

Tác giả: Aayush Mittal
ngày 11 tháng 6 năm 2024
Sau nhiều tháng chờ đợi, đội ngũ Qwen của Alibaba cuối cùng đã ra mắt Qwen2 – bước tiến tiếp theo trong loạt mô hình ngôn ngữ mạnh mẽ của họ. Qwen2 đại diện cho một bước tiến vượt bậc, với những cải tiến tiên tiến có thể đưa nó trở thành lựa chọn thay thế tốt nhất cho mô hình Llama 3 nổi tiếng của Meta. Trong phân tích kỹ thuật chuyên sâu này, chúng ta sẽ khám phá các tính năng chính, tiêu chuẩn hiệu suất và các kỹ thuật đổi mới làm cho Qwen2 trở thành một đối thủ đáng gờm trong lĩnh vực các mô hình ngôn ngữ lớn (LLMs).
Mở rộng quy mô: Giới thiệu dòng sản phẩm mô hình Qwen2
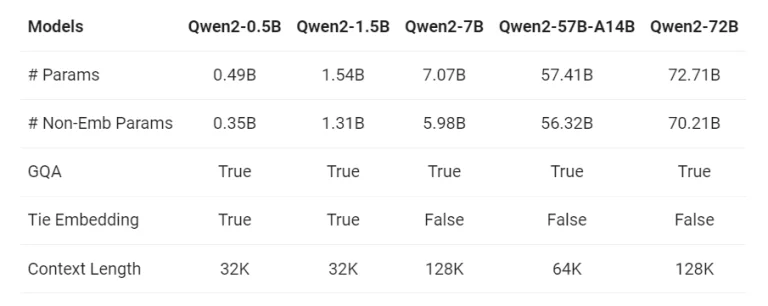
Tại cốt lõi của Qwen2 là một loạt các mô hình đa dạng được thiết kế để đáp ứng các yêu cầu tính toán khác nhau. Dòng sản phẩm bao gồm năm kích thước mô hình khác nhau: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B và mô hình chủ lực Qwen2-72B. Dải lựa chọn này phục vụ cho một loạt người dùng rộng lớn, từ những người có tài nguyên phần cứng khiêm tốn đến những người có quyền truy cập vào cơ sở hạ tầng tính toán tiên tiến.
Một trong những tính năng nổi bật của Qwen2 là khả năng đa ngôn ngữ. Trong khi mô hình Qwen1.5 trước đây xuất sắc trong tiếng Anh và tiếng Trung, Qwen2 đã được huấn luyện trên dữ liệu bao gồm 27 ngôn ngữ bổ sung ấn tượng. Chương trình huấn luyện đa ngôn ngữ này bao gồm các ngôn ngữ từ các khu vực đa dạng như Tây Âu, Đông và Trung Âu, Trung Đông, Đông Á và Nam Á.

Bằng cách mở rộng vốn ngôn ngữ của mình, Qwen2 thể hiện khả năng xuất sắc trong việc hiểu và tạo ra nội dung trên một loạt ngôn ngữ rộng lớn, biến nó thành một công cụ vô giá cho các ứng dụng toàn cầu và giao tiếp đa văn hóa.
Giải Quyết Hiện Tượng Chuyển Mã: Một Thách Thức Đa Ngôn Ngữ
Trong các bối cảnh đa ngôn ngữ, hiện tượng chuyển mã – việc xen kẽ giữa các ngôn ngữ khác nhau trong một cuộc hội thoại hoặc một câu nói – là một hiện tượng phổ biến. Qwen2 đã được huấn luyện kỹ lưỡng để xử lý các tình huống chuyển mã, giảm đáng kể các vấn đề liên quan và đảm bảo các chuyển đổi giữa các ngôn ngữ diễn ra mượt mà.
Các đánh giá bằng cách sử dụng các lời nhắc thường gây ra hiện tượng chuyển mã đã xác nhận sự cải thiện đáng kể của Qwen2 trong lĩnh vực này, chứng tỏ cam kết của Alibaba trong việc cung cấp một mô hình ngôn ngữ thực sự đa ngôn ngữ.
Vượt Trội Trong Lập Trình và Toán Học
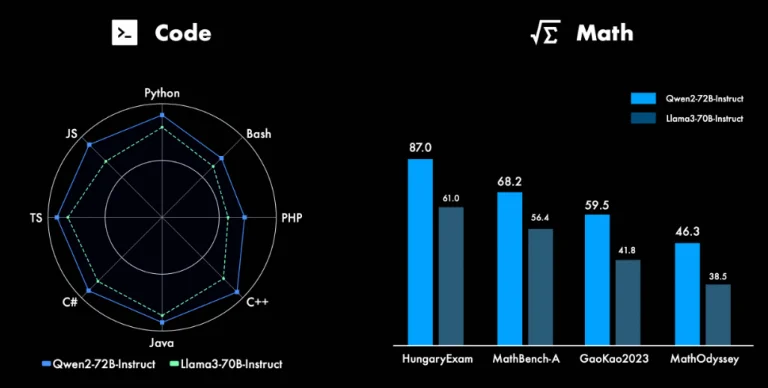
Qwen2 có khả năng đáng kinh ngạc trong các lĩnh vực lập trình và toán học, những lĩnh vực mà các mô hình ngôn ngữ truyền thống thường gặp khó khăn. Bằng cách tận dụng các tập dữ liệu chất lượng cao rộng lớn và các phương pháp huấn luyện tối ưu, Qwen2-72B-Instruct, phiên bản được điều chỉnh theo chỉ dẫn của mô hình chủ lực, thể hiện hiệu suất xuất sắc trong việc giải các bài toán toán học và các nhiệm vụ lập trình bằng nhiều ngôn ngữ lập trình khác nhau.
Mở Rộng Khả Năng Hiểu Ngữ Cảnh
Một trong những tính năng ấn tượng nhất của Qwen2 là khả năng hiểu và xử lý các chuỗi ngữ cảnh mở rộng. Trong khi hầu hết các mô hình ngôn ngữ gặp khó khăn với văn bản dài, các mô hình Qwen2-7B-Instruct và Qwen2-72B-Instruct đã được thiết kế để xử lý độ dài ngữ cảnh lên tới 128 nghìn token.
Khả năng đáng kinh ngạc này là một bước ngoặt cho các ứng dụng đòi hỏi sự hiểu biết sâu sắc về các tài liệu dài, chẳng hạn như hợp đồng pháp lý, các bài nghiên cứu hoặc các sổ tay kỹ thuật dày đặc. Bằng cách xử lý hiệu quả các ngữ cảnh mở rộng, Qwen2 có thể cung cấp các phản hồi chính xác và toàn diện hơn, mở ra những biên giới mới trong lĩnh vực xử lý ngôn ngữ tự nhiên.
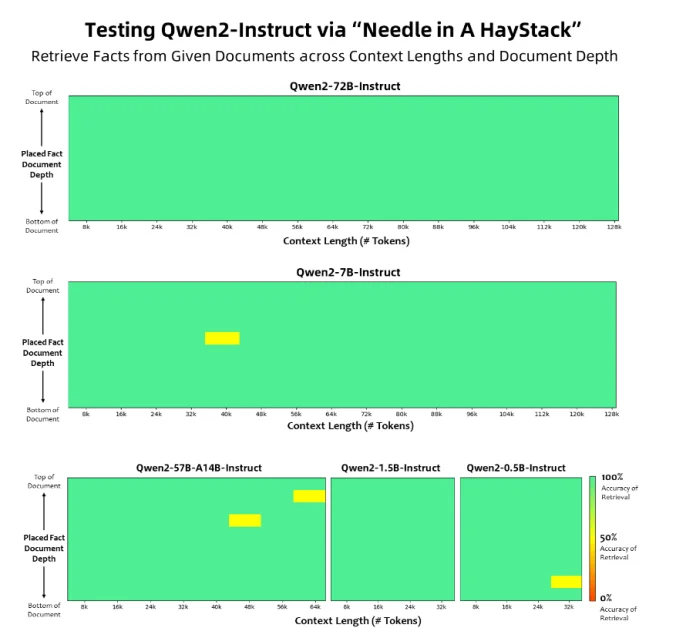
Biểu đồ này cho thấy khả năng của các mô hình Qwen2 trong việc truy xuất thông tin từ các tài liệu có độ dài và độ sâu ngữ cảnh khác nhau.
Những Đổi Mới Kiến Trúc: Group Query Attention và Tối Ưu Hóa Embedding
Bên dưới, Qwen2 tích hợp một số đổi mới kiến trúc góp phần vào hiệu suất xuất sắc của nó. Một trong những đổi mới đó là việc áp dụng Group Query Attention (GQA) trên tất cả các kích thước mô hình. GQA cung cấp tốc độ suy luận nhanh hơn và giảm mức sử dụng bộ nhớ, giúp Qwen2 trở nên hiệu quả hơn và tiếp cận được với nhiều cấu hình phần cứng đa dạng hơn.
Ngoài ra, Alibaba đã tối ưu hóa các embedding cho các mô hình nhỏ hơn trong loạt Qwen2. Bằng cách gắn kết các embedding, nhóm phát triển đã giảm được bộ nhớ cần thiết cho các mô hình này, cho phép triển khai chúng trên phần cứng ít mạnh mẽ hơn mà vẫn duy trì hiệu suất chất lượng cao.
Đánh Giá Qwen2: Vượt Trội Hơn Các Mô Hình Hiện Đại
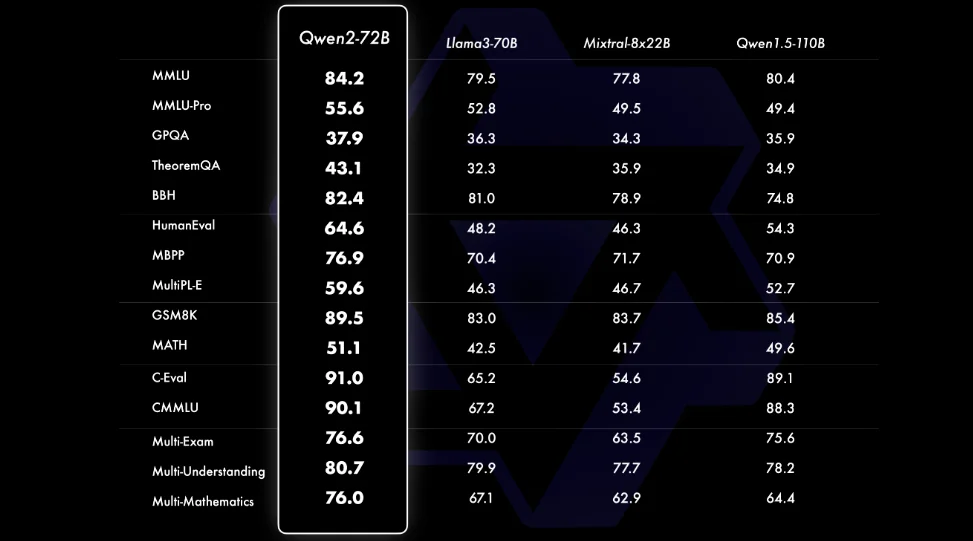
Qwen2 có hiệu suất đáng kinh ngạc trên nhiều tiêu chuẩn đánh giá khác nhau. Các đánh giá so sánh cho thấy Qwen2-72B, mô hình lớn nhất trong loạt, vượt trội hơn so với các đối thủ hàng đầu như Llama-3-70B trong các lĩnh vực quan trọng bao gồm hiểu ngôn ngữ tự nhiên, thu thập kiến thức, khả năng lập trình, kỹ năng toán học và khả năng đa ngôn ngữ.
Mặc dù có ít tham số hơn so với phiên bản tiền nhiệm, Qwen1.5-110B, Qwen2-72B vẫn thể hiện hiệu suất vượt trội, minh chứng cho hiệu quả của các tập dữ liệu được Alibaba chọn lọc kỹ lưỡng và các phương pháp huấn luyện được tối ưu hóa.
An Toàn và Trách Nhiệm: Hướng Tới Các Giá Trị Nhân Văn
Qwen2-72B-Instruct đã được đánh giá kỹ lưỡng về khả năng xử lý các truy vấn tiềm ẩn rủi ro liên quan đến các hoạt động phi pháp, lừa đảo, nội dung khiêu dâm và vi phạm quyền riêng tư. Kết quả rất đáng khích lệ: Qwen2-72B-Instruct hoạt động tương đương với mô hình GPT-4 rất được đánh giá cao về mặt an toàn, với tỷ lệ phản hồi có hại thấp hơn đáng kể so với các mô hình lớn khác như Mistral-8x22B.
Thành tựu này nhấn mạnh cam kết của Alibaba trong việc phát triển các hệ thống AI phù hợp với các giá trị nhân văn, đảm bảo rằng Qwen2 không chỉ mạnh mẽ mà còn đáng tin cậy và có trách nhiệm.
Cấp Phép và Cam Kết Mở Nguồn
Trong một động thái nhằm gia tăng ảnh hưởng của Qwen2, Alibaba đã áp dụng cách tiếp cận mở nguồn đối với việc cấp phép. Trong khi Qwen2-72B và các mô hình được điều chỉnh theo chỉ dẫn của nó vẫn giữ nguyên Giấy phép Qianwen ban đầu, các mô hình còn lại – Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B và Qwen2-57B-A14B – đã được cấp phép theo Giấy phép Apache 2.0 dễ dàng chấp nhận hơn.
Sự cởi mở nâng cao này được kỳ vọng sẽ thúc đẩy ứng dụng và sử dụng thương mại các mô hình Qwen2 trên toàn thế giới, khuyến khích sự hợp tác và đổi mới trong cộng đồng AI toàn cầu.
Sử Dụng và Triển Khai
Việc sử dụng các mô hình Qwen2 rất đơn giản nhờ vào việc tích hợp chúng với các framework phổ biến như Hugging Face. Dưới đây là một ví dụ về việc sử dụng Qwen2-7B-Chat-beta để suy luận:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-7B-Chat", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat")
prompt = "Give me a short introduction to large language models."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)Đoạn mã sau đây minh họa cách thiết lập và tạo văn bản bằng mô hình Qwen2-7B-Chat. Việc tích hợp với Hugging Face giúp nó trở nên dễ dàng truy cập và thử nghiệm.
Qwen2 và Llama 3: Phân Tích So Sánh
Trong khi Qwen2 và Llama 3 của Meta đều là các mô hình ngôn ngữ mạnh mẽ, chúng có những điểm mạnh và đánh đổi riêng biệt.
Dưới đây là phân tích so sánh để giúp bạn hiểu rõ những khác biệt chính:
- Khả Năng Đa Ngôn Ngữ: Qwen2 có lợi thế rõ ràng về hỗ trợ đa ngôn ngữ. Việc đào tạo trên dữ liệu bao gồm 27 ngôn ngữ bổ sung ngoài tiếng Anh và tiếng Trung giúp Qwen2 vượt trội trong giao tiếp đa văn hóa và các tình huống đa ngôn ngữ. Ngược lại, khả năng đa ngôn ngữ của Llama 3 ít được nhấn mạnh hơn, có thể hạn chế hiệu quả của nó trong các ngữ cảnh ngôn ngữ đa dạng.
- Khả Năng Lập Trình và Toán Học: Cả Qwen2 và Llama 3 đều thể hiện khả năng lập trình và toán học ấn tượng. Tuy nhiên, Qwen2-72B-Instruct có vẻ như có lợi thế nhẹ, nhờ vào việc được đào tạo kỹ lưỡng trên các tập dữ liệu chất lượng cao và rộng lớn trong các lĩnh vực này. Tập trung của Alibaba vào việc nâng cao khả năng của Qwen2 trong các lĩnh vực này có thể mang lại lợi thế cho nó trong các ứng dụng chuyên biệt liên quan đến lập trình hoặc giải quyết các vấn đề toán học.
- Khả Năng Hiểu Ngữ Cảnh Dài: Các mô hình Qwen2-7B-Instruct và Qwen2-72B-Instruct có khả năng ấn tượng trong việc xử lý độ dài ngữ cảnh lên tới 128K token. Tính năng này đặc biệt có giá trị cho các ứng dụng đòi hỏi sự hiểu biết sâu sắc về các tài liệu dài hoặc các tài liệu kỹ thuật dày đặc. Llama 3, mặc dù có khả năng xử lý các chuỗi dài, có thể không đạt được hiệu suất như Qwen2 trong lĩnh vực cụ thể này.
Mặc dù cả Qwen2 và Llama 3 đều thể hiện hiệu suất tiên tiến nhất, dòng sản phẩm đa dạng của Qwen2, từ 0.5B đến 72B tham số, mang lại sự linh hoạt và khả năng mở rộng lớn hơn. Sự linh hoạt này cho phép người dùng lựa chọn kích thước mô hình phù hợp nhất với tài nguyên tính toán và yêu cầu hiệu suất của họ. Ngoài ra, những nỗ lực liên tục của Alibaba để mở rộng Qwen2 lên các mô hình lớn hơn có thể nâng cao hơn nữa khả năng của nó, tiềm năng vượt qua Llama 3 trong tương lai.
Triển Khai và Tích Hợp: Đơn Giản Hóa Việc Áp Dụng Qwen2
Để thúc đẩy việc áp dụng và tích hợp rộng rãi Qwen2, Alibaba đã thực hiện các bước chủ động để đảm bảo triển khai liền mạch trên các nền tảng và framework khác nhau. Đội ngũ Qwen đã hợp tác chặt chẽ với nhiều dự án và tổ chức bên thứ ba, cho phép Qwen2 được sử dụng kết hợp với nhiều công cụ và framework khác nhau.
- Tinh Chỉnh và Lượng Tử Hóa: Các dự án bên thứ ba như Axolotl, Llama-Factory, Firefly, Swift và XTuner đã được tối ưu hóa để hỗ trợ tinh chỉnh các mô hình Qwen2, giúp người dùng điều chỉnh mô hình cho các nhiệm vụ và tập dữ liệu cụ thể của họ. Ngoài ra, các công cụ lượng tử hóa như AutoGPTQ, AutoAWQ và Neural Compressor đã được điều chỉnh để hoạt động với Qwen2, giúp triển khai hiệu quả trên các thiết bị có hạn chế về tài nguyên.
- Triển Khai và Suy Luận: Các mô hình Qwen2 có thể được triển khai và phục vụ bằng nhiều framework khác nhau, bao gồm vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino và TGI. Các framework này cung cấp các pipeline suy luận tối ưu hóa, cho phép triển khai Qwen2 hiệu quả và có khả năng mở rộng trong các môi trường sản xuất.
- Nền Tảng API và Thực Thi Cục Bộ: Đối với các nhà phát triển muốn tích hợp Qwen2 vào ứng dụng của họ, các nền tảng API như Together, Fireworks và OpenRouter cung cấp quyền truy cập thuận tiện vào các khả năng của mô hình. Ngoài ra, việc thực thi cục bộ được hỗ trợ thông qua các framework như MLX, Llama.cpp, Ollama và LM Studio, cho phép người dùng chạy Qwen2 trên máy tính cục bộ của họ đồng thời duy trì quyền kiểm soát dữ liệu về quyền riêng tư và bảo mật.
- Framework Đại Diện và RAG: Hỗ trợ của Qwen2 cho việc sử dụng công cụ và khả năng đại diện được tăng cường bởi các framework như LlamaIndex, CrewAI và OpenDevin. Các framework này cho phép tạo ra các đại diện AI chuyên biệt và tích hợp Qwen2 vào các pipeline tạo dữ liệu có hỗ trợ truy xuất (RAG), mở rộng phạm vi ứng dụng và trường hợp sử dụng.
Nhìn Về Tương Lai: Phát Triển và Cơ Hội Tương Lai
Tầm nhìn của Alibaba về Qwen2 không chỉ dừng lại ở phiên bản hiện tại. Nhóm phát triển đang tích cực huấn luyện các mô hình lớn hơn để khám phá biên giới của việc mở rộng mô hình, kết hợp với những nỗ lực mở rộng dữ liệu đang diễn ra. Hơn nữa, các kế hoạch đã được đề ra để mở rộng Qwen2 vào lĩnh vực của AI đa dạng hình ảnh, âm thanh, giúp tích hợp khả năng hiểu hình ảnh và âm thanh.
Khi hệ sinh thái AI mã nguồn mở tiếp tục phát triển mạnh mẽ, Qwen2 sẽ đóng vai trò then chốt, trở thành một nguồn tài nguyên mạnh mẽ cho các nhà nghiên cứu, nhà phát triển và tổ chức mong muốn thúc đẩy tiến bộ trong lĩnh vực xử lý ngôn ngữ tự nhiên và trí tuệ nhân tạo.