


Tác giả: Aayush Mitta
25 tháng 10 năm 2023
Các mô hình ngôn ngữ lớn (LLMs) như dòng sản phẩm GPT của OpenAI đã được đào tạo trên một loạt đa dạng dữ liệu có sẵn công khai, thể hiện khả năng đáng kinh ngạc trong việc tạo văn bản, tóm tắt, trả lời câu hỏi và lập kế hoạch. Mặc dù tính linh hoạt của chúng, một câu hỏi thường xuyên được đặt ra liên quan đến việc tích hợp mượt mà của những mô hình này với dữ liệu tùy chỉnh, riêng tư hoặc độc quyền.
Các doanh nghiệp và cá nhân thường đối mặt với dữ liệu độc đáo và tùy chỉnh, thường được lưu trữ trong các ứng dụng khác nhau như Notion, Slack và Salesforce, hoặc được lưu trữ trong các tệp cá nhân. Để tận dụng LLMs cho dữ liệu cụ thể này, đã được đề xuất và thử nghiệm một số phương pháp.
Feine-tuning (điều chỉnh tinh chỉnh) đại diện cho một trong những phương pháp như vậy, nó bao gồm việc điều chỉnh các trọng số của mô hình để tích hợp kiến thức từ các bộ dữ liệu cụ thể. Tuy nhiên, quá trình này không thiếu những thách thức của riêng nó. Nó đòi hỏi sự cố gắng đáng kể trong việc chuẩn bị dữ liệu, kết hợp với một quy trình tối ưu hóa khó khăn, đòi hỏi một mức độ nhất định về chuyên môn về học máy. Hơn nữa, những tác động tài chính có thể đáng kể, đặc biệt khi xử lý các bộ dữ liệu lớn.
Học trong ngữ cảnh (in-context learning) đã nảy sinh như một phương pháp thay thế, ưu tiên việc tạo ra các đầu vào và gợi ý để cung cấp cho LLM ngữ cảnh cần thiết để tạo ra kết quả chính xác. Phương pháp này giảm bớt nhu cầu về việc đào tạo lại mô hình một cách mở rộng, cung cấp một cách hiệu quả và dễ tiếp cận hơn để tích hợp dữ liệu riêng.
Tuy nhiên, hạn chế của phương pháp này đó là nó phụ thuộc vào kỹ năng và chuyên môn của người sử dụng trong việc tạo ra gợi ý. Hơn nữa, học trong ngữ cảnh không phải lúc nào cũng chính xác hoặc đáng tin cậy như việc tinh chỉnh, đặc biệt khi xử lý dữ liệu chuyên ngành hoặc kỹ thuật cao cấp. Quá trình tiền đào tạo của mô hình trên nhiều loại văn bản trên internet không đảm bảo hiểu biết về ngôn ngữ chuyên ngành hoặc ngữ cảnh cụ thể, điều này có thể dẫn đến kết quả không chính xác hoặc không liên quan. Điều này đặc biệt gây khó khăn khi dữ liệu riêng tư xuất phát từ một lĩnh vực hoặc ngành nghề cụ thể.
Hơn nữa, lượng ngữ cảnh có thể được cung cấp trong một gợi ý đơn lẻ bị hạn chế, và hiệu suất của LLM có thể suy giảm khi độ phức tạp của nhiệm vụ tăng lên. Còn một thách thức nữa là về quyền riêng tư và bảo mật dữ liệu, vì thông tin được cung cấp trong gợi ý có thể là nhạy cảm hoặc bí mật.
Khi cộng đồng nghiên cứu những kỹ thuật này, các công cụ như LlamaIndex đang thu hút sự chú ý.
Dự án LlamaIndex được khởi đầu bởi Jerry Liu, một cựu nhà nghiên cứu của Uber. Trong quá trình thử nghiệm với GPT-3 vào mùa thu năm ngoái, Liu đã nhận thấy giới hạn của mô hình liên quan đến việc xử lý dữ liệu riêng tư, chẳng hạn như các tệp cá nhân. Nhận thức này đã dẫn đến việc bắt đầu dự án mã nguồn mở LlamaIndex.
Dự án này đã thu hút sự quan tâm của các nhà đầu tư và đã đảm bảo 8,5 triệu đô la trong vòng gọi vốn hạt giống gần đây.
LlamaIndex giúp tăng cường LLMs với dữ liệu tùy chỉnh, nối kết khoảng cách giữa các mô hình được đào tạo trước và các trường hợp sử dụng dữ liệu tùy chỉnh. Thông qua LlamaIndex, người dùng có thể tận dụng dữ liệu của riêng họ với LLMs, mở khóa quá trình tạo ra kiến thức và lý luận với cái nhìn cá nhân hóa.
Người dùng có thể dễ dàng cung cấp dữ liệu của riêng họ cho LLMs, tạo ra môi trường mà ở đó quá trình tạo ra kiến thức và lý luận được cá nhân hóa sâu sắc và sâu sắc. LlamaIndex giải quyết những hạn chế của học trong ngữ cảnh bằng cách cung cấp một nền tảng dễ sử dụng và an toàn hơn cho tương tác dữ liệu, đảm bảo rằng ngay cả những người có kiến thức hạn chế về học máy cũng có thể tận dụng toàn bộ tiềm năng của LLMs với dữ liệu riêng tư của họ.
Các Khái niệm Cao Cấp và Một số Kiến thức
- RAG – Tạo ra thông tin bằng cách tìm kiếm (Retrieval Augmented Generation):
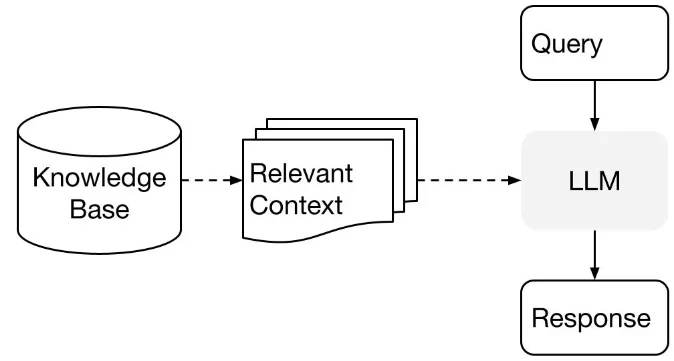
RAG là một quá trình kép được thiết kế để kết hợp LLMs với dữ liệu tùy chỉnh, từ đó tăng cường khả năng của mô hình để cung cấp những phản ứng chính xác và thông tin hơn. Quá trình này bao gồm:
Giai đoạn Chỉ mục hóa (Indexing Stage): Đây là giai đoạn chuẩn bị, nơi đặt nền móng cho việc tạo cơ sở dữ liệu kiến thức.

Giai đoạn Truy vấn (Querying Stage): Ở đây, cơ sở dữ liệu kiến thức được tìm kiếm để tìm kiếm ngữ cảnh liên quan để hỗ trợ LLMs trong việc trả lời các truy vấn.
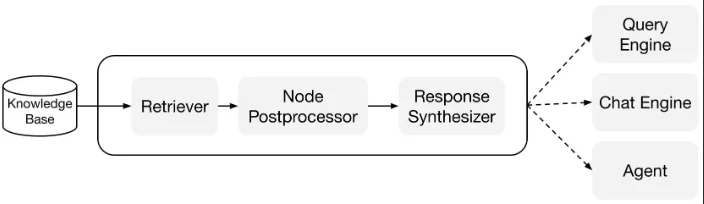
Hành trình Chỉ mục hóa với LlamaIndex:
- Bộ kết nối dữ liệu (Data Connectors): Hãy xem xét bộ kết nối dữ liệu như hộ chiếu của dữ liệu của bạn đến LlamaIndex. Chúng giúp nhập dữ liệu từ các nguồn và định dạng khác nhau, đóng gói chúng thành một biểu diễn ‘Tài liệu’ đơn giản. Bộ kết nối dữ liệu có sẵn trong LlamaHub, một kho chứa mã nguồn mở chứa các trình tải dữ liệu. Những trình tải này được thiết kế để tích hợp dễ dàng, cho phép trải nghiệm cắm và chạy với bất kỳ ứng dụng LlamaIndex nào.
- Tài liệu / Nút (Documents / Nodes): Một Tài liệu giống như một chiếc vali tổng hợp có thể chứa nhiều loại dữ liệu khác nhau, có thể là một tệp PDF, kết quả API, hoặc dữ liệu trong cơ sở dữ liệu. Ngược lại, một Nút là một đoạn hoặc “mẩu” từ một Tài liệu, được bổ sung bởi siêu dữ liệu và mối quan hệ với các nút khác, đảm bảo một nền tảng mạnh mẽ cho việc truy xuất dữ liệu chính xác sau này.
- Chỉ mục dữ liệu (Data Indexes): Sau khi dữ liệu được nhập, LlamaIndex hỗ trợ trong việc chỉ mục hóa dữ liệu này thành một định dạng có thể tìm kiếm. Đằng sau hậu trường, nó phân tách các tài liệu thô thành các biểu diễn trung gian, tính toán các vectơ nhúng và suy ra siêu dữ liệu. Trong các chỉ mục này, ‘VectorStoreIndex’ thường là sự lựa chọn phổ biến.
Các Loại Chỉ mục trong LlamaIndex: Chìa khóa cho Dữ liệu Tổ chức
LlamaIndex cung cấp các loại chỉ mục khác nhau, mỗi loại phục vụ cho những nhu cầu và trường hợp sử dụng khác nhau. Ở trung tâm của những chỉ mục này nằm “nút” như đã được thảo luận ở trên. Hãy cùng tìm hiểu về các chỉ mục trong LlamaIndex với cơ chế và ứng dụng của chúng.
- Chỉ mục Danh sách (List Index):
- Cơ chế: Chỉ mục Danh sách sắp xếp các nút theo thứ tự như một danh sách. Sau khi chia dữ liệu đầu vào thành các nút, chúng được sắp xếp theo một cách tuyến tính, sẵn sàng để được truy vấn theo cách tuần tự hoặc thông qua từ khóa hoặc vectơ nhúng.
- Lợi ích: Loại chỉ mục này nổi bật khi cần thực hiện truy vấn theo thứ tự. LlamaIndex đảm bảo sử dụng toàn bộ dữ liệu đầu vào của bạn, ngay cả khi nó vượt quá giới hạn mã thông báo của LLM, bằng cách truy vấn văn bản một cách thông minh từ mỗi nút và điều chỉnh câu trả lời khi điều hướng xuống danh sách.
- Chỉ mục Lưu trữ Vectơ (Vector Store Index):
- Cơ chế: Ở đây, các nút biến đổi thành các vectơ nhúng, được lưu trữ cục bộ hoặc trong một cơ sở dữ liệu vectơ chuyên dụng như Milvus. Khi được truy vấn, nó truy xuất các nút tương tự nhất theo top_k và đưa chúng đến bộ tổng hợp câu trả lời.
- Lợi ích: Nếu quy trình làm việc của bạn dựa vào so sánh văn bản để tìm kiếm sự tương tự ngữ nghĩa thông qua tìm kiếm vectơ, loại chỉ mục này có thể được sử dụng.
- Chỉ mục Cây (Tree Index):
- Cơ chế: Trong một Chỉ mục Cây, dữ liệu đầu vào biến đổi thành một cấu trúc cây, được xây dựng từ dưới lên từ các nút lá (các đoạn dữ liệu gốc). Các nút cha xuất hiện dưới dạng tóm tắt của các nút lá, được tạo ra bằng GPT. Trong quá trình truy vấn, chỉ mục cây có thể đi từ nút gốc đến nút lá hoặc xây dựng câu trả lời trực tiếp từ các nút lá được chọn.
- Lợi ích: Với Chỉ mục Cây, việc truy vấn các đoạn văn bản dài trở nên hiệu quả hơn và việc trích xuất thông tin từ các đoạn văn bản khác nhau được đơn giản hóa.
- Chỉ mục Từ khóa (Keyword Index):
- Cơ chế: Một bản đồ từ khóa đến các nút tạo nên lõi của Chỉ mục Từ khóa. Khi được truy vấn, các từ khóa được rút ra từ truy vấn và chỉ các nút được ánh sáng chiếu sáng trong bản đồ từ khóa được đưa ra.
- Lợi ích: Khi bạn có truy vấn từ người dùng rõ ràng, bạn có thể sử dụng Chỉ mục Từ khóa. Ví dụ, việc tìm kiếm trong các tài liệu về chăm sóc sức khỏe trở nên hiệu quả hơn khi chỉ tập trung vào các tài liệu liên quan đến COVID-19.
Cài đặt LlamaIndex
Cài đặt LlamaIndex là một quá trình đơn giản. Bạn có thể lựa chọn cài đặt trực tiếp từ Pip hoặc từ mã nguồn. (Đảm bảo bạn đã cài đặt Python trên hệ thống của bạn hoặc bạn có thể sử dụng Google Colab)
- Cài đặt từ Pip:
- Thực hiện lệnh sau:
perlCopy code
pip install llama-index
- Ghi chú: Trong quá trình cài đặt, LlamaIndex có thể tải về và lưu trữ các tệp cục bộ cho các gói như NLTK và HuggingFace. Để chỉ định một thư mục cho các tệp này, sử dụng biến môi trường “LLAMA_INDEX_CACHE_DIR”.
- Cài đặt từ Mã nguồn (Source):
- Trước hết, sao chép kho LlamaIndex từ GitHub:
bashCopy code
git clone https://github.com/jerryjliu/llama_index.git
- Sau khi đã sao chép, điều hướng đến thư mục dự án.
- Bạn sẽ cần sử dụng Poetry để quản lý các gói phụ thuộc.
- Tiếp theo, tạo một môi trường ảo bằng Poetry:
Copy code
poetry shell
- Cuối cùng, cài đặt các yêu cầu gói cốt lõi với lệnh:
Copy code
poetry install
Thiết Lập Môi trường cho LlamaIndex
- Thiết lập OpenAI:
- Theo mặc định, LlamaIndex sử dụng gpt-3.5-turbo của OpenAI để tạo văn bản và text-embedding-ada-002 cho truy vấn và vectơ nhúng văn bản.
- Để sử dụng thiết lập này, bạn cần có một OPENAI_API_KEY. Bạn có thể lấy một key bằng cách đăng ký tại trang web của OpenAI và tạo một mã thông báo API mới.
- Bạn có sự linh hoạt để tùy chỉnh Mô hình Ngôn ngữ Lớn (LLM) cơ bản phù hợp với nhu cầu dự án của bạn. Tùy theo nhà cung cấp LLM của bạn, bạn có thể cần các khóa môi trường và mã thông báo bổ sung.
- Thiết Lập Môi Trường Cục bộ (Local Environment Setup):
- Nếu bạn không muốn sử dụng OpenAI, LlamaIndex sẽ tự động chuyển sang các mô hình cục bộ – LlamaCPP và llama2-chat-13B cho việc tạo văn bản, và BAAI/bge-small-en cho truy vấn và vectơ nhúng.
- Để sử dụng LlamaCPP, hãy tuân theo hướng dẫn cài đặt được cung cấp. Đảm bảo cài đặt gói llama-cpp-python, được biên dịch tốt để hỗ trợ GPU của bạn. Thiết lập này sẽ sử dụng khoảng 11.5GB bộ nhớ trên cả CPU và GPU.
- Đối với vectơ nhúng cục bộ, thực hiện lệnh pip install sentence-transformers. Thiết lập cục bộ này sẽ sử dụng khoảng 500MB bộ nhớ.
Với các thiết lập này, bạn có thể điều chỉnh môi trường của mình để sử dụng sức mạnh của OpenAI hoặc chạy các mô hình cục bộ, phù hợp với yêu cầu và tài nguyên dự án của bạn.
LlamaIndex và Langchain: Lựa chọn dựa trên nhu cầu sử dụng
Lựa chọn giữa LlamaIndex và Langchain sẽ phụ thuộc vào mục tiêu của dự án của bạn. Nếu bạn muốn phát triển một công cụ tìm kiếm thông minh, LlamaIndex là một sự lựa chọn đáng tin cậy, xuất sắc là một cơ chế lưu trữ thông minh cho việc truy xuất dữ liệu. Ngược lại, nếu bạn muốn tạo một hệ thống giống như ChatGPT với khả năng kết nối và mở rộng, Langchain là lựa chọn phù hợp hơn. Langchain không chỉ hỗ trợ nhiều phiên bản của ChatGPT và LlamaIndex mà còn mở rộng chức năng bằng cách cho phép xây dựng các tác nhân đa nhiệm. Ví dụ, với Langchain, bạn có thể tạo ra các tác nhân có khả năng thực thi mã Python trong khi thực hiện tìm kiếm Google.
Tóm lại, trong khi LlamaIndex xuất sắc ở khâu xử lý dữ liệu, Langchain tổ chức nhiều công cụ để cung cấp một giải pháp linh hoạt toàn diện hơn.