


Tác giả: Haziqa Sajid.
ngày 11 tháng 5 năm 2023
Các mô hình ngôn ngữ lớn (LLM) như GPT-3 và ChatGPT đã làm cách mạng hóa lĩnh vực Trí tuệ nhân tạo bằng cách cung cấp khả năng Hiểu Ngôn ngữ Tự nhiên và tạo nội dung. Tuy nhiên, quá trình phát triển chúng đòi hỏi một số lượng tiền lớn, giới hạn sự tiếp cận và nghiên cứu tiếp theo. Các nhà nghiên cứu ước tính rằng việc huấn luyện GPT-3 đã tốn khoảng 5 triệu đô la cho OpenAI. Tuy nhiên, Microsoft đã nhận ra tiềm năng của chúng và đã đầu tư 1 tỷ đô la vào năm 2019 và 10 tỷ đô la vào năm 2023 vào dự án GPT-3 và ChatGPT của OpenAI.
LLM là các mô hình học máy được đào tạo trên dữ liệu văn bản mở rộng để áp dụng trong các ứng dụng Xử lý Ngôn ngữ Tự nhiên. Chúng dựa trên kiến trúc transformer và sử dụng cơ chế chú ý cho các nhiệm vụ Xử lý Ngôn ngữ Tự nhiên như trả lời câu hỏi, dịch máy, phân tích tâm trạng, vv.
Một câu hỏi nảy sinh: liệu có thể tăng hiệu suất của những mô hình lớn này đồng thời giảm chi phí tính toán và thời gian đào tạo không?

Nhiều phương pháp, như Progressive Neural Networks, Network Morphism, sự song song hóa mô hình trong từng lớp, chuyển giao kiến thức, v.v., đã được phát triển để giảm chi phí tính toán khi đào tạo các mạng nơ-ron. Phương pháp mới LiGO (Linear Growth Operator) mà chúng ta sẽ thảo luận đang thiết lập một ngưỡng mới. Nó giảm đi một nửa chi phí tính toán khi đào tạo các LLM.
Trước khi thảo luận về kỹ thuật này, việc xem xét các yếu tố góp phần vào chi phí cao của việc tạo ra các LLM là rất cần thiết.
Chi phí xây dựng các Mô hình Ngôn ngữ Lớn
Ba khoản chi tiêu chính cho việc phát triển các Mô hình Nền tảng Ngôn ngữ Lớn (LLM) như sau:
1. Tài nguyên tính toán
Xây dựng các LLM đòi hỏi tài nguyên tính toán khổng lồ để đào tạo trên các bộ dữ liệu lớn. Chúng phải xử lý hàng tỷ tham số và học các mẫu phức tạp từ dữ liệu văn bản khổng lồ.
Để đạt được hiệu suất hàng đầu, cần đầu tư vào phần cứng chuyên biệt như Đơn vị Xử lý Đồ họa (GPU) và Đơn vị Xử lý Tensor (TPU) để xây dựng và đào tạo các LLM.
Ví dụ, GPT-3 đã được đào tạo trên một máy tính siêu cấp với 10.000 GPU cấp doanh nghiệp (H100 và A100) và 285.000 lõi CPU.
2. Tiêu thụ năng lượng
Sự yêu cầu tài nguyên tính toán mạnh mẽ cho việc xây dựng các LLM dẫn đến tiêu thụ năng lượng đáng kể. Ví dụ, việc đào tạo GPT-3 với 175 tỷ tham số đã mất 14,8 ngày bằng cách sử dụng 10.000 GPU V100, tương đương với 3,55 triệu giờ GPU. Mức tiêu thụ năng lượng cao như vậy có tác động đáng kể đến môi trường.
3. Lưu trữ và Quản lý Dữ liệu
Các LLM được đào tạo trên các bộ dữ liệu lớn. Ví dụ, GPT-3 đã được đào tạo trên một nguồn tài liệu văn bản lớn, bao gồm Common Crawl, WebText2, Books1, Books2 và Wikipedia, cùng với các nguồn khác. Để thu thập, quản lý và lưu trữ những bộ dữ liệu như vậy, cần đầu tư đáng kể vào hạ tầng.
Ngoài ra, cần sử dụng lưu trữ đám mây để lưu trữ dữ liệu, và cần có chuyên môn con người để tiền xử lý dữ liệu và quản lý phiên bản. Hơn nữa, đảm bảo rằng chiến lược dữ liệu của bạn tuân theo các quy định như GDPR cũng làm tăng chi phí.
Kỹ thuật LiGO (Linear Growth Operator): Giảm Chi phí Xây dựng Các Mô hình Ngôn ngữ Lớn đi Một Nửa
LiGO (Linear Growth Operator) là một kỹ thuật mới được các nhà nghiên cứu tại MIT phát triển để giảm đi 50% chi phí tính toán khi đào tạo các LLM. Phương pháp này liên quan đến việc khởi tạo trọng số của các mô hình lớn hơn từ các mô hình nhỏ hơn đã được đào tạo trước, từ đó cho phép việc mở rộng hiệu quả của mạng nơ-ron.
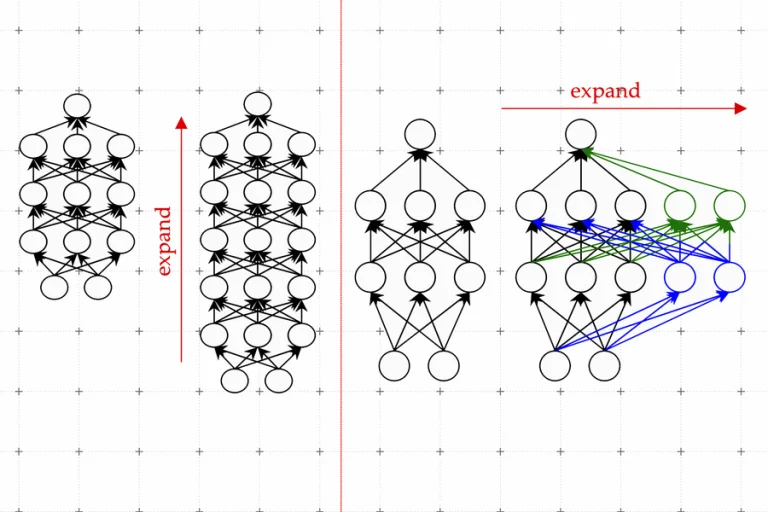
Yoon Kim, tác giả chính của bài báo, nói: “Đã được ước tính rằng việc đào tạo các mô hình ở quy mô mà ChatGPT được giả định chạy có thể tốn hàng triệu đô la chỉ cho một lần đào tạo duy nhất. Liệu chúng ta có thể cải thiện hiệu quả của các phương pháp đào tạo này, để chúng ta vẫn có thể có các mô hình tốt trong thời gian ngắn hơn và với ít tiền hơn? Chúng tôi đề xuất làm điều này bằng cách tận dụng các mô hình ngôn ngữ nhỏ hơn đã được đào tạo trước đó.”
Phương pháp này duy trì được các lợi ích về hiệu suất của các mô hình lớn với chi phí tính toán và thời gian đào tạo giảm so với việc đào tạo một mô hình lớn từ đầu. LiGO sử dụng một toán tử tăng trưởng tuyến tính dựa trên dữ liệu kết hợp các toán tử về độ sâu và độ rộng để đạt hiệu suất tối ưu.
Bài báo đã sử dụng nhiều bộ dữ liệu khác nhau để tiến hành các thử nghiệm dựa trên văn bản, bao gồm tập dữ liệu tiếng Anh Wikipedia để đào tạo các mô hình BERT và RoBERTa và tập dữ liệu C4 để đào tạo GPT2.
Kỹ thuật LiGO đã thực hiện thử nghiệm bao gồm việc mở rộng BERT-Small thành BERT-Base, BERT-Base thành BERT-Large, RoBERTa-Small thành RoBERTa-Base, GPT2-Base thành GPT2-Medium, và CaiT-XS thành CaiT-S.
Các nhà nghiên cứu đã so sánh phương pháp của họ với một số cơ sở dữ liệu khác, bao gồm việc đào tạo từ đầu, đào tạo tiến bộ, bert2BERT và KI.
Kỹ thuật LiGO đã giúp tiết kiệm 44,7% lượng phép toán dấu phẩy động (FLOPs) và 40,7% thời gian trên tường so với việc đào tạo BERT-Base từ đầu bằng cách tái sử dụng mô hình BERT-Small. Toán tử tăng trưởng LiGO vượt trội hơn so với StackBERT, MSLT, bert2BERT và KI trong việc đào tạo hiệu quả.
Lợi ích của việc sử dụng một kỹ thuật tối ưu hóa đào tạo như LiGO
LiGO là một phương pháp đào tạo mạng nơ-ron hiệu quả với các lợi ích sau đây:
1. Đào tạo Nhanh Hơn
Như đã nêu trước đây, việc đào tạo nhanh hơn là lợi ích chính của kỹ thuật LiGO. Nó đào tạo các LLM trong nửa thời gian, tăng năng suất và giảm chi phí.
2. Tiết kiệm Tài nguyên
LiGO hiệu quả về tài nguyên vì nó giảm thiểu thời gian thực hiện và số lượng phép toán dấu phẩy động (FLOPs), dẫn đến một cách tiếp cận đào tạo các mô hình transformer lớn hiệu quả về chi phí và thân thiện với môi trường hơn.
3. Tính tổng quát
Kỹ thuật LiGO đã cải thiện hiệu suất của cả các mô hình transformer về ngôn ngữ và thị giác, ngụ ý rằng đó là một kỹ thuật có thể áp dụng cho nhiều nhiệm vụ khác nhau.
Xây dựng các sản phẩm Trí tuệ Nhân tạo thương mại chỉ là một khía cạnh của tổng chi phí liên quan đến các hệ thống Trí tuệ Nhân tạo. Một phần chi phí đáng kể khác đến từ hoạt động hàng ngày. Ví dụ, việc trả lời các truy vấn bằng ChatGPT tốn cho OpenAI khoảng 700,000 đô la mỗi ngày. Dự kiến các nhà nghiên cứu sẽ tiếp tục nghiên cứu các phương pháp làm cho các LLM hiệu quả về chi phí trong quá trình đào tạo và dễ tiếp cận hơn khi chạy thời gian thực.