


Tác giả: Carl Franzen
11 Tháng 12, 2023 6:25 PM
Nhân bản giọng nói là một trong những lĩnh vực nhanh chóng phát triển nhờ vào trí tuệ tạo sinh. Thuật ngữ này đề cập đến việc sao chép những đặc điểm âm thanh của một người, bao gồm cả cường độ, giai điệu, nhịp, cách diễn đạt và cách phát âm riêng biệt, thông qua công nghệ.
Trong khi các công ty khởi nghiệp như ElevenLabs đã nhận được hàng chục triệu đô la để tận dụng vào hướng này, Meta Platforms, công ty mẹ của Facebook, Instagram, WhatsApp và Oculus VR, đã phát hành chương trình nhân bản giọng nói miễn phí của riêng mình, mang tên Audiobox – với một điều kiện nào đó.
Được giới thiệu hôm nay trên trang web của Meta bởi các nhà nghiên cứu làm việc tại phòng lab nghiên cứu trí tuệ nhân tạo của Facebook (FAIR), Audiobox được mô tả là một “mô hình nền tảng nghiên cứu mới cho việc tạo ra âm thanh” được xây dựng dựa trên công việc trước đây trong lĩnh vực này, Voicebox.
“Nó có thể tạo ra giọng nói và hiệu ứng âm thanh bằng cách kết hợp giọng đầu vào và các yêu cầu văn bản ngôn ngữ tự nhiên – giúp dễ dàng tạo ra âm thanh tùy chỉnh cho nhiều trường hợp sử dụng,” đọc trên trang web Audiobox.
Đơn giản chỉ cần nhập một câu bạn muốn giọng nói nhân bản nói, hoặc mô tả một âm thanh bạn muốn tạo ra, và Audiobox sẽ làm phần còn lại. Người dùng cũng có thể ghi âm giọng của họ và nhờ Audiobox nhân bản nó.
Một ‘gia đình’ của trí tuệ nhân tạo tạo ra âm thanh
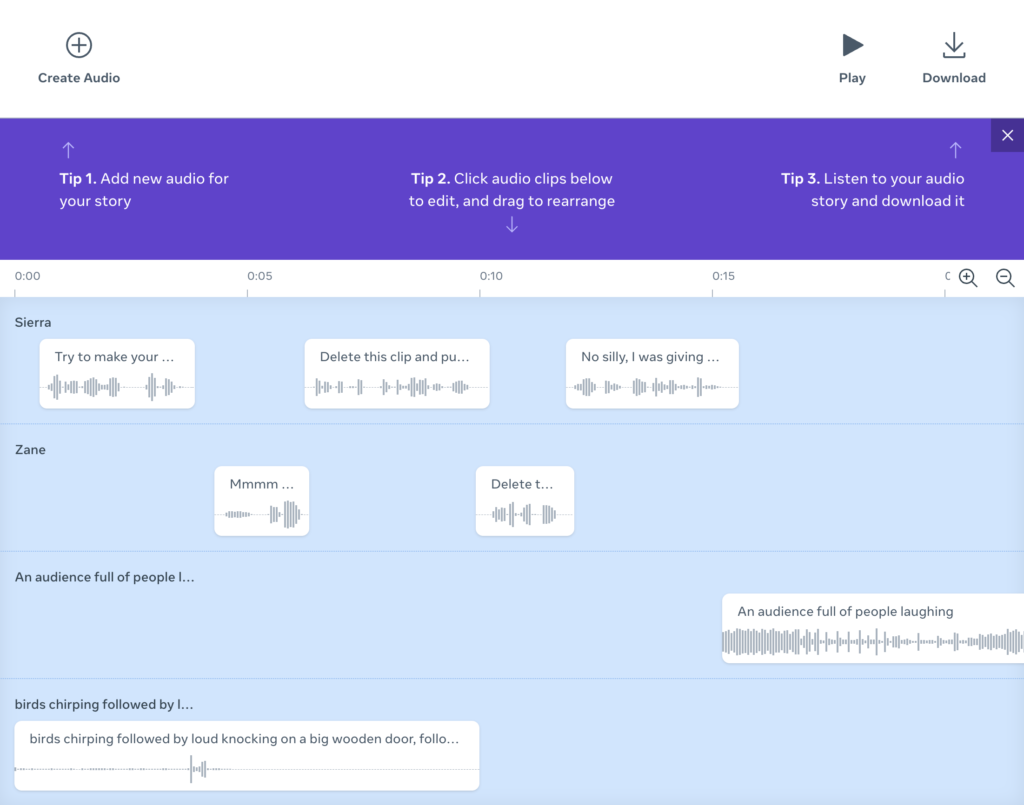
Meta còn chú ý rằng họ thực sự đã tạo ra một “gia đình các mô hình,” một để mô phỏng giọng nói và một để tạo ra âm thanh môi trường và hiệu ứng âm thanh như tiếng chó sủa, còi báo động hoặc tiếng trẻ con đang chơi, và tất cả đều “được xây dựng dựa trên mô hình tự giáo dục chung Audiobox SSL.”
Học tự giáo dục (SSL) là một kỹ thuật học máy (ML) trong lĩnh vực học sâu, trong đó các thuật toán trí tuệ nhân tạo được giao nhiệm vụ tạo ra nhãn cho dữ liệu không được đánh nhãn, so với học giám sát, nơi dữ liệu có thể đã được đánh nhãn trước đó.
Các nhà nghiên cứu đã công bố một bài báo khoa học giải thích một số phương pháp và lý do của họ khi áp dụng phương pháp tự giáo dục, viết rằng “vì dữ liệu có nhãn không phải lúc nào cũng có sẵn hoặc chất lượng cao, và việc mở rộng dữ liệu là chìa khóa để tổng quát hóa, chiến lược của chúng tôi là huấn luyện mô hình nền này bằng âm thanh mà không có bất kỳ sự giám sát nào, như bản trascripts, chú thích hoặc nhãn thuộc tính, có thể tìm thấy nhiều hơn.”
Tất nhiên, hầu hết các mô hình trí tuệ tạo sinh hàng đầu đều phụ thuộc nặng vào dữ liệu do con người tạo ra để huấn luyện cách tạo ra nội dung mới, và Audiobox cũng không nằm ngoại lệ. Các nhà nghiên cứu FAIR đã sử dụng “160,000 giờ nói (chủ yếu là tiếng Anh), 20,000 giờ nhạc và 6,000 giờ mẫu âm thanh.”
“Phần nói bao gồm sách nói, podcast, câu nói đọc, bài giảng, cuộc trò chuyện và các bản ghi tự nhiên bao gồm nhiều điều kiện âm thanh và giọng điệu không từ vựng. Để đảm bảo sự công bằng và một đại diện tốt cho mọi người từ các nhóm khác nhau, nó bao gồm người nói từ hơn 150 quốc gia nói hơn 200 ngôn ngữ chính khác nhau.”
Bài báo nghiên cứu không chỉ rõ nơi dữ liệu này được lấy từ và liệu nó có thuộc phạm vi công cộng hay không, nhưng đó chắc chắn là một câu hỏi quan trọng, với nhiều nghệ sĩ, tác giả và nhà xuất bản âm nhạc đang kiện một loạt các công ty trí tuệ nhân tạo vì huấn luyện trên nội dung có thể thuộc bản quyền mà không có sự đồng ý rõ ràng từ người tạo/ chủ sở hữu quyền. Chúng tôi đã liên hệ với một người phát ngôn của Meta để làm rõ thông tin và sẽ cập nhật khi chúng tôi nhận được câu trả lời.
Bạn có thể thử ngay và nhân bản giọng của mình ngay bây giờ
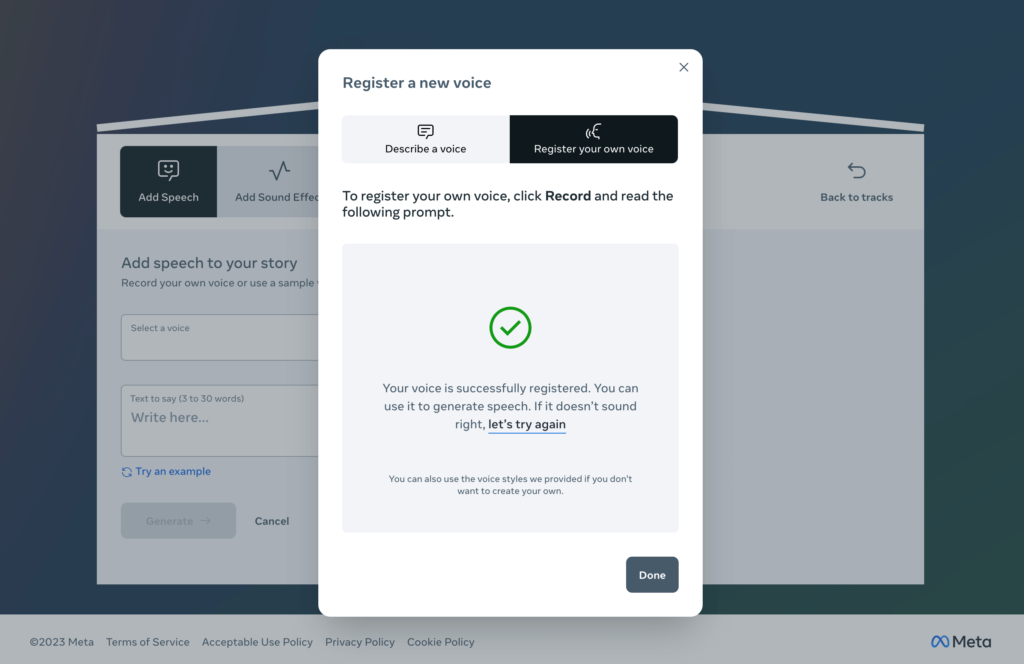
Để trình bày khả năng của Audiobox, Meta cũng đã phát hành nhiều bản demo tương tác, bao gồm một cho phép bạn ghi âm người dùng nói về một đoạn văn và nhân bản giọng của họ.
Sau đó, người dùng có thể nhập văn bản mà họ muốn giọng nhân bản của mình đọc và nghe nó đọc lại với giọng nhân bản của họ.
Bạn có thể tự thử nghiệm tại đây. Trong trường hợp của tôi, âm thanh nhân tạo được tạo ra khá giống, mặc dù không hoàn toàn giống giọng nói của tôi (như được chứng minh bởi vợ và con tôi, người đã nghe mà không biết đó là gì).
Meta cũng cho phép người dùng tạo ra các giọng nói hoàn toàn mới từ mô tả văn bản về cách chúng nên nghe như “giọng nữ sâu” “người nam giọng cao từ Hoa Kỳ” v.v., cũng như làm mới giọng của người dùng hoặc nhập một đoạn văn bản để tạo ra âm thanh mới hoàn toàn. Tôi đã thử nghiệm điều này với “tiếng chó sủa” và nhận được hai phiên bản mà theo ý kiến của tôi không thể phân biệt được với âm thanh thực tế.
Giờ đến phần chính: Meta kèm theo một thông báo từ chối trách nhiệm cho các bản demo tương tác Audiobox, chú ý rằng “đây là một bản demo nghiên cứu và không thể được sử dụng cho bất kỳ mục đích thương mại nào,” và hơn nữa, nó chỉ dành cho những người ở “các tiểu bang Illinois hoặc Texas,” nơi có luật lệ tiểu bang cấm loại thu thập âm thanh mà Meta đang thực hiện cho các bản demo.

Đáng chú ý, giống như ứng dụng web tạo hình Imagine by Meta AI mới của họ được giới thiệu tuần trước, Audiobox cũng không phải là mã nguồn mở, phản đối cam kết của Meta với lĩnh vực này được thể hiện trước đó thông qua việc phát hành dòng mô hình ngôn ngữ lớn Llama 2 (LLMs) của họ. Chúng tôi cũng đã hỏi người liên hệ của chúng tôi tại Meta về điều này và liệu Audiobox có được công bố mã nguồn mở vào một lúc nào đó không, và sẽ cập nhật khi nhận được câu trả lời.
Đúng, hiện tại công nghệ này không thể được sử dụng cho bất kỳ mục đích kiếm lợi/nhãn hàng kinh doanh nào – cũng như không thể được sử dụng bởi cư dân của hai tiểu bang có dân số đông nhất tại Hoa Kỳ – ít nhất là trong thời điểm hiện tại. Tuy nhiên, với tiến triển nhanh chóng của trí tuệ nhân tạo, dự kiến rằng điều này sẽ thay đổi và sẽ xuất hiện các phiên bản thương mại trong tương lai gần, nếu không phải từ Meta thì từ các đơn vị khác.