


Tác giả: Aayush Mitta
Ngày 24 tháng 10 năm 2023
Các Mô hình Ngôn ngữ Lớn (LLMs) đã tạo ra một niền độc đáo, mang lại khả năng đặc biệt trong việc hiểu và tạo ra văn bản giống con người. Sức mạnh của LLMs có thể được truy nguồn về kích thước khổng lồ của chúng, thường có hàng tỷ tham số. Trong khi quy mô lớn này thúc đẩy hiệu suất của chúng, nó đồng thời đem lại những thách thức, đặc biệt là khi đến việc điều chỉnh mô hình cho các nhiệm vụ hoặc lĩnh vực cụ thể. Các con đường truyền thống để quản lý LLMs, chẳng hạn như việc điều chỉnh tất cả các tham số, đề xuất một gánh nặng tính toán và tài chính nặng nề, do đó tạo ra một rào cản đáng kể đối với việc áp dụng rộng rãi của chúng trong các ứng dụng thực tế.
Trong một bài viết trước đó, chúng tôi đã nghiên cứu về việc điều chỉnh Mô hình Ngôn ngữ Lớn (LLMs) để điều chỉnh chúng cho các yêu cầu cụ thể. Chúng tôi đã khám phá các phương pháp điều chỉnh như Điều chỉnh dựa trên hướng dẫn, Điều chỉnh Đơn nhiệm vụ và Điều chỉnh Hiệu quả về Tham số (PEFT), mỗi phương pháp có cách tiếp cận riêng của nó để tối ưu hóa LLMs cho các nhiệm vụ khác nhau. Trung tâm của cuộc thảo luận là kiến trúc transformer, cốt lõi của LLMs, và những thách thức mà sự yêu cầu tính toán và bộ nhớ đối với việc xử lý một lượng lớn tham số trong quá trình điều chỉnh.
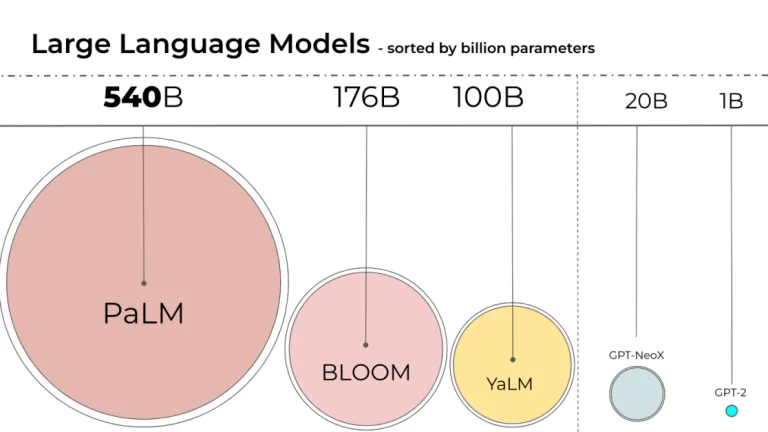
Hình ảnh trên đại diện cho quy mô của các mô hình ngôn ngữ lớn khác nhau, được sắp xếp theo số lượng tham số của họ. Đáng chú ý: PaLM, BLOOM, và nhiều mô hình khác.
Cho đến nay, đã có sự phát triển dẫn đến sự xuất hiện của các mô hình cỡ lớn hơn nhiều. Tuy nhiên, điều chỉnh các mô hình khổng lồ như vậy trên các hệ thống tiêu chuẩn là không thể thực hiện được mà không có các kỹ thuật tối ưu hóa chuyên biệt.
Khả năng thích nghi Rank-Thấp (LoRA) đã được Microsoft giới thiệu trong bài báo này, với mục tiêu giảm bớt những thách thức này và làm cho LLMs trở nên dễ tiếp cận và dễ thích nghi hơn.
Tâm huyết của LoRA nằm ở cách tiếp cận của nó đối với việc thích nghi mô hình mà không phải đi sâu vào việc đào tạo lại toàn bộ mô hình. Không giống như việc điều chỉnh tường tận truyền thống, nơi mỗi tham số đều có thể thay đổi, LoRA áp dụng một con đường thông minh hơn. Nó đóng băng trọng lượng mô hình được đào tạo trước và giới thiệu các ma trận phân tách hạng có thể đào tạo vào mỗi lớp của kiến trúc Transformer. Cách tiếp cận này giảm đáng kể số lượng tham số có thể đào tạo, đảm bảo quá trình thích nghi hiệu quả hơn.
Sự Tiến Hoá Của Các Chiến Lược Tinh Chỉnh (Fine-tuning) LLM
Nhìn lại hành trình của việc điều chỉnh LLM, người ta có thể nhận biết một số chiến lược được các chuyên gia áp dụng trong suốt nhiều năm. Ban đầu, sự chú ý được tập trung vào việc điều chỉnh tường tận các mô hình đã được đào tạo trước, một chiến lược đòi hỏi sự thay đổi toàn diện của các tham số mô hình để phù hợp với nhiệm vụ cụ thể hiện tại. Tuy nhiên, khi các mô hình trở nên lớn hơn và phức tạp hơn, yêu cầu tính toán của chiến lược này cũng tăng lên.
Chiến lược tiếp theo đang trở nên phổ biến là chiến lược điều chỉnh một phần, một phiên bản hạn chế hơn của chiến lược trước đó. Ở đây, chỉ một phần của các tham số của mô hình được điều chỉnh, giảm bớt một phần tải tính toán. Mặc dù có những ưu điểm, chiến lược điều chỉnh một phần vẫn không đủ nhanh để theo kịp sự tăng trưởng về kích thước của các mô hình LLMs.
Khi các chuyên gia liên tục khám phá các phương thức hiệu quả hơn, việc điều chỉnh toàn bộ đã nổi lên như một phương pháp nghiêm khắc nhưng đáng để theo đuổi.
Giới thiệu về LoRA
Hạng của một ma trận cho chúng ta cái nhìn vào các chiều được tạo ra bởi các cột của nó, được xác định bởi số lượng dòng hoặc cột duy nhất mà nó có.
- Ma trận Hạng Đầy Đủ: Hạng của nó phù hợp với số lượng ít hơn giữa số dòng hoặc số cột.
- Ma trận Hạng Thấp: Với một hạng đáng kể nhỏ hơn cả số dòng và số cột, nó chỉ bắt kịp ít đặc điểm hơn.
Bây giờ, các mô hình lớn hiểu rộng rãi về lĩnh vực của họ, chẳng hạn như ngôn ngữ trong các mô hình ngôn ngữ. Tuy nhiên, việc điều chỉnh tường tận chúng cho các nhiệm vụ cụ thể thường chỉ cần làm nổi bật một phần nhỏ trong những hiểu biết này. Đây là nơi LoRA tỏ sáng. Nó đề xuất rằng ma trận biểu diễn sự điều chỉnh trọng số này có thể là một ma trận hạng thấp, do đó chỉ bắt kịp ít đặc điểm hơn.
LoRA thông minh hạn chế hạng của ma trận điều chỉnh này bằng cách chia nó thành hai ma trận hạng thấp nhỏ hơn. Thay vì thay đổi toàn bộ ma trận trọng số, nó chỉ thay đổi một phần của nó, làm cho nhiệm vụ điều chỉnh tường tận trở nên hiệu quả hơn.
Sử dụng LoRA cho Transformers
LoRA giúp giảm tải huấn luyện trong mạng nơ-ron bằng cách tập trung vào các ma trận trọng số cụ thể. Trong kiến trúc Transformer, có một số ma trận trọng số được liên kết với cơ chế tự-chú ý, cụ thể là Wq, Wk, Wv và Wo, cùng với hai ma trận khác trong mô-đun Multi-Layer Perceptron (MLP).
Hãy phân tích toán học đằng sau LoRA:
- Ma trận Trọng số đã Đào tạo W0:
- Bắt đầu bằng một ma trận trọng số đã đào tạo W0 với kích thước d×k. Điều này có nghĩa rằng ma trận có d hàng và k cột.
- Phân Tách Hạng Thấp:
- Thay vì cập nhật trực tiếp toàn bộ ma trận W0, điều này có thể tốn nhiều tính toán, phương pháp đề xuất một cách tiếp cận phân tách hạng thấp.
- Cập nhật ΔW cho W0 có thể được biểu diễn dưới dạng tích của hai ma trận: B và A.
- B có kích thước d×r
- A có kích thước r×k
- Điểm quan trọng ở đây là r hạng của ma trận là nhỏ hơn nhiều so với cả d và k, điều này cho phép biểu diễn một cách hiệu quả tính toán hơn.
- Quá Trình Huấn Luyện:
- Trong quá trình huấn luyện, W0 vẫn không thay đổi. Điều này được gọi là “đóng băng” trọng số.
- Ngược lại, A và B là các tham số có thể đào tạo. Điều này có nghĩa rằng, trong quá trình huấn luyện, sẽ điều chỉnh các ma trận A và B để cải thiện hiệu suất của mô hình.
- Phép Nhân và Phép Cộng:
- Cả W0 và cập nhật ΔW (là tích của B và A) đều được nhân với cùng một đầu vào (được ký hiệu là x).
- Kết quả của những phép nhân này sau đó được cộng lại với nhau.
- Quá trình này được tóm tắt trong phương trình: h=W0x+ΔWx=W0x+BAx. Ở đây, h đại diện cho đầu ra cuối cùng sau khi áp dụng các cập nhật lên đầu vào x.
Nói tóm lại, phương pháp này cho phép cập nhật một ma trận trọng số lớn một cách hiệu quả hơn bằng cách biểu diễn các cập nhật bằng cách sử dụng phân tách hạng thấp, điều này có lợi về hiệu suất tính toán và sử dụng bộ nhớ.
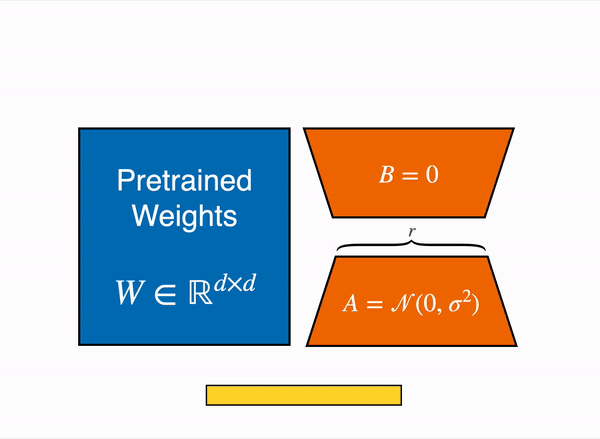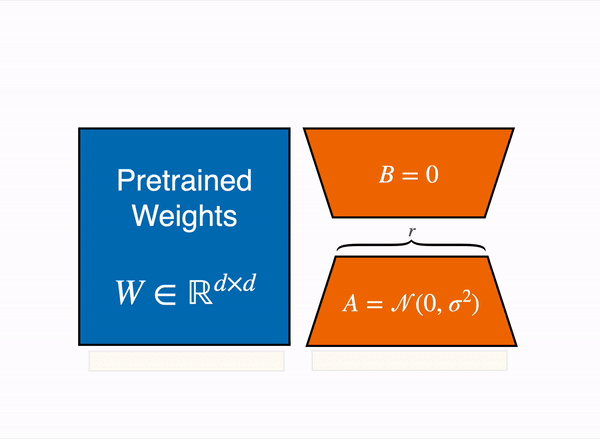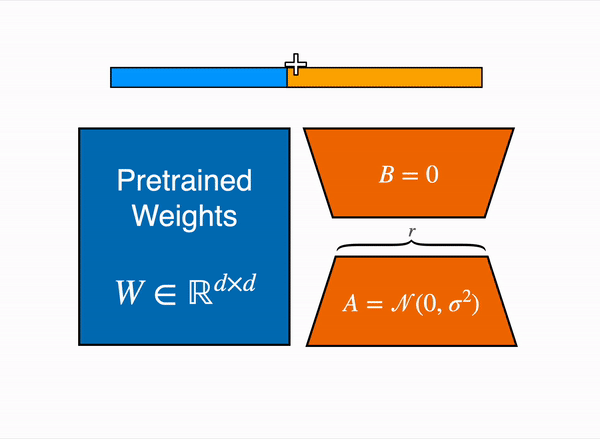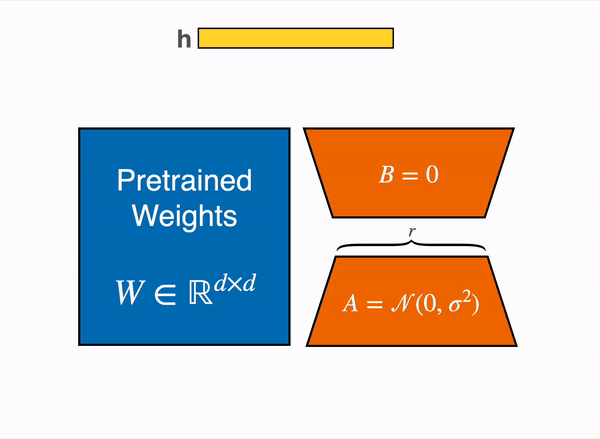
Khởi tạo và Mở rộng:
Khi huấn luyện các mô hình, cách chúng ta khởi tạo các tham số có thể ảnh hưởng đáng kể đến hiệu suất và hiệu quả của quá trình học. Trong ngữ cảnh việc cập nhật ma trận trọng số bằng cách sử dụng A và B:
- Khởi tạo Ma trận A và B:
- Ma trận A: Ma trận này được khởi tạo với các giá trị ngẫu nhiên theo phân phối Gaussian, còn được gọi là phân phối chuẩn. Lý do đằng sau việc sử dụng khởi tạo Gaussian là để phá vỡ đối xứng: các neuron khác nhau trong cùng một lớp sẽ học các đặc điểm khác nhau khi chúng có trọng số ban đầu khác nhau.
- Ma trận B: Ma trận này được khởi tạo với giá trị bằng không. Bằng cách làm như vậy, cập nhật ΔW=BA bắt đầu từ giá trị không ở đầu quá trình huấn luyện. Điều này đảm bảo rằng không có sự thay đổi đột ngột trong hành vi của mô hình ở đầu, cho phép mô hình thích nghi dần dần khi B học các giá trị thích hợp trong quá trình huấn luyện.
- Thang Chỉnh Đầu Ra từ ΔW:
- Sau khi tính toán cập nhật ΔW, đầu ra của nó được thang chỉnh bằng một hệ số rα trong đó α là một hằng số. Bằng cách thang chỉnh, độ lớn của các cập nhật được kiểm soát.
- Thang chỉnh đặc biệt quan trọng khi hạng r thay đổi. Ví dụ, nếu bạn quyết định tăng hạng để đạt được độ chính xác cao hơn (với chi phí tính toán), thang chỉnh đảm bảo bạn không cần phải điều chỉnh nhiều tham số siêu. Nó đảm bảo tính ổn định cho mô hình.
Tác Động Thực Tế của LoRA
LoRA đã thể hiện tiềm năng của nó trong việc điều chỉnh các mô hình LLMs thành các phong cách nghệ thuật cụ thể một cách hiệu quả bởi cộng đồng AI. Điều này đã được thể hiện rõ trong việc thích nghi một mô hình để bắt chước phong cách nghệ thuật của Greg Rutkowski.
Như đã được nhấn mạnh trong bài báo với ví dụ về GPT-3 175 tỷ tham số. Có các phiên bản riêng lẻ của các mô hình được điều chỉnh cho từng tác vụ với 175 tỷ tham số mỗi phiên bản là một chi phí đáng kể. Nhưng với LoRA, số lượng tham số có thể đào tạo giảm đi 10.000 lần, và việc sử dụng bộ nhớ GPU giảm xuống còn một phần ba.
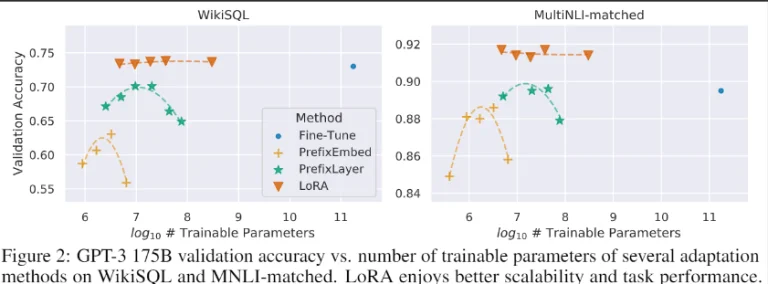
Phương pháp LoRA không chỉ thể hiện một bước tiến đáng kể trong việc làm cho LLMs trở nên dễ tiếp cận hơn mà còn làm nổi bật tiềm năng để nối dầu khoảng cách giữa các tiến bộ lý thuyết và các ứng dụng thực tế trong lĩnh vực Trí tuệ Nhân tạo. Bằng cách giảm bớt những rào cản tính toán và tạo điều kiện thuận lợi cho quá trình điều chỉnh mô hình hiệu quả hơn, LoRA đã sẵn sàng đóng một vai trò quan trọng trong việc áp dụng và triển khai rộng rãi hơn của LLMs trong các tình huống thực tế.
QLoRA (Quantized)
Mặc dù LoRA là một biến đổi trò chơi trong việc giảm nhu cầu lưu trữ, nó vẫn đòi hỏi một GPU mạnh để nạp mô hình cho quá trình huấn luyện. Đó là lý do tại sao QLoRA, hoặc Quantized LoRA, ra đời, kết hợp LoRA với Quy tắc hóa để có một cách tiếp cận thông minh hơn.

Thường thì, các tham số trọng số được lưu trữ dưới định dạng 32-bit (FP32), điều này có nghĩa rằng mỗi phần tử trong ma trận chiếm 32 bit bộ nhớ. Hãy tưởng tượng nếu chúng ta có thể nén cùng thông tin vào chỉ 8 hoặc thậm chí 4 bit. Đó là ý tưởng cốt lõi của QLoRA. Quy tắc hóa đề cập đến quá trình ánh xạ các giá trị vô hạn liên tục thành một tập hợp nhỏ hữu hạn giá trị rời rạc. Trong ngữ cảnh của LLMs, nó đề cập đến quá trình chuyển đổi trọng số của mô hình từ các loại dữ liệu có độ chính xác cao sang các loại dữ liệu có độ chính xác thấp hơn.
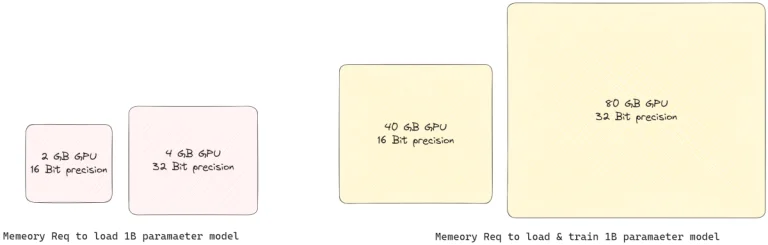
Dưới đây là một cách phân chia đơn giản hơn về QLoRA:
- Quá trình Quy tắc hóa Ban đầu: Trước hết, Mô hình Ngôn ngữ Lớn (LLM) được quy tắc hóa xuống còn 4 bit, giảm đáng kể kích thước bộ nhớ.
- Huấn Luyện LoRA: Sau đó, quá trình huấn luyện LoRA được thực hiện, nhưng với độ chính xác 32-bit tiêu chuẩn (FP32).
Bây giờ, có thể bạn đang tự hỏi, tại sao quay trở lại 32 bit cho quá trình huấn luyện sau khi thu nhỏ xuống còn 4 bit? Thì, để huấn luyện các bộ điều chỉnh LoRA một cách hiệu quả trong định dạng FP32, trọng lượng của mô hình cũng cần phải trở lại dạng FP32. Việc chuyển đổi này được thực hiện theo cách thông minh, từng bước để tránh quá tải bộ nhớ GPU.
LoRA tìm thấy ứng dụng thực tế của nó trong thư viện Parameter Efficient Fine-Tuning (PEFT) của Hugging Face, làm đơn giản hóa việc sử dụng nó. Đối với những người muốn sử dụng QLoRA, nó có thể được truy cập thông qua sự kết hợp của các thư viện bitsandbytes và PEFT. Ngoài ra, thư viện Transformer Reinforcement Learning (TRL) của Hugging Face cung cấp sự hỗ trợ tích hợp cho LoRA trong quá trình điều chỉnh tường tận theo hướng dẫn. Cùng nhau, ba thư viện này cung cấp bộ công cụ cần thiết để điều chỉnh tường tận một mô hình trước đã chọn, giúp tạo ra mô tả sản phẩm thuyết phục và mạch lạc khi được yêu cầu với hướng dẫn thuộc tính cụ thể.
Sau quá trình điều chỉnh từ QLoRA, các trọng số phải trở lại định dạng có độ chính xác cao, điều này có thể dẫn đến mất mát độ chính xác và thiếu tối ưu hóa để tăng tốc quá trình.
Một giải pháp được đề xuất là nhóm ma trận trọng số thành các phần nhỏ hơn và áp dụng quy tắc hóa và phân tách hạng thấp cho từng nhóm một. Một phương pháp mới, có tên QA-LoRA, cố gắng kết hợp những lợi ích của quy tắc hóa và phân tách hạng thấp trong khi vẫn giữ quá trình hiệu quả và mô hình hiệu quả cho các nhiệm vụ mong muốn.
Kết Luận
Trong bài viết này, chúng ta đã đề cập đến những thách thức do kích thước tham số lớn của các mô hình ngôn ngữ lớn (LLMs) mang lại. Chúng ta đã nghiên cứu các phương pháp điều chỉnh truyền thống và các yêu cầu tính toán và tài chính đi kèm. Bản chất của LoRA nằm ở khả năng điều chỉnh các mô hình đã đào tạo trước mà không cần đào tạo lại toàn bộ, từ đó giảm số tham số có thể đào tạo và làm cho quá trình điều chỉnh trở nên hiệu quả về chi phí hơn.
Những chiến lược này được xây dựng để cân bằng giữa việc làm cho LLMs thích nghi với các nhiệm vụ cụ thể và đảm bảo quá trình điều chỉnh và triển khai không quá tải về tài nguyên tính toán và lưu trữ.
Chúng ta cũng đã nhanh chóng tìm hiểu về Quantized LoRA (QLoRA), một sự kết hợp giữa LoRA và Quy tắc hóa giúp giảm bộ nhớ của mô hình trong khi vẫn duy trì độ chính xác cần thiết cho quá trình huấn luyện. Với những kỹ thuật tiên tiến này, các chuyên gia hiện đã có trong tay các thư viện mạnh mẽ, giúp việc áp dụng và triển khai LLMs trở nên dễ dàng hơn trên một loạt các tình huống thực tế.