


Bài viết tập trung vào đo lường mức độ hiểu biết ngôn ngữ tiếng Anh của mô hình hàng đầu mới được giới thiệu của OpenAI GPT-4o
Việc OpenAI ra mắt GPT-4o gần đây đã tạo tiền đề cho một kỷ nguyên mới trong các mô hình ngôn ngữ AI và cách chúng ta tương tác với chúng.
Phần ấn tượng nhất là hỗ trợ tương tác trực tiếp với ChatGPT mà không bị gián đoạn cuộc trò chuyện.
Mặc dù có một số trục trặc trong quá trình demo trực tiếp, tôi không thể không cảm thấy ngạc nhiên trước những gì nhóm đã đạt được.
Điều tuyệt vời nhất là ngay sau bản demo, OpenAI đã cho phép truy cập vào API GPT-4o.
Trong bài viết này, tôi sẽ trình bày phân tích độc lập của mình để đo lường khả năng phân loại của GPT-4o so với GPT 4 so với các mô hình Gemini và Unicorn của Google bằng cách sử dụng tập dữ liệu tiếng Anh mà tôi đã tạo.
Mô hình nào trong số này có khả năng hiểu tiếng Anh tốt nhất?
Có gì mới với GPT-4o?
Đi đầu là khái niệm về mô hình Omni, được thiết kế để hiểu và xử lý văn bản, âm thanh và video một cách liền mạch.
Trọng tâm của OpenAI dường như đã chuyển sang hướng phổ cập hóa trí thông minh cấp độ GPT-4 cho đại chúng, giúp trí thông minh mô hình ngôn ngữ cấp độ GPT-4 có thể truy cập được ngay cả với người dùng miễn phí.
OpenAI cũng thông báo rằng GPT-4o bao gồm chất lượng và tốc độ được nâng cao trên hơn 50 ngôn ngữ, hứa hẹn mang lại trải nghiệm AI toàn diện hơn và có thể truy cập toàn cầu với mức giá rẻ hơn.
Họ cũng đề cập rằng thuê bao trả phí sẽ nhận được dung lượng gấp 5 lần so với người dùng không trả phí.
Hơn nữa, họ sẽ phát hành phiên bản ChatGPT dành cho máy tính để bàn để tạo điều kiện thuận lợi cho việc suy luận theo thời gian thực trên các giao diện âm thanh, hình ảnh và văn bản cho đại chúng.
Cách sử dụng API GPT-4o
Mô hình GPT-4o mới tuân theo API hoàn thành trò chuyện hiện có từ OpenAI, giúp nó tương thích ngược và sử dụng đơn giản.
from openai import AsyncOpenAI
OPENAI_API_KEY = "<your-api-key>"
def openai_chat_resolve(response: dict, strip_tokens = None) -> str:
if strip_tokens is None:
strip_tokens = []
if response and response.choices and len(response.choices) > 0:
content = response.choices[0].message.content.strip()
if content is not None or content != '':
if strip_tokens:
for token in strip_tokens:
content = content.replace(token, '')
return content
raise Exception(f'Cannot resolve response: {response}')
async def openai_chat_request(prompt: str, model_nane: str, temperature=0.0):
message = {'role': 'user', 'content': prompt}
client = AsyncOpenAI(api_key=OPENAI_API_KEY)
return await client.chat.completions.create(
model=model_nane,
messages=[message],
temperature=temperature,
)
openai_chat_request(prompt="Hello!", model_nane="gpt-4o-2024–05–13")Đánh giá chính thức
Bài đăng trên blog của OpenAI bao gồm điểm đánh giá của các bộ dữ liệu đã biết, chẳng hạn như MMLU và HumanEval.
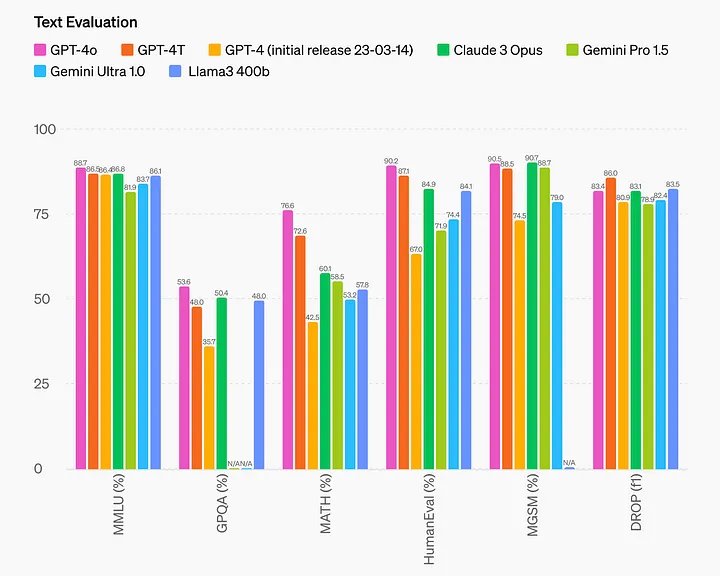
Như chúng ta có thể rút ra từ biểu đồ, hiệu suất của GPT-4o có thể được phân loại là hiện đại nhất trong lĩnh vực này – điều này nghe có vẻ rất hứa hẹn vì mẫu mới rẻ hơn và nhanh hơn.
Tuy nhiên, trong năm qua, tôi đã thấy nhiều mô hình tuyên bố có hiệu suất ngôn ngữ tiên tiến trên các tập dữ liệu đã biết. Trên thực tế, một số mô hình này đã được đào tạo một phần (hoặc quá phù hợp) trên các bộ dữ liệu mở này, dẫn đến điểm số không thực tế trên bảng xếp hạng.
Do đó, điều quan trọng là phải thực hiện các phân tích độc lập về hiệu suất của các mô hình này bằng cách sử dụng các bộ dữ liệu ít được biết đến hơn – chẳng hạn như bộ dữ liệu mà tôi đã tạo 😄
Tập dữ liệu đánh giá của tôi
Như tôi đã giải thích trong các bài viết trước, tôi đã tạo một tập dữ liệu chủ đề mà chúng ta có thể sử dụng để đo lường hiệu suất phân loại trên các LLM khác nhau.
Bộ dữ liệu bao gồm 200 câu được phân loại theo 50 chủ đề, trong đó một số câu có liên quan chặt chẽ với mục đích làm cho nhiệm vụ phân loại trở nên khó khăn hơn.
Tôi đã tạo và gắn nhãn toàn bộ tập dữ liệu bằng tiếng Anh theo cách thủ công.
Sau đó, tôi đã sử dụng GPT4 (gpt-4–0613) để dịch tập dữ liệu sang nhiều ngôn ngữ.
Tuy nhiên, trong quá trình đánh giá này, chúng tôi sẽ chỉ đánh giá phiên bản tiếng Anh của tập dữ liệu – nghĩa là kết quả sẽ không bị ảnh hưởng bởi những sai lệch tiềm ẩn bắt nguồn từ việc sử dụng cùng một mô hình ngôn ngữ để tạo tập dữ liệu và dự đoán chủ đề.
Hãy tự mình kiểm tra tập dữ liệu: tập dữ liệu chủ đề.
Kết quả thực hiện
Tôi quyết định đánh giá các mô hình sau:
- GPT-4o: gpt-4o-2024–05–13
- GPT-4: gpt-4–0613
- GPT-4-Turbo: gpt-4-turbo-2024–04–09
- Gemini 1.5 Pro: gemini-1.5-pro-preview-0409
- Gemini 1.0: gemini-1.0-pro-002
- Palm 2 Unicorn: text-unicorn@001
Nhiệm vụ được giao cho các mô hình ngôn ngữ là ghép từng câu trong tập dữ liệu với đúng chủ đề. Điều này cho phép chúng tôi tính toán điểm chính xác cho mỗi ngôn ngữ và tỷ lệ lỗi của từng mô hình.
Vì các mô hình hầu hết đều được phân loại chính xác nên tôi đang vẽ biểu đồ tỷ lệ lỗi cho từng mô hình.
Hãy nhớ rằng tỷ lệ lỗi thấp hơn cho thấy hiệu suất mô hình tốt hơn.
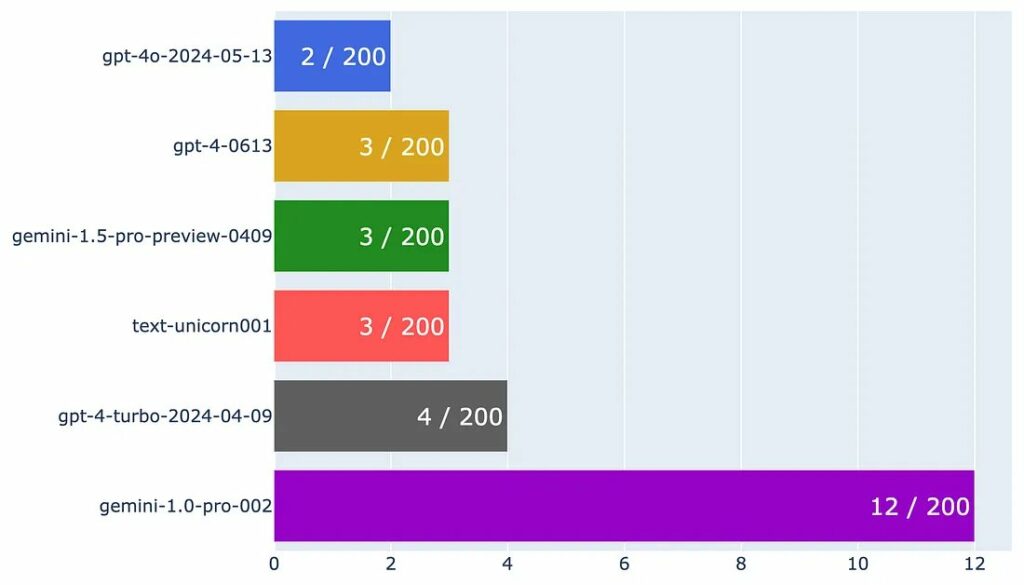
Như chúng ta có thể rút ra từ biểu đồ, GPT-4o có tỷ lệ lỗi thấp nhất trong tất cả các mẫu chỉ có 2 lỗi.
Chúng ta cũng có thể thấy rằng GPT-4, Gemini 1.5 và Palm 2 Unicorn chỉ mắc một lỗi nhiều hơn GPT-4o – thể hiện hiệu suất mạnh mẽ của chúng. Điều thú vị là GPT-4 Turbo hoạt động kém hơn một chút so với GPT-4–0613, điều này trái ngược với những gì OpenAI viết trên trang mô hình của họ .
Cuối cùng, Gemini 1.0 đang bị tụt lại phía sau, điều này được mong đợi trong phạm vi giá của nó.
Kết luận
Phân tích này sử dụng bộ dữ liệu tiếng Anh được tạo ra riêng biệt nhằm làm lộ ra những hiểu biết sâu sắc về khả năng tiên tiến của các mô hình ngôn ngữ tiên tiến này.
GPT-4o, sản phẩm mới nhất của OpenAI, nổi bật với tỷ lệ lỗi thấp nhất trong số các mẫu được thử nghiệm, điều này khẳng định tuyên bố của OpenAI về hiệu suất của nó.
Cộng đồng AI cũng như người dùng sẽ tiếp tục thực hiện các đánh giá độc lập bằng cách sử dụng các bộ dữ liệu đa dạng khác nhau, vì những bộ dữ liệu này giúp cung cấp bức tranh rõ ràng hơn về hiệu quả thực tế của mô hình, ngoài những gì được đề xuất bởi các tiêu chuẩn chuẩn hóa.
Lưu ý rằng tập dữ liệu mà chúng tôi tạo ra để đánh giá khá nhỏ và kết quả có thể khác nhau tùy thuộc vào tập dữ liệu. Hiệu suất được thực hiện chỉ bằng cách sử dụng tập dữ liệu tiếng Anh, trong khi việc so sánh đa ngôn ngữ sẽ phải đợi vào lúc khác.