


Tác giả: Aayush Mittal
Cập nhật vào ngày 16 tháng 4 năm 2024
Trong lĩnh vực tiến triển nhanh chóng của các mô hình ngôn ngữ lớn (LLMs), một mô hình mạnh mẽ mới đã xuất hiện – DBRX, một mô hình mã nguồn mở được tạo ra bởi Databricks. Mô hình LLM này đang gây sốt với hiệu suất tiên tiến trên một loạt các chỉ số, thậm chí cạnh tranh với khả năng của các công ty lớn như GPT-4 của OpenAI.
DBRX đại diện cho một cột mốc quan trọng trong việc dân chủ hóa trí tuệ nhân tạo, cung cấp cho các nhà nghiên cứu, nhà phát triển và doanh nghiệp quyền truy cập mở vào một mô hình ngôn ngữ hàng đầu. Nhưng chính xác DBRX là gì, và điều gì làm cho nó đặc biệt? Trong bài phân tích kỹ thuật sâu này, chúng ta sẽ khám phá kiến trúc đổi mới, quá trình huấn luyện và các khả năng chính đã thúc đẩy DBRX tiến lên hàng đầu trong cảnh quan LLM mã nguồn mở.
Sinh Ra của DBRX Sự sáng tạo của DBRX được thúc đẩy bởi nhiệm vụ của Databricks là làm cho trí thông minh dữ liệu trở nên dễ dàng tiếp cận đối với tất cả các doanh nghiệp. Là một trong những nhà lãnh đạo trong các nền tảng phân tích dữ liệu, Databricks nhận ra tiềm năng khổng lồ của LLMs và đã bắt đầu phát triển một mô hình có thể phù hợp hoặc thậm chí vượt qua hiệu suất của các dịch vụ độc quyền.
Sau tháng nghiên cứu, phát triển và đầu tư hàng triệu đô la, nhóm Databricks đã đạt được một bước tiến với DBRX. Hiệu suất ấn tượng của mô hình trên một loạt các chỉ số, bao gồm hiểu ngôn ngữ, lập trình và toán học, đã định rõ nó là một trong những mô hình mới tiên tiến nhất trong các LLM mã nguồn mở.
Kiến Trúc Đổi Mới
Sức Mạnh của Mixture-of-Experts Ở trung tâm của hiệu suất xuất sắc của DBRX là kiến trúc mixture-of-experts (MoE) đổi mới của nó. Thiết kế tiên tiến này đại diện cho một sự rời bỏ khỏi các mô hình dense truyền thống, áp dụng một phương pháp thưa thớt tăng cường cả hiệu quả huấn luyện trước và tốc độ suy luận.
Trong khung cảnh MoE, chỉ một nhóm được chọn lựa các thành phần, gọi là “chuyên gia,” được kích hoạt cho mỗi đầu vào. Sự chuyên môn này cho phép mô hình xử lý một loạt các nhiệm vụ rộng lớn với độ thành thạo lớn hơn, đồng thời cũng tối ưu hóa tài nguyên tính toán.
DBRX đưa khái niệm này thậm chí còn xa hơn với kiến trúc MoE tinh tế của nó. Khác với một số mô hình MoE khác sử dụng một số ít chuyên gia lớn hơn, DBRX sử dụng 16 chuyên gia, với bốn chuyên gia hoạt động cho bất kỳ đầu vào nào. Thiết kế này cung cấp một con số ấn tượng lên đến 65 lần nhiều tổ hợp chuyên gia có thể, góp phần trực tiếp vào hiệu suất vượt trội của DBRX.
DBRX khác biệt với một số tính năng đổi mới:
- Rotary Position Encodings (RoPE): Tăng cường hiểu biết về vị trí của token, rất quan trọng để tạo ra văn bản chính xác theo ngữ cảnh.
- Gated Linear Units (GLU): Giới thiệu một cơ chế cửa hàng nhấn mạnh khả năng học các mẫu phức tạp của mô hình một cách hiệu quả hơn.
- Grouped Query Attention (GQA): Cải thiện hiệu suất của mô hình bằng cách tối ưu hóa cơ chế chú ý.
- Tokenization Tiên Tiến: Sử dụng bộ từ vựng của GPT-4 để xử lý đầu vào một cách hiệu quả hơn.
Kiến trúc MoE đặc biệt thích hợp cho các mô hình ngôn ngữ lớn quy mô, vì nó cho phép việc mở rộng hiệu quả hơn và tận dụng tốt hơn tài nguyên tính toán. Bằng cách phân phối quá trình học trên nhiều mạng con chuyên môn, DBRX có thể phân bổ dữ liệu và sức mạnh tính toán một cách hiệu quả cho mỗi nhiệm vụ, đảm bảo cả đầu ra chất lượng cao và hiệu quả tối ưu.
Dữ liệu Huấn Luyện Mở Rộng và Tối Ưu Hóa Hiệu Quả Mặc dù kiến trúc của DBRX không thể phủ nhận là ấn tượng, sức mạnh thực sự của nó nằm ở quá trình huấn luyện tỉ mỉ và lượng dữ liệu rộng lớn mà nó đã tiếp xúc. DBRX được huấn luyện trước trên một lượng kinh khủng 12 nghìn tỉ token của dữ liệu văn bản và mã nguồn, được chăm sóc cẩn thận để đảm bảo chất lượng và đa dạng.
Dữ liệu huấn luyện được xử lý bằng bộ công cụ của Databricks, bao gồm Apache Spark cho xử lý dữ liệu, Unity Catalog cho quản lý và quản trị dữ liệu, và MLflow cho việc theo dõi thí nghiệm. Bộ công cụ toàn diện này cho phép nhóm Databricks quản lý, khám phá và tinh chỉnh tập dữ liệu khổng lồ một cách hiệu quả, đặt nền tảng cho hiệu suất xuất sắc của DBRX.
Để nâng cao khả năng của mô hình, Databricks đã sử dụng một chương trình học trước động, đổi mới bằng cách thay đổi mix dữ liệu trong quá trình huấn luyện. Chiến lược này cho phép mỗi token được xử lý một cách hiệu quả bằng cách sử dụng 36 tỉ tham số hoạt động, dẫn đến một mô hình linh hoạt và có thể thích ứng tốt hơn.
Hơn nữa, quá trình huấn luyện của DBRX đã được tối ưu hóa cho hiệu quả, tận dụng bộ công cụ và thư viện độc quyền của Databricks, bao gồm Composer, LLM Foundry, MegaBlocks và Streaming. Bằng cách sử dụng các kỹ thuật như học giáo trình và các chiến lược tối ưu hóa tối ưu, nhóm đã đạt được gần 4 lần cải thiện về hiệu quả tính toán so với các mô hình trước đó của họ.
Huấn Luyện và Kiến Trúc
DBRX được huấn luyện bằng một mô hình dự đoán token tiếp theo trên một tập dữ liệu khổng lồ gồm 12 nghìn tỉ token, tập trung vào cả văn bản và mã nguồn. Tập dữ liệu huấn luyện này được cho là hiệu quả đáng kể hơn so với những tập dữ liệu được sử dụng trong các mô hình trước đó, đảm bảo một hiểu biết phong phú và khả năng phản ứng đa dạng trên các yêu cầu khác nhau.
Kiến trúc của DBRX không chỉ là một minh chứng cho sự khéo léo kỹ thuật của Databricks mà còn là điểm nhấn của ứng dụng của nó trong nhiều lĩnh vực. Từ việc tăng cường tương tác của trợ lý ảo đến việc cung cấp sức mạnh cho các nhiệm vụ phân tích dữ liệu phức tạp, DBRX có thể được tích hợp vào các lĩnh vực đa dạng đòi hỏi hiểu biết ngôn ngữ tinh tế.
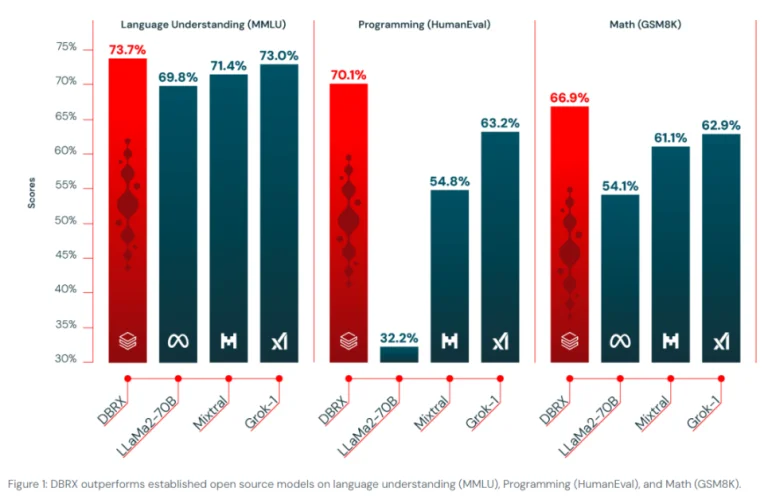
Đáng chú ý, DBRX Instruct thậm chí còn cạnh tranh với một số mô hình đóng trên thị trường. Theo đo lường của Databricks, nó vượt qua GPT-3.5 và cạnh tranh với Gemini 1.0 Pro và Mistral Medium trên các chỉ số khác nhau, bao gồm kiến thức tổng quát, lập luận thông thường, lập trình và lập luận toán học.
Ví dụ, trên chỉ số MMLU, đo lường hiểu ngôn ngữ, DBRX Instruct đạt được điểm số 73,7%, vượt qua điểm số báo cáo của GPT-3.5 là 70,0%. Trên chỉ số lập luận thông thường HellaSwag, DBRX Instruct đạt được điểm số ấn tượng là 89,0%, vượt qua 85,5% của GPT-3.5.
DBRX Instruct thực sự tỏa sáng, đạt được 70,1% độ chính xác trên chỉ số HumanEval, vượt qua không chỉ GPT-3.5 (48,1%) mà còn mô hình chuyên biệt CodeLLaMA-70B Instruct (67,8%).
Những kết quả xuất sắc này nhấn mạnh tính linh hoạt của DBRX và khả năng vượt trội trên một loạt các nhiệm vụ, từ hiểu ngôn ngữ tự nhiên đến lập trình phức tạp và giải quyết vấn đề toán học.
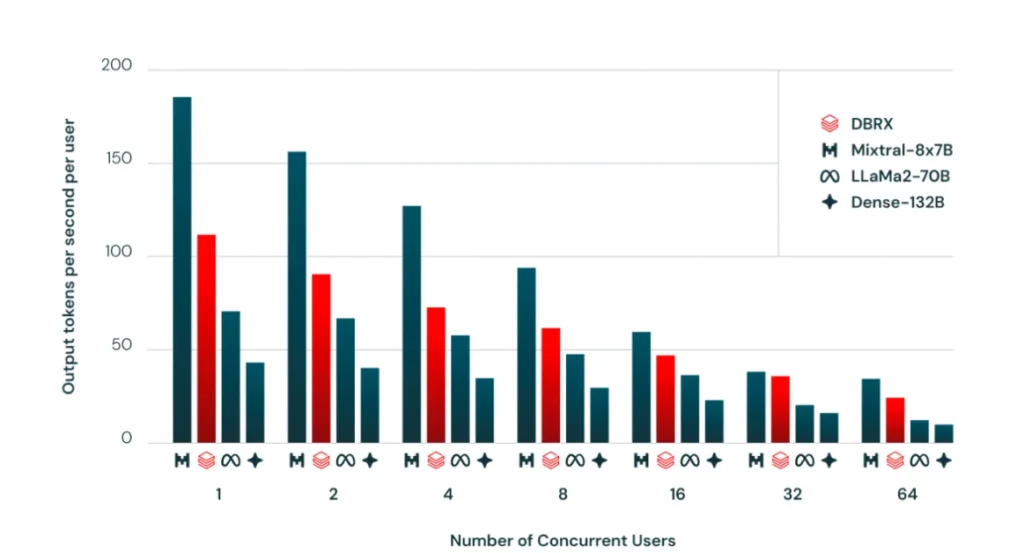
Suy luận Hiệu Quả và Khả năng Mở Rộng Một trong những ưu điểm chính của kiến trúc MoE của DBRX là hiệu quả trong quá trình suy luận. Nhờ vào việc kích hoạt thưa của các tham số, DBRX có thể đạt được tốc độ suy luận nhanh gấp đôi hoặc ba lần so với các mô hình dense có cùng số lượng tham số tổng.
So với LLaMA2-70B, một LLM mã nguồn mở phổ biến, DBRX không chỉ thể hiện chất lượng cao hơn mà còn tự hào về tốc độ suy luận gần gấp đôi, mặc dù có khoảng một nửa số lượng tham số hoạt động. Hiệu quả này khiến cho DBRX trở thành một lựa chọn hấp dẫn cho triển khai trong một loạt các ứng dụng, từ việc tạo nội dung đến phân tích dữ liệu và hơn thế nữa.
Hơn nữa, Databricks đã phát triển một ngăn xếp huấn luyện mạnh mẽ cho phép các doanh nghiệp huấn luyện các mô hình cùng cấp của DBRX từ đầu hoặc tiếp tục huấn luyện trên các điểm kiểm soát được cung cấp. Khả năng này giúp các doanh nghiệp tận dụng toàn bộ tiềm năng của DBRX và điều chỉnh nó theo nhu cầu cụ thể của họ, làm tiếp cận công nghệ LLM tiên tiến trở nên phổ biến hơn.
Việc phát triển mô hình DBRX của Databricks đánh dấu một bước tiến đáng kể trong lĩnh vực học máy, đặc biệt là thông qua việc sử dụng các công cụ đổi mới từ cộng đồng mã nguồn mở. Hành trình phát triển này được ảnh hưởng đáng kể bởi hai công nghệ then chốt: thư viện MegaBlocks và hệ thống Fully Sharded Data Parallel (FSDP) của PyTorch.
MegaBlocks: Tăng Cường Hiệu Quả của MoE
Thư viện MegaBlocks giải quyết các thách thức liên quan đến việc định tuyến động trong các lớp Mixture-of-Experts (MoEs), một rào cản phổ biến trong việc mở rộng mạng nơ-ron. Các khung công việc truyền thống thường áp đặt các giới hạn có thể làm giảm hiệu quả của mô hình hoặc làm tổn thất chất lượng của mô hình. Tuy nhiên, MegaBlocks tái định nghĩa tính toán MoE thông qua các phép tính thưa thớt khối giúp quản lý một cách thành thạo tính động bên trong MoEs, do đó tránh được những sự hy sinh này.
Phương pháp này không chỉ bảo tồn tính nguyên vẹn của token mà còn phù hợp tốt với khả năng hiện đại của GPU, giúp việc huấn luyện nhanh hơn đến 40% so với các phương pháp truyền thống. Sự hiệu quả như vậy rất quan trọng cho việc huấn luyện các mô hình như DBRX, mà dựa nhiều vào các kiến trúc MoE tiên tiến để quản lý tập hợp tham số rộng lớn của mình một cách hiệu quả.
PyTorch FSDP: Mở Rộng Các Mô Hình Lớn
Fully Sharded Data Parallel (FSDP) của PyTorch cung cấp một giải pháp mạnh mẽ cho việc huấn luyện các mô hình cực kỳ lớn bằng cách tối ưu hóa việc phân chia và phân phối tham số trên nhiều thiết bị tính toán. Được thiết kế cùng với các thành phần quan trọng của PyTorch, FSDP tích hợp một cách mượt mà, mang lại trải nghiệm người dùng trực quan tương tự như cài đặt huấn luyện cục bộ nhưng trên quy mô lớn hơn nhiều.
Thiết kế của FSDP một cách thông minh giải quyết một số vấn đề quan trọng sau:
- Trải Nghiệm Người Dùng: Nó đơn giản hóa giao diện người dùng, bất kể các quy trình backend phức tạp, làm cho nó dễ truy cập hơn để sử dụng rộng rãi hơn.
- Đa Dạng Thiết Bị: Nó thích nghi với môi trường phần cứng đa dạng để tối ưu hóa việc sử dụng tài nguyên một cách hiệu quả.
- Tận Dụng Tài Nguyên và Lập Kế Hoạch Bộ Nhớ: FSDP tăng cường việc sử dụng các tài nguyên tính toán trong khi giảm thiểu các chi phí bộ nhớ, điều này quan trọng cho việc huấn luyện các mô hình hoạt động ở quy mô của DBRX.
FSDP không chỉ hỗ trợ các mô hình lớn hơn so với trước đây dưới khung Distributed Data Parallel mà còn duy trì tính mở rộng gần như tuyến tính về thời gian hoàn thành và hiệu suất. Khả năng này đã được chứng minh là quan trọng đối với DBRX của Databricks, cho phép nó mở rộng qua nhiều GPU trong khi quản lý hiệu quả số lượng tham số rộng lớn của mình.
Sự Tiếp Cận và Tích Hợp
Phù hợp với sứ mệnh của mình là thúc đẩy sự tiếp cận mở đến trí tuệ nhân tạo, Databricks đã làm cho DBRX có sẵn thông qua nhiều kênh. Cả trọng lượng của cả hai mô hình cơ bản (DBRX Base) và mô hình được điều chỉnh (DBRX Instruct) đều được lưu trữ trên nền tảng phổ biến Hugging Face, cho phép các nhà nghiên cứu và nhà phát triển dễ dàng tải xuống và làm việc với mô hình.
Ngoài ra, kho lưu trữ mô hình DBRX có sẵn trên GitHub, cung cấp sự minh bạch và cho phép khám phá và tùy chỉnh mã nguồn của mô hình.
Đối với các khách hàng của Databricks, DBRX Base và DBRX Instruct có thể dễ dàng truy cập thông qua các API Mô hình Nền tảng Databricks, cho phép tích hợp mượt mà vào các luồng công việc và ứng dụng hiện có. Điều này không chỉ đơn giản hóa quá trình triển khai mà còn đảm bảo quản lý dữ liệu và bảo mật cho các trường hợp sử dụng nhạy cảm.
Hơn nữa, DBRX đã được tích hợp vào một số nền tảng và dịch vụ bên thứ ba, như You.com và Perplexity Labs, mở rộng phạm vi và ứng dụng tiềm năng của nó. Những tích hợp này cho thấy sự quan tâm ngày càng tăng về DBRX và khả năng của nó, cũng như sự gia tăng về sự chấp nhận của các LLM mã nguồn mở trong các ngành công nghiệp và trường hợp sử dụng khác nhau.
Khả năng Xử Lý Ngữ Cảnh Dài và Tạo Ra Bổ Sung thông qua Tra Cứu Một trong những tính năng nổi bật của DBRX là khả năng xử lý đầu vào có ngữ cảnh dài, với độ dài ngữ cảnh tối đa là 32,768 token. Khả năng này cho phép mô hình xử lý và tạo ra văn bản dựa trên thông tin ngữ cảnh rộng lớn, làm cho nó phù hợp cho các nhiệm vụ như tóm tắt tài liệu, trả lời câu hỏi và truy xuất thông tin.
Trong các chỉ số đánh giá hiệu suất ngữ cảnh dài, như KV-Pairs và HotpotQAXL, DBRX Instruct vượt trội so với GPT-3.5 Turbo trên nhiều độ dài chuỗi và vị trí ngữ cảnh khác nhau.
Hạn Chế và Công Việc Tương Lai
Mặc dù DBRX đại diện cho một thành tựu đáng kể trong lĩnh vực các mô hình ngôn ngữ lớn mở, nhưng cũng cần nhận biết các hạn chế và các lĩnh vực cần cải thiện trong tương lai. Giống như bất kỳ mô hình trí tuệ nhân tạo nào, DBRX cũng có thể tạo ra các phản ứng không chính xác hoặc thiên vị, phụ thuộc vào chất lượng và đa dạng của dữ liệu huấn luyện của nó.
Ngoài ra, trong khi DBRX xuất sắc trong các nhiệm vụ đa mục đích, một số ứng dụng cụ thể trong một lĩnh vực cụ thể có thể đòi hỏi việc điều chỉnh tiếp theo hoặc huấn luyện chuyên sâu hơn để đạt được hiệu suất tối ưu. Ví dụ, trong các kịch bản nơi độ chính xác và trung thực là quan trọng nhất, Databricks khuyến nghị sử dụng các kỹ thuật tăng cường truy xuất và tạo ra (RAG) để cải thiện đầu ra của mô hình.
Hơn nữa, tập dữ liệu huấn luyện hiện tại của DBRX chủ yếu bao gồm nội dung tiếng Anh, có thể giới hạn hiệu suất của nó trong các nhiệm vụ không phải tiếng Anh. Các phiên bản trong tương lai của mô hình có thể bao gồm mở rộng dữ liệu huấn luyện để bao gồm một loạt các ngôn ngữ và ngữ cảnh văn hóa đa dạng hơn.
Databricks cam kết liên tục cải thiện khả năng của DBRX và đối phó với các hạn chế của nó. Công việc trong tương lai sẽ tập trung vào việc cải thiện hiệu suất, khả năng mở rộng và tính khả dụng của mô hình trên các ứng dụng và trường hợp sử dụng khác nhau, cũng như khám phá các kỹ thuật để giảm thiểu các thiên lệch tiềm ẩn và thúc đẩy việc sử dụng trí tuệ nhân tạo một cách đạo đức.
Ngoài ra, công ty cũng có kế hoạch để tinh chỉnh quá trình huấn luyện hơn nữa, tận dụng các kỹ thuật tiên tiến như học phân tán và các phương pháp bảo vệ quyền riêng tư để đảm bảo quyền riêng tư và bảo mật của dữ liệu.
Hướng Tiếp Theo
DBRX đại diện cho một bước tiến quan trọng trong việc dân chủ hóa phát triển trí tuệ nhân tạo. Nó hình dung một tương lai trong đó mọi doanh nghiệp đều có khả năng kiểm soát dữ liệu của mình và số phận của mình trong thế giới mới nổi của trí tuệ nhân tạo sáng tạo.
Bằng cách làm cho DBRX trở thành mã nguồn mở và cung cấp quyền truy cập vào các công cụ và cơ sở hạ tầng giống như những công cụ và cơ sở hạ tầng được sử dụng để xây dựng nó, Databricks đang trao quyền cho doanh nghiệp và nhà nghiên cứu phát triển Databricks tiên tiến riêng của họ phù hợp với nhu cầu cụ thể của họ.
Thông qua nền tảng Databricks, các khách hàng có thể tận dụng bộ công cụ xử lý dữ liệu của công ty, bao gồm Apache Spark, Unity Catalog và MLflow, để chọn lọc và quản lý dữ liệu huấn luyện của họ. Sau đó, họ có thể sử dụng các thư viện huấn luyện được tối ưu hóa của Databricks, chẳng hạn như Composer, LLM Foundry, MegaBlocks và Streaming, để huấn luyện các mô hình cấp DBRX của riêng họ một cách hiệu quả và ở quy mô lớn.
Sự dân chủ hóa của việc phát triển trí tuệ nhân tạo có tiềm năng mở khóa một làn sóng đổi mới, khi các doanh nghiệp có khả năng tận dụng sức mạnh của các mô hình ngôn ngữ lớn cho một loạt các ứng dụng, từ việc tạo nội dung và phân tích dữ liệu đến hỗ trợ quyết định và hơn thế nữa.
Hơn nữa, bằng cách tạo ra một hệ sinh thái mở và hợp tác xung quanh DBRX, Databricks nhằm tăng tốc độ nghiên cứu và phát triển trong lĩnh vực các mô hình ngôn ngữ lớn. Khi có nhiều tổ chức và cá nhân đóng góp kiến thức chuyên môn và hiểu biết của họ, tri thức và sự hiểu biết tổng hợp về những hệ thống trí tuệ nhân tạo mạnh mẽ này sẽ tiếp tục phát triển, mở đường cho các mô hình càng phát triển và có khả năng hơn trong tương lai.
Thay lời kết
DBRX là một bước đột phá trong thế giới của các mô hình ngôn ngữ lớn mã nguồn mở. Với kiến trúc tiên tiến của nó dựa trên sự kết hợp của các chuyên gia, tập dữ liệu huấn luyện rộng lớn và hiệu suất hàng đầu, nó đã đặt ra một tiêu chuẩn mới cho những gì có thể thực hiện được với các LLM mã nguồn mở.
Bằng cách dân chủ hóa quyền truy cập vào công nghệ trí tuệ nhân tạo tiên tiến, DBRX trao quyền cho các nhà nghiên cứu, nhà phát triển và doanh nghiệp khám phá những ranh giới mới trong xử lý ngôn ngữ tự nhiên, tạo nội dung, phân tích dữ liệu, và nhiều hơn nữa. Khi Databricks tiếp tục tinh chỉnh và cải thiện DBRX, tiềm năng ứng dụng và tác động của mô hình mạnh mẽ này là vô song.