

Các mô hình ngôn ngữ lớn (LLM) đã gây bão trên Internet vào cuối năm 2022 sau khi ChatGPT do OpenAI phát triển đã đạt 1 triệu người dùng chỉ 5 ngày sau khi ra mắt. Khả năng và ứng dụng rộng rãi của ChatGPT đã được công nhận với 175 tỷ tham số mà mô hình ngôn ngữ GPT-3, GPT-4 có được.
Mặc dù việc sử dụng các mô hình ngôn ngữ qua các sản phẩm cuối như ChatGPT rất dễ dàng, nhưng việc phát triển một mô hình ngôn ngữ lớn cần có kiến thức, thời gian và nguồn lực đáng kể về khoa học máy tính. Chúng tôi giới thiệu bài viết này để cung cấp một số hiểu biết chung về:
- Định nghĩa mô hình ngôn ngữ lớn
- Ví dụ về các mô hình ngôn ngữ lớn
- Kiến trúc của các mô hình ngôn ngữ lớn
- Quá trình huấn luyện các mô hình ngôn ngữ lớn,
Và cách để có thể tận dụng trí tuệ nhân tạo và học máy một cách hiệu quả.
Mô hình ngôn ngữ lớn là gì?
Mô hình ngôn ngữ lớn là một loại mô hình học máy được đào tạo trên một kho dữ liệu văn bản lớn để tạo đầu ra cho các tác vụ xử lý ngôn ngữ tự nhiên (NLP) khác nhau, chẳng hạn như tạo văn bản, trả lời câu hỏi và dịch máy.
Các mô hình ngôn ngữ lớn thường dựa trên các mạng thần kinh học sâu như kiến trúc Transformer và được đào tạo trên lượng dữ liệu văn bản khổng lồ, thường liên quan đến hàng tỷ từ. Các mô hình lớn hơn, chẳng hạn như mô hình BERT của Google, được đào tạo bằng tập dữ liệu lớn từ nhiều nguồn dữ liệu khác nhau, cho phép chúng tạo đầu ra cho nhiều tác vụ.
Một số mô hình ngôn ngữ lớn hàng đầu theo kích thước tham số
Chúng tôi đã tổng hợp 7 mô hình ngôn ngữ lớn nhất theo kích thước tham số trong bảng bên dưới:
| Mô hình | Nhà phát triển | Kích thước tham số |
|---|---|---|
| WuDao 2.0 | Học viện trí tuệ nhân tạo Bắc Kinh | 1,75 nghìn tỷ |
| MT-NLG | Nvidia và Microsoft | 530 tỷ |
| Bloom | HuggingFace và BigScience | 176 tỷ |
| GPT-3 | OpenAI | 175 tỷ |
| LaMDA | 137 tỷ | |
| ESMFold | Siêu AI | 15 tỷ |
| Gato | DeepMind | 1,18 tỷ |
Hiện tại đã có thêm nhiều mô hình với lượng tham số lớn được ứng dụng rộng rãi như GPT-4; Llama; Claude…
Kiến trúc của các mô hình ngôn ngữ lớn
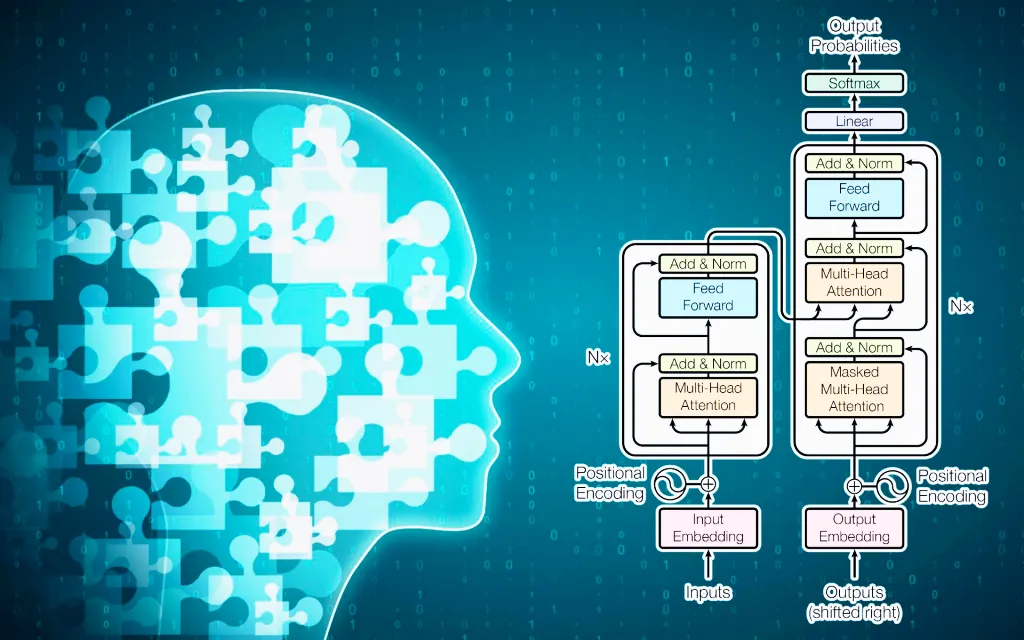
Kiến trúc của các mô hình ngôn ngữ lớn, chẳng hạn như GPT-3 của OpenAI, dựa trên một loại hình học sâu được gọi là kiến trúc Transformer. Nó bao gồm các thành phần chính sau (xem Hình 1):
1. Input embedding
Chuỗi đầu vào trước tiên được chuyển đổi thành biểu diễn vectơ dày đặc, được gọi là nhúng, nắm bắt mối quan hệ giữa các từ trong đầu vào.
2. Multi-head self-attention
Thành phần cốt lõi của kiến trúc khối máy biến áp là cơ chế tự chú ý nhiều đầu, cho phép mô hình chú ý đến các phần khác nhau của chuỗi đầu vào để nắm bắt các mối quan hệ và sự phụ thuộc của nó.
3. Feed-forward network
Sau cơ chế tự chú ý, đầu ra được đưa vào mạng thần kinh chuyển tiếp nguồn cấp dữ liệu, thực hiện chuyển đổi phi tuyến tính để tạo ra một biểu diễn mới.
4. Normalization and residual connections
Để ổn định quá trình đào tạo, đầu ra từ mỗi lớp được chuẩn hóa và kết nối dư được thêm vào để cho phép đầu vào được chuyển trực tiếp đến đầu ra, cho phép mô hình tìm hiểu phần nào của đầu vào là quan trọng nhất.
Các thành phần này được lặp lại nhiều lần để tạo thành một mạng lưới thần kinh sâu, có thể xử lý các chuỗi văn bản dài và tạo ra kết quả đầu ra chất lượng cao cho các tác vụ ngôn ngữ khác nhau, chẳng hạn như tạo văn bản, trả lời câu hỏi và dịch thuật.
Các nhà phát triển tiếp tục phát triển các mô hình ngôn ngữ lớn bằng cách triển khai các kỹ thuật mới để:
- Đơn giản hóa mô hình (giảm kích thước mô hình hoặc bộ nhớ cần thiết để huấn luyện),
- Cải thiện hiệu quả làm việc,
- Giá thấp hơn,
- Giảm thời gian đào tạo mô hình.
Đào tạo mô hình ngôn ngữ lớn
Có bốn bước để đào tạo các mô hình ngôn ngữ lớn:
1. Thu thập và tiền xử lý dữ liệu
Bước đầu tiên là thu thập tập dữ liệu huấn luyện, đây là tài nguyên mà LLM sẽ được đào tạo. Dữ liệu có thể đến từ nhiều nguồn khác nhau như sách, trang web, bài báo và bộ dữ liệu mở.
Các nguồn công khai phổ biến để tìm tập dữ liệu là:
- Kaggle
- Google Dataset Search
- Hugging Face
- Data.gov
- Wikipedia database
- Các báo online lớn
Dữ liệu sau đó cần phải được làm sạch và chuẩn bị cho việc đào tạo. Điều này có thể liên quan đến việc chuyển đổi tập dữ liệu thành chữ thường, xóa các từ dừng và mã hóa văn bản thành chuỗi mã thông báo tạo nên văn bản.
2. Lựa chọn và cấu hình model
Các mô hình lớn như BERT của Google và GPT-3 của OpenAI đều sử dụng kiến trúc deep learning transformer, đây là lựa chọn phổ biến cho các ứng dụng NLP phức tạp trong những năm gần đây. Một số yếu tố chính của mô hình như:
- Số lớp trong khối transformer
- Số các head cần chú ý
- Loss function
- Siêu tham số
cần phải được chỉ định khi cấu hình mạng nơ-ron biến áp. Cấu hình có thể phụ thuộc vào trường hợp sử dụng mong muốn và dữ liệu huấn luyện. Cấu hình của mô hình ảnh hưởng trực tiếp đến thời gian huấn luyện của mô hình.
3. Đào tạo mô hình
Mô hình được huấn luyện trên dữ liệu văn bản được xử lý trước bằng phương pháp học có giám sát. Trong quá trình huấn luyện, mô hình được trình bày một chuỗi các từ và được huấn luyện để dự đoán từ tiếp theo trong chuỗi đó. Mô hình điều chỉnh trọng số của nó dựa trên sự khác biệt giữa dự đoán của nó và từ thực tế tiếp theo. Quá trình này được lặp lại hàng triệu lần cho đến khi mô hình đạt được mức hiệu suất thỏa đáng.
Vì các mô hình và dữ liệu có kích thước lớn nên đòi hỏi khả năng tính toán rất lớn để đào tạo các mô hình. Để giảm thời gian đào tạo, một kỹ thuật gọi là song song mô hình được sử dụng. Tính song song của mô hình cho phép các phần khác nhau của một mô hình lớn được trải rộng trên nhiều GPU, cho phép mô hình được đào tạo theo cách phân tán với chip AI.
Bằng cách chia mô hình thành các phần nhỏ hơn, mỗi phần có thể được đào tạo song song, dẫn đến quá trình đào tạo nhanh hơn so với việc đào tạo toàn bộ mô hình trên một GPU hoặc bộ xử lý duy nhất. Điều này dẫn đến khả năng hội tụ nhanh hơn và hiệu suất tổng thể tốt hơn, giúp có thể đào tạo các mô hình ngôn ngữ lớn hơn trước đây. Các loại mô hình song song phổ biến bao gồm:
- Data parallelism
- Sequence parallelism
- Pipeline parallelism
- Tensor parallelism
Việc đào tạo một mô hình ngôn ngữ lớn ngay từ đầu đòi hỏi phải đầu tư đáng kể, một giải pháp thay thế kinh tế hơn là tinh chỉnh mô hình ngôn ngữ hiện có để điều chỉnh nó cho phù hợp với trường hợp sử dụng cụ thể của bạn. Một đợt huấn luyện duy nhất cho GPT-3 ước tính tiêu tốn khoảng 5 triệu USD.
4. Đánh giá và tinh chỉnh
Sau khi đào tạo, mô hình được đánh giá trên tập dữ liệu thử nghiệm chưa được sử dụng làm tập dữ liệu huấn luyện để đo lường hiệu suất của mô hình. Dựa trên kết quả đánh giá, mô hình có thể yêu cầu một số tinh chỉnh bằng cách điều chỉnh các siêu tham số, thay đổi kiến trúc hoặc đào tạo về dữ liệu bổ sung để cải thiện hiệu suất của nó.
Đào tạo LLM cho các trường hợp sử dụng cụ thể
Đào tạo LLM bao gồm hai phần: đào tạo trước và đào tạo theo nhiệm vụ cụ thể. Đào tạo trước là một phần của quá trình đào tạo cho phép mô hình tìm hiểu các quy tắc chung và các phần phụ thuộc trong một ngôn ngữ, việc này cần một lượng dữ liệu đáng kể, sức mạnh tính toán và thời gian để hoàn thành. Các mô hình ngôn ngữ lớn được thảo luận trong bài viết yêu cầu hệ thống siêu máy tính với một số chip AI (ví dụ: NVIDIA DGX A100 có giá khởi điểm là 199.999 USD). Sau khi cộng thêm chi phí bảo trì và điện năng, việc đào tạo trước một mô hình ngôn ngữ lớn là một khoản đầu tư trị giá hàng triệu USD.
Để làm cho các mô hình ngôn ngữ lớn trở nên dễ tiếp cận hơn đối với các doanh nghiệp, các nhà phát triển LLM đang cung cấp dịch vụ cho các doanh nghiệp đang tìm cách tận dụng các mô hình ngôn ngữ. NeMO của NVIDIA là một ví dụ về các dịch vụ này, cung cấp LLM được đào tạo trước để tinh chỉnh và đào tạo nhiệm vụ cụ thể cho phù hợp với các trường hợp sử dụng cụ thể. Quá trình đào tạo nhiệm vụ cụ thể sẽ bổ sung thêm một lớp vào mô hình đòi hỏi ít dữ liệu, năng lượng và thời gian đào tạo hơn nhiều; làm cho các mô hình lớn có thể truy cập được để sử dụng trong doanh nghiệp. Lớp dành riêng cho nhiệm vụ mới được đào tạo bằng phương pháp học vài lần, nhằm mục đích tạo ra kết quả đầu ra chính xác với ít dữ liệu đào tạo hơn.
Vì mô hình đã được đào tạo trước và quen thuộc với ngôn ngữ nên học vài lần là một phương pháp khả thi để dạy các từ và cụm từ theo miền cụ thể cho mô hình.
Nếu bạn có thêm câu hỏi về các mô hình ngôn ngữ lớn, hãy liên hệ với myGPT. Chúng tôi rất sẵn lòng để trả lời câu hỏi của bạn. Chúng tôi hiện đang cung cấp dịch vụ huấn luyện bổ sung hoặc triển khai các mô hình riêng theo nhu cầu của doanh nghiệp với dữ liệu riêng của các bạn tại Việt Nam.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, AN, Kaiser, L., & Polosukhin, I. (2017). Sự chú ý là tất cả những gì bạn cần. Hệ thống xử lý thông tin thần kinh, 30, 5998-6008.