

Tác giả: Aayush Mittal
Ngày 11 tháng 12 năm 2023
Sundar Pichai, Giám đốc điều hành của Google, cùng với Demis Hassabis từ Google DeepMind, đã giới thiệu Gemini vào tháng 12 năm 2023. Mô hình ngôn ngữ lớn mới này được tích hợp trên toàn bộ danh mục sản phẩm đồ sộ của Google, mang lại những cải tiến lan tỏa qua các dịch vụ và công cụ được hàng triệu người sử dụng.
Gemini, trí tuệ nhân tạo đa phương tiện tiên tiến của Google, ra đời từ những nỗ lực hợp tác của các phòng thí nghiệm thống nhất DeepMind và Brain AI. Gemini đứng trên vai những người tiền nhiệm của mình, hứa hẹn mang đến một bộ ứng dụng kết nối và thông minh hơn.
Việc công bố Google Gemini, ngay sau sự ra mắt của Bard, Duet AI và PaLM 2 LLM, là một tuyên bố rõ ràng từ Google không chỉ để cạnh tranh mà còn để dẫn đầu trong cuộc cách mạng trí tuệ nhân tạo.
Ngược lại với bất kỳ khái niệm nào về một mùa đông của trí tuệ nhân tạo, việc ra mắt Gemini cho thấy một mùa xuân trí tuệ nhân tạo đang phát triển mạnh mẽ, đầy tiềm năng và tăng trưởng. Khi chúng ta nhìn lại một năm kể từ sự xuất hiện của ChatGPT, chính điều này đã là một bước tiến đột phá cho trí tuệ nhân tạo, và hành động của Google cho thấy rằng sự mở rộng của ngành này chưa chắc đã kết thúc; thực tế, nó có thể chỉ là bắt đầu.
Gemini là gì?
Mô hình Gemini của Google có khả năng xử lý nhiều loại dữ liệu khác nhau như văn bản, hình ảnh, âm thanh và video. Nó có ba phiên bản – Ultra, Pro và Nano – mỗi phiên bản được tinh chỉnh cho các ứng dụng cụ thể, từ tư duy phức tạp đến việc sử dụng trên thiết bị. Ultra xuất sắc trong các nhiệm vụ đa chiều và sẽ có sẵn trên Bard Advanced, trong khi Pro cung cấp sự cân bằng giữa hiệu suất và hiệu quả tài nguyên, đã được tích hợp vào Bard cho các lời nhắc văn bản. Nano, được tối ưu hóa cho triển khai trên thiết bị, có hai kích thước và tính năng tối ưu hóa phần cứng như 4-bit quantization để sử dụng offline trên các thiết bị như Pixel 8 Pro.
Kiến trúc của Gemini là độc đáo trong khả năng đầu ra đa phương tiện tự nhiên của nó, sử dụng các mã thông báo hình ảnh rời rạc để tạo hình ảnh và tích hợp các tính năng âm thanh từ Mô hình Nói chung để hiểu âm thanh tinh tế. Khả năng của nó để xử lý dữ liệu video dưới dạng hình ảnh liên tiếp, xen kẽ với đầu vào văn bản hoặc âm thanh, là một minh chứng cho khả năng đa phương tiện của nó.
Truy cập Gemini
Gemini 1.0 đang được triển khai trên toàn bộ hệ sinh thái của Google, bao gồm cả Bard, hiện đang hưởng lợi từ những khả năng được tinh chỉnh của Gemini Pro. Google cũng đã tích hợp Gemini vào các dịch vụ Tìm kiếm, Quảng cáo và Duet của mình, nâng cao trải nghiệm người dùng với phản hồi nhanh hơn và chính xác hơn.
Đối với những người muốn tận dụng khả năng của Gemini, Google AI Studio và Google Cloud Vertex cung cấp quyền truy cập vào Gemini Pro, với Vertex cung cấp các tính năng tùy chỉnh và bảo mật lớn hơn.
Để trải nghiệm những khả năng nâng cao của Bard được động viên bởi Gemini Pro, người dùng có thể thực hiện các bước đơn giản sau:
- Điều hướng đến Bard: Mở trình duyệt web ưa thích của bạn và truy cập trang web Bard.
- Đăng nhập An toàn: Truy cập dịch vụ bằng cách đăng nhập bằng tài khoản Google của bạn, đảm bảo trải nghiệm mượt mà và an toàn.
- Trò chuyện Tương tác: Bây giờ bạn có thể sử dụng Bard, nơi có thể chọn các tính năng tiên tiến của Gemini Pro.
Sức Mạnh của Đa Phương Tiện:
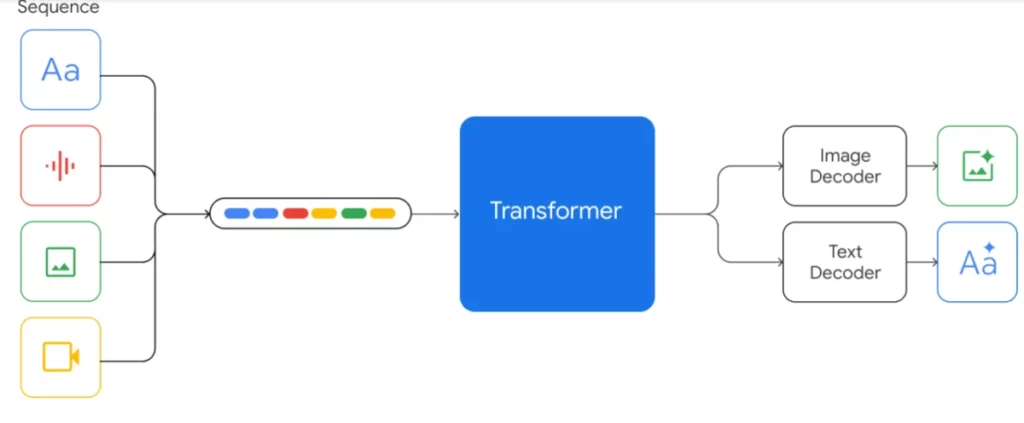
Ở cơ bản, Gemini sử dụng một kiến trúc dựa trên transformer, tương tự như những mô hình NLP thành công như GPT-3. Tuy nhiên, sự độc đáo của Gemini nằm ở khả năng xử lý và tích hợp thông tin từ nhiều dạng, bao gồm văn bản, hình ảnh và mã code. Điều này được đạt được thông qua một kỹ thuật mới gọi là chú ý chéo (cross-modal attention), cho phép mô hình học các mối quan hệ và phụ thuộc giữa các loại dữ liệu khác nhau.
Dưới đây là phân tích chi tiết về các thành phần chính của Gemini:
- Bộ mã hóa Đa Phương Tiện: Mô-đun này xử lý dữ liệu đầu vào từ mỗi dạng (ví dụ: văn bản, hình ảnh) một cách độc lập, trích xuất các đặc điểm liên quan và tạo ra các biểu diễn cá nhân.
- Mạng Chú Ý Chéo Đa Phương Tiện: Mạng này là trái tim của Gemini. Nó cho phép mô hình học các mối quan hệ và phụ thuộc giữa các biểu diễn khác nhau, giúp chúng “nói chuyện” với nhau và làm giàu hiểu biết của chúng.
- Bộ giải mã Đa Phương Tiện: Mô-đun này sử dụng các biểu diễn được làm giàu bởi mạng chú ý chéo để thực hiện các nhiệm vụ khác nhau, chẳng hạn như viết chú thích hình ảnh, tạo hình ảnh từ văn bản và tạo mã code.
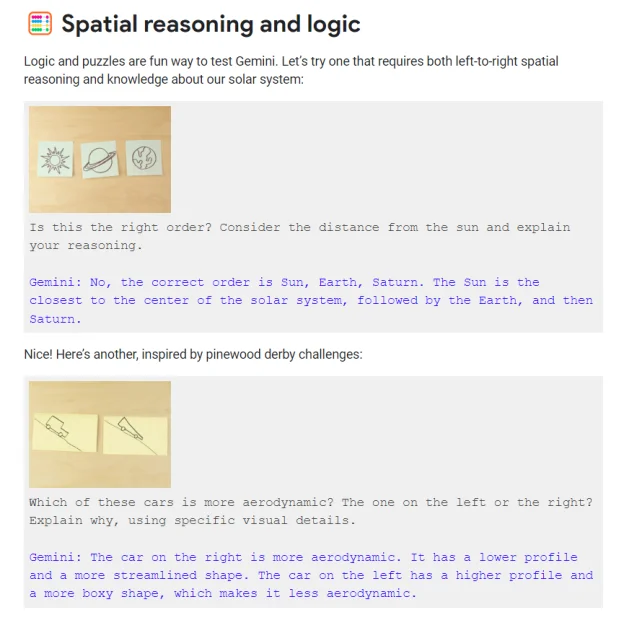
Mô hình Gemini không chỉ là về việc hiểu văn bản hoặc hình ảnh – nó là về việc tích hợp các loại thông tin khác nhau một cách gần gũi hơn với cách chúng ta, như con người, nhìn nhận thế giới. Ví dụ, Gemini có thể nhìn vào một chuỗi hình ảnh và xác định thứ tự logic hoặc không gian của các đối tượng bên trong chúng. Nó cũng có thể phân tích các đặc điểm thiết kế của đối tượng để đưa ra những đánh giá, chẳng hạn như chiếc ô tô nào có hình dạng động học hơn trong hai chiếc.
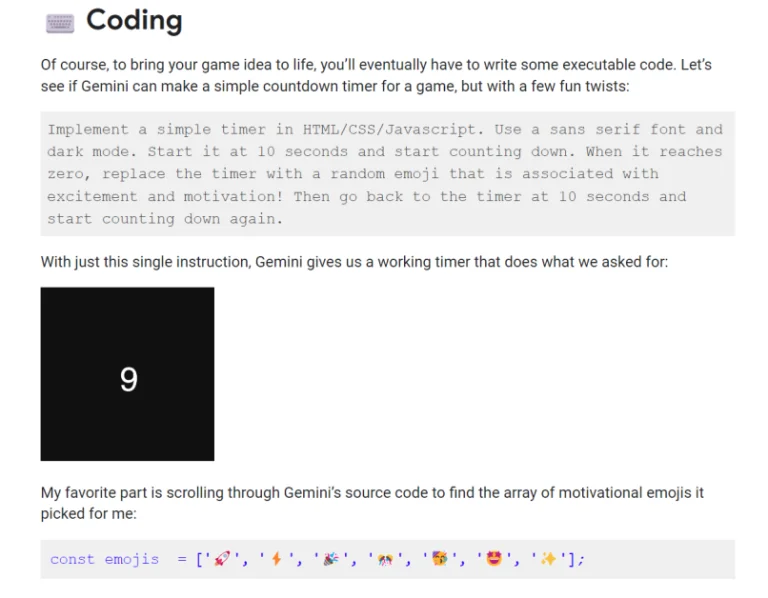
Nhưng tài năng của Gemini không chỉ giới hạn ở việc hiểu hình ảnh. Nó có thể chuyển đổi một bộ hướng dẫn thành mã code, tạo ra các công cụ thực tế như một bộ đếm thời gian đảm bảo không chỉ hoạt động theo hướng dẫn mà còn bao gồm các yếu tố sáng tạo, chẳng hạn như biểu tượng cảm hứng, để tăng cường tương tác người dùng. Điều này chỉ ra khả năng xử lý các nhiệm vụ đòi hỏi sự kết hợp giữa sự sáng tạo và chức năng – những kỹ năng thường được coi là đặc trưng của con người.
Thiết kế phức tạp của Gemini dựa trên một lịch sử phong phú về nghiên cứu mạng nơ-ron và tận dụng công nghệ TPU tiên tiến của Google để huấn luyện. Đặc biệt, Gemini Ultra đã đặt ra các tiêu chuẩn mới trong nhiều lĩnh vực trí tuệ nhân tạo, thể hiện hiệu suất đáng kể trong các nhiệm vụ tư duy đa phương tiện.
Với khả năng phân tích và hiểu dữ liệu phức tạp, Gemini cung cấp giải pháp cho các ứng dụng thực tế, đặc biệt là trong lĩnh vực giáo dục. Nó có thể phân tích và sửa lỗi các giải pháp cho vấn đề, như trong vật lý, thông qua việc hiểu các ghi chú viết tay và cung cấp định dạng toán học chính xác. Những khả năng này gợi ý về một tương lai trong đó trí tuệ nhân tạo hỗ trợ trong môi trường giáo dục, mang lại cho sinh viên và giáo viên các công cụ tiên tiến để học và giải quyết vấn đề.
Gemini đã được sử dụng để tạo ra các tác nhân như AlphaCode 2, nổi bật trong việc giải quyết các vấn đề lập trình cạnh tranh. Điều này thể hiện tiềm năng của Gemini làm một trí tuệ nhân tạo tổng quát, có khả năng xử lý các vấn đề phức tạp và đa bước.
Gemini Nano mang lại sức mạnh của trí tuệ nhân tạo đến các thiết bị hàng ngày, duy trì khả năng ấn tượng trong các nhiệm vụ như tóm tắt và hiểu đọc, cũng như các thách thức liên quan đến lập trình và STEM. Những mô hình nhỏ hơn này được điều chỉnh để cung cấp các chức năng trí tuệ nhân tạo chất lượng cao trên các thiết bị có bộ nhớ thấp, khiến cho trí tuệ nhân tạo tiên tiến trở nên dễ tiếp cận hơn bao giờ hết.
Việc phát triển của Gemini đã liên quan đến các đổi mới trong thuật toán và cơ sở hạ tầng đào tạo, sử dụng TPU mới nhất của Google. Điều này cho phép quy mô hiệu quả và quy trình đào tạo mạnh mẽ, đảm bảo rằng ngay cả những mô hình nhỏ nhất cũng mang lại hiệu suất xuất sắc.
Bộ dữ liệu đào tạo cho Gemini đa dạng như khả năng của nó, bao gồm tài liệu web, sách, mã code, hình ảnh, âm thanh và video. Bộ dữ liệu đa phương tiện và đa ngôn ngữ này đảm bảo rằng các mô hình Gemini có thể hiểu và xử lý hiệu quả nhiều loại nội dung khác nhau.
Gemini và GPT-4
Mặc dù có sự xuất hiện của các mô hình khác, câu hỏi trên tâm trí của mọi người là làm thế nào mô hình Gemini của Google so sánh với GPT-4 của OpenAI, làm chuẩn mới cho các Mô hình Ngôn ngữ Lớn. Dữ liệu của Google cho thấy trong khi GPT-4 có thể xuất sắc trong các nhiệm vụ tư duy phổ quát, Gemini Ultra có ưu thế ở gần như mọi lĩnh vực khác.
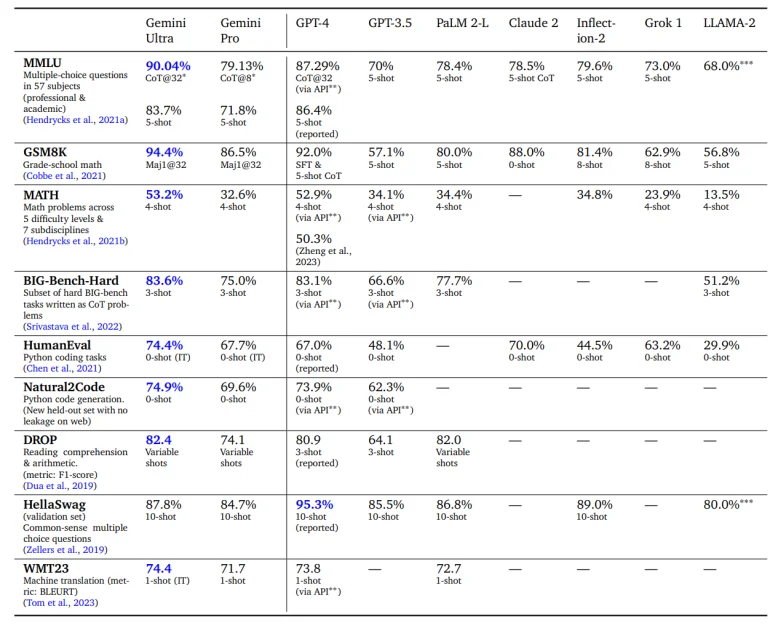
Bảng so sánh trên thể hiện hiệu suất ấn tượng của Google’s Gemini AI trong nhiều nhiệm vụ khác nhau. Đáng chú ý, Gemini Ultra đã đạt được kết quả đáng kinh ngạc trong bài kiểm tra MMLU với độ chính xác 90,04%, chứng tỏ sự hiểu biết vượt trội trong các câu hỏi lựa chọn nhiều trong 57 chủ đề.
Trong bài kiểm tra GSM8K, đánh giá câu hỏi toán cấp tiểu học, Gemini Ultra đạt điểm 94,4%, thể hiện khả năng xử lý toán học tiên tiến của nó. Trong các bài kiểm tra lập trình, với Gemini Ultra đạt điểm 74,4% trong HumanEval cho việc tạo mã Python, chứng tỏ sự hiểu biết mạnh mẽ về ngôn ngữ lập trình.
Bài kiểm tra DROP, kiểm tra hiểu đọc, lại thấy Gemini Ultra dẫn đầu với điểm số 82,4%. Trong khi đó, trong một bài kiểm tra tư duy thông hiểu thông thường, HellaSwag, Gemini Ultra thực hiện một cách xuất sắc, mặc dù không vượt qua chuẩn rất cao được đặt ra bởi GPT-4.
Kết luận
Kiến trúc độc đáo của Gemini, được nâng cấp bởi công nghệ tiên tiến của Google, đặt nó làm một đối thủ đáng kể trong lĩnh vực trí tuệ nhân tạo, đặt ra thách thức cho các tiêu chuẩn hiện tại được đặt ra bởi các mô hình như GPT-4. Các phiên bản của nó – Ultra, Pro và Nano – mỗi cái đều phục vụ các nhu cầu cụ thể, từ các nhiệm vụ tư duy phức tạp đến ứng dụng hiệu quả trên thiết bị, thể hiện cam kết của Google đối với việc làm cho trí tuệ nhân tạo tiên tiến trở nên dễ tiếp cận trên nhiều nền tảng và thiết bị khác nhau.
Việc tích hợp Gemini vào hệ sinh thái của Google, từ Bard đến Google Cloud Vertex, làm nổi bật tiềm năng của nó để cải thiện trải nghiệm người dùng trên nhiều dịch vụ. Nó không chỉ hứa hẹn làm tinh tế các ứng dụng hiện tại mà còn mở ra những cơ hội mới cho các giải pháp được thúc đẩy bởi trí tuệ nhân tạo, có thể là trong việc hỗ trợ cá nhân, sáng tạo hoạt động, hoặc phân tích kinh doanh.
Khi nhìn về phía trước, sự tiến bộ liên tục trong các mô hình trí tuệ nhân tạo như Gemini làm nổi bật tầm quan trọng của nghiên cứu và phát triển liên tục. Những thách thức của việc đào tạo các mô hình phức tạp như vậy và đảm bảo sử dụng chúng một cách đạo đức và có trách nhiệm vẫn nằm ở tâm điểm của cuộc thảo luận.