1. Tổng quan về mô hình ngôn ngữ lớn
1.1 Mô hình ngôn ngữ lớn là gì?
Mô hình ngôn ngữ lớn (Large Language Model) là một dạng của trí tuệ nhân tạo dựa trên học sâu và mạng nơ-ron hồi quy. Mục tiêu chính của mô hình này là xử lý và hiểu ngôn ngữ tự nhiên, cho phép nó tạo ra văn bản mới dựa trên các đầu vào đã được cung cấp. Trong những năm gần đây, các mô hình ngôn ngữ lớn đã tiến bộ mạnh mẽ nhờ vào sự phát triển của kiến thức học sâu, kỹ thuật xử lý ngôn ngữ tự nhiên và khả năng tính toán mạnh mẽ từ việc sử dụng phần cứng đám mây.
Các mô hình ngôn ngữ lớn như GPT (Generative Pre-trained Transformer) đã đạt được những thành tựu đáng kể trong việc xử lý ngôn ngữ tự nhiên, dịch máy, tóm tắt văn bản và tạo câu chuyện. Đặc điểm chung của các mô hình này là khả năng học thông qua việc tiền huấn luyện trên một lượng lớn dữ liệu văn bản, sau đó được huấn luyện chuyên sâu (fine-tuning) trên tác vụ cụ thể.
Mô hình ngôn ngữ lớn đã có nhiều ứng dụng quan trọng và đa dạng trong lĩnh vực trí tuệ nhân tạo và cả các lĩnh vực khác. Dưới đây là một số ứng dụng tiêu biểu của mô hình ngôn ngữ lớn:
- Tạo ra văn bản tự nhiên: Mô hình ngôn ngữ lớn có khả năng tạo ra văn bản tự nhiên, điều này đã được sử dụng để viết tin tức, bài blog, câu chuyện và thậm chí sách.
- Hỗ trợ viết và chỉnh sửa văn bản: Mô hình ngôn ngữ lớn có thể giúp người dùng viết và chỉnh sửa văn bản bằng cách đề xuất từ khóa, cung cấp phương án gợi ý hoặc kiểm tra cú pháp và ngữ pháp.
- Dịch thuật tự động: Mô hình ngôn ngữ lớn có thể được sử dụng để xây dựng hệ thống dịch máy mạnh mẽ, từ việc dịch ngôn ngữ thông qua văn bản hay thậm chí qua một cuộc trò chuyện.
- Trả lời câu hỏi và hỗ trợ khách hàng: Mô hình ngôn ngữ lớn có thể đảm nhận vai trò trong việc trả lời câu hỏi từ người dùng hoặc hỗ trợ khách hàng, cung cấp thông tin một cách nhanh chóng và chính xác.
- Phân tích và tổng hợp văn bản: Mô hình ngôn ngữ lớn có thể được sử dụng để phân tích ý kiến, phát hiện thông tin quan trọng từ văn bản và tóm tắt nội dung một cách tự động.
- Hỗ trợ giáo dục và nghiên cứu: Mô hình ngôn ngữ lớn có thể cung cấp thông tin và gợi ý cho giảng dạy, nghiên cứu và học tập, từ việc tìm kiếm thông tin đến việc phân loại và phân tích dữ liệu.
- Tương tác người-máy: Mô hình ngôn ngữ lớn có thể hỗ trợ tương tác người-máy thông qua các ứng dụng như chatbot, trợ lý ảo và giao diện người dùng thông qua giọng nói.
Mặc dù mô hình ngôn ngữ lớn mang lại nhiều tiềm năng và cải tiến đáng kể, nhưng cũng cần chú ý đến các vấn đề liên quan đến độ tin cậy và đạo đức. Một số vấn đề như việc mô hình có thể tạo ra thông tin giả, không đáng tin cậy hoặc vi phạm quyền riêng tư đã được xác định và đang được nghiên cứu để giải quyết. Dù vẫn còn nhiều thách thức phải đối mặt, mô hình ngôn ngữ lớn đóng vai trò quan trọng trong việc nâng cao khả năng xử lý ngôn ngữ tự nhiên của máy tính và đưa chúng gần hơn với khả năng hiểu và tương tác như con người.
1.2 Một số khái niệm cơ bản
– Mạng nơ-ron hồi quy là một loại mạng nơ-ron nhân tạo có khả năng xử lý các dữ liệu dạng chuỗi như văn bản, âm thanh, video hay dữ liệu thời gian. Mạng nơ-ron hồi quy có thể nhớ được các thông tin trước đó và sử dụng chúng để ảnh hưởng đến các thông tin sau này. Một mạng nơ-ron hồi quy gồm có các tế bào (cell) được kết nối với nhau theo một trình tự thời gian. Mỗi tế bào có thể nhận đầu vào là một phần của chuỗi dữ liệu và đầu ra là một phần của chuỗi kết quả. Mỗi tế bào cũng có một trạng thái ẩn (hidden state) là một vector lưu trữ các thông tin quan trọng từ các bước thời gian trước đó. Trạng thái ẩn có thể được cập nhật theo các quy tắc khác nhau tùy thuộc vào kiểu của tế bào. Có nhiều kiểu tế bào khác nhau trong mạng nơ-ron hồi quy, như tế bào RNN đơn giản, tế bào LSTM (Long Short-Term Memory), tế bào GRU (Gated Recurrent Unit) và tế bào Transformer.
– Transformer là một kiến trúc mạng nơ-ron biến đổi được giới thiệu bởi Vaswani et al. vào năm 2017. Kiến trúc này sử dụng cơ chế Attention để tập trung vào các phần quan trọng trong dữ liệu đầu vào. Transformer đã trở thành công cụ quan trọng trong việc xây dựng các mô hình ngôn ngữ lớn, giúp cải thiện hiệu suất và khả năng mở rộng của chúng.
– Tiền huấn luyện (Pre-training) là giai đoạn đào tạo ban đầu của mô hình ngôn ngữ lớn, trong đó mô hình được tiền huấn luyện trên một lượng lớn dữ liệu không có nhãn. Trong quá trình này, mô hình cố gắng dự đoán các từ tiếp theo dựa trên ngữ cảnh trước đó trong câu. Quá trình tiền huấn luyện giúp mô hình hiểu được cấu trúc và khía cạnh ngôn ngữ rộng hơn.
– Huấn luyện chuyên sâu (Fine-tuning) là giai đoạn tinh chỉnh sau khi tiền huấn luyện. Mô hình được huấn luyện lại trên dữ liệu có nhãn liên quan đến tác vụ cụ thể mà nó sẽ được sử dụng. Quá trình huấn luyện chuyên sâu giúp mô hình tùy chỉnh cho một tác vụ cụ thể và nâng cao khả năng xử lý của nó.
– Kích thước mô hình ngôn ngữ lớn được đo bằng số lượng tham số được dùng để cấu thành lên các tế bào của mạng nơ-ron. Ví dụ, ChatGPT có nhiều phiên bản với các kích thước khác nhau, từ GPT-1 (có khoảng 117 triệu tham số) đến GPT-3 (khoảng 175 tỷ tham số). Việc tăng kích thước mô hình thông qua số lượng tham số giúp cải thiện hiệu suất và khả năng biểu diễn của mô hình. Kích thước lớn hơn cho phép GPT học được một phạm vi ngữ nghĩa rộng hơn và tạo ra kết quả đáng tin cậy hơn trong việc xử lý và tạo ra văn bản. Tuy nhiên, cần lưu ý rằng kích thước lớn cũng đồng nghĩa với yêu cầu tính toán và bộ nhớ cao hơn, và có thể gặp khó khăn trong việc huấn luyện và triển khai trên các thiết bị có tài nguyên hạn chế. Do đó, việc lựa chọn kích thước phù hợp của mô hình phụ thuộc vào yêu cầu cụ thể của ứng dụng và tài nguyên sẵn có.
* Để hiểu rõ hơn về nguyên lý hoạt động của mô hình ngôn ngữ lớn, các bạn có thể đọc nhanh bài viết của tác giả Lê Văn Lợi với tiêu đề “Nhàn đàm ICT: Large Language Model (LLM)” trên ICTVN group – https://groups.google.com/g/ict_vn/c/i9P2JNviEb8/m/tAAxXZJUBAAJ?pli=1
2. Nghiên cứu và ứng dụng mô hình ngôn ngữ lớn
2.1 Một số kết quả nổi bật trên thế giới
Có rất nhiều hãng công nghệ lớn trên thế giới đang quan tâm đến nghiên cứu và phát triển các mô hình ngôn ngữ lớn. Các sản phẩm mới nhất là các mô hình có quy mô, chất lượng và tốc độ cao hơn so với các mô hình trước đây. Các mô hình này có thể thực hiện nhiều tác vụ liên quan đến ngôn ngữ tự nhiên, như sinh văn bản, trả lời câu hỏi, phân tích cảm xúc, phát hiện sai sót chính tả, biên tập văn bản và nhiều hơn nữa. Các mô hình này cũng có thể được tinh chỉnh cho các ứng dụng cụ thể như hội thoại, tìm kiếm hay dịch thuật. Dưới đây là một số kết quả sản phẩm nổi bật đã được công bố.
– GPT-4 của OpenAI
OpenAI, một tổ chức nghiên cứu trí tuệ nhân tạo đã có nhiều đóng góp cho sự phát triển lớn mạnh của việc ứng dụng mô hình ngôn ngữ lớn. GPT-1 là mô hình ngôn ngữ lớn đầu tiên được phát triển bởi OpenAI vào năm 2018. Vào tháng 6 năm 2020, OpenAI giới thiệu GPT-3, mô hình ngôn ngữ lớn có quy mô lớn nhất đến thời điểm đó. GPT-3 có khoảng 175 tỷ tham số, có khả năng thực hiện nhiều loại công việc như tạo ra văn bản, dịch thuật, trả lời câu hỏi, giải toán, và thậm chí chơi game. Kể từ GPT-3, OpenAI đã tiếp tục phát triển và cải tiến mô hình ngôn ngữ lớn với phiên bản mới nhất hiện nay là GPT-4. Các kết quả nghiên cứu của OpenAI, được Microsoft hỗ trợ và tích hợp vào các sản phẩm, dịch vụ của hãng như Bing Chat, Microsoft 365 Copilot.
– PaLM 2 của Google
Google đã công bố ra mắt PaLM 2, một mô hình ngôn ngữ lớn thế hệ mới vào ngày 11/5/2023. PaLM 2 có 540 tỷ tham số và được đào tạo trên một kho ngữ liệu có hơn 100 ngôn ngữ. Nó sẽ cung cấp dịch vụ cho công cụ trò chuyện Bard của Google, được xem là đối thủ cạnh tranh với ChatGPT. PaLM 2 tạo thành nền tảng của Codey, mô hình chuyên dụng của Google để viết mã và gỡ lỗi. Ngoài ra, Google cũng có Med-PaLM 2, một mô hình của hãng tập trung vào kiến thức y tế.
– LLaMa 2 của Meta
Llama 2 là một mô hình ngôn ngữ lớn, được Meta ra mắt vào quý đầu tiên năm 2023. Llama 2 có nhiều cải tiến về quy mô, chất lượng và tốc độ so với Llama 1. Llama 2 có hai điểm đặc biệt so với các mô hình ngôn ngữ lớn khác. Thứ nhất, Llama 2 là một dự án mã nguồn mở. Điều này có nghĩa là Meta đang xuất bản toàn bộ mô hình để bất kỳ ai cũng có thể sử dụng để xây dựng các mô hình hoặc ứng dụng mới. Llama 2 cũng có một giấy phép cộng đồng rất linh hoạt, cho phép sử dụng thương mại. Thứ hai, Llama 2 sử dụng một kỹ thuật mới gọi là “grouped-query attention”, giúp giảm thiểu chi phí tính toán và tăng hiệu suất của mô hình. Nhờ vậy, Llama 2 có thể xử lý được các đoạn văn bản dài hơn và nhanh hơn so với các mô hình truyền thống.
– Gopher của Deepmind
Gopher là một mô hình ngôn ngữ lớn có thể dùng để tạo ra các bài báo khoa học chất lượng cao từ các đầu vào đơn giản như tiêu đề hoặc tóm tắt. Gopher cũng có thể tự động tạo ra các biểu đồ, bảng biểu và công thức toán học để minh hoạ cho các ý tưởng trong bài báo. Gopher được huấn luyện trên kho dữ liệu ArXiv, chứa hàng triệu bài báo khoa học trong các lĩnh vực như toán học, vật lý và máy tính. Gopher đã sử dụng kỹ thuật gọi là học tăng cường (reinforcement learning) để cải thiện chất lượng của các bài báo được tạo ra, bằng cách đánh giá chúng theo các tiêu chí như tính đúng đắn, tính mới mẻ và tính hấp dẫn.
2.2 Nghiên cứu phát triển mô hình ngôn ngữ lớn tiếng Việt
Nhận thức rõ tầm quan trọng của mô hình ngôn ngữ lớn, Bộ TT&TT mới đây đã ban hành kế hoạch thúc đẩy, với mục tiêu đặt ra là đến năm 2025, Việt Nam có ít nhất một nền tảng công nghệ mô hình ngôn ngữ lớn tiếng Việt, có khả năng cung cấp dịch vụ cho các nền tảng ứng dụng trí tuệ nhân tạo khác. Mô hình ngôn ngữ lớn tiếng Việt sử dụng tri thức, dữ liệu huấn luyện đã được sàng lọc của Việt Nam, với chi phí thấp cho người dân, doanh nghiệp, tổ chức tại Việt Nam sử dụng để phát triển các ứng dụng mới. Để cụ thể hóa kế hoạch, Bộ TT&TT đã phê duyệt việc lựa chọn tập đoàn Viettel là đơn vị nghiên cứu, thử nghiệm phát triển mô hình ngôn ngữ lớn tiếng Việt và trợ lý ảo cho cán bộ, công chức tại Bộ TT&TT.
Mô hình ngôn ngữ lớn tiếng Việt cũng nhận được nhiều sự quan tâm của các nhóm nghiên cứu thuộc các tổ chức giáo dục và doanh nghiệp công nghệ lớn tại Việt Nam như Đại học Bách Khoa Hà Nội (BKAI), Trường Đại học Công nghệ-ĐHQGHN (UET-IAI), Tập đoàn Vingroup (VinAI Research), Tập đoàn FPT (FPT AI), Tập đoàn Viettel (Viettel AI),… Dưới đây là một số kết quả ban đầu về nghiên cứu và phát triển mô hình ngôn ngữ lớn tiếng Việt.
PhoBERT là một mô hình ngôn ngữ lớn đầu tiên được xây dựng chỉ dùng cho tiếng Việt. Nó được thiết kế dựa trên kiến trúc BERT của Google. PhoBERT được huấn luyện trên kho dữ liệu tiếng Việt lớn gồm 20GB văn bản thuộc nhiều thể loại khác nhau. PhoBERT có thể đạt kết quả tốt hơn các mô hình ngôn ngữ khác trong các tác vụ xử lý ngôn ngữ tiếng Việt như phân tích cảm xúc, phân loại văn bản và nhận dạng thực thể có tên.
Mới đây ngày 21/08/2023, VinBigdata của tập đoàn Vingroup đã công bố xây dựng thành công mô hình ngôn ngữ lớn tiếng Việt, đặt nền móng cho việc xây dựng các giải pháp tích hợp AI tạo sinh tại Việt Nam. Dự kiến cuối tháng 12/2023, VinBigdata sẽ chính thức ra mắt cộng đồng hai dòng sản phẩm chính. Đó là Nền tảng AI tạo sinh đa nhận thức VinBase 2.0 với các giải pháp phục vụ doanh nghiệp, cơ quan chính phủ và ứng dụng ViGPT – “ChatGPT phiên bản Việt” sẽ được mở cho cộng đồng truy cập và thử nghiệm. Với ViGPT, người dùng có thể hỏi đáp các thông tin đặc thù của Việt Nam (quy định, văn bản pháp luật), hoặc các thông tin mang tính bản địa (lịch sử, văn học, danh lam thắng cảnh, đặc sản địa phương…).
3. Phát triển ứng dụng mô hình ngôn ngữ lớn
3.1 Khám phá Hugging Face
Hugging Face là một nền tảng mã nguồn mở cho trí tuệ nhân tạo, chuyên về xử lý ngôn ngữ tự nhiên (NLP). Hugging Face cung cấp các công cụ và thư viện để huấn luyện, sử dụng và chia sẻ các mô hình ngôn ngữ lớn như BERT, RoBERTa, GPT-2, GPT-3, T5, Llama 2,…. Hugging Face cũng có một cộng đồng lớn và năng động, gồm các nhà nghiên cứu, các nhà phát triển và các người dùng của AI. Dưới đây là một số tính năng nổi bật được cung cấp qua nền tảng của Hugging Face.
- Hugging Face Hub là nơi mà các nhà phát triển, nghiên cứu và ứng dụng có thể chia sẻ và khám phá các mô hình học máy và tài liệu liên quan đến xử lý ngôn ngữ tự nhiên.
- Transformers là một thư viện mã nguồn mở cung cấp các mô hình học máy sẵn có cho nhiều tác vụ khác nhau để giải quyết các bài toán ứng dụng mô hình ngôn ngữ lớn.
- Tokenizers là một thư viện mã nguồn mở cung cấp các công cụ cho việc mã hóa và giải mã các câu văn bản trong xử lý ngôn ngữ tự nhiên.
- Datasets là một bộ sưu tập các tập dữ liệu mở được sử dụng để huấn luyện các mô hình học máy.
- Pipeline là một công cụ giúp các nhà phát triển và người dùng không cần có kiến thức chuyên sâu về xử lý ngôn ngữ tự nhiên và học máy để sử dụng các mô hình được chia sẻ trên Hugging Face. Pipeline cung cấp một giao diện đơn giản và dễ sử dụng để thực hiện các tác vụ như phân loại văn bản, trích xuất thông tin và chuyển đổi ngôn ngữ.
3.2 Ngôn ngữ, thư viện lập trình mở
Python là ngôn ngữ lập trình ưa thích được cộng đồng các nhà nghiên cứu, lập trình viên lựa chọn để phát triển các ứng dụng về khoa học dữ liệu và trí tuệ nhân tạo. Nó được sử dụng bởi khả năng linh hoạt và có sẵn nhiều thư viện có thể hỗ trợ giải quyết đa dạng các bài toán ứng dụng trong thực tế. Các thư viện này cung cấp các chức năng như huấn luyện, sử dụng và đánh giá các mô hình AI và NLP, xử lý và phân tích các dữ liệu văn bản, âm thanh, video và hình ảnh, trực quan hóa và minh họa các kết quả và nhiều hơn nữa. Dưới đây là một số các ví dụ thư viện nổi bật.
- Pandas là một thư viện thường dùng cho phân tích và xử lý dữ liệu. Pandas cung cấp các cấu trúc dữ liệu và các chức năng để tải, lưu trữ, thao tác, lọc, nhóm, tổng hợp, trực quan hóa và phân tích các dữ liệu dạng bảng hoặc chuỗi thời gian. Pandas có thể được sử dụng cho nhiều mục đích, như khám phá dữ liệu, làm sạch dữ liệu, xây dựng mô hình học máy, tạo báo cáo và nhiều hơn nữa.
- PyTorch là một thư viện cho học sâu (deep learning), một lĩnh vực của AI. PyTorch cho phép bạn xây dựng, huấn luyện và sử dụng các mạng nơ-ron nhân tạo (artificial neural network), một loại mô hình AI có khả năng xử lý và tạo ra các dữ liệu phức tạp. PyTorch cũng có nhiều công cụ và thư viện hỗ trợ cho NLP, như Transformers, TorchText và SpeechBrain.
- NLTK là một thư viện cho NLP. NLTK cung cấp các chức năng để xử lý, phân tích và thao tác với các dữ liệu văn bản ngôn ngữ tự nhiên. NLTK có thể được sử dụng để giải quyết các bài toán như tách từ, gán nhãn từ loại, phân tích cú pháp, trích xuất thông tin và nhiều hơn nữa.
- LangChain là một framework cho phép lập trình viên phát triển ứng dụng dựa trên mô hình ngôn ngữ lớn. Những ứng dụng phổ biến của nó là chatbot, tóm tắt văn bản, trả lời câu hỏi,… LangChain không chỉ giúp tương tác với các mô hình ngôn ngữ lớn mà còn cho phép ứng dụng tận dụng thêm các thông tin từ nhiều nguồn dữ liệu khác của bên thứ 3 như Google, Notion, Facebook… Nó cũng cung cấp các component cho phép sử dụng các mô hình ngôn ngữ trong nhiều tình huống ứng dụng khác nhau trên thực tế.
- Ngoài ra còn có rất nhiều thư viện lập trình nguồn mở khác có thể hỗ trợ xây dựng các ứng dụng mô hình ngôn ngữ lớn, có thể kể ra như Awesome-LLM, Lamini, LlamaIndex, CodiumAI, Auto-GPT,…
3.3 Môi trường thực hành Google Colab
Google Colab là một dịch vụ web cho việc tạo và chạy các Jupyter Notebook trên đám mây. Google Colab cho phép bạn sử dụng miễn phí các máy tính có GPU hoặc TPU để huấn luyện và sử dụng các mô hình trí tuệ nhân tạo. Google Colab cũng cho phép bạn kết nối với Google Drive hoặc GitHub để lưu trữ và chia sẻ các tài liệu. Google Colab có nhiều ưu điểm, như:
- Dễ sử dụng: Google Colab có giao diện thân thiện và dễ sử dụng, giống như Jupyter Notebook. Bạn có thể viết và chạy các đoạn mã Python, thêm các chú thích, trực quan hóa và minh họa các kết quả, và tương tác với các widget và biểu mẫu.
- Miễn phí: Google Colab không yêu cầu bạn thanh toán bất kỳ chi phí nào để sử dụng các máy tính có GPU hoặc TPU. Bạn chỉ cần có một tài khoản Google để đăng nhập và sử dụng Google Colab. Tuy nhiên, bạn cần lưu ý rằng Google Colab có một số giới hạn về thời gian, dung lượng và tài nguyên của các phiên làm việc.
- Mạnh mẽ: Google Colab cho phép bạn sử dụng các máy tính có GPU hoặc TPU để huấn luyện và sử dụng các mô hình trí tuệ nhân tạo một cách hiệu quả và nhanh chóng. Bạn cũng có thể sử dụng các thư viện và công cụ hỗ trợ trí tuệ nhân tạo, như TensorFlow, PyTorch, Keras và Hugging Face.
Việc học và làm quen với môi trường thực hành Google Colab sẽ giúp ích rất nhiều cho các kĩ sư trong việc chia sẻ kiến thức về các đoạn mã nguồn trong lĩnh vực trí tuệ nhân tạo hiện nay. Một ví dụ cụ thể, tất cả các bài giảng và chương trình mẫu được cung cấp thông qua nền tảng Hugging Face chủ yếu được viết dưới dạng notebook để có thể chạy thực hành trực tuyến trên Google Colab.
* Các bạn mới làm quen với LLM có thể bắt đầu với bài giảng về NLP được cung cấp trên Hugging Face tại địa chỉ https://huggingface.co/learn/nlp-course/
4. Chuẩn bị cho cuộc thi PMNM – OLP 2023
Cuộc thi phần mềm nguồn mở do Hội Tin học Việt Nam tổ chức hàng năm cho sinh viên của các trường đại học, cao đẳng trên cả nước tham gia. Thể lệ của cuộc thi năm 2023 đã được công bố trên trang thông tin của Ban tổ chức. Hình thức của cuộc thi là các đội tuyển tham gia làm một dự án phát triển phần mềm nguồn mở theo yêu cầu của đề thi do BTC công bố. Chủ đề của cuộc thi năm 2023 là “Ứng dụng các mô hình ngôn ngữ lớn”. Do vậy các trường tham gia cuộc thi phải thực hiện lựa chọn và huấn luyện đội tuyển để có các kĩ năng, kiến thức cần thiết sau đây:
- Hiểu biết về dự án PMNM: Nắm vững và có kĩ năng sử dụng các công cụ hỗ trợ trong xây dựng một dự án PMNM đáp ứng được các tiêu chí cần thiết theo đúng thông lệ quốc tế.
- Làm chủ ngôn ngữ, thư viện lập trình phù hợp: Đề thi sẽ yêu cầu lập trình tạo ra một ứng dụng theo chủ đề của năm. Các ngôn ngữ lập trình, thư viện mở thích hợp với chủ đề của năm 2023 đã được giới thiệu ở trên. Các đội tuyển cần luyện tập, làm chủ ngôn ngữ và các thư viện sẵn có để có khả năng sử dụng khai thác trong cuộc thi.
- Hiểu biết cách triển khai một mô hình LLM: Làm quen với với việc triển khai các mô hình LLM tiền huấn luyện được cung cấp sẵn bằng một thư viện mở (vd., Hugging Face) hoặc thông qua API (vd., ChatGPT). Nắm vững khả năng ứng dụng của từng mô hình và cách thức triển khai xây dựng ứng dụng với nó.
- Tìm hiểu các cách tiếp cận xây dựng ứng dụng LLM: Sưu tập và làm quen với một số giải pháp xây dựng ứng dụng khác nhau dựa trên mô hình ngôn ngữ lớn. Phân loại ứng dụng theo một số lớp bài toán và tìm các cách tiếp cận phù hợp tương ứng để giải quyết bài toán đó. Ví dụ một số lớp các bài toán thường găp như: tìm kiếm trả lời câu hỏi dựa trên một kho tri thức của tổ chức (dạng văn bản); tra cứu thông tin, dịch vụ được cung cấp từ CSDL bằng ngôn ngữ tự nhiên;…
5. Thông tin từ Ban tổ chức
30/08/2023 – Chủ đề và Thể lệ tham dự OLP – nội dung Phần mền nguồn mở năm 2023:
“Ứng dụng các mô hình ngôn ngữ lớn (LLMs)”
Thể lệ OLP Phần mềm nguồn mở năm 2023
- Cơ quan tổ chức: Hội Tin học Việt nam
- Đơn vị thường trực: Câu lạc bộ VFOSSA
Căn cứ theo Quy chế Olympic Tin học Sinh viên Việt Nam
Đối tượng tham dự:
- Sinh viên chuyên hoặc không chuyên về CNTT của các trường đại học, cao đẳng trên toàn quốc.
Hình thức cuộc thi:
- Thi hình thức Hackathon theo đội tuyển trong từ 5 đến 8 tiếng theo đề bài do Hội đồng giám khảo đưa ra.
Yêu cầu tham gia:
- Các trường đăng kí các đội tuyển tham gia nội dung PMNM.
- Mỗi đội thi phải bao gồm không quá 3 thí sinh và được dẫn dắt bởi một giảng viên của trường tham dự.
- Mỗi trường chỉ được đăng kí tối đa 2 đội tuyển tham gia nội dung PMNM.
Giải thưởng:
- Gồm các giải nhất, nhì, ba và khuyến khích theo quy chế OLP 2023.
- Quà tặng, giải thưởng của nhà tài trợ cho các đội đạt giải chuyên môn do các chuyên gia của VFOSSA bình chọn.
Phương thức ra đề và làm bài thi:
- Các đề thi lập trình do các chuyên gia của VFOSSA xây dựng dựa trên việc thu thập bài toán yêu cầu cần giải quyết từ các cá nhân, tổ chức trong thực tế. Các bài toán yêu cầu được đặt ra phải theo cùng một chủ đề chung do HĐGK đưa ra.
- Đề thi được giữ kín và sẽ được công bố trước 2 tuần của ngày chấm thi chung kết.
- Sau khi đề thi được công bố, các đội lựa chọn 1 đề bài trong số các đề đưa ra để lập trình. Toàn bộ kết quả sản phẩm của các đội thi phải được công bố trên một kho nguồn mở.
- Các đội thi chuẩn bị bài trình bày và nội dung trình diễn sản phẩm kết quả tại buổi chấm thi Chung kết của HĐGK PMNM trong thời gian tổ chức Oympic.
- HĐGK chấm điểm bài thi và sắp xếp phân hạng dựa trên sản phẩm công bố trên kho nguồn mở và kết quả trình diễn tại buổi chung kết.
Chủ đề cuộc thi năm 2023: “Ứng dụng các mô hình ngôn ngữ lớn (LLMs)”
Lịch trình tổ chức
- Tháng 9/2023: Công bố chủ đề và phát động cuộc thi PMNM – OLP 2023
- Tháng 9-10/2023: Thu thập ý tưởng, bài toán yêu cầu thực tiễn theo chủ đề cuộc thi
- Tháng 11/2023: BTC ra đề và tiếp nhận thông tin danh sách đăng kí thi
- Ngày 20/11-3/12/2023: Công bố đề thi và các đội tham gia lập trình hackathon
- Ngày 4-6/12/2023: Chấm thi kho mã nguồn của sản phẩm dự thi
- Ngày 7/12/2023: Trình diễn sản phẩm và chấm thi chung kết
- Ngày 8/12/2023: Công bố trao giải
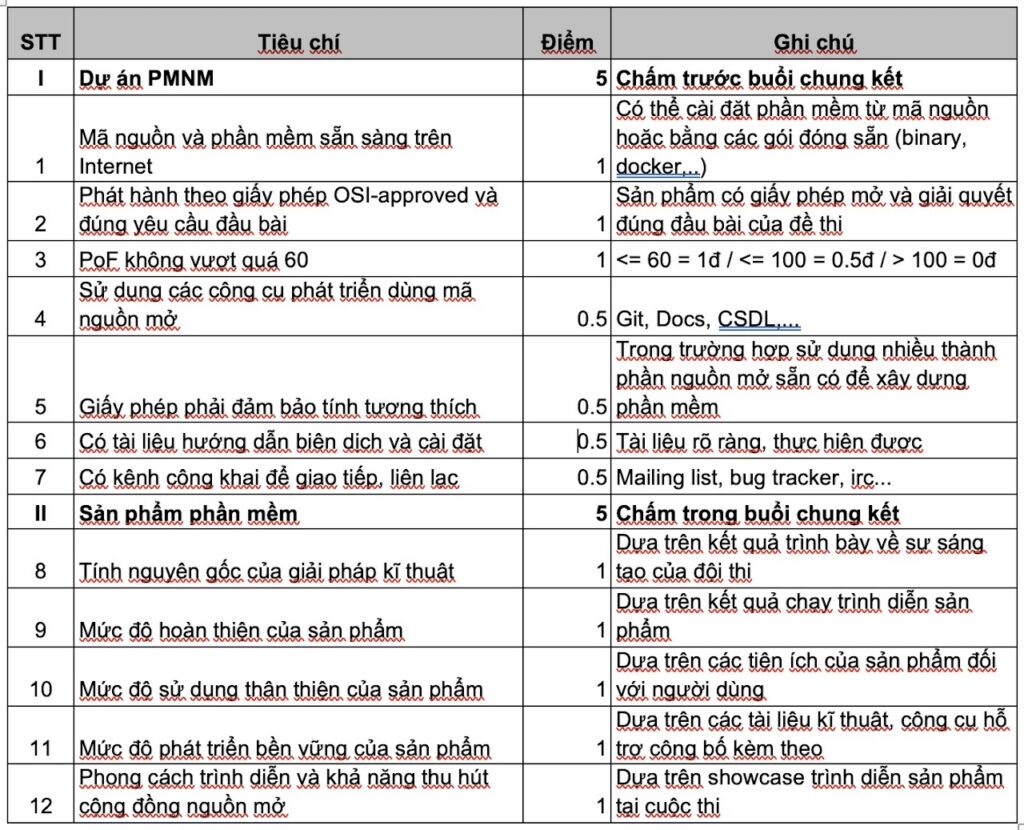
Các tiêu chí chấm điểm