

Tạo nên một mô hình ngôn ngữ lớn độc lập hoạt động trong tổ chức quả là một câu chuyện tốn kém so với tác động mà chúng có thể mang lại trong tổ chức vì vậy sau một thời gian cố gắng xây dựng và duy trì thì chúng ta cũng lại chứng kiến một cuộc dịch chuyển sang sử dụng mô hình của các nhà cung cấp dịch vụ lớn có tầm hoạt động toàn cầu.
Các công ty như OpenAI, Google, Cohere và Anthropic hiện đang thống trị thị trường LLM toàn cầu mới nổi này với các nhiệm vụ Xử lý ngôn ngữ tự nhiên (NLP) trên toàn thế giới.
Cùng với đó, các API nhúng văn bản mang tính đột phá, then chốt cho nhiều ứng dụng khác nhau, đã xuất hiện; và chúng ta đang chứng kiến cuộc chiến giữa những gã khổng lồ nhằm cung cấp dịch vụ nhúng đa ngôn ngữ tốt nhất.
Microsoft đã thực hiện một cách tiếp cận độc đáo bằng cách cung cấp nguồn mở cho mô hình nhúng đa ngôn ngữ có tên E5, từ đó tăng sự quyết liệt trong cạnh tranh này. Và Học viện Trí tuệ nhân tạo Bắc Kinh gần đây đã tiết lộ một mô hình đa ngôn ngữ nguồn mở cạnh tranh mới được gọi là BGE-M3.
Là một Kỹ sư Máy học giàu kinh nghiệm chuyên phát triển sản phẩm để sử dụng đa ngôn ngữ, tôi thấy những tiến bộ này đặc biệt thú vị và đã quyết định so sánh những tiến bộ tiên tiến nhất trong lĩnh vực này.
Hôm nay, tôi sẽ trình bày bản phân tích hiệu suất độc lập của các mô hình nhúng đa dạng, tập trung vào tính hiệu quả của chúng trên các truy vấn bằng nhiều ngôn ngữ.
Sự so sánh này bao gồm các nền tảng hàng đầu OpenAI, Google và Cohere, cùng với các mô hình nguồn mở hoạt động tốt nhất, để làm nổi bật sức mạnh tương đối của chúng trong bối cảnh AI đang phát triển nhanh chóng!

Các mô hình so sánh
Tôi đã đưa vào các mô hình nổi bật nhất để so sánh – nguồn đóng và nguồn mở. Dưới đây là tổng quan về các mô hình khác nhau cùng với các ví dụ về cách tôi sử dụng chúng.
OpenAI Embeddings
OpenAI cung cấp API nguồn đóng để nhúng văn bản đa ngôn ngữ.
Mô hình nhúng mới nhất của họ là text-embedding-3-large được phát hành vào ngày 25 tháng 1 năm 2024, vốn đã hỗ trợ đa ngôn ngữ và hỗ trợ các kích thước 256, 1024 và 3072 chiều.
Theo mặc định, text-embedding-3-large trả về việc nhúng với 3072 chiều.
Cách sử dụng ví dụ:từ openai import OpenAI
from openai import OpenAI
import os
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY", "")
openai_client = OpenAI(api_key=OPENAI_API_KEY)
def openai_embed(query: str, model="text-embedding-3-large"):
query = query.replace("\n", " ")
response = openai_client.embeddings.create(input=[query], model=model)
embedding = response.data[0].embedding
return embedding
# Example usage (3072 dimensions)
embeddings = openai_embed("This is a text I want to embed")Xem tài liệu: chi tiết
Tài liệu API: xem chi tiết
Cohere Embeddings
Cohere cung cấp API nguồn đóng để nhúng văn bản đa ngôn ngữ.
Mô hình nhúng mới nhất embed-multilingual-v3.0 của họ được phát hành vào ngày 2 tháng 11 năm 2023, nó hỗ trợ đa ngôn ngữ và trả về đối tượng nhúng với 1024 chiều.
Ví dụ sử dụng:
import cohere
COHERE_API_KEY = os.environ.get("COHERE_API_KEY", "")
cohere_client = cohere.Client(COHERE_API_KEY)
def cohere_embed(query: str, model="cohere-embed-multilingual-v3.0"):
response = cohere_client.embed(
texts=[query],
input_type="search_query",
model="embed-multilingual-v3.0"
)
embedding = response.embeddings[0]
return embedding
# Example usage (1024 dimensions)
embeddings = cohere_embed('This is a text I want to embed')Xem tài liệu: xem chi tiết
Google Embeddings
Google cung cấp API nguồn đóng để nhúng văn bản đa ngôn ngữ.
Mô hình nhúng mới nhất của họ text-multilingual-embedding-preview-0409 đã được phát hành để xem trước vào ngày 2 tháng 4 năm 2024, nó hỗ trợ đa ngôn ngữ và trả về một nội dung đối tượng nhúng có 768 chiều.
Phiên bản này là một cải tiến so với mô hình nhúng trước đó từ dòng gecko textembedding-gecko-multilingual@001.
Ví dụ sử dụng:
from vertexai.preview.language_models import TextEmbeddingModel
def google_embed(query: str):
embedder_name = "text-multilingual-embedding-preview-0409"
model = TextEmbeddingModel.from_pretrained(embedder_name)
embeddings_list = model.get_embeddings([query])
embeddings = embeddings_list[0].values
return embeddings
# Example usage (768 dimensions)
embeddings = google_embed("This is a text I want to embed")Liên kết tới tài liệu: xem chi tiết
E5 của Microsoft
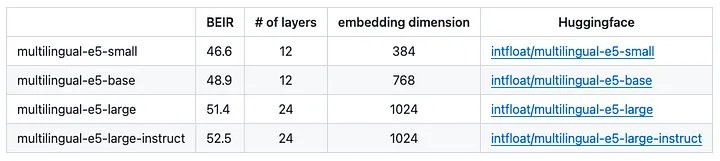
Multilingual E5 là mô hình nhúng đa ngôn ngữ mã nguồn mở được tạo ra bởi nhóm nghiên cứu của Microsoft.
Bản phát hành đầu tiên bao gồm ba mô hình nhúng – nhỏ, cơ sở và lớn; Mặc dù phiên bản hướng dẫn đã được phát hành vào đầu năm 2024. Xem các kích thước nhúng bên dưới:
Ví dụ sử dụng:
from sentence_transformers import SentenceTransformer
def e5_embed(query: str, model: str):
if model not in ['large', 'base', 'small', 'large-instruct']:
raise ValueError(f'Invalid model name {model}')
embedder = SentenceTransformer(f'intfloat/multilingual-e5-{model}')
if model == 'large-instruct':
task = 'Given a short informative text, retrieve relevant topics'
query = f'Instruct: {task}\nQuery: {query}'
embeddings = embedder.encode(sentences=[query], convert_to_tensor=False, normalize_embeddings=True)
return embeddings
# Example usage (768 dimensions)
embeddings = e5_embed('This is a text I want to embed', model='base')Xem báo cáo kỹ thuật: https://arxiv.org/pdf/2402.05672.pdf
Kho Github: https://github.com/microsoft/unilm/tree/master/e5
BGE-M3
BGE-M3 là mô hình nhúng đa ngôn ngữ nguồn mở được tạo ra bởi Học viện Trí tuệ nhân tạo Bắc Kinh.
Mô hình nhúng mới nhất BGE-M3 của họ được phát hành vào ngày 30 tháng 1 năm 2024, nó đa ngôn ngữ và trả về đối tượng nhúng với kích thước 1024 chiều.
M3 là viết tắt từ 3 chữ đầu của Multi với nội dung bao gồm ngôn ngữ (hơn 100 ngôn ngữ), chi tiết (độ dài đầu vào lên tới 8192), chức năng (thống nhất truy xuất dày đặc, từ vựng, đa vec (colbert)) [ nguồn ].
Cách sử dụng ví dụ:
from FlagEmbedding import BGEM3FlagModel
def bge_m3_embed(query: str):
# Can add "use_fp16=True" to speed up predictions
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=False)
embeddings = model.encode([query])['dense_vecs'][0]
return embeddings
# Example usage (1024 dimensions)
embeddings = bge_m3_embed("This is a text I want to embed")Xem báo cáo kỹ thuật: https://arxiv.org/pdf/2402.03216.pdf
Cách đánh giá chất lượng các mô hình nhúng
Mục đích của việc nhúng câu là gói gọn ý nghĩa ngữ nghĩa của toàn bộ câu thành các biểu diễn vectơ, chuyển đổi hiệu quả các từ và ý nghĩa ngữ cảnh của chúng thành dạng số mà máy tính có thể hiểu được.
Về bản chất, phần nhúng chỉ là cách biểu diễn số của các câu, trong đó các câu có ý nghĩa tương tự nhau được đặt gần nhau trong không gian vectơ.
Điều này có nghĩa là chúng ta có thể đánh giá chất lượng của một mô hình nhúng bằng cách nhúng các câu tương tự về ý nghĩa ngữ nghĩa của chúng và đo lường mức độ liên quan giữa các phần nhúng này với nhau.
Để minh họa khái niệm này, chúng ta hãy xem xét hai câu sau:
- “Hôm nay trời lạnh và nhiều gió.”
- “Đó là một ngày lạnh và nhiều gió.”
Cả hai câu đều truyền đạt một ý nghĩa rất giống nhau bằng cách mô tả điều kiện thời tiết lạnh và có gió. Lý tưởng nhất là việc nhúng hai câu này sẽ tạo ra các vectơ rất giống nhau.
Để hiểu tính hiệu quả hoặc chất lượng của các phần nhúng này, điều quan trọng là phải xem xét cách chúng ta có thể đo khoảng cách hoặc độ tương tự giữa chúng, đó là lúc các hàm khoảng cách phát huy tác dụng.
Có vô số hàm khoảng cách mà chúng ta có thể sử dụng, mỗi hàm phục vụ mục đích riêng của nó.
Dưới đây là danh sách một số hàm khoảng cách được sử dụng rộng rãi nhất:
- Euclide: Tính khoảng cách đường thẳng giữa hai điểm trong không gian vectơ. Nó nhạy cảm với độ lớn của vectơ, với khoảng cách nhỏ hơn biểu thị độ tương tự lớn hơn.
- Manhattan: Tính khoảng cách giữa hai tọa độ bằng cách di chuyển theo lưới thẳng (không phải đường đi nhanh nhất). Nó được tính bằng cách tính tổng sự khác biệt tuyệt đối của tọa độ trong mỗi chiều.
- Cosine: Tính cosin của góc giữa hai vectơ, tập trung vào hướng hơn là độ lớn. Đó là giải pháp lý tưởng để đánh giá sự tương đồng về ngữ nghĩa trong văn bản vì nó đánh giá tính định hướng của các phần nhúng. Giá trị gần bằng 1 biểu thị mức độ tương tự cao. Các giá trị gần bằng 0 hoặc âm biểu thị mức độ tương đồng thấp hoặc không có sự tương đồng, với các giá trị âm cho thấy ý nghĩa trái ngược nhau.
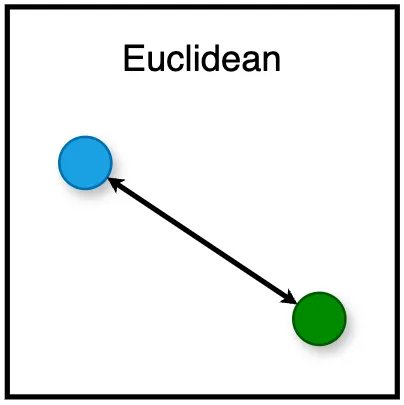
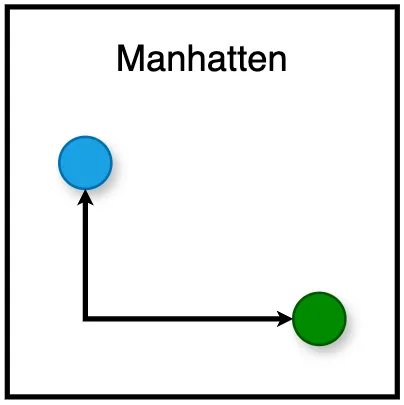
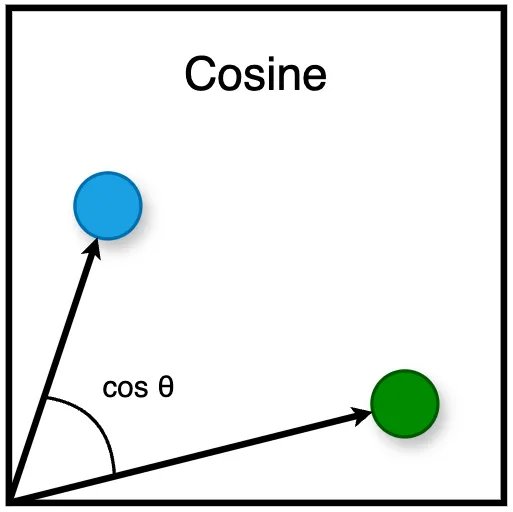
Mặc dù khoảng cách Euclide ban đầu có vẻ như là sự lựa chọn hợp lý nhất, nhưng nó phải đối mặt với những thách thức đáng kể trong không gian nhiều chiều. Khó khăn này nảy sinh từ một hiện tượng được gọi là “lời nguyền của đa hướng”.
Để đo độ tương tự về ngữ nghĩa giữa dữ liệu văn bản, độ tương tự cosine thường là phương pháp được ưa thích trong số ba phương pháp, chủ yếu là do tính độc lập của nó với độ lớn vectơ.
Ưu điểm này xuất phát từ thực tế là độ tương tự cosine tính toán cosin của góc giữa hai vectơ, tập trung vào hướng mà vectơ chỉ chứ không phải độ dài của chúng.
Độ tương tự cosine chuẩn hóa một cách hiệu quả cho độ lớn vectơ, khiến nó đặc biệt phù hợp để so sánh các văn bản có độ dài và mật độ nội dung khác nhau.
Do đó, đánh giá của chúng tôi sẽ sử dụng độ tương tự cosine để đánh giá hiệu suất của các phần nhúng mà chúng ta tạo ra.
Chúng tôi sẽ chuyển một loạt câu bằng nhiều ngôn ngữ đến mô-đun đánh giá của mình để xác định mô hình nhúng mang lại hiệu suất tốt nhất – nghĩa là mô hình nắm bắt chính xác nhất các mối quan hệ ngữ nghĩa trong các ngữ cảnh ngôn ngữ khác nhau.
Tập dữ liệu đánh giá
Tôi đã tạo một tập dữ liệu chủ đề mà chúng tôi có thể sử dụng để đánh giá.
Bộ dữ liệu bao gồm 200 câu được phân loại theo 50 chủ đề khác nhau (một số trong đó có liên quan chặt chẽ với nhau).
Dưới đây là một số ví dụ từ tập dữ liệu:
- Sailing and boating: Many people find solace in the peacefulness of being out on the water.
- The global economy: Trade tensions between major economies continue to impact global markets.
- The US stock market: Wall Street’s indices reflect the pulse of American corporate and economic health.
- Book reviews: Discover the latest book reviews on bestsellers and hidden gems.
- Religion and spirituality: Many people find comfort and guidance in their religious beliefs.
- AI for coding and software development: The use of AI in software development is revolutionizing the industry.
Tôi đã sử dụng GPT4 để dịch tập dữ liệu sang nhiều ngôn ngữ: tiếng Anh, tiếng Tây Ban Nha, tiếng Pháp, tiếng Đức, tiếng Nga, tiếng Hà Lan, tiếng Bồ Đào Nha, tiếng Na Uy, tiếng Thụy Điển, tiếng Phần Lan.
Dataset đầy đủ về dữ liệu sử dụng cho đánh giá: tập dữ liệu.
Đánh giá dựa trên thứ hạng – Top N
Trước khi trình bày kết quả cuối cùng từ đánh giá của mình, các số liệu được hiển thị phải được giải thích rõ ràng.
Đường cong Đặc tính đối sánh tích lũy (Cumulative Match Characteristic – CMC) là một cách trực quan đẹp mắt để hiển thị mức độ hoạt động của mô hình nhúng trong nhiều tình huống.
Đường cong này là công cụ thể hiện khả năng dự đoán của mô hình (trong trường hợp này là phần nhúng phù hợp với một truy vấn nhất định) sẽ nằm trong các kết quả được xếp hạng N hàng đầu.
Hãy xem xét một ví dụ trong đó bạn được cung cấp 200 câu và được giao nhiệm vụ xếp hạng 50 chủ đề dựa trên mức độ liên quan của chúng với từng câu.
Chúng ta có thể đánh giá độ chính xác bằng cách quan sát thứ hạng được gán cho đúng chủ đề. Dự đoán đặt đúng chủ đề ở cấp 1 thể hiện độ chính xác xếp hạng tuyệt vời, trong khi dự đoán đặt đúng chủ đề ở cấp 50 thể hiện hiệu suất kém nhất có thể.
Chúng ta có thể lặp lại trên N trong đó 1 ≤ N ≤ 50 để tính xác suất dự đoán một chủ đề chính xác trong N chủ đề phù hợp nhất.
Để áp dụng điều này vào thực tế, hãy xem xét việc triển khai ví dụ sau bằng Python:
for N in range(1, 51): # Starts at 1, goes up to and includes 50
correct_topics = []
for query, target_topic in zip(queries, topics):
sim = cosine_similarity(query, topics)
sim_sorted_idx = sim.argsort()
topics_ordered = [topics[i] for i in sim_sorted_idx]
top_N = topics_ordered[-N:]
correct_topics.append(1 if target_topic in top_N else 0)
CMC_score = round(sum(correct_topics) / len(correct_topics), 3)
print(f"Top {N} CSC_score: {CMC_score}")Trong mã này, queries đại diện cho các câu của chúng tôi và topics đại diện cho các chủ đề tiềm năng mà mỗi câu có thể liên quan đến. Hàm này cosine_similarity đo lường sự giống nhau giữa mỗi câu và các chủ đề có thể có. Đối với mỗi N trong phạm vi được chỉ định, chúng tôi tính điểm từ 0 đến 1, trong đó 1 biểu thị đủ độ chính xác trong việc dự đoán chủ đề mục tiêu trong N kết quả phù hợp hàng đầu.
Để minh họa Đặc điểm đối sánh tích lũy trông như thế nào, chúng ta hãy xem một ví dụ về multilingual-e5-small cho tiếng Thụy Điển:
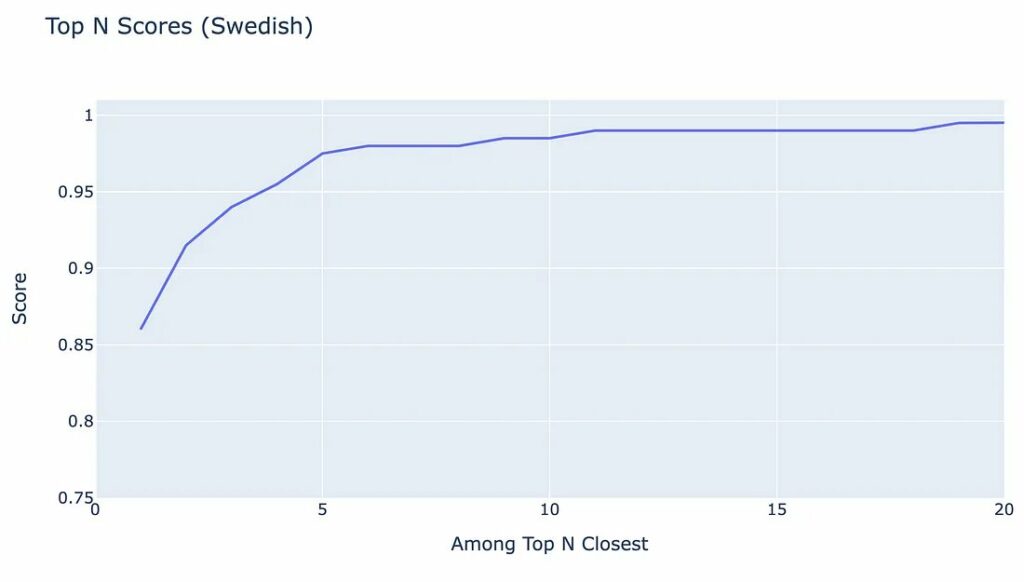
Như chúng ta có thể thấy từ biểu đồ, khoảng 95% câu có chủ đề chính xác được xếp hạng trong 4 vị trí hàng đầu – vì đường màu xanh lam vượt quá 0,95 khi N=4.
Như bạn có thể đã hiểu, độ chính xác chỉ có thể cải thiện đối với các giá trị N lớn hơn (vì nó làm tăng cơ hội chứa chủ đề mục tiêu).
Chúng ta có thể mở rộng sơ đồ này bằng cách thêm multilingual-e5-large, đây sẽ là một mô hình hoạt động tốt hơn.
Hãy xem nó trông như thế nào:
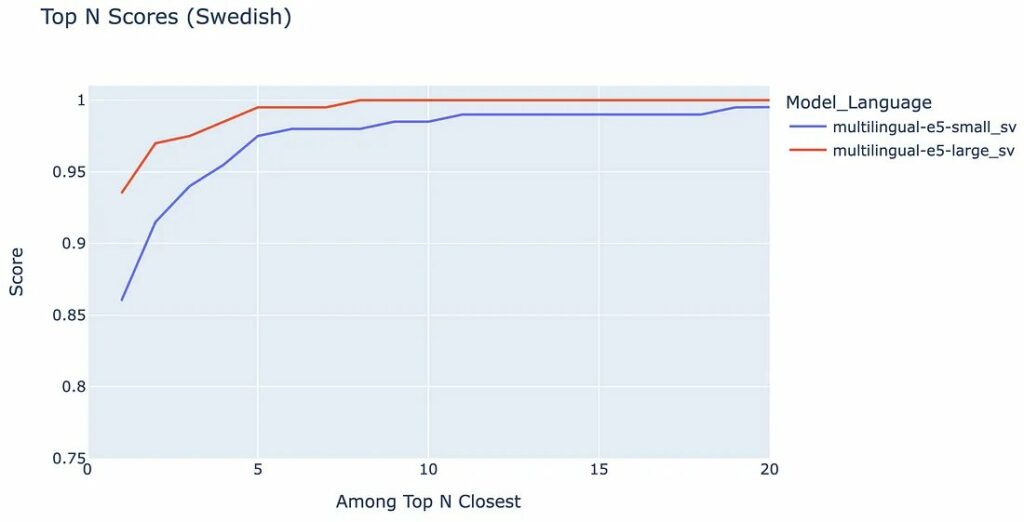
Đúng như mong đợi, multilingual-e5-large (đường màu đỏ) nằm trên đa ngôn ngữ-e5-nhỏ (đường màu xanh) – biểu thị hiệu suất tốt hơn cho tất cả các giá trị của N.
Đánh giá tỷ lệ lỗi
Ngoài đường cong CMC, chúng ta có thể hình dung biểu đồ thanh về tỷ lệ thành công bằng cách tính Độ chính xác trung bình trung bình (MAP) .
Tuy nhiên, để trực quan hóa Tỷ lệ lỗi, chúng tôi có thể tính toán nghịch đảo của MAP, Độ chính xác trung bình nghịch đảo (IMAP), về cơ bản cung cấp cho chúng tôi số liệu tập trung vào các lỗi do mô hình tạo ra, thay vì thành công của nó.
IMAP đương nhiên là một con số nhỏ vì hiệu suất trung bình của tất cả các giá trị có thể có của N gần bằng 1. Chúng ta có thể chia tỷ lệ lỗi theo hệ số 1000 để chia tỷ lệ thành một con số dễ hiểu hơn – giúp việc so sánh dễ dàng hơn.
IMAP được tính như sau:
MAP = avg(cmc_score)
scale_rate = 1000 # For easier comparison of numbers
IMAP = (1 - MAP) * scale_rate # Also known as "error rate"Hãy nhớ rằng khi hiển thị tỷ lệ lỗi, các giá trị gần bằng 0 biểu thị hiệu suất tốt hơn.
Để minh họa Độ chính xác trung bình nghịch đảo trông như thế nào, chúng ta hãy xem lại ví dụ của chúng tôi với multilingual-e5-small và multilingual-e5-large cho tiếng Thụy Điển:
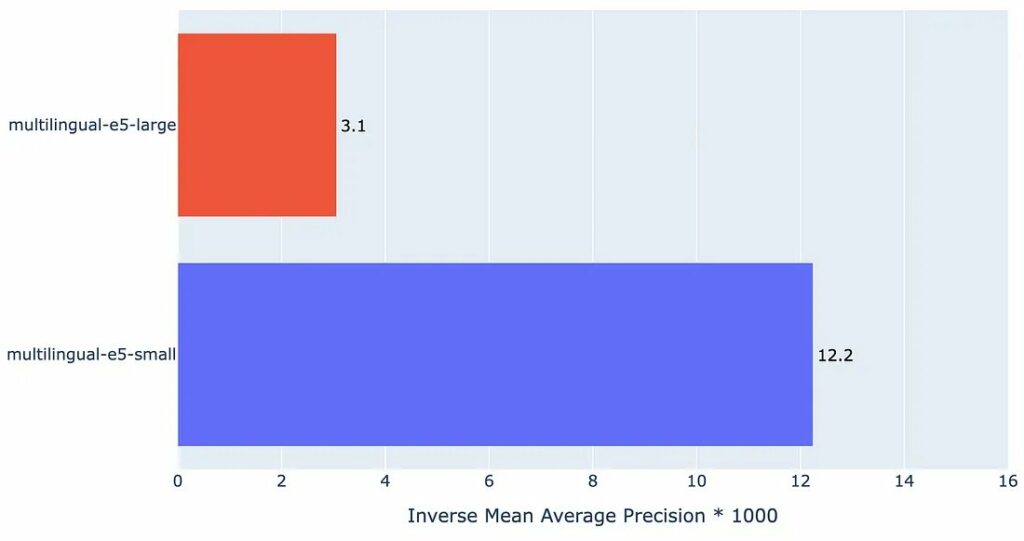
Như chúng ta có thể thấy, biểu đồ hiển thị lỗi tích lũy của từng mô hình nhúng. Đúng như dự đoán, multilingual-e5-large có tỷ lệ lỗi thấp hơn so với người anh em multilingual-e5-small – cho thấy rằng multilingual-e5-large là mô hình tổng thể tốt hơn cho tiếng Thụy Điển.
Bây giờ chúng ta đã hiểu hai số liệu CMC và IMAP, hãy chuyển sang phần kết quả.
Kết quả
Chúng tôi tiếp tục tiến hành kiểm tra trải rộng trên nhiều ngôn ngữ (tiếng Anh, tiếng Tây Ban Nha, tiếng Pháp, tiếng Đức, tiếng Nga, tiếng Hà Lan, tiếng Bồ Đào Nha, tiếng Na Uy, tiếng Thụy Điển và tiếng Phần Lan).
Nghiên cứu này sử dụng các đường cong Đặc điểm đối sánh tích lũy và tỷ lệ Độ chính xác trung bình nghịch đảo như được mô tả trong các phần trước, đây là các phương pháp để đo lường mức độ hoạt động của các mô hình của chúng tôi.
Hãy xem xét các số liệu này khi chúng tôi tính trung bình chúng trên tất cả các ngôn ngữ!
Đặc tính đối sánh tích lũy (CMC)
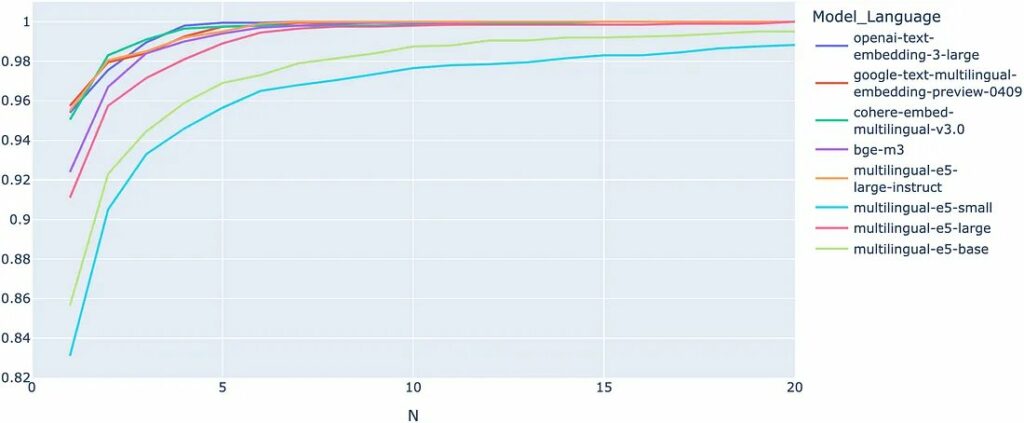
Đường cong CMC cao hơn cho thấy hiệu suất vượt trội. Như chúng ta có thể rút ra từ biểu đồ, có sự phân biệt rõ ràng giữa các mô hình nhúng hoạt động kém nhất và mô hình nhúng tốt nhất.
Bây giờ, hãy kết hợp các điểm từ biểu đồ cho tất cả các giá trị của N và tính IMAP (tỷ lệ lỗi).
Độ chính xác trung bình nghịch đảo (Tỷ lệ lỗi)
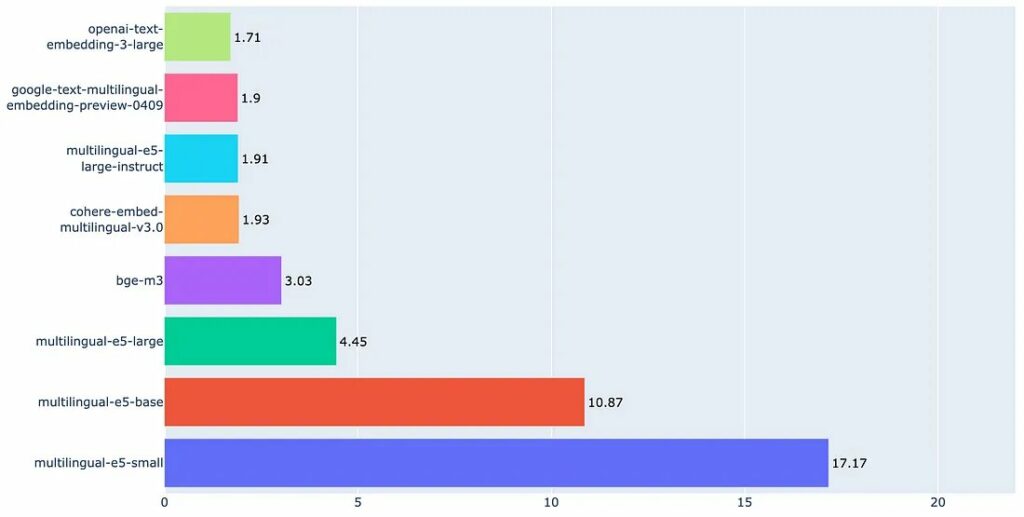
Để có thêm thông tin chi tiết và có khả năng hình dung được những điểm bất thường, chúng ta cũng hãy trực quan hóa tỷ lệ lỗi trên mỗi ngôn ngữ.
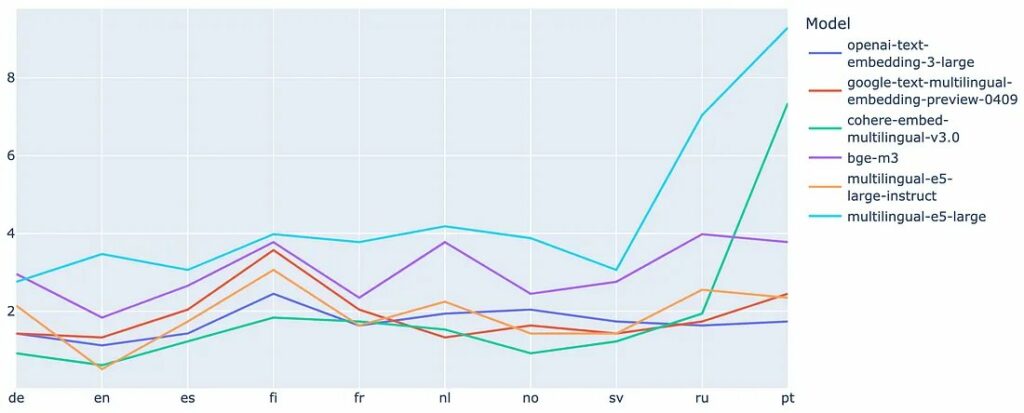
Độ chính xác trung bình nghịch đảo (Tỷ lệ lỗi) trên mỗi ngôn ngữ
Diễn giải chung
Cuộc kiểm của chúng tôi tìm cách xác định mô hình nhúng hàng đầu trong số các ngôn ngữ đã chọn.
Ban đầu, chúng tôi nhận thấy rằng OpenAI, Google, E5-Instruct và Cohere nổi bật so với đối thủ, trong đó OpenAI dẫn trước một chút do tỷ lệ lỗi trung bình thấp hơn trên tất cả các ngôn ngữ.
Khi xem xét kỹ hơn cách biểu diễn ngôn ngữ của từng cá nhân, câu chuyện trở nên phức tạp hơn.
Cohere nổi lên như mô hình hàng đầu ở một số ngôn ngữ, vượt trội hơn những ngôn ngữ khác ở một nửa số ngôn ngữ được thử nghiệm. Tuy nhiên, nó hoạt động kém hơn đáng kể ở tiếng Bồ Đào Nha, điều này dẫn đến cái nhìn rộng hơn về tính nhất quán của các màn trình diễn mẫu.
Dưới đây là ảnh chụp nhanh về mô hình hoạt động tốt nhất cho mỗi ngôn ngữ:
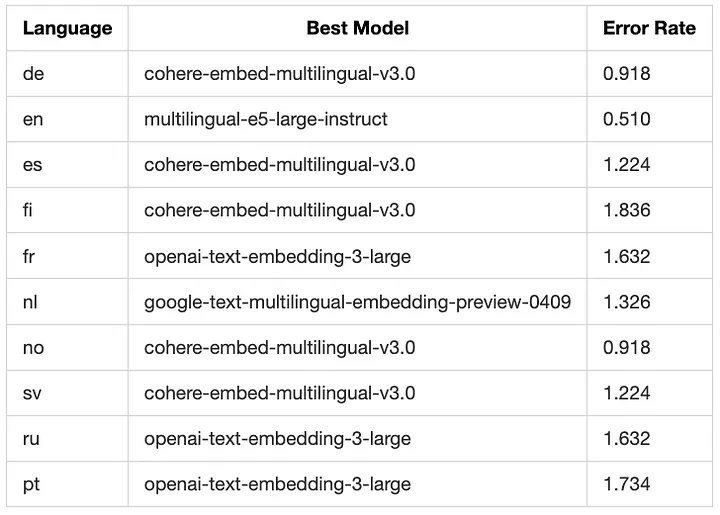
Mặc dù Cohere hoạt động tốt ở một số ngôn ngữ nhất định nhưng mô hình nhúng đa ngôn ngữ tối ưu sẽ hiển thị kết quả nhất quán trên nhiều ngôn ngữ khác nhau.
OpenAI minh họa tính nhất quán này với hiệu suất ổn định trong các phân tích của chúng tôi. Điều này cho thấy OpenAI vượt trội trong việc tạo ra các phần nhúng mạnh mẽ, có thể áp dụng phổ biến.
Quan sát này cho thấy rằng việc đưa nhiều ngôn ngữ hơn vào các phân tích trong tương lai có thể làm nổi bật hơn nữa điểm mạnh của các mô hình, củng cố tầm quan trọng của khả năng thích ứng và khả năng mở rộng của chúng trên phổ ngôn ngữ rộng lớn.
Kết luận
Phân tích này nhắm tới mục đích làm sáng tỏ bối cảnh phức tạp của các công nghệ nhúng đa ngôn ngữ mà bạn có thể xem xét sử dụng.
Mặc dù OpenAI, Google và Cohere là những lực lượng dẫn đầu trong lĩnh vực mô hình ngôn ngữ lớn độc quyền, phân tích này đã cho thấy hiệu suất tiên tiến của họ trong việc tạo nhúng đa ngôn ngữ.
Đặc biệt đáng chú ý là tính ổn định của OpenAI trên nhiều ngôn ngữ khác nhau, hiệu suất mạnh mẽ của Cohere trong một nhóm ngôn ngữ được chọn và hiệu suất tổng thể của Google dựa trên kích thước chiều nhúng nhỏ của chúng.
Hơn nữa, tác động của các mô hình nguồn mở như E5-Instruct và BGE-M3 không thể bị phóng đại. Những mô hình này không chỉ làm phong phú thêm bối cảnh cạnh tranh mà còn thể hiện tiềm năng đổi mới dựa vào cộng đồng trong AI.
Tôi muốn gửi lời cảm ơn tới các nhóm nghiên cứu của Microsoft đối với các mẫu E5 cũng như Học viện Trí tuệ Nhân tạo Bắc Kinh đối với BGE-M3. Những đóng góp đáng kể của họ làm phong phú thêm bối cảnh cạnh tranh.