


Đừng bỏ cuộc sự nghiệp lập trình của bạn. Các nghiên cứu đã chỉ ra rằng trí tuệ nhân tạo tạo ra mã chỉ được một phần, và thất bại thảm hại trước các vấn đề khó khăn.
Tác giả: Tiernan Ray
ngày 28 tháng 9 năm 2023
Những ngày đầu thú vị của việc OpenAI phát hành ChatGPT cho công chúng vào mùa đông năm ngoái đã đem lại bằng chứng về khả năng của chương trình trong việc tạo ra mã máy tính, điều này thực sự là một điều kỳ diệu đối với các nhà phát triển. Ban đầu có vẻ như ChatGPT rất giỏi trong việc viết mã, thậm chí đến mức mà ngay cả những người có kiến thức lập trình ít ỏi cũng có thể sử dụng nó để tạo ra phần mềm mạnh mẽ, mạnh đến mức có thể sử dụng như phần mềm độc hại để đe dọa mạng máy tính.
Nhiều tháng kinh nghiệm và nghiên cứu chính thức về vấn đề này đã cho thấy rằng ChatGPT và các trí tuệ nhân tạo tạo ra mã khác không thể phát triển chương trình thực sự. Điều tốt nhất mà họ có thể làm là đưa ra những bước đi đầu tiên, chủ yếu cho các vấn đề lập trình đơn giản, có thể hoặc không có ích cho các lập trình viên con người.
“Naveen Rao, đồng sáng lập và CEO của công ty khởi nghiệp trí tuệ nhân tạo MosaicML, mà sau đó đã được Databricks mua lại vào tháng 8, nói: ‘Những gì trí tuệ nhân tạo tạo ra đã mở mắt mọi người đến sự thật rằng tôi gần như có một đối tác khi tôi đang thực hiện một nhiệm vụ, thực sự đưa ra gợi ý giúp tôi vượt qua những khúc mắc trong quá trình sáng tạo’.”
“Đồng thời, ông Rao nói rằng mức độ hỗ trợ cho việc viết mã là thấp.”
“Họ cung cấp cho bạn một khuôn khổ, một số thứ có thể lặp lại, nhưng họ không cung cấp cho bạn bất kỳ điều gì đặc biệt tốt,” ông nói. “Nếu tôi nói, hãy giải quyết vấn đề khó khăn này, thì họ không thể làm được điều đó, phải không? Họ thậm chí không viết mã đặc biệt tốt; nó giống như một người đã làm nó trong một hoặc hai năm, một cách tổng quát.”

Thực tế, một số nghiên cứu đã phát hiện ra rằng các mô hình ngôn ngữ lớn như GPT-4 có chất lượng mã hóa tổng thể dưới mức của các lập trình viên con người.
Một nghiên cứu gần đây của Sayed Erfan Arefin và đồng nghiệp tại Đại học Texas Tech đã thử nghiệm GPT-4 và phiên bản trước đó là GPT-3.5 trên các vấn đề mã hóa ví dụ từ nền tảng trực tuyến LeetCode – các vấn đề mà các ứng viên xin việc tại Google và các tập đoàn công nghệ khác thường được hỏi.
Các chương trình đã được đánh giá dựa trên hai thách thức chính, “tổ chức dữ liệu để truy cập hiệu quả (sử dụng cấu trúc dữ liệu thích hợp)” và “tạo quy trình làm việc để xử lý dữ liệu (sử dụng thuật toán hiệu quả).” Họ cũng đã được đánh giá dựa trên điều gọi là “xử lý chuỗi,” một lĩnh vực giao nhau với cả hai thách thức trên.
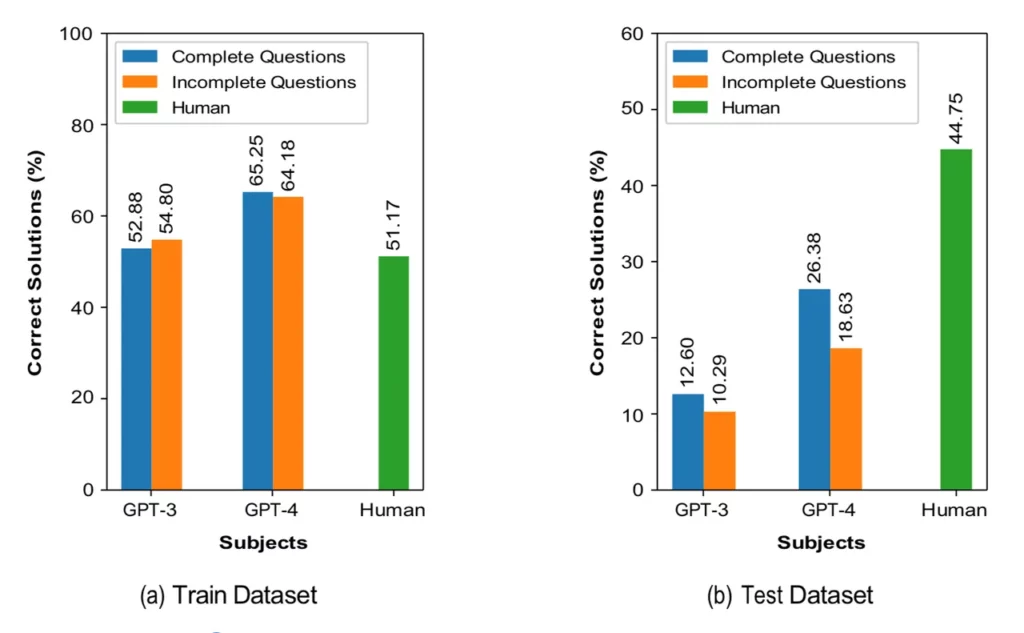
Khi các mô hình ngôn ngữ được cung cấp những gì tác giả gọi là các câu hỏi hoàn chỉnh, trong đó các chương trình được cung cấp với ví dụ về các giải pháp cho các câu hỏi, GPT-4 chỉ trả lời đúng 26% các câu hỏi, trong khi người tham gia con người đạt được tỷ lệ 45%. Khi loại bỏ một số thông tin, khả năng của GPT-4 sụt giảm xuống còn 19% câu trả lời đúng. GPT-3.5 chỉ đạt khoảng 12% và 10%, tương ứng.
Các tác giả cũng xem xét chất lượng mã code của GPT, cả trong trường hợp thành công và thất bại. Trong cả hai trường hợp, họ phát hiện ra một vấn đề thường xuyên: GPT thường gặp khó khăn trong việc cơ bản của lập trình, “xác định biến một cách đồng nhất.”
Quy mô cũng là một vấn đề đối với việc tạo mã trí tuệ nhân tạo. Các kết quả đáng khích lệ nhất cho đến nay trong các nghiên cứu về GPT-4 chủ yếu là về các vấn đề lập trình đơn giản.
Một nghiên cứu của David Noever thuộc công ty bảo mật mạng PeopleTec đã thử nghiệm khả năng của GPT-4 trong việc tìm mã lỗi trong các mẫu mã, tương tự như các chương trình hiện có trên thị trường để kiểm tra lỗ hổng bảo mật, như Snyk, một dạng của “Kiểm tra Bảo mật Ứng dụng Tĩnh” hoặc SAST.
Trong một số trường hợp, GPT-4 tìm thấy nhiều lỗi hơn so với Snyk, các tác giả báo cáo. Tuy nhiên, nó cũng bỏ sót nhiều lỗi khác. Và nó chỉ được thử nghiệm trên tổng cộng hơn 2.000 dòng mã. Điều này rất nhỏ bé so với các ứng dụng sản xuất đầy đủ, có thể chứa hàng trăm nghìn đến hàng triệu dòng mã, trải dài qua nhiều tập tin liên kết. Chưa rõ rằng những thành công trên các vấn đề mẫu nhỏ có thể áp dụng vào sự phức tạp như vậy.
Một nghiên cứu tháng trước của Zhijie Liu và đồng nghiệp tại Đại học ShanghaiTech đã xem xét chất lượng mã dựa trên tính đúng đắn, dễ hiểu và bảo mật. Cuộc kiểm tra đã thách thức ChatGPT với các nhiệm vụ trên LeetCode, giống như Arefin và nhóm tại Đại học Texas Tech, và cũng thử nghiệm khả năng tạo mã của nó trên môi trường Common Weakness Environment, một bài kiểm tra về lỗ hổng được duy trì bởi công ty nghiên cứu MITRE.
Lou và nhóm của ông đã kiểm tra ChatGPT với các nhiệm vụ được đưa ra trước hoặc sau năm 2021, vì ChatGPT chỉ được đào tạo trên tài liệu trước năm 2021, vì vậy họ muốn xem chương trình hoạt động ra sao khi được kiểm tra với cả những thách thức đã được xác định từ trước và các thách thức mới hơn.
Kết quả rất đáng chú ý. Đối với các vấn đề mới hơn, gọi là “Aft.” cho “sau” năm 2021, Lui và nhóm của ông đã phát hiện tỷ lệ đúng đắn trong mã code của ChatGPT rất thấp. “Khả năng tạo ra mã chính xác chức năng của ChatGPT giảm đáng kể khi độ khó của vấn đề tăng lên,” họ viết. Chỉ có 15,4% mã chương trình C được chấp nhận, và không có mã nào được chấp nhận cho các vấn đề khó nhất. Ngoài ra, “mã được tạo ra bởi ChatGPT cho các vấn đề khó và trung bình có khả năng chứa cả lỗi biên dịch và lỗi thời gian chạy.” Các lập trình viên con người tham gia kiểm tra, trung bình, đúng 66%.
Đối với các vấn đề cũ hơn, được gắn nhãn “Bef.” (trước) tỷ lệ tăng lên 31% đúng, nhưng vẫn còn thấp.
Nhóm nghiên cứu đã xem xét nhiều ví dụ và xác định các loại câu trả lời sai mà ChatGPT đã đưa ra trong dòng mã của nó. Ví dụ, trong khi thiết kế tổng thể của chương trình có thể theo hướng đúng, một dòng mã cụ thể có thể thể hiện một cách sai lầm cơ bản trong việc sử dụng một thứ đơn giản như đánh giá một biến, một lỗi mà khó có thể tưởng tượng một lập trình viên mới làm.

Liu và nhóm của ông đưa ra một loạt các kết luận chung thú vị và các yếu tố làm giảm điều này. Một điều họ phát hiện là ChatGPT gặp khó khăn khi giải quyết các vấn đề mới lạ: “ChatGPT có thể có giới hạn khi tạo mã cho các vấn đề không quen thuộc hoặc chưa được thấy trong tập dữ liệu huấn luyện, ngay cả khi vấn đề đó dễ dàng từ góc nhìn của con người.”
Tuy nhiên, loại ngôn ngữ lập trình được sử dụng cũng quan trọng: công nghệ này hoạt động tốt hơn với một số ngôn ngữ lập trình cụ thể được “kiểu mạnh” hoặc có tính “biểu đạt” cao hơn.
“Nói chung, xác suất của ChatGPT tạo ra mã chức năng đúng là cao hơn khi sử dụng các ngôn ngữ có sức mạnh biểu đạt cao hơn (ví dụ, Python3),” họ viết.
Một điểm yếu khác là ChatGPT có thể trở nên phức tạp đến mức các lỗi của nó khó để sửa chữa. “Quá trình tạo mã của ChatGPT có thể bất cẩn,” họ viết, “và mã được tạo ra có thể không đáp ứng một số điều kiện chi tiết được mô tả, dẫn đến việc khó khăn trong việc tạo ra hoặc sửa chữa (để đạt được tính chính xác chức năng).”
Về bài kiểm tra Lỗ hổng Chung của MITRE, “mã được tạo ra bởi ChatGPT thường thể hiện các lỗ hổng liên quan, đó là một vấn đề nghiêm trọng,” họ viết. May mắn là họ lưu ý rằng ChatGPT có khả năng sửa chữa nhiều lỗ hổng đó trong các lần yêu cầu tiếp theo khi được cung cấp với thông tin chi tiết hơn từ tập dữ liệu của MITRE.
Tất cả ba nghiên cứu đều cho thấy rằng việc sử dụng trí tuệ nhân tạo tạo ra mã máy tính đang ở giai đoạn rất sớm. Như Rao đã nói, nó hữu ích trong các nhiệm vụ trợ lý đơn giản, nơi lập trình viên đảm trách.
Có khả năng tiến bộ sẽ đến từ các phương pháp mới đánh đổ các mô hình lập trình truyền thống. Ví dụ, công việc gần đây của Google đào tạo các mô hình ngôn ngữ để kết nối với internet để tìm các công cụ giải quyết nhiệm vụ. Và công việc của đơn vị DeepMind của Google đào tạo các mô hình ngôn ngữ để đi sâu hơn vào việc cải thiện hiệu suất thông qua việc tối ưu hóa các lời nhắc của chính nó – một loại lập trình tự phản xạ có vẻ triển vọng.
Rao cho biết có thể cuối cùng sẽ cần có điều gì đó sâu sắc hơn.
“Tôi không nghĩ rằng nó có thể được giải quyết bằng lời nhắc,” Rao nói. “Tôi nghĩ rằng thực tế là chúng ta vẫn còn phải giải quyết một số vấn đề cơ bản – vẫn còn điều gì đó cơ bản thiếu.”
Rao bổ sung: “Chúng ta có thể cung cấp rất nhiều dữ liệu cho một mạng thần kinh lớn đến mức đó là sẽ có hàng trăm kiếp người hoặc hơn về kinh nghiệm con người, và tuy nhiên, một con người có ít kinh nghiệm hơn có thể giải quyết các vấn đề mới mẻ tốt hơn và không mắc các loại lỗi cơ bản cụ thể.”