approach using a case-preserving WordPiece model and including the maximal document context provided by the data. The results presented in Table 7 show the performance of both approaches on the NER task.Câu hỏi 2
naive_rag_chain.invoke("What is SQuADv2.0?")
#############################RESPONSE##########################
SQuAD v2.0, or the Stanford Question Answering Dataset version 2.0, is a collection of question/answer pairs that extends the SQuAD v1.1 problem definition by allowing for the possibility that no short answer exists in the provided paragraph. This makes the problem more realistic. The SQuAD v2.0 BERT model is extended from the SQuAD v1.1 model by treating questions that do not have an answer as having an answer span with start and end at the [CLS] token, and extending the probability space for the start and end answer span positions to include the position of the [CLS] token. For prediction, the score of the no-answer span is compared to the score of the best non-null span.Câu hỏi 3
naive_rag_chain.invoke("What is the purpose of Ablation Studies?")
#############################RESPONSE##########################
Ablation studies are used to evaluate the effect of different components or settings in a machine learning model. In the provided context, ablation studies are used to understand the impact of certain aspects of the BERT model, such as the number of training steps and masking procedures, on the model's performance.
For instance, one ablation study investigates the effect of the number of training steps on BERT's performance. The results show that BERT BASE achieves higher fine-tuning accuracy on MNLI when trained for 1M steps compared to 500k steps, indicating that a larger number of training steps contributes to better performance.
Another ablation study focuses on different masking procedures during pre-training. The study compares BERT's masked language model (MLM) with a left-to-right strategy. The results demonstrate that the masking strategies aim to reduce the mismatch between pre-training and fine-tuning, as the [MASK] symbol does not appear during the fine-tuning stage. The study also reports Dev set results for both MNLI and Named Entity Recognition (NER) tasks, considering fine-tuning and feature-based approaches for NER.Đánh giá Ragas cho Sematic chunker
Chặt tài liệu sử dụng RecursiveCharacterTextSplitter
synthetic_data_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
length_function=len,
is_separator_regex=False
)
#
synthetic_data_chunks = synthetic_data_splitter.create_documents([d.page_content for d in documents])
print(len(synthetic_data_chunks))Tạo Dataset
- Câu hỏi – được tạo tổng hợp (grogq-mixtral-8x7b-32768)
- Bối cảnh – được tạo ở trên (Khối dữ liệu tổng hợp)
- Sự thật cơ bản – được tạo tổng hợp (grogq-mixtral-8x7b-32768)
- Câu trả lời – được tạo từ Chuỗi RAG ngữ nghĩa của chúng tôi
questions = []
ground_truths_semantic = []
contexts = []
answers = []
question_prompt = """\
You are a teacher preparing a test. Please create a question that can be answered by referencing the following context.
Context:
{context}
"""
question_prompt = ChatPromptTemplate.from_template(question_prompt)
ground_truth_prompt = """\
Use the following context and question to answer this question using *only* the provided context.
Question:
{question}
Context:
{context}
"""
ground_truth_prompt = ChatPromptTemplate.from_template(ground_truth_prompt)
question_chain = question_prompt | chat_model | StrOutputParser()
ground_truth_chain = ground_truth_prompt | chat_model | StrOutputParser()
for chunk in synthetic_data_chunks[10:20]:
questions.append(question_chain.invoke({"context" : chunk.page_content}))
contexts.append([chunk.page_content])
ground_truths_semantic.append(ground_truth_chain.invoke({"question" : questions[-1], "context" : contexts[-1]}))
answers.append(semantic_rag_chain.invoke(questions[-1]))Lưu ý: vì mục đích thử nghiệm chúng tôi chỉ xem xét 10 mẫu
Định dạng nội dung được tạo thành Định dạng tập dữ liệu HuggingFace
from datasets import load_dataset, Dataset
qagc_list = []
for question, answer, context, ground_truth in zip(questions, answers, contexts, ground_truths_semantic):
qagc_list.append({
"question" : question,
"answer" : answer,
"contexts" : context,
"ground_truth" : ground_truth
})
eval_dataset = Dataset.from_list(qagc_list)
eval_dataset
###########################RESPONSE###########################
Dataset({
features: ['question', 'answer', 'contexts', 'ground_truth'],
num_rows: 10
})Chấm điểm Ragas
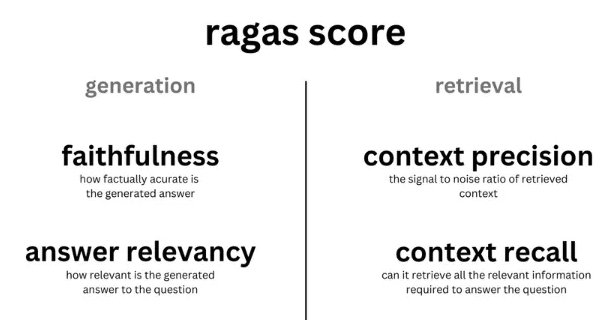
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
#
from ragas import evaluate
result = evaluate(
eval_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
llm=chat_model,
embeddings=embed_model,
raise_exceptions=False
)Chúng tôi tiến hành sử dụng OpenAI sử dụng bởi RAGAS
import os
from google.colab import userdata
import openai
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
openai.api_key = os.environ['OPENAI_API_KEY']from ragas import evaluate
result = evaluate(
eval_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
result
#########################RESPONSE##########################
{'context_precision': 1.0000, 'faithfulness': 0.8857, 'answer_relevancy': 0.9172, 'context_recall': 1.0000}#Extract the details into a dataframe
results_df = result.to_pandas()
results_df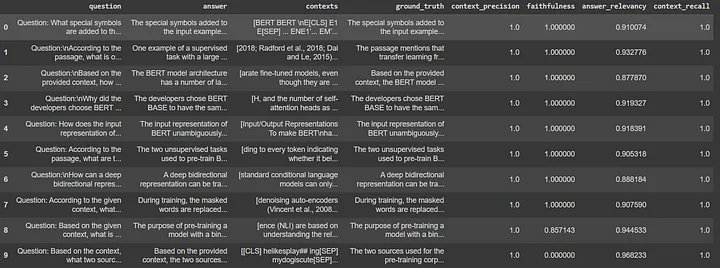
Đánh giá Ragas cho native chunk
import tqdm
questions = []
ground_truths_semantic = []
contexts = []
answers = []
for chunk in tqdm.tqdm(synthetic_data_chunks[10:20]):
questions.append(question_chain.invoke({"context" : chunk.page_content}))
contexts.append([chunk.page_content])
ground_truths_semantic.append(ground_truth_chain.invoke({"question" : questions[-1], "context" : contexts[-1]}))
answers.append(naive_rag_chain.invoke(questions[-1]))xây dựng dữ liệu đánh giá
qagc_list = []
for question, answer, context, ground_truth in zip(questions, answers, contexts, ground_truths_semantic):
qagc_list.append({
"question" : question,
"answer" : answer,
"contexts" : context,
"ground_truth" : ground_truth
})
naive_eval_dataset = Dataset.from_list(qagc_list)
naive_eval_dataset
############################RESPONSE########################
Dataset({
features: ['question', 'answer', 'contexts', 'ground_truth'],
num_rows: 10
})Chạy đánh giá Ragas
naive_result = evaluate(
naive_eval_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
#
naive_result
############################RESPONSE#######################
{'context_precision': 1.0000, 'faithfulness': 0.9500, 'answer_relevancy': 0.9182, 'context_recall': 1.0000}naive_results_df = naive_result.to_pandas()
naive_results_df
###############################RESPONSE #######################
{'context_precision': 1.0000, 'faithfulness': 0.9500, 'answer_relevancy': 0.9182, 'context_recall': 1.0000}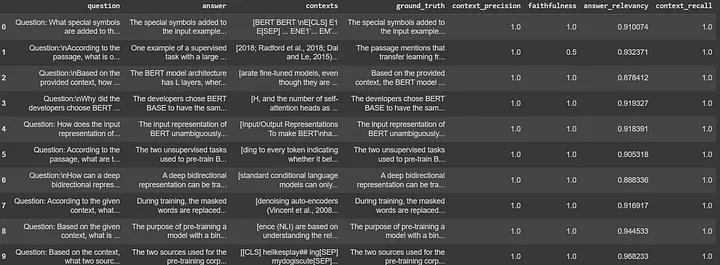
Kết quả thử nghiệm
Ở đây chúng ta có thể thấy rằng kết quả của cả Semantic Chunking và Native Chunking gần như giống nhau ngoại trừ Native Chunker có cách trình bày câu trả lời thực tế tốt hơn với số điểm 0,95 khi so sánh với điểm 0,88 của Semantic Chunker.
Tóm lại, phân đoạn ngữ nghĩa cho phép nhóm các thông tin tương tự về ngữ cảnh, cho phép tạo ra các phân đoạn độc lập và có ý nghĩa. Cách tiếp cận này nâng cao hiệu suất và hiệu quả của các mô hình ngôn ngữ lớn bằng cách cung cấp cho chúng các đầu vào tập trung, cuối cùng là cải thiện khả năng hiểu và xử lý dữ liệu ngôn ngữ tự nhiên của chúng.
Ở MyGPT chúng tôi sử dụng chiến lược chunking nào?
Như các bạn thấy hai thử nghiệm trên là thực hiện đơn lẻ về 2 phương pháp giả định trên một tập dữ liệu nào đó bằng phương pháp chặt dữ liệu tự động. Cách thức này phù hợp với việc chúng ta đưa 1 file tài liệu vào để máy xử lý nhưng kết quả đầu ra thường có mức độ dưới 0,95 và 0.05 còn lại thì chúng ta sẽ không biết lúc nào nó xẩy ra và tối ưu thế nào để có thể loại bỏ hoàn toàn con số đáng ghét này.
Ở MyGPT chúng tôi thực hiện việc chunking bằng tay, có nghĩa là sẽ kiểm soát chính xác 100% nội dung cũng như ý nghĩa của từng chunk một để đảm bảo chúng fit 100% với mô hình về kích thức, ngữ nghĩa, độ tương đồng với mô hình ngôn ngữ, chúng tôi gọi đây là Manual Chunking.
Dĩ nhiên với phương pháp chunking mà MyGPT triển khai, thời gian sẽ lâu hơn rất nhiều so với các phương pháp chunk tự động tuy nhiên chúng tôi cần đảm bảo rằng độ chính xác đạt được ở mức 1.00 chứ không được phép có bất cứ suy diễn nào bên ngoài vùng dữ liệu. Chúng tôi hiểu rằng đây là ngưỡng để các tổ chức chấp nhận đưa hệ thống ra thay mặt mình để hoạt động công khai chứ không phải ở mức tư vấn hay trợ lý cho một nhóm cá nhân nhỏ nào.
Dĩ nhiên với Manual chunking thì việc thực hiện xử lý sẽ phụ thuộc rất nhiều vào dữ liệu raw mà tổ chức hiện có cũng như cần phải xử lý ở các công đoạn Rettrival hay Augument cho từng tổ chức khác nhau sẽ khác nhau hoàn toàn. Có nghĩa rằng mỗi một Chatbot GenAI mà chúng tôi triển khai sẽ chỉ chạy tốt với dữ liệu của tổ chức đó mà không phải tổ chức khác nhằm đảm bảo mục tiêu của độ chính xác 100%.
Hãy liên hệ với MyGPT để được tư vấn cụ thể các bạn nhé!