


Tác giả: Christoph H
27 Tháng 10 năm 2023
Hãy tưởng tượng một chút về một tương lai với các Mô hình Ngôn ngữ Lớn (LLMs) mạnh mẽ và đáng tin cậy, với số lượng trọng số ít hơn và thời gian suy luận nhanh chóng, phù hợp với quy trình sản xuất và được đánh giá một cách kỹ lưỡng.
Hướng tiến đến mục tiêu này không phải là thu thập các bộ dữ liệu càng lớn càng tốt và huấn luyện LLMs với số lượng tham số mô hình càng nhiều. Thú vị thay, hướng tiếp cận “Ít là nhiều” ngược lại lại có triển vọng hơn nhiều. Các kỹ thuật NLP tập trung vào dữ liệu tạo ra bộ dữ liệu chất lượng cao, không chệch và giàu thông tin cho quá trình tiền huấn luyện, điều chỉnh và đồng bộ hóa một cách bán tự động. Ngành công nghiệp NLP tập trung vào dữ liệu phát triển bộ dữ liệu ở quy mô lớn và đặt ưu tiên thấp cho tối ưu hóa mô hình.
Nhưng điều gì làm cho hướng tiếp cận này trở nên quan trọng? Tại sao các đội Data Science và AI nên xem xét nó?
Bài viết này nhằm làm sáng tỏ khái niệm về Trí tuệ Nhân tạo Tập trung vào Dữ liệu, giải thích tại sao nó đang tạo ra một ảnh hưởng đáng kể trong Trí tuệ Nhân tạo Tạo ra và Xử lý Ngôn ngữ Tự nhiên, và làm thế nào bạn có thể triển khai nó một cách thực tế trong dự án của mình. Qua một khám phá rõ ràng và toàn diện, chúng ta sẽ đào sâu vào bản chất của Trí tuệ Nhân tạo Tập trung vào Dữ liệu, mang đến cái nhìn sâu sắc và thông tin quý báu cho cả khán giả kinh doanh và kỹ thuật.
Trí tuệ Nhân tạo Tập trung vào Dữ liệu là gì?
Trí tuệ Nhân tạo Tập trung vào Dữ liệu là một khái niệm đơn giản nhưng mạnh mẽ: chất lượng và sự diễn đạt của dữ liệu của bạn là trung tâm của sự thành công trong các dự án Trí tuệ Nhân tạo. Hãy phân tích điều này thành những thuật ngữ đơn giản hơn.
Trí tuệ Nhân tạo Tập trung vào Dữ liệu là lĩnh vực hệ thống hóa một cách có hệ thống dữ liệu được sử dụng để xây dựng một hệ thống Trí tuệ Nhân tạo.
— Andrew Ng
Để biết thêm chi tiết, hãy xem video “A Chat with Andrew on MLOps: From Model-centric to Data-centric AI DeepLearningAI” trên Youtube.
Trong các dự án Trí tuệ Nhân tạo truyền thống, có nhiều tập trung vào các mô hình và thuật toán. Hãy tưởng tượng mô hình như là động cơ của một chiếc xe. Nhiều công sức được đầu tư để làm cho động cơ này mạnh mẽ và hiệu quả nhất có thể.
Tuy nhiên, trong phương pháp tập trung vào dữ liệu, sự chú ý chuyển sang dữ liệu, mà bạn có thể tưởng tượng như là nhiên liệu cho động cơ. Giống như chiếc xe chạy tốt với nhiên liệu chất lượng cao, một mô hình Trí tuệ Nhân tạo hoạt động hiệu quả hơn với dữ liệu chất lượng cao.
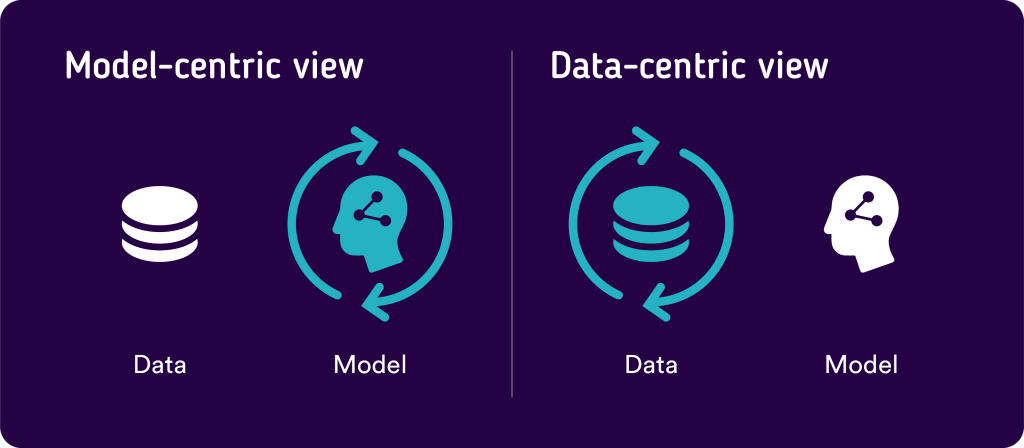
Điều này có nghĩa là thay vì tiêu tốn hầu hết nỗ lực của chúng ta vào việc điều chỉnh động cơ, chúng ta đảm bảo rằng chúng ta đang sử dụng nhiên liệu tốt nhất có sẵn. Theo cách thực tế, điều này bao gồm:
- làm sạch dữ liệu,
- đảm bảo rằng nó liên quan,
- và nó chính xác đại diện cho vấn đề mà chúng ta muốn mô hình giải quyết.
Đối với cả doanh nghiệp và chuyên gia dữ liệu, phương pháp này nhấn mạnh tầm quan trọng của dữ liệu mà bạn đưa vào mô hình Trí tuệ Nhân tạo của mình. Dữ liệu tốt hơn dẫn đến hiệu suất tốt hơn, làm cho các dự án và sản phẩm Trí tuệ Nhân tạo của bạn trở nên thành công và đáng tin cậy hơn.
Tại sao Trí tuệ Nhân tạo Tập trung vào Dữ liệu là Sự Thay Đổi Lớn trong Xử lý Ngôn ngữ Tự nhiên?
Vậy tại sao việc tập trung vào dữ liệu lại quan trọng đến vậy trong Xử lý Ngôn ngữ Tự nhiên (NLP)? Dưới đây, chúng ta sẽ khám phá lý do mà phương pháp này đang tạo sóng và thay đổi cách chúng ta xử lý các dự án Trí tuệ Nhân tạo Tạo ra và Xử lý Ngôn ngữ Tự nhiên.
- Cải Thiện Hiệu Suất Mô Hình: Khi dữ liệu sạch và đại diện, các mô hình Trí tuệ Nhân tạo có thể học các mẫu chung một cách hiệu quả hơn. Trong NLP, điều này có nghĩa là các mô hình có thể hiểu và xử lý ngôn ngữ một cách chính xác và hữu ích hơn.
- Tiết Kiệm Thời Gian và Tài Nguyên: Bằng cách tập trung vào dữ liệu chất lượng, chúng ta có thể tiết kiệm rất nhiều thời gian mà ngược lại sẽ được dành cho việc liên tục điều chỉnh và điều chỉnh các mô hình Trí tuệ Nhân tạo. Điều này làm cho quá trình phát triển trở nên hiệu quả hơn. Hãy xem xét khó khăn của việc thực hiện kiểm thử hồi quy cho LLMs sau khi triển khai lại, để đảm bảo rằng phiên bản mô hình mới ít nhất là tốt như phiên bản trước đó.
- Nâng Cao Khả Năng Thích ứng: Với nền tảng vững chắc từ dữ liệu chất lượng, các mô hình NLP trở nên linh hoạt hơn. Chúng có thể xử lý thông tin mới và thay đổi tốt hơn, làm cho chúng trở nên linh hoạt và đáng tin cậy hơn trong các ứng dụng thực tế. Hãy coi bộ dữ liệu như một cuốn sách giáo trình. Nếu các khái niệm chính được mô tả rõ ràng, có thể “nối các điểm” và đưa ra những ý tưởng mới đầy cảm hứng. Nếu nội dung không liên quan và trùng lặp được hiển thị cho người học, khó có thể phát triển một mô hình tư duy hữu ích của kiến thức để tái kết hợp.
- Hỗ Trợ Quyết Định Tốt Hơn: Trong lĩnh vực kinh doanh, có một mô hình NLP cung cấp kết quả chính xác và đáng tin cậy có nghĩa là người quyết định có thông tin tốt hơn ngay trong tay họ, dẫn đến các quyết định thông tin và hiệu quả hơn.
Đơn giản là, phương pháp Tập trung vào Dữ liệu làm cho bất kỳ dự án NLP nào trở nên mạnh mẽ, hiệu quả, và có khả năng thích ứng – điều quan trọng để đáp ứng các yêu cầu đa dạng và động đặc của các Mô hình Ngôn ngữ Lớn đang ngày càng tăng lên.
Làm thế nào để Thực Hiện Phương Pháp Trí tuệ Nhân tạo Tập trung vào Dữ liệu?
Việc thực hiện một phương pháp Trí tuệ Nhân tạo Tập trung vào Dữ liệu trong các dự án NLP và Trí tuệ Nhân tạo Tạo ra của bạn ở quy mô lớn (với terabytes dữ liệu văn bản) có thể trông đáng sợ, nhưng không nhất thiết phải như vậy. Dưới đây là một số bước thực tế và những cái nhìn để hướng dẫn bạn qua quá trình này.
1. Thu Thập và Tổ Chức Dữ Liệu
- Tập trung vào chất lượng: Cố gắng thu thập dữ liệu chất lượng cao và liên quan từ đầu. Đảm bảo rằng dữ liệu đại diện cho các tình huống thực tế mà bạn muốn mô hình của mình xử lý. Điều này sẽ mang lại lợi ích lâu dài.
- Chú ý đến việc tổ chức: Tổ chức dữ liệu một cách có cấu trúc, làm cho nó dễ dàng truy cập và sử dụng trong quá trình huấn luyện mô hình.
2. Làm Sạch Dữ Liệu
- Loại bỏ dữ liệu không liên quan: Không phải tất cả dữ liệu được thu thập sẽ hữu ích. Xác định và loại bỏ thông tin không đóng góp vào quá trình học của mô hình.
- Xử lý dữ liệu thiếu: Quyết định cách xử lý những khoảng trống trong dữ liệu, liệu có xóa các trường hợp đó hay điền vào chúng một cách hợp lý.
3. Chú Thích Dữ Liệu
- Áp dụng chiến lược gán nhãn: Nếu dự án của bạn đòi hỏi dữ liệu đã được gán nhãn, đảm bảo rằng việc đánh nhãn là chính xác và nhất quán.
- Sử dụng công cụ và dịch vụ: Xem xét việc sử dụng các công cụ và dịch vụ có sẵn có thể hỗ trợ trong quá trình chú thích dữ liệu, giúp làm cho nó hiệu quả hơn.
4. Cải Thiện Liên Tục
- Thực hiện các vòng lặp phản hồi: Thiết lập cơ chế phản hồi để liên tục cải thiện và làm tinh chỉnh dữ liệu và mô hình của bạn.
- Cập nhật kiến thức: Yêu cầu về dữ liệu có thể thay đổi theo thời gian. Cập nhật thông tin về các xu hướng và thực hành tốt nhất mới nhất trong Trí tuệ Nhân tạo Tập trung vào Dữ liệu để duy trì việc cải thiện quy trình của bạn.
Việc áp dụng một phương pháp Trí tuệ Nhân tạo Tập trung vào Dữ liệu là về việc tập trung vào dữ liệu như một thành phần chính trong sự thành công của các dự án và sản phẩm Trí tuệ Nhân tạo của bạn. Với dữ liệu chất lượng và cách tiếp cận đúng, bạn có thể cải thiện hiệu suất và độ tin cậy của mô hình Trí tuệ Nhân tạo của mình, đảm bảo thành công của các dự án của bạn.
Triển vọng Tương lai của Trí tuệ Nhân tạo Tập trung vào Dữ liệu trong Trí tuệ Nhân tạo Tạo ra và Xử lý Ngôn ngữ Tự nhiên
Nhìn về tương lai, việc tập trung vào Trí tuệ Nhân tạo Tập trung vào Dữ liệu đang được dự định tiếp tục định hình hướng phát triển của Trí tuệ Nhân tạo Tạo ra, Xử lý Ngôn ngữ Tự nhiên và các đổi mới và ứng dụng của Mô hình Ngôn ngữ Lớn. Dưới đây là một cái nhìn sơ bộ về những gì tương lai có thể mang lại khi phương pháp này trở nên tích hợp sâu rộng hơn vào các dự án Trí tuệ Nhân tạo.
1. Hiệu Suất Mô Hình Nâng Cao & Độ Trễ Suy Luận Thấp
Khi ngày càng nhiều dự án áp dụng phương pháp Tập trung vào Dữ liệu, chúng ta có thể kỳ vọng thấy sự cải thiện trong cách mà các mô hình Xử lý Ngôn ngữ Tự nhiên và Mô hình Ngôn ngữ Lớn thực hiện, làm cho chúng trở nên chính xác và hiệu quả hơn trong các ứng dụng khác nhau. Các mô hình nhỏ hơn có thể vượt trội so với các mô hình lớn và dẫn đến độ trễ suy luận thấp, khả năng bảo trì tốt hơn và giảm chi phí triển khai.
2. Ứng Dụng Rộng Rãi Hơn
Với chất lượng dữ liệu cải thiện, các mô hình Xử lý Ngôn ngữ Tự nhiên có thể được áp dụng trong nhiều lĩnh vực đa dạng hơn, mở rộng tính hữu ích và tác động của chúng trên nhiều ngành và lĩnh vực khác nhau.
3. Cải Thiện Sự Hợp Tác
Sự tập trung vào dữ liệu có thể tạo điều kiện cho sự hợp tác tốt hơn giữa các bên liên quan kỹ thuật và không kỹ thuật, vì nó cho phép hiểu rõ hơn và đồng thuận về mục tiêu và kết quả của dự án.
4. Trí Tuệ Nhân tạo Đạo Đức và Trách Nhiệm
Một phương pháp tập trung vào dữ liệu thúc đẩy việc xem xét các hệ quả đạo đức, khuyến khích sự phát triển của các mô hình Xử lý Ngôn ngữ Tự nhiên có trách nhiệm hơn và nhạy cảm hơn với tác động của xã hội. Tuân thủ quy định và an toàn Trí tuệ Nhân tạo được đảm bảo nếu tuân thủ đã xảy ra ở cấp độ bộ dữ liệu đào tạo. Điều này có thể giảm bớt công sức của việc kiểm soát nội dung sau khi mô hình được triển khai.
5. Học Liên Tục và Khả Năng Thích ứng
Đặt trọng điểm vào dữ liệu có thể dẫn đến các mô hình có khả năng học và thích ứng tốt hơn theo thời gian, làm cho chúng mạnh mẽ hơn và có khả năng xử lý các thách thức mới và thay đổi trong ngôn ngữ.
Nói một cách khác: tương lai của Trí tuệ Nhân tạo Tập trung vào Dữ liệu trong Xử lý Ngôn ngữ Tự nhiên trông đầy hứa hẹn, với tiềm năng cho nhiều đổi mới và cải thiện sẽ thúc đẩy thành công trong các dự án và ứng dụng khác nhau. Đây là một hành trình không ngừng phát triển mang theo hứa hẹn làm cho Trí tuệ Nhân tạo Tạo ra, Xử lý Ngôn ngữ Tự nhiên và Mô hình Ngôn ngữ Lớn trở nên mạnh mẽ, linh hoạt và điều chỉnh với nhu cầu và thách thức thực tế của doanh nghiệp.
Trí tuệ Nhân tạo Tập trung vào Dữ liệu – Những điểm Quan trọng
Điều hướng qua những phức tạp của Trí tuệ Nhân tạo Tạo ra và Xử lý Ngôn ngữ Tự nhiên có thể là một hành trình rất khó khăn. Tuy nhiên, việc áp dụng một phương pháp tập trung vào dữ liệu có tiềm năng trở thành một chiến lược biến đổi cải thiện hiệu suất, tính linh hoạt và thành công của các dự án Trí tuệ Nhân tạo của bạn. Bạn hiện đã có kiến thức cơ bản và hướng dẫn hành động về các khái niệm quan trọng, cái nhìn thực tế và triển vọng tương lai của Trí tuệ Nhân tạo Tập trung vào Dữ liệu.
Khi chúng ta đứng trước ngưỡng cửa của các khả năng và đổi mới mới trong Xử lý Ngôn ngữ Tự nhiên, việc om sòm các thực hành tập trung vào dữ liệu mở ra một cơ hội hấp dẫn để thúc đẩy tiến triển và đạt được các kết quả đáng chú ý. Để có một sự khám phá sâu rộ hơn và cái nhìn toàn diện vào việc tối đa hóa tiềm năng của Trí tuệ Nhân tạo Tập trung vào Dữ liệu trong Trí tuệ Nhân tạo Tạo ra và Xử lý Ngôn ngữ Tự nhiên, chúng tôi mời bạn tải về bản toàn bộ của bài báo trắng của chúng tôi về chủ đề này.
White-Paper-Data-centric-AI-for-NLP-PTC-by-CBTW