


Được xuất bản cách đây 7 giây vào ngày 7 tháng 3, 2025
Tác giả: Martin Anderson
Một nghiên cứu gần đây từ LG AI Research cho thấy các bộ dữ liệu được cho là “mở” dùng để huấn luyện mô hình AI có thể đang tạo ra một cảm giác an toàn giả tạo — khi phát hiện ra rằng gần 4 trong số 5 bộ dữ liệu AI được gắn nhãn là “có thể sử dụng cho mục đích thương mại” thực tế lại tiềm ẩn các rủi ro pháp lý ẩn giấu.
Những rủi ro này bao gồm từ việc chứa các tài liệu có bản quyền chưa được tiết lộ đến các điều khoản cấp phép hạn chế được giấu sâu trong các thành phần phụ thuộc của bộ dữ liệu. Nếu những phát hiện trong nghiên cứu này là chính xác, các công ty dựa vào bộ dữ liệu công khai có thể cần phải xem xét lại quy trình AI hiện tại của họ, nếu không sẽ đối mặt với nguy cơ về pháp lý trong tương lai.
Các nhà nghiên cứu đề xuất một giải pháp triệt để và có thể gây tranh cãi: sử dụng các tác nhân tuân thủ dựa trên AI có khả năng quét và kiểm tra lịch sử bộ dữ liệu nhanh chóng và chính xác hơn so với các luật sư con người.
Bài nghiên cứu viết:
“Chúng tôi cho rằng rủi ro pháp lý của các bộ dữ liệu huấn luyện AI không thể chỉ được xác định bằng cách xem xét các điều khoản cấp phép bề mặt; một phân tích toàn diện từ đầu đến cuối về việc phân phối lại bộ dữ liệu là điều cần thiết để đảm bảo tuân thủ.
“Vì loại phân tích này vượt quá khả năng của con người do sự phức tạp và quy mô của nó, các tác nhân AI có thể lấp đầy khoảng trống này bằng cách thực hiện với tốc độ và độ chính xác cao hơn. Nếu không có sự tự động hóa, các rủi ro pháp lý quan trọng sẽ phần lớn không được xem xét, đe dọa sự phát triển AI có đạo đức và việc tuân thủ quy định.
“Chúng tôi kêu gọi cộng đồng nghiên cứu AI nhận thức rằng phân tích pháp lý toàn diện là một yêu cầu cơ bản và cần áp dụng các phương pháp dựa trên AI như một con đường khả thi để đảm bảo tuân thủ bộ dữ liệu ở quy mô lớn.”
Khi kiểm tra 2.852 bộ dữ liệu phổ biến dường như có thể sử dụng cho mục đích thương mại dựa trên giấy phép cá nhân của chúng, hệ thống tự động của các nhà nghiên cứu phát hiện rằng chỉ có 605 bộ (khoảng 21%) thực sự an toàn về mặt pháp lý để thương mại hóa sau khi truy vết tất cả các thành phần và phụ thuộc của chúng.
Bài nghiên cứu mới có tiêu đề “Đừng tin vào giấy phép bạn thấy — Tuân thủ bộ dữ liệu đòi hỏi sự truy vết vòng đời quy mô lớn dựa trên AI” và đến từ tám nhà nghiên cứu của LG AI Research.
Đúng và Sai
Các tác giả nhấn mạnh những thách thức mà các công ty phải đối mặt khi thúc đẩy phát triển AI trong một môi trường pháp lý ngày càng bất ổn — khi tư duy “sử dụng hợp lý” mang tính học thuật trước đây về việc huấn luyện bộ dữ liệu đang dần nhường chỗ cho một bối cảnh phân mảnh, nơi các bảo vệ pháp lý không còn rõ ràng và “bến đỗ an toàn” không còn được đảm bảo.
Như một bài báo gần đây đã chỉ ra, các công ty ngày càng trở nên phòng thủ hơn về nguồn dữ liệu huấn luyện của mình. Tác giả Adam Buick bình luận:
“[Trong khi] OpenAI đã tiết lộ các nguồn dữ liệu chính cho GPT-3, bài báo giới thiệu GPT-4 chỉ tiết lộ rằng dữ liệu dùng để huấn luyện mô hình là sự kết hợp của ‘dữ liệu có sẵn công khai (chẳng hạn như dữ liệu trên internet) và dữ liệu được cấp phép từ các nhà cung cấp bên thứ ba’.
“Động cơ đằng sau sự chuyển hướng khỏi tính minh bạch này chưa được các nhà phát triển AI giải thích cụ thể, nhiều trường hợp thậm chí còn không đưa ra lời giải thích nào.
“Về phần mình, OpenAI biện minh cho quyết định không tiết lộ thêm chi tiết về GPT-4 dựa trên những lo ngại liên quan đến ‘bối cảnh cạnh tranh và những tác động an toàn của các mô hình quy mô lớn’, mà không có giải thích thêm nào trong báo cáo.“
Tính minh bạch có thể là một thuật ngữ không chân thành — hoặc đơn giản là một sự nhầm lẫn; chẳng hạn, mô hình sinh Firefly hàng đầu của Adobe, được huấn luyện trên dữ liệu ảnh có bản quyền mà Adobe có quyền khai thác, được cho là đã mang lại sự đảm bảo cho khách hàng về tính hợp pháp của việc sử dụng hệ thống này. Tuy nhiên, sau đó đã xuất hiện một số bằng chứng cho thấy kho dữ liệu của Firefly đã bị “làm giàu” bằng dữ liệu có thể có bản quyền từ các nền tảng khác.
Như chúng ta đã thảo luận hồi đầu tuần, ngày càng có nhiều sáng kiến được thiết kế để đảm bảo tuân thủ giấy phép trong các bộ dữ liệu, bao gồm một sáng kiến chỉ quét video trên YouTube với giấy phép Creative Commons linh hoạt.
Vấn đề là các giấy phép đó tự bản thân chúng có thể sai sót, hoặc được cấp nhầm, như nghiên cứu mới dường như đã chỉ ra.
Kiểm tra các Bộ Dữ liệu Mã Nguồn Mở
Rất khó để phát triển một hệ thống đánh giá như Nexus của các tác giả khi bối cảnh liên tục thay đổi. Do đó, bài nghiên cứu cho biết rằng hệ thống khung Tuân thủ Dữ liệu NEXUS được xây dựng dựa trên “các tiền lệ và cơ sở pháp lý khác nhau tại thời điểm hiện tại”.
NEXUS sử dụng một tác nhân điều khiển bởi AI có tên là AutoCompliance để tự động hóa việc tuân thủ dữ liệu. AutoCompliance bao gồm ba mô-đun chính:
- Mô-đun điều hướng để khám phá web.
- Mô-đun hỏi đáp (QA) để trích xuất thông tin.
- Mô-đun chấm điểm để đánh giá rủi ro pháp lý.
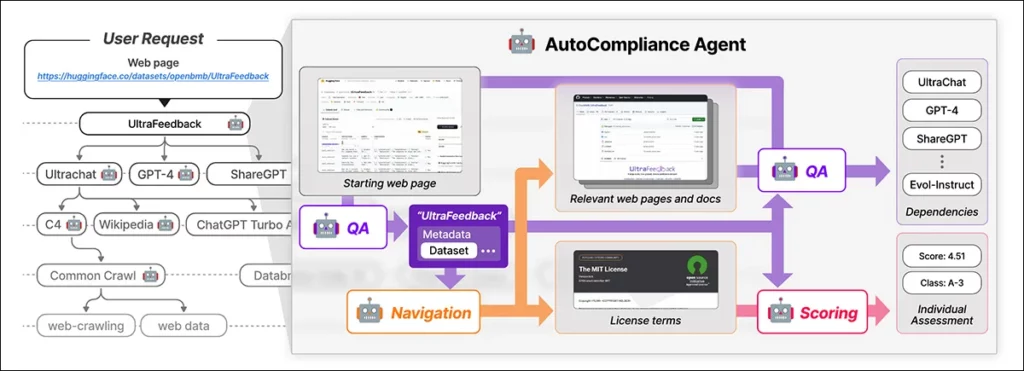
Các mô-đun này được vận hành bởi các mô hình AI đã được tinh chỉnh, bao gồm mô hình EXAONE-3.5-32B-Instruct, được huấn luyện trên dữ liệu tổng hợp và dữ liệu có nhãn của con người. AutoCompliance cũng sử dụng một cơ sở dữ liệu để lưu trữ kết quả tạm thời nhằm nâng cao hiệu suất.
AutoCompliance bắt đầu với URL của bộ dữ liệu do người dùng cung cấp và coi đó là thực thể gốc, tìm kiếm các điều khoản giấy phép và các phụ thuộc của nó, sau đó đệ quy truy vết các bộ dữ liệu liên kết để xây dựng đồ thị phụ thuộc giấy phép. Khi tất cả các kết nối đã được lập bản đồ, nó sẽ tính toán điểm tuân thủ và gán các phân loại rủi ro.
Khung Tuân thủ Dữ liệu được phác thảo trong nghiên cứu mới xác định các loại thực thể khác nhau tham gia vào vòng đời dữ liệu, bao gồm:
- Bộ dữ liệu: Là đầu vào cốt lõi cho việc huấn luyện AI.
- Phần mềm xử lý dữ liệu và mô hình AI: Được sử dụng để chuyển đổi và tận dụng dữ liệu.
- Nhà cung cấp dịch vụ nền tảng (Platform Service Providers): Tạo điều kiện cho việc xử lý dữ liệu.
Hệ thống này đánh giá một cách toàn diện các rủi ro pháp lý bằng cách xem xét các thực thể khác nhau và sự phụ thuộc lẫn nhau của chúng, vượt ra ngoài việc đánh giá máy móc các giấy phép của bộ dữ liệu để bao quát một hệ sinh thái rộng hơn của các thành phần tham gia vào phát triển AI.
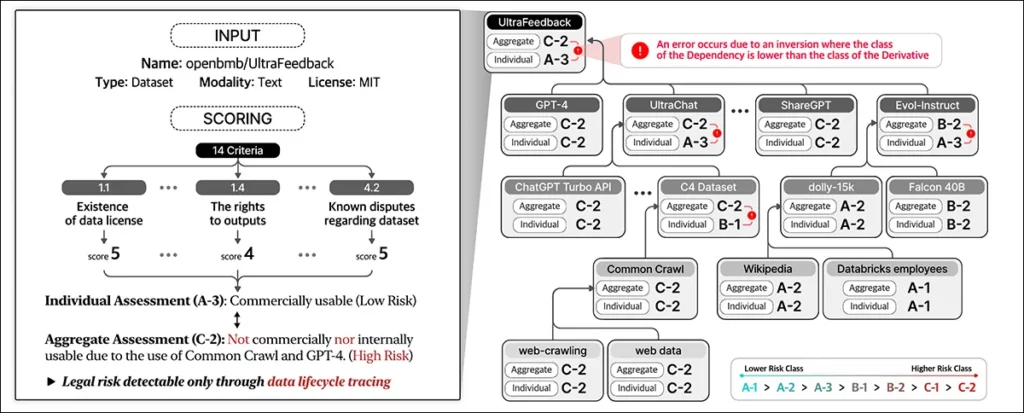
Huấn luyện và Các Chỉ số
Các tác giả đã trích xuất URL của 1.000 bộ dữ liệu được tải xuống nhiều nhất trên Hugging Face, sau đó lấy mẫu ngẫu nhiên 216 mục để tạo thành tập kiểm thử.
Mô hình EXAONE đã được tinh chỉnh trên bộ dữ liệu tùy chỉnh của các tác giả, với:
- Mô-đun điều hướng và mô-đun hỏi đáp sử dụng dữ liệu tổng hợp.
- Mô-đun chấm điểm sử dụng dữ liệu có nhãn của con người.
Nhãn chuẩn được tạo ra bởi năm chuyên gia pháp lý đã được đào tạo ít nhất 31 giờ về các nhiệm vụ tương tự. Những chuyên gia này đã xác định thủ công các phụ thuộc và điều khoản giấy phép cho 216 trường hợp kiểm thử, sau đó tổng hợp và tinh chỉnh kết quả thông qua thảo luận.
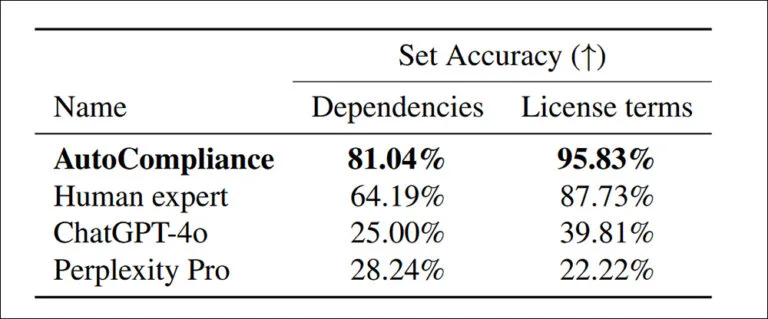
Khi hệ thống AutoCompliance đã được huấn luyện và hiệu chỉnh bởi con người được kiểm thử so với ChatGPT-4o và Perplexity Pro, đáng chú ý là nhiều phụ thuộc hơn đã được phát hiện trong các điều khoản giấy phép:
Bài báo nêu rõ:
“AutoCompliance vượt trội hơn hẳn tất cả các tác nhân khác và cả chuyên gia con người, đạt độ chính xác lần lượt là 81,04% và 95,83% trong từng nhiệm vụ. Ngược lại, cả ChatGPT-4o và Perplexity Pro đều cho thấy độ chính xác tương đối thấp đối với các nhiệm vụ về Nguồn và Giấy phép.”
“Những kết quả này làm nổi bật hiệu suất vượt trội của AutoCompliance, chứng minh hiệu quả của nó trong việc xử lý cả hai nhiệm vụ với độ chính xác đáng kể, đồng thời chỉ ra một khoảng cách hiệu suất lớn giữa các mô hình dựa trên AI và chuyên gia con người trong các lĩnh vực này.”
Về hiệu suất, phương pháp AutoCompliance chỉ mất 53,1 giây để chạy, trong khi chuyên gia con người phải mất 2.418 giây cho các nhiệm vụ tương đương.
Ngoài ra, chi phí để thực hiện đánh giá chỉ là 0,29 USD, so với 207 USD cho các chuyên gia con người. Tuy nhiên, cần lưu ý rằng chi phí này dựa trên việc thuê một node GCP a2-megagpu-16gpu hàng tháng với mức giá 14.225 USD mỗi tháng – điều này cho thấy tính hiệu quả về chi phí này chủ yếu liên quan đến các hoạt động quy mô lớn.
Điều tra Bộ Dữ liệu
Trong phân tích của mình, các nhà nghiên cứu đã chọn 3.612 bộ dữ liệu, bao gồm 3.000 bộ dữ liệu được tải xuống nhiều nhất từ Hugging Face và 612 bộ dữ liệu từ Sáng kiến Nguồn gốc Dữ liệu năm 2023.
Bài báo nêu rõ:
“Bắt đầu từ 3.612 thực thể mục tiêu, chúng tôi đã xác định tổng cộng 17.429 thực thể duy nhất, trong đó có 13.817 thực thể xuất hiện như là các phụ thuộc trực tiếp hoặc gián tiếp của các thực thể mục tiêu.”
“Đối với phân tích thực nghiệm của chúng tôi, chúng tôi coi một thực thể và đồ thị phụ thuộc giấy phép của nó có cấu trúc đơn tầng nếu thực thể đó không có phụ thuộc nào và có cấu trúc đa tầng nếu nó có một hoặc nhiều phụ thuộc.”
“Trong số 3.612 bộ dữ liệu mục tiêu, có 2.086 bộ (57,8%) có cấu trúc đa tầng, trong khi 1.526 bộ (42,2%) còn lại có cấu trúc đơn tầng không có phụ thuộc.”
Các bộ dữ liệu có bản quyền chỉ có thể được phân phối lại khi có thẩm quyền pháp lý, có thể đến từ giấy phép, các ngoại lệ theo luật bản quyền hoặc các điều khoản hợp đồng. Việc phân phối lại trái phép có thể dẫn đến hậu quả pháp lý, bao gồm vi phạm bản quyền hoặc vi phạm hợp đồng. Do đó, việc xác định rõ ràng các trường hợp không tuân thủ là điều cần thiết.
Kết quả Điều tra về Phân phối lại Bộ Dữ liệu Không tuân thủ
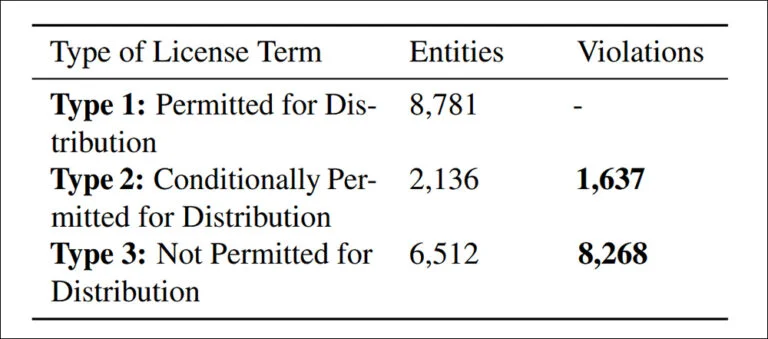
Nghiên cứu đã phát hiện 9.905 trường hợp phân phối lại bộ dữ liệu không tuân thủ, chia thành hai loại chính:
- 83,5%: Bị cấm rõ ràng theo các điều khoản giấy phép, khiến việc phân phối lại trở thành vi phạm pháp lý rõ ràng.
- 16,5%: Liên quan đến các bộ dữ liệu có điều kiện giấy phép xung đột, trong đó việc phân phối lại được cho phép về mặt lý thuyết nhưng không đáp ứng được các điều khoản bắt buộc, tạo ra rủi ro pháp lý về sau.
Hạn chế và Hướng Cải tiến của NEXUS
Các tác giả thừa nhận rằng các tiêu chí rủi ro được đề xuất trong NEXUS không mang tính phổ quát và có thể thay đổi tùy theo khu vực pháp lý và ứng dụng AI cụ thể.
Do đó, họ đề xuất rằng các cải tiến trong tương lai nên tập trung vào:
- Thích ứng với các quy định toàn cầu đang thay đổi.
- Tinh chỉnh quy trình rà soát pháp lý tự động của AI để đảm bảo độ chính xác và tuân thủ.
Kết luận
Bài báo này tuy dài dòng và khó tiếp cận, nhưng đã đề cập đến một trong những rào cản lớn nhất đối với việc ứng dụng AI trong ngành công nghiệp hiện nay — đó là nguy cơ dữ liệu “mở” có thể bị đòi quyền sở hữu sau này bởi các thực thể, cá nhân hoặc tổ chức khác nhau.
Rủi ro Pháp lý Dưới DMCA
Theo Đạo luật DMCA, các vi phạm có thể dẫn đến mức phạt khổng lồ tính trên từng trường hợp. Khi các vi phạm có thể lên tới hàng triệu USD như trong các trường hợp được nhóm nghiên cứu phát hiện, trách nhiệm pháp lý tiềm ẩn là vô cùng đáng kể.
Trách nhiệm của Doanh nghiệp
Các công ty được chứng minh là đã hưởng lợi từ dữ liệu không hợp lệ không thể viện dẫn lý do không biết để tránh trách nhiệm pháp lý, đặc biệt là ở thị trường Mỹ.
- Hiện tại, các doanh nghiệp cũng thiếu công cụ thực tế để có thể giải mã những điều khoản phức tạp trong các giấy phép dữ liệu mã nguồn mở.
Thách thức trong Việc Xây dựng Hệ thống NEXUS Toàn cầu
Việc xây dựng một hệ thống như NEXUS đã đủ thách thức khi phải tùy chỉnh theo từng bang ở Mỹ hoặc theo từng quốc gia trong EU.
- Khả năng xây dựng một khung pháp lý toàn cầu (giống như một dạng Interpol cho nguồn gốc dữ liệu) gặp khó khăn không chỉ bởi các động cơ mâu thuẫn giữa các chính phủ, mà còn bởi thực tế là các quy định và luật pháp liên quan đang không ngừng thay đổi.
→ Nhìn chung, bài báo đã làm nổi bật các thách thức và rủi ro pháp lý quan trọng liên quan đến dữ liệu đào tạo AI, đồng thời nhấn mạnh sự cần thiết của một hệ thống kiểm duyệt và tuân thủ pháp lý tự động hiệu quả như NEXUS.