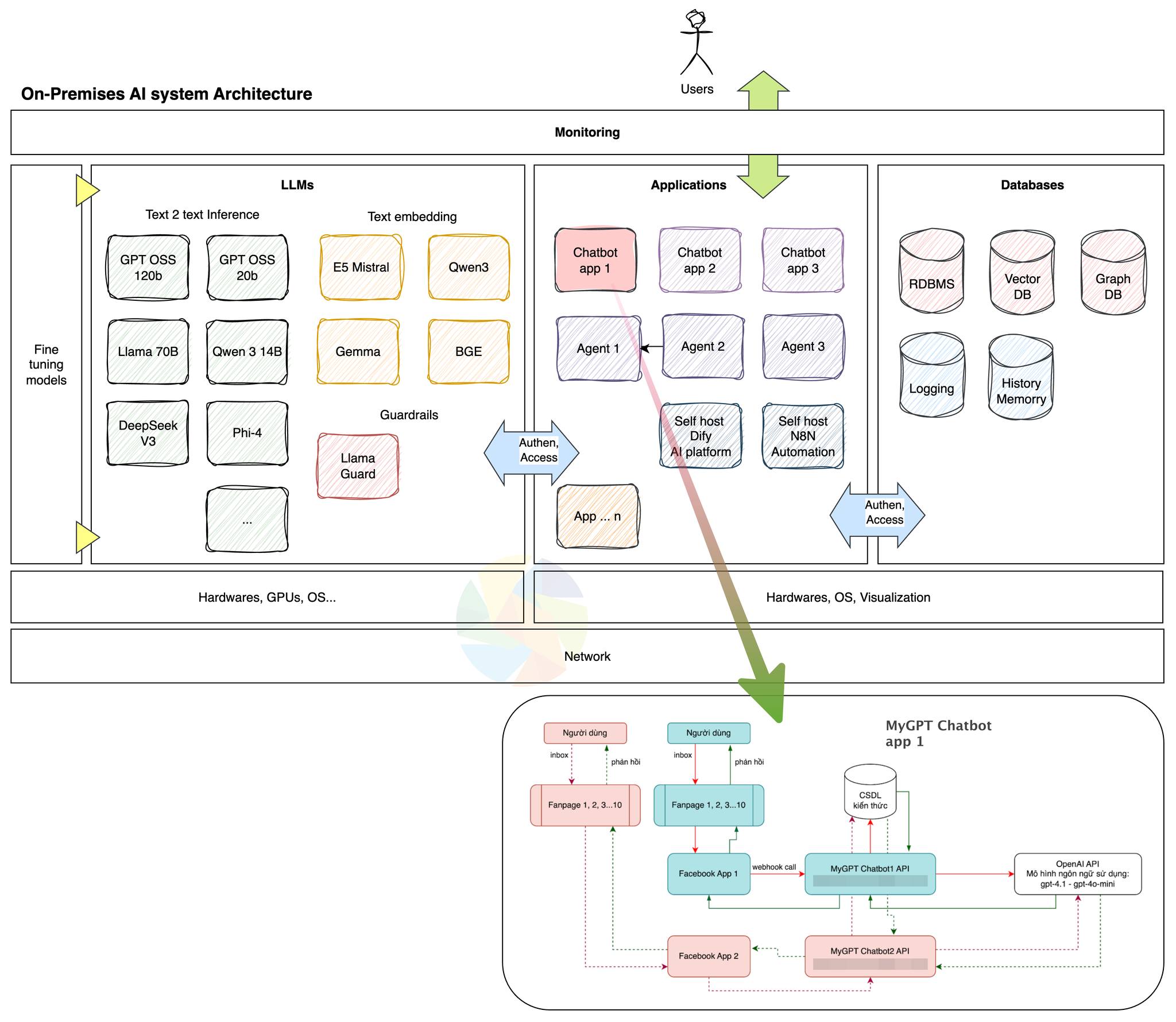
Mô hình ngôn ngữ lớn: GPT-OSS, Llama, Phi, Mistral, Gemma, Qwen, DeepSeek và nhiều mô hình nguồn mở khác.
Độ lớn mô hình lựa chọn: từ 2 tỉ tham số đến 405 tỉ tham số hoặc cao hơn tuỳ thuộc vào nhiệm vụ của từng ứng dụng riêng biệt và hạ tầng có thể đầu tư
Ứng dụng: Phân tích/Kiểm soát dữ liệu nội bộ; Tạo sinh text phản hồi trong các ứng dụng AI; AI Agents, Data pipeline; Tạo Embeddings; Tạo ảnh; Nhận dạng ảnh; Chatbot chăm sóc khách hàng…
Phạm vi hoạt động: 100% trên hệ thống máy chủ riêng rẽ, không kết nối ra ngoài Internet
Ước tính yêu cầu phần cứng cho LLM
Tuỳ thuộc vào mô hình ngôn ngữ lớn, phạm vi và nhiệm vụ cần thực hiện, hệ thống phần cứng cần được trang bị GPU với thông tin tham khảo dưới đây sử dụng cho máy chạy production với mô hình LLama 3.3 70B:
Phần cứng
Cấu hình đề xuất
CPU
2 x 48 Cores
RAM
256GB
SSD
2 x 1.92TB
GPU
2 x Nvidia A100 80GB
Output non quatization
~20-25 tokens/giây
CCU
~8-12 người dùng đồng thời
Latency
~200ms-400ms per token
Giá dự kiến cả VAT
2.700.000.000đ/server
– Cấu hình trên được chúng tôi kiểm nghiệm ở chế độ production khi vận hành inference cho mô hình ngôn ngữ Llama 3.3 70B Instruct cho kết quả phản hồi tạm đủ cho việc triển khai ứng dụng Chat. Với những hệ thống có yêu cầu lượng người Chat đồng thời cao hoặc sử dụng mô hình nhiều tham số hơn thì cần phải cân nhắc nâng thêm số lượng GPU với VRAM và RAM lên tối thiểu lớn hơn 30% so với tham số mô hình.
– Trong một số nhiệm vụ khác có thể sử dụng mô hình nhỏ hơn hoặc thực hiện quantization để giảm sử dụng VRAM của GPU tuy nhiên việc quantization sẽ phức tạp và mất nhiều thời gian vì có thể thay đổi chất lượng output của mô hình.
Ưu điểm
Có thể triển khai các mô hình phù hợp theo nhiệm vụ của ứng dụng.
Hoạt động hoàn toàn trên hệ thống riêng, đảm bảo an toàn và bảo mật dữ liệu của tổ chức đạt mức độ cao nhất
Kiểm soát hoàn toàn dữ liệu và ứng dụng phục vụ nhu cầu sử dụng và phát triển riêng