

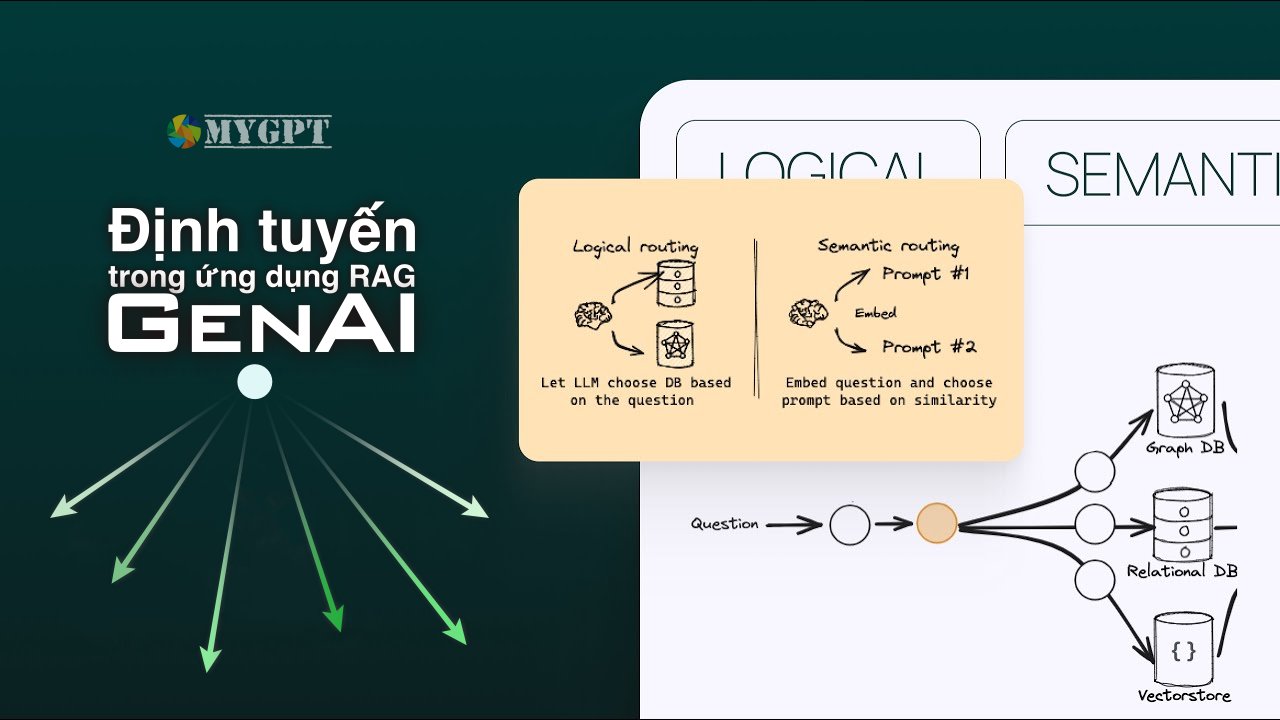
Định tuyến luồng điều khiển bên trong ứng dụng RAG dựa trên mục đích truy vấn của người dùng có thể giúp chúng ta tạo các ứng dụng dựa trên Truy xuất tăng cường (RAG) trở nên hữu ích và mạnh mẽ hơn.
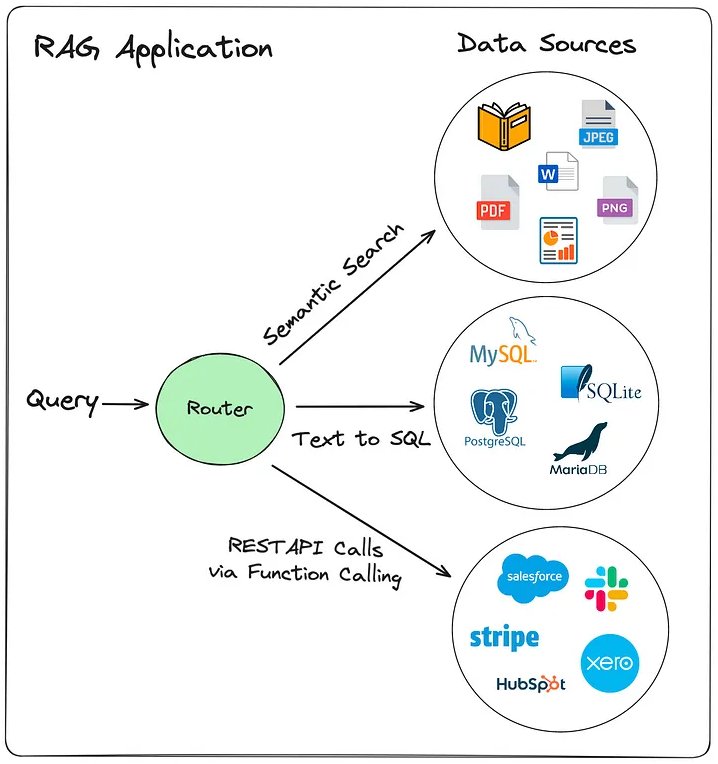
Các nguồn dữ liệu chúng ta muốn cho phép người dùng tương tác có thể đến từ nhiều nguồn khác nhau, chẳng hạn như từ báo cáo, tài liệu, hình ảnh, cơ sở dữ liệu và hệ thống của bên thứ ba. Đối với các ứng dụng RAG ở mức độ doanh nghiệp, chúng ta có thể cho phép người dùng tương tác với thông tin từ nhiều lĩnh vực khác nhau trong doanh nghiệp, chẳng hạn như từ hệ thống bán hàng, đặt hàng và kế toán…
Do có nhiều nguồn dữ liệu đa dạng nên cách thông tin được lưu trữ và cách chúng ta tương tác với nó cũng có thể sẽ rất đa dạng. Một số dữ liệu có thể được lưu trữ trong các cơ sở dữ liệu vectơ, một số trong cơ sở dữ liệu quan hệ và một số dữ liệu mà chúng ta có thể cần truy cập qua lệnh gọi API vì dữ liệu đó nằm trong hệ thống do bên thứ ba cung cấp.
Có thể có các thiết lập đến các csdl vectơ khác nhau cho cùng một dữ liệu nhưng được tối ưu hóa cho các loại truy vấn khác nhau. Ví dụ: một csdl vectơ có thể được thiết lập để trả lời các câu hỏi loại tóm tắt và một csdl khác để trả lời các câu hỏi loại cụ thể, có định hướng.
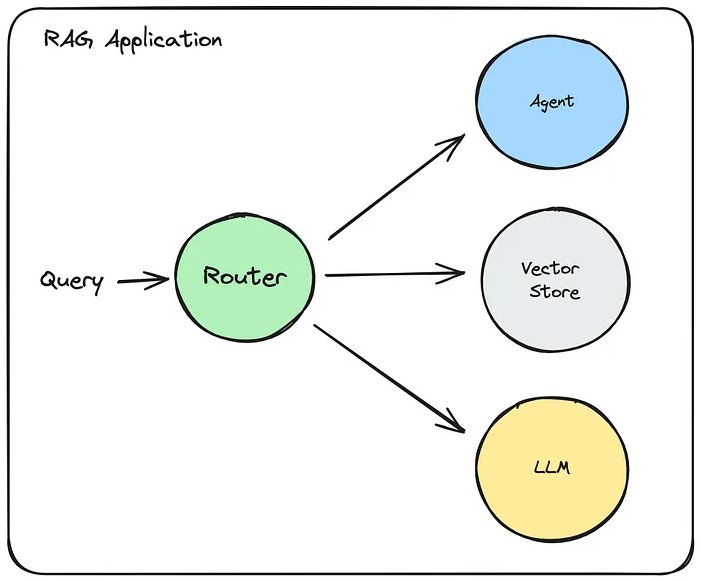
Và chúng ta cũng có thể muốn định tuyến đến các loại thành phần xử lý khác nhau, dựa trên câu hỏi. Ví dụ: chúng tôi có thể muốn chuyển truy vấn tới Tác nhân, VectorStore hoặc trực tiếp đến LLM để xử lý, tất cả đều dựa trên bản chất của câu hỏi được người dùng gửi tới.
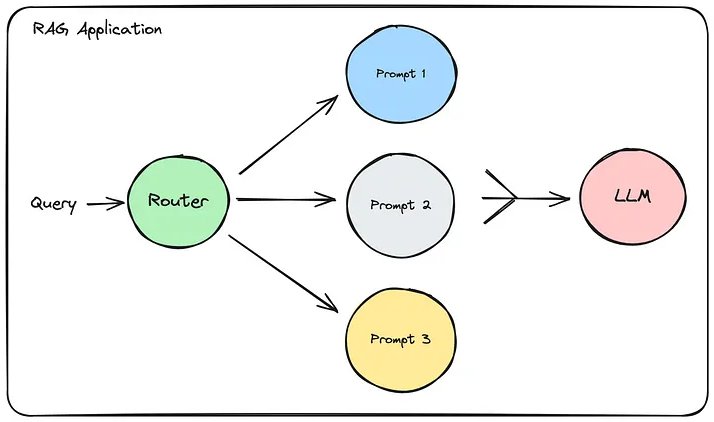
Chúng ta thậm chí có thể muốn tùy chỉnh các mẫu lời nhắc tùy thuộc vào câu hỏi được hỏi.
Nhìn chung, có rất nhiều lý do khiến chúng ta muốn thay đổi và điều hướng luồng truy vấn của người dùng thông qua ứng dụng. Ứng dụng của chúng ta càng cố gắng đáp ứng nhiều trường hợp sử dụng thì chúng ta càng có nhiều khả năng có các yêu cầu định tuyến trong toàn bộ ứng dụng.
Bộ định tuyến về cơ bản chỉ là các câu lệnh If/Else mà chúng ta có thể sử dụng để điều khiển luồng điều khiển của truy vấn.
Tuy nhiên, điều thú vị ở đây là chúng ta cần đưa ra quyết định dựa trên đầu vào ngôn ngữ tự nhiên chứ không phải các chỉ thị Nếu/Thì cố định. Vì vậy, trong bài viết này chúng ta cùng nhau tìm kiếm một giải pháp riêng biệt dựa trên mô tả ngôn ngữ tự nhiên.
Và vì phần lớn logic định tuyến dựa trên việc sử dụng LLM hoặc thuật toán học máy, vốn có bản chất không xác định nên chúng ta cũng có thể đối mặt với khả năng bộ định tuyến sẽ luôn đưa ra lựa chọn đúng 100%. Hơn nữa, chúng ta cũng khó có thể dự đoán tất cả các biến thể truy vấn khác nhau có trong bộ định tuyến. Tuy nhiên, bằng cách sử dụng các phương pháp mới nhất và một số thử nghiệm mà chúng tôi đề cập ở đây có thể giúp tạo ra các ứng dụng RAG mạnh mẽ hơn.
Bộ định tuyến ngôn ngữ tự nhiên
Ở đây chúng ta sẽ khám phá một vài bộ điều hướng ngôn ngữ tự nhiên mà chúng tôi đã tìm thấy, được triển khai bởi một số framework và thư viện RAG và các LLM khác nhau.
- Bộ định tuyến Hoàn toàn LLM (LLM Completion Routers)
- Bộ định tuyến Gọi hàm LLM (LLM Function Calling Routers)
- Bộ định tuyến Ngữ nghĩa (Semantic Routers)
- Bộ định tuyến Phân loại không cần huấn luyện (Zero Shot Classification Routers)
- Bộ định tuyến Phân loại ngôn ngữ (Language Classification Routers)
Sơ đồ bên dưới đây mô tả các bộ định tuyến này, cùng với các framework/gói đi kèm.
Sơ đồ cũng bao gồm Bộ định tuyến logic, mà chúng ta cần xác định đây là bộ định tuyến hoạt động dựa trên logic rời rạc, chẳng hạn như các điều kiện đối với độ dài chuỗi, tên tệp, giá trị số nguyên, v.v. Nói cách khác, chúng không dựa trên việc phải hiểu mục đích của ngôn ngữ tự nhiên truy vấn
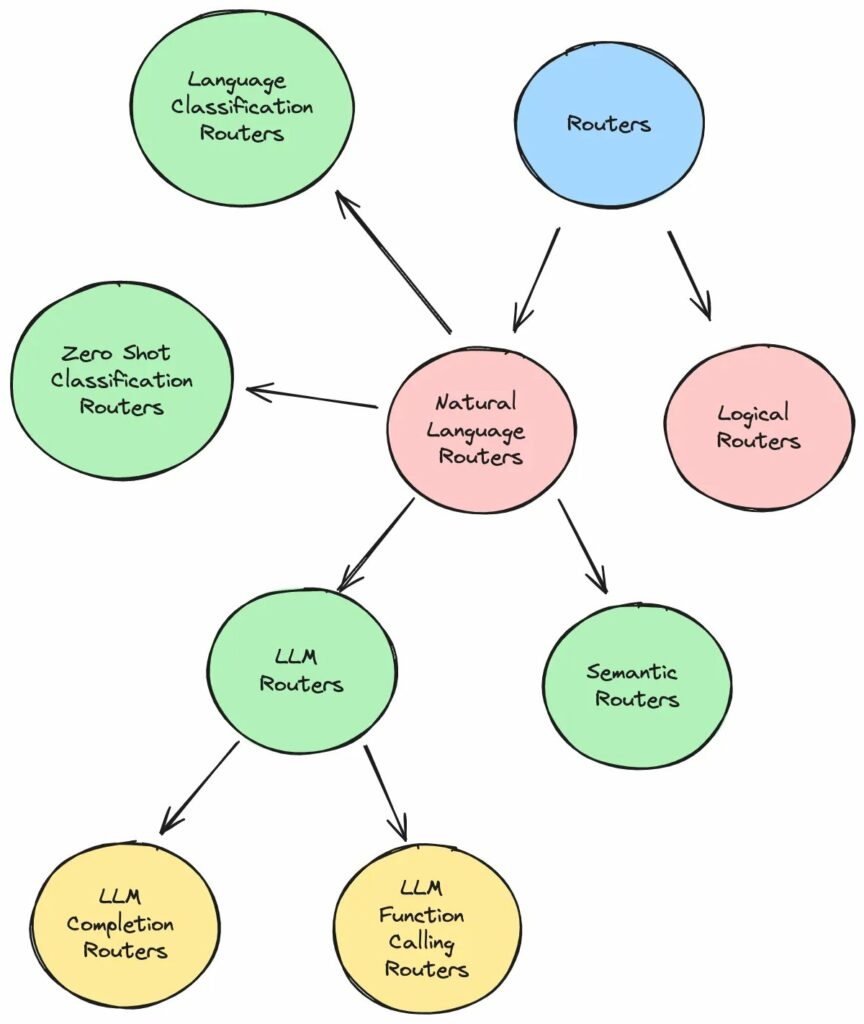
Hãy cùng khám phá từng bộ định tuyến này một cách chi tiết hơn
Bộ định tuyến LLM
Những điều này tận dụng khả năng ra quyết định của LLM để chọn tuyến đường dựa trên truy vấn của người dùng.
Bộ định tuyến hoàn toàn LLM
Chúng sử dụng lệnh gọi hoàn toàn dựa vào LLM và yêu cầu LLM trả về một “từ ngữ” mô tả đúng nhất truy vấn có trong danh sách các tùy chọn “từ ngữ” mà bạn định nghĩa để chuyển đến qua lời nhắc với LLM. “Từ ngữ” được LLM trả về sau đó có thể được sử dụng như một phần của điều kiện If/Else để kiểm soát luồng ứng dụng.
Đây là cách hàm LLM Selector trong LlamaIndex hoạt động. Và cũng là ví dụ được đưa ra cho bộ định tuyến bên trong tài liệu của LangChain.
Chúng ta hãy xem một mẫu mã nguồn, dựa trên mẫu được cung cấp trong tài liệu LangChain, để làm rõ hơn một chút. Như bạn có thể thấy, việc tự mình xem xét một trong những thứ như vậy bên trong LangChain khá đơn giản.
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# Thiết lập Chuỗi LLM để trả về một từ duy nhất dựa trên truy vấn,
# và dựa trên danh sách các từ chúng ta cung cấp cho nó trong lời nhắc
llm_completion_select_route_chain = (
PromptTemplate.from_template("""
Given the user question below, classify it as either
being about `LangChain`, `Anthropic`, or `Other`.
Do not respond with more than one word.
<question>
{question}
</question>
Classification:"""
)
| ChatAnthropic(model_name="claude-3-haiku")
| StrOutputParser()
)
# Thiết lập điều kiện IF/Else để định tuyến truy vấn đến đúng chuỗi
# dựa trên lệnh gọi hoàn thành LLM ở trên
def route_to_chain(route_name):
if "anthropic" == route_name.lower():
return anthropic_chain
elif "langchain" == route_name.lower():
return langchain_chain
else:
return general_chain
...
# Trong ứng dụng, chúng ta có thể sử dụng phản hồi từ chuỗi hoàn thành LLM # để kiểm soát (tức là định tuyến) luồng ứng dụng
# đến chuỗi chính xác thông qua phương thức Route_to_chain đã tạo
route_name = llm_completion_select_route_chain.invoke(user_query)
chain = route_to_chain(route_name)
chain.invoke(user_query)Bộ định tuyến gọi hàm LLM
Cách này sử dụng khả năng gọi hàm của chính các LLM để chọn tuyến đường đi qua. Các tuyến khác nhau được thiết lập dưới dạng các hàm với các mô tả thích hợp trong Lệnh gọi hàm LLM. Sau đó, dựa trên truy vấn được chuyển đến LLM, nó có thể trả về đúng hàm (tức là tuyến đường) để chúng ta thực hiện.
Đây là cách Bộ định tuyến Pydantic hoạt động bên trong LlamaIndex. Và đây cũng là cách mà hầu hết các Đại lý làm việc để chọn đúng công cụ cần sử dụng. Chúng sử dụng khả năng Gọi hàm (function-calling) của LLM để chọn công cụ chính xác cho công việc dựa trên truy vấn của người dùng.
Bộ định tuyến ngữ nghĩa
Loại bộ định tuyến này tận dụng các tìm kiếm nhúng và tìm kiếm tương tự để chọn tuyến đường tốt nhất sẽ đi qua.
Mỗi tuyến đường có một tập hợp các truy vấn mẫu được liên kết với nó, các truy vấn này sẽ được nhúng và lưu trữ dưới dạng vectơ. Truy vấn đến cũng được nhúng và tìm kiếm tương tự được thực hiện đối với các truy vấn mẫu khác từ bộ định tuyến. Tuyến đường thuộc truy vấn có kết quả phù hợp nhất sẽ được chọn.
Trên thực tế, có một gói python được gọi là bộ định tuyến ngữ nghĩa thực hiện việc này. Hãy xem xét một số chi tiết triển khai để hiểu rõ hơn về cách thức hoạt động của toàn bộ sự việc. Những ví dụ này được lấy trực tiếp từ trang GitHub của thư viện đó.
Hãy thiết lập hai lộ trình, một dành cho các câu hỏi về chính trị và một dành cho các câu hỏi thuộc loại tán gẫu chung. Đối với mỗi tuyến đường, chúng tôi chỉ định một danh sách các câu hỏi thường có thể được hỏi để kích hoạt tuyến đường đó. Những truy vấn ví dụ này được gọi là cách nói. Những cách nói này sẽ được nhúng để chúng tôi có thể sử dụng chúng cho các tìm kiếm tương tự đối với truy vấn của người dùng.
from semantic_router import Route
# Chúng ta có thể sử dụng hướng dẫn này để hướng cho chatbot của mình tránh các hội thoại về chính trị
politics = Route(
name="politics",
utterances=[
"isn't politics the best thing ever",
"why don't you tell me about your political opinions",
"don't you just love the president",
"they're going to destroy this country!",
"they will save the country!",
],
)
# điều này có thể được sử dụng như một chỉ báo cho chatbot của chúng ta chuyển sang một prompt hội thoại khác
chitchat = Route(
name="chitchat",
utterances=[
"how's the weather today?",
"how are things going?",
"lovely weather today",
"the weather is horrendous",
"let's go to the chippy",
],
)
# chúng ta đặt cả hai quyết định của mình vào một danh sách duy nhất
routes = [politics, chitchat]Chúng ta chỉ định OpenAI làm bộ mã hóa, mặc dù mọi thư viện nhúng đều sẽ hoạt động. Và tiếp theo, chúng ta tạo lớp tuyến đường bằng cách sử dụng bộ định tuyến và bộ mã hóa.
encoder = OpenAIEncoder()
from semantic_router.layer import RouteLayer
route_layer = RouteLayer(encoder=encoder, routes=routes)Sau đó, khi áp dụng truy vấn của chúng ta đối với lớp bộ định tuyến, nó sẽ trả về tuyến đường nên được sử dụng cho truy vấn
route_layer("don't you love politics?").name
# -> 'politics'Vì vậy, bộ định tuyến ngữ nghĩa này tận dụng các phần nhúng và tìm kiếm tương tự bằng cách sử dụng truy vấn của người dùng để chọn tuyến đường tối ưu để đi qua. Loại bộ định tuyến này cũng sẽ nhanh hơn các bộ định tuyến dựa trên LLM khác, vì nó chỉ yêu cầu xử lý một truy vấn Chỉ mục duy nhất, trái ngược với các loại khác yêu cầu cuộc gọi đến LLM.
Bộ định tuyến phân loại Zero Shot
“Phân loại văn bản Zero-shot là một nhiệm vụ trong xử lý ngôn ngữ tự nhiên trong đó một mô hình được đào tạo trên một tập hợp các ví dụ được gắn nhãn nhưng sau đó có thể phân loại các ví dụ mới từ các lớp chưa từng thấy trước đó”. Các bộ định tuyến này tận dụng mô hình Phân loại Zero-Shot để gán nhãn cho một đoạn văn bản, từ một bộ nhãn được xác định trước mà bạn chuyển vào bộ định tuyến.
Ví dụ: ZeroShotTextRouter trong Haystack, tận dụng mô hình Phân Loại Không Cần Huấn Luyện từ Hugging Face.
Bộ định tuyến phân loại ngôn ngữ
Loại bộ định tuyến này có thể xác định ngôn ngữ của truy vấn và định tuyến truy vấn dựa trên ngôn ngữ đó. Sẽ hữu ích nếu bạn yêu cầu một số loại khả năng phân tích cú pháp đa ngôn ngữ trong ứng dụng của mình.
Ví dụ: TextClassificationRouter từ Haystack. Nó tận dụng thư viện lang detect python để phát hiện ngôn ngữ của văn bản, bản thân thư viện này sử dụng thuật toán Naive Bayes để phát hiện ngôn ngữ.
Bộ định tuyến từ khóa
Bài viết này của Jerry Liu, Người đồng sáng lập của LlamaIndex, về định tuyến bên trong các ứng dụng RAG, đề xuất, trong số các tùy chọn khác, một bộ định tuyến từ khóa sẽ cố gắng chọn một tuyến đường bằng cách khớp các từ khóa giữa danh sách truy vấn và tuyến đường.
Bộ định tuyến từ khóa này cũng có thể được cung cấp bởi LLM để xác định từ khóa hoặc bởi một số thư viện đối sánh từ khóa khác. Hiện tại chúng tôi chưa tìm thấy bất kỳ gói nào triển khai loại bộ định tuyến này tuy nhiên trong từng dự án cụ thể mà MyGPT triển khai, chúng tôi có thể sử dụng phương pháp này bằng các triển khai riêng để đáp ứng nhu cầu ứng dụng trong thực tế.
Bộ định tuyến logic
Chúng sử dụng tính năng kiểm tra logic đối với các biến, chẳng hạn như độ dài chuỗi, tên tệp và so sánh giá trị để xử lý cách định tuyến truy vấn. Chúng rất giống với các điều kiện If/Else điển hình được sử dụng trong lập trình.
Nói cách khác, nó sẽ không dựa trên việc phải hiểu mục đích của truy vấn ngôn ngữ tự nhiên mà có thể đưa ra lựa chọn dựa trên các biến hiện có và một số dạng dữ liệu rời rạc đầu vào.
Ví dụ: ConditionalRouter và FileTypeRouter từ HayStack.
Tác nhân vs Bộ định tuyến
Thoạt nhìn, thực sự có rất nhiều điểm tương đồng giữa bộ định tuyến và tác nhân và có thể khó phân biệt chúng khác nhau như thế nào.
Có những điểm tương đồng tồn tại vì trên thực tế, các Tác nhân cũng sẽ thực hiện việc định tuyến như một phần trong quy trình trong ứng dụng cụ thể. Nó sử dụng cơ chế định tuyến để chọn đúng công cụ cần sử dụng cho công việc và thường tận dụng chức năng gọi hàm để chọn đúng công cụ, giống như Bộ định tuyến gọi hàm LLM được mô tả ở trên.
Tuy nhiên, Bộ định tuyến là các thành phần đơn giản hơn nhiều so với Tác nhân, thường có công việc “đơn giản” là chỉ định tuyến một tác vụ đến đúng vị trí, trái ngược với việc thực hiện bất kỳ logic hoặc xử lý nào liên quan đến tác vụ đó.
Mặt khác, các Tác nhân thường chịu trách nhiệm xử lý logic, bao gồm cả việc quản lý công việc được thực hiện bằng các công cụ mà họ có quyền truy cập.
Phần kết luận
Ở đây, trong bài viết này chúng tôi đã đề cập đến một số bộ định tuyến ngôn ngữ tự nhiên khác nhau hiện được tìm thấy bên trong các gói và khung RAG và LLM khác nhau được cung cấp dưới dạn mã nguồn mở.
Các khái niệm, gói và thư viện xung quanh việc định tuyến chắc chắn sẽ gia tăng lên theo thời gian. Khi xây dựng một ứng dụng RAG, bạn sẽ thấy rằng tại một thời điểm nào đó, không xa lắm, khả năng định tuyến trở nên cần thiết để xây dựng một ứng dụng hữu ích cho người dùng.
Bộ định tuyến là các khối xây dựng cơ bản cho phép bạn định tuyến các yêu cầu ngôn ngữ tự nhiên đến ứng dụng của mình đến đúng nơi để các truy vấn của người dùng có thể được đáp ứng tốt nhất có thể.
Trong các ứng dụng cụ thể mà MyGPT triển khai, sẽ có nhiều phương pháp định tuyến khác nhau được sử dụng kết hợp hoặc chúng tôi có thể phát triển thêm những cách thức định tuyến ad-hoc cho từng loại dữ liệu, hoặc mục đích riêng cho từng tổ chức hoặc doanh nghiệp nhằm giải quyết bài toán ứng dụng đồng thời giúp chúng trở nên mềm dẻo hơn theo thực tế.
Đừng quên liên hệ đến MyGPT để trao đổi về trường hợp sử dụng cụ thể của tổ chức mình các bạn nhé!