


Các mô hình ngôn ngữ lớn (LLM) đã cách mạng hóa cách chúng ta trích xuất thông tin chi tiết từ lượng lớn dữ liệu văn bản. Trong lĩnh vực phân tích tài chính, các ứng dụng LLM cũng đang được thiết kế để hỗ trợ các nhà phân tích trả lời các câu hỏi phức tạp về hiệu quả hoạt động của công ty dựa trên các báo cáo thu nhập và xu hướng thị trường.
Một ứng dụng như vậy liên quan đến việc sử dụng Tăng cường truy xuất (RAG) để tạo điều kiện thuận lợi cho việc trích xuất thông tin từ báo cáo tài chính và các nguồn khác.
Hãy xem xét một tình huống cụ thể trong đó một nhà phân tích tài chính muốn hiểu những điểm chính rút ra từ báo cáo thu nhập quý 2 của công ty, đặc biệt tập trung vào các rào cản công nghệ mà công ty đang xây dựng. Loại câu hỏi này vượt xa việc tra cứu đơn giản và đòi hỏi một cách tiếp cận phức tạp hơn. Đây là lúc khái niệm về Tác nhân LLM phát huy tác dụng.
Tác nhân là gì?
Theo Llama-Index, “tác nhân” là một công cụ đưa ra quyết định và lý luận tự động. Nó nhận thông tin đầu vào hoặc truy vấn của người dùng và có thể đưa ra các quyết định nội bộ để thực hiện truy vấn đó nhằm trả về kết quả chính xác. Các thành phần tác nhân chính có thể bao gồm, nhưng không giới hạn ở việc:
- Chia một câu hỏi phức tạp thành những câu hỏi nhỏ hơn
- Lựa chọn Tool bên ngoài để sử dụng + đưa ra các thông số để gọi Tool
- Lập kế hoạch cho một nhóm nhiệm vụ
- Lưu trữ các tác vụ đã hoàn thành trước đó trong mô-đun bộ nhớ
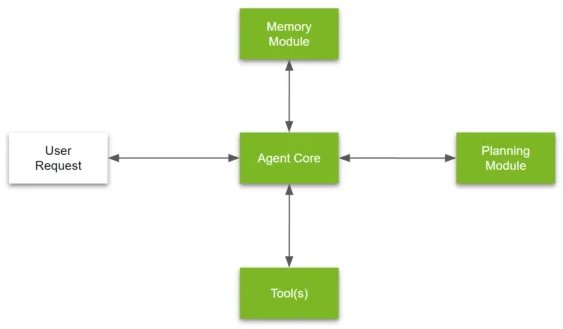
Tác nhân LLM là một hệ thống kết hợp nhiều kỹ thuật khác nhau như lập kế hoạch, tập trung phù hợp, sử dụng bộ nhớ và sử dụng các công cụ khác nhau để trả lời các câu hỏi phức tạp.
Hãy phân tích cách phát triển Tác nhân LLM để trả lời câu hỏi đã nói ở trên:
- Lập kế hoạch: Trước tiên, Tác nhân LLM cần hiểu bản chất của câu hỏi và lập kế hoạch để trích xuất thông tin liên quan. Điều này liên quan đến việc xác định các thuật ngữ chính như “thu nhập quý 2” và “rào cản công nghệ” và xác định các nguồn tốt nhất để thu thập thông tin này.
- Xác định trọng tâm phù hợp: Sau đó, Tác nhân LLM sẽ tập trung sự chú ý của mình vào các khía cạnh cụ thể của câu hỏi liên quan đến rào cản công nghệ. Điều này liên quan đến việc lọc ra những thông tin không liên quan và tập trung vào những chi tiết phù hợp nhất với yêu cầu của nhà phân tích.
- Bộ nhớ: Tác nhân LLM tận dụng bộ nhớ của mình để nhớ lại thông tin liên quan từ các cuộc gọi thu nhập trước đây, báo cáo của công ty và các nguồn khác. Điều này giúp cung cấp thông tin bối cảnh và cơ bản để hỗ trợ phân tích của nó.
- Sử dụng các công cụ khác nhau: Tác nhân LLM sử dụng nhiều công cụ và kỹ thuật để trích xuất và phân tích thông tin. Điều này có thể bao gồm các thuật toán xử lý ngôn ngữ tự nhiên (NLP), phân tích cảm xúc và lập mô hình chủ đề để hiểu sâu hơn về cuộc gọi thu nhập.
- Chia nhỏ các câu hỏi phức tạp: Cuối cùng, Tác nhân LLM chia câu hỏi phức tạp thành các phần phụ đơn giản hơn, giúp dễ dàng trích xuất thông tin liên quan và đưa ra câu trả lời mạch lạc.
Tool calling
Trong RAG LLM tiêu chuẩn chủ yếu chỉ được sử dụng để tổng hợp thông tin.
Mặt khác, Tool Calling bổ sung thêm một lớp hiểu biết về truy vấn bên trên Đường dẫn RAG cho phép người dùng đặt các truy vấn phức tạp và nhận lại kết quả chính xác hơn. Điều này cho phép LLM tìm ra cách sử dụng vectordb thay vì chỉ sử dụng kết quả đầu ra của nó.
Công cụ gọi cho phép LLM tương tác với môi trường bên ngoài thông qua giao diện động trong đó việc gọi công cụ không chỉ giúp chọn công cụ phù hợp mà còn suy ra các lập luận cần thiết để thực thi. Do đó, hiểu rõ hơn về câu hỏi và cũng tạo ra phản hồi tốt hơn so với RAG tiêu chuẩn.
Vòng lặp lý luận của Tác nhân
Điều gì sẽ xảy ra nếu người dùng hỏi một câu hỏi phức tạp bao gồm nhiều bước hoặc một câu hỏi mơ hồ cần được làm rõ. Ở đây vòng lặp lý luận tác nhân xuất hiện. Thay vì gọi nó trong cài đặt một lần, tác nhân sẽ có thể suy luận về các công cụ phải trải qua nhiều bước.
Kiến trúc tác nhân
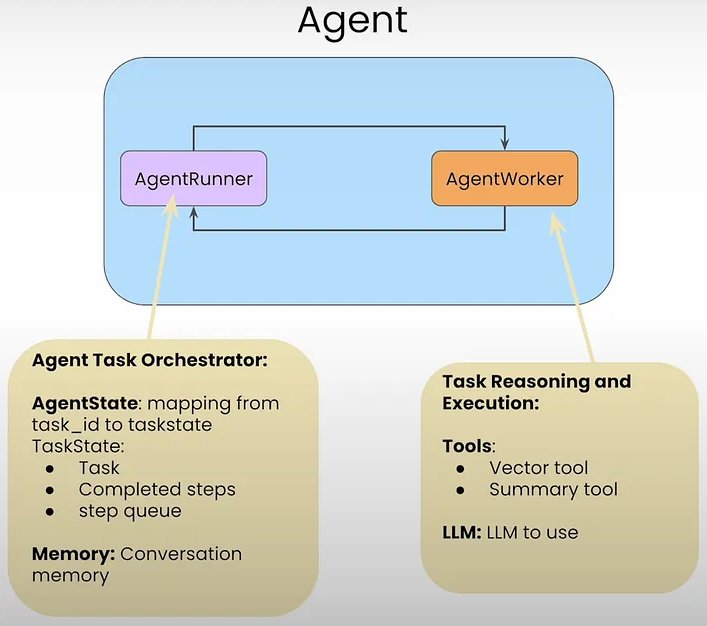
Trong LlamaIndex, một tác nhân bao gồm hai thành phần:
- AgentRunner
- AgentWorkers
Các đối tượng AgentRunner giao tiếp với AgentWorkers .
AgentRunners là người điều phối lưu trữ:
- Tình trạng
- Trí nhớ đàm thoại
- Tạo nhiệm vụ
- Duy trì nhiệm vụ
- Chạy các bước cho từng nhiệm vụ
- Trình bày giao diện người dùng cấp cao, hướng tới người dùng
AgentWorkers đảm trách:
- Lựa chọn và sử dụng công cụ
- Chọn LLM để sử dụng các công cụ.
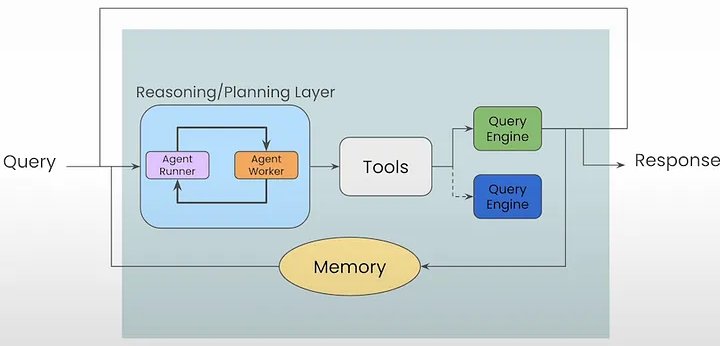
Việc gọi truy vấn tác nhân cho phép truy vấn tác nhân theo cách một lần nhưng không bảo toàn trạng thái. Đây là lúc các khía cạnh trí nhớ xuất hiện để duy trì lịch sử cuộc trò chuyện. Ở đây, tác nhân duy trì lịch sử trò chuyện vào bộ nhớ đệm đàm thoại. Theo mặc định, bộ nhớ đệm là một danh sách phẳng các mục là bộ đệm cuộn tùy thuộc vào kích thước cửa sổ ngữ cảnh của LLM. Do đó, khi Tác nhân quyết định sử dụng một công cụ, nó không chỉ sử dụng cuộc trò chuyện hiện tại mà còn cả lịch sử cuộc trò chuyện trước đó để thực hiện nhóm hành động tiếp theo.
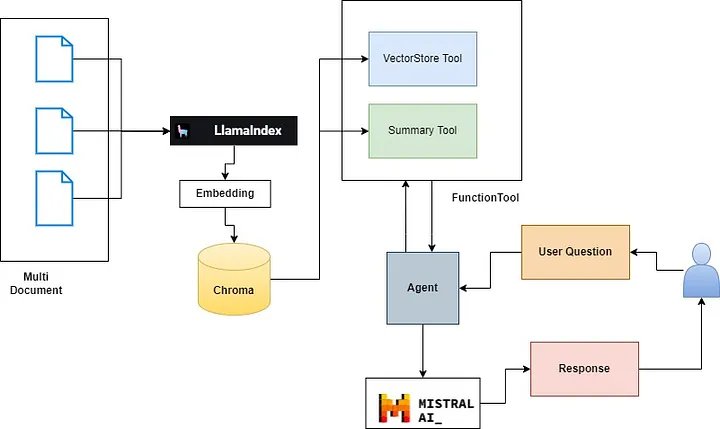
Ở đây chúng ta sẽ xây dựng một tác nhân đa tài liệu để xử lý nhiều tài liệu. Ở đây chúng tôi đã triển khai Agentic RAG trên 3 tài liệu, điều tương tự cũng có thể được mở rộng cho nhiều tài liệu hơn.
Công nghệ được sử dụng
- Llama-Index: LlamaIndex là framework cho các ứng dụng LLM tăng cường theo ngữ cảnh.
- API Mistral: Các nhà phát triển có thể tương tác với Mistral thông qua API của nó, tương tự như trải nghiệm với hệ thống API của OpenAI.
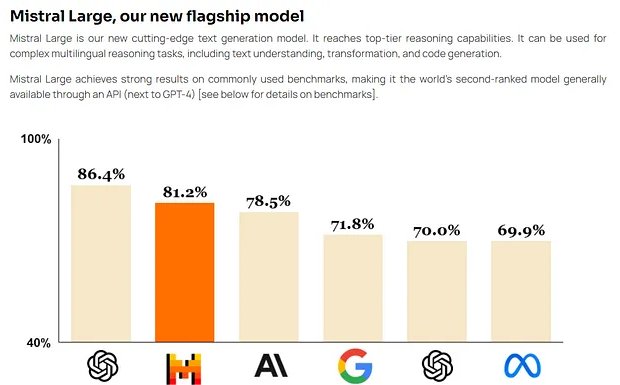
Mistral Large đi kèm với những khả năng và thế mạnh mới:
- Nó vốn thông thạo tiếng Anh, tiếng Pháp, tiếng Tây Ban Nha, tiếng Đức và tiếng Ý, với sự hiểu biết sâu sắc về ngữ pháp và bối cảnh văn hóa.
- Cửa sổ ngữ cảnh lời nhắc 32K của nó cho phép thu hồi thông tin chính xác từ các tài liệu lớn.
- Việc làm theo hướng dẫn chính xác của nó cho phép các nhà phát triển thiết kế các chính sách kiểm duyệt của họ – chúng tôi đã sử dụng nó để thiết lập việc kiểm duyệt le Chat ở cấp hệ thống.
- Nó được cung cấp đi kèm khả gọi hàm (function calling).
Triển khai mã
Mã được triển khai bằng google colab
Cài đặt các phụ thuộc cần thiết
%%writefile requirements.txt
llama-index
llama-index-llms-huggingface
llama-index-embeddings-fastembed
fastembed
Unstructured[md]
chromadb
llama-index-vector-stores-chroma
llama-index-llms-groq
einops
accelerate
sentence-transformers
llama-index-llms-mistralai
llama-index-llms-openai!pip install -r requirements.txt
####################################################################
Successfully installed Unstructured-0.13.7 accelerate-0.30.1 asgiref-3.8.1 backoff-2.2.1 bcrypt-4.1.3 chroma-hnswlib-0.7.3 chromadb-0.5.0 coloredlogs-15.0.1 dataclasses-json-0.6.6 deepdiff-7.0.1 deprecated-1.2.14 dirtyjson-1.0.8 dnspython-2.6.1 einops-0.8.0 email_validator-2.1.1 emoji-2.11.1 fastapi-0.111.0 fastapi-cli-0.0.3 fastembed-0.2.7 filetype-1.2.0 h11-0.14.0 httpcore-1.0.5 httptools-0.6.1 httpx-0.27.0 humanfriendly-10.0 importlib-metadata-7.0.0 jsonpath-python-1.0.6 kubernetes-29.0.0 langdetect-1.0.9 llama-index-0.10.36 llama-index-agent-openai-0.2.4 llama-index-cli-0.1.12 llama-index-core-0.10.36 llama-index-embeddings-fastembed-0.1.4 llama-index-embeddings-openai-0.1.9 llama-index-indices-managed-llama-cloud-0.1.6 llama-index-legacy-0.9.48 llama-index-llms-groq-0.1.3 llama-index-llms-huggingface-0.1.5 llama-index-llms-openai-0.1.18 llama-index-llms-openai-like-0.1.3 llama-index-multi-modal-llms-openai-0.1.5 llama-index-program-openai-0.1.6 llama-index-question-gen-openai-0.1.3 llama-index-readers-file-0.1.22 llama-index-readers-llama-parse-0.1.4 llama-index-vector-stores-chroma-0.1.8 llama-parse-0.4.2 llamaindex-py-client-0.1.19 loguru-0.7.2 marshmallow-3.21.2 mmh3-4.1.0 monotonic-1.6 mypy-extensions-1.0.0 nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-8.9.2.26 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.19.3 nvidia-nvjitlink-cu12-12.4.127 nvidia-nvtx-cu12-12.1.105 onnx-1.16.0 onnxruntime-1.17.3 openai-1.28.1 opentelemetry-api-1.24.0 opentelemetry-exporter-otlp-proto-common-1.24.0 opentelemetry-exporter-otlp-proto-grpc-1.24.0 opentelemetry-instrumentation-0.45b0 opentelemetry-instrumentation-asgi-0.45b0 opentelemetry-instrumentation-fastapi-0.45b0 opentelemetry-proto-1.24.0 opentelemetry-sdk-1.24.0 opentelemetry-semantic-conventions-0.45b0 opentelemetry-util-http-0.45b0 ordered-set-4.1.0 orjson-3.10.3 overrides-7.7.0 posthog-3.5.0 pypdf-4.2.0 pypika-0.48.9 python-dotenv-1.0.1 python-iso639-2024.4.27 python-magic-0.4.27 python-multipart-0.0.9 rapidfuzz-3.9.0 sentence-transformers-2.7.0 shellingham-1.5.4 starlette-0.37.2 striprtf-0.0.26 text-generation-0.7.0 tiktoken-0.6.0 tokenizers-0.15.2 transformers-4.39.3 typer-0.12.3 typing-inspect-0.9.0 ujson-5.9.0 unstructured-client-0.22.0 uvicorn-0.29.0 uvloop-0.19.0 watchfiles-0.21.0 websockets-12.0
Tải xuống tài liệu để xử lý
!mkdir data
#
! wget "https://arxiv.org/pdf/1810.04805.pdf" -O ./data/BERT_arxiv.pdf
! wget "https://arxiv.org/pdf/2005.11401" -O ./data/RAG_arxiv.pdf
! wget "https://arxiv.org/pdf/2310.11511" -O ./data/self_rag_arxiv.pdf
! wget "https://arxiv.org/pdf/2401.15884" -O ./data/crag_arxiv.pdfNhập các phần phụ thuộc bắt buộc
from llama_index.core import SimpleDirectoryReader,VectorStoreIndex,SummaryIndex
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.tools import FunctionTool,QueryEngineTool
from llama_index.core.vector_stores import MetadataFilters,FilterCondition
from typing import List,Optionalimport nest_asyncio
nest_asyncio.apply()Đọc tài liệu
documents = SimpleDirectoryReader(input_files = ['./data/self_rag_arxiv.pdf']).load_data()
print(len(documents))
print(f"Document Metadata: {documents[0].metadata}")Chia tài liệu thành các khối/nút
splitter = SentenceSplitter(chunk_size=1024,chunk_overlap=100)
nodes = splitter.get_nodes_from_documents(documents)
print(f"Length of nodes : {len(nodes)}")
print(f"get the content for node 0 :{nodes[0].get_content(metadata_mode='all')}")
###########################RESPONSE ################################
Length of nodes : 43
get the content for node 0 :page_label: 1
file_name: self_rag_arxiv.pdf
file_path: data/self_rag_arxiv.pdf
file_type: application/pdf
file_size: 1405127
creation_date: 2024-05-11
last_modified_date: 2023-10-19
Preprint.
SELF-RAG: LEARNING TO RETRIEVE , GENERATE ,AND
CRITIQUE THROUGH SELF-REFLECTION
Akari Asai†, Zeqiu Wu†, Yizhong Wang†§, Avirup Sil‡, Hannaneh Hajishirzi†§
†University of Washington§Allen Institute for AI‡IBM Research AI
{akari,zeqiuwu,yizhongw,hannaneh }@cs.washington.edu ,avi@us.ibm.com
ABSTRACT
Despite their remarkable capabilities, large language models (LLMs) often produce
responses containing factual inaccuracies due to their sole reliance on the paramet-
ric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad
hoc approach that augments LMs with retrieval of relevant knowledge, decreases
such issues. However, indiscriminately retrieving and incorporating a fixed number
of retrieved passages, regardless of whether retrieval is necessary, or passages are
relevant, diminishes LM versatility or can lead to unhelpful response generation.
We introduce a new framework called Self-Reflective Retrieval-Augmented Gen-
eration ( SELF-RAG)that enhances an LM’s quality and factuality through retrieval
and self-reflection. Our framework trains a single arbitrary LM that adaptively
retrieves passages on-demand, and generates and reflects on retrieved passages
and its own generations using special tokens, called reflection tokens. Generating
reflection tokens makes the LM controllable during the inference phase, enabling it
to tailor its behavior to diverse task requirements. Experiments show that SELF-
RAG(7B and 13B parameters) significantly outperforms state-of-the-art LLMs
and retrieval-augmented models on a diverse set of tasks. Specifically, SELF-RAG
outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA,
reasoning and fact verification tasks, and it shows significant gains in improving
factuality and citation accuracy for long-form generations relative to these models.1
1 I NTRODUCTION
State-of-the-art LLMs continue to struggle with factual errors (Mallen et al., 2023; Min et al., 2023)
despite their increased model and data scale (Ouyang et al., 2022). Retrieval-Augmented Generation
(RAG) methods (Figure 1 left; Lewis et al. 2020; Guu et al. 2020) augment the input of LLMs
with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks (Ram et al.,
2023; Asai et al., 2023a). However, these methods may hinder the versatility of LLMs or introduce
unnecessary or off-topic passages that lead to low-quality generations (Shi et al., 2023) since they
retrieve passages indiscriminately regardless of whether the factual grounding is helpful. Moreover,
the output is not guaranteed to be consistent with retrieved relevant passages (Gao et al., 2023) since
the models are not explicitly trained to leverage and follow facts from provided passages. This
work introduces Self-Reflective Retrieval-augmented Generation ( SELF-RAG)to improve an
LLM’s generation quality, including its factual accuracy without hurting its versatility, via on-demand
retrieval and self-reflection. We train an arbitrary LM in an end-to-end manner to learn to reflect on
its own generation process given a task input by generating both task output and intermittent special
tokens (i.e., reflection tokens ). Reflection tokens are categorized into retrieval andcritique tokens to
indicate the need for retrieval and its generation quality respectively (Figure 1 right). In particular,
given an input prompt and preceding generations, SELF-RAGfirst determines if augmenting the
continued generation with retrieved passages would be helpful. If so, it outputs a retrieval token that
calls a retriever model on demand (Step 1). Subsequently, SELF-RAGconcurrently processes multiple
retrieved passages, evaluating their relevance and then generating corresponding task outputs (Step
2). It then generates critique tokens to criticize its own output and choose best one (Step 3) in terms
of factuality and overall quality. This process differs from conventional RAG (Figure 1 left), which
1Our code and trained models are available at https://selfrag.github.io/ .
1arXiv:2310.11511v1 [cs.CL] 17 Oct 2023Khởi tạo vector trên ChromaDB
import chromadb
db = chromadb.PersistentClient(path="./chroma_db_mistral")
chroma_collection = db.get_or_create_collection("multidocument-agent")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)Khởi tạo mô hình nhúng
from llama_index.embeddings.fastembed import FastEmbedEmbedding
from llama_index.core import Settings
#
embed_model = FastEmbedEmbedding(model_name="BAAI/bge-small-en-v1.5")
#
Settings.embed_model = embed_model
#
Settings.chunk_size = 1024
#Khởi tạo LLM
from llama_index.llms.mistralai import MistralAI
os.environ["MISTRAL_API_KEY"] = userdata.get("MISTRAL_API_KEY")
llm = MistralAI(model="mistral-large-latest")
Khởi tạo công cụ Truy vấn Vector và công cụ tóm tắt cho tài liệu cụ thể
Tác nhân xử lý dữ liệu LlamaIndex xử lý đầu vào ngôn ngữ tự nhiên để thực hiện các hành động thay vì tạo ra phản hồi. Chìa khóa để tạo ra các tác nhân dữ liệu hiệu quả nằm ở các công cụ trừu tượng hóa. Nhưng chính xác thì công cụ có ý nghĩa gì trong bối cảnh này? Hãy coi các công cụ như giao diện API được thiết kế cho tương tác của tác nhân thay vì giao diện của con người.
Khái niệm cốt lõi:
- Công cụ: Về cơ bản, Công cụ bao gồm giao diện chung và siêu dữ liệu cơ bản như tên, mô tả và lược đồ chức năng.
- Thông số công cụ: Phần này đi sâu vào các chi tiết cụ thể của API, trình bày đặc tả API dịch vụ toàn diện có thể được dịch sang nhiều Công cụ khác nhau.
Có một số loại Công cụ có sẵn:
- FunctionTool: Chuyển đổi bất kỳ hàm nào do người dùng xác định thành Công cụ, với khả năng suy ra lược đồ của hàm.
- QueryEngineTool: Bao quanh một công cụ truy vấn hiện có. Vì sự trừu tượng hóa tác nhân của chúng tôi có nguồn gốc từ BaseQueryEngine nên công cụ này cũng có thể chứa các tác nhân.
#instantiate Vectorstore
name = "BERT_arxiv"
vector_index = VectorStoreIndex(nodes,storage_context=storage_context)
vector_index.storage_context.vector_store.persist(persist_path="/content/chroma_db")
#
# Define Vectorstore Autoretrieval tool
def vector_query(query:str,page_numbers:Optional[List[str]]=None)->str:
'''
perform vector search over index on
query(str): query string needs to be embedded
page_numbers(List[str]): list of page numbers to be retrieved,
leave blank if we want to perform a vector search over all pages
'''
page_numbers = page_numbers or []
metadata_dict = [{"key":'page_label',"value":p} for p in page_numbers]
#
query_engine = vector_index.as_query_engine(similarity_top_k =2,
filters = MetadataFilters.from_dicts(metadata_dict,
condition=FilterCondition.OR)
)
#
response = query_engine.query(query)
return response
#
#llamiondex FunctionTool wraps any python function we feed it
vector_query_tool = FunctionTool.from_defaults(name=f"vector_tool_{name}",
fn=vector_query)
# Prepare Summary Tool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(response_mode="tree_summarize",
se_async=True,)
summary_query_tool = QueryEngineTool.from_defaults(name=f"summary_tool_{name}",
query_engine=summary_query_engine,
description=("Use ONLY IF you want to get a holistic summary of the documents."
"DO NOT USE if you have specified questions over the documents."))Kiểm tra LLM
response = llm.predict_and_call([vector_query_tool],
"Summarize the content in page number 2",
verbose=True)
######################RESPONSE###########################
=== Calling Function ===
Calling function: vector_tool_BERT_arxiv with args: {"query": "summarize content", "page_numbers": ["2"]}
=== Function Output ===
The content discusses the use of RAG models for knowledge-intensive generation tasks, such as MS-MARCO and Jeopardy question generation, showing that the models produce more factual, specific, and diverse responses compared to a BART baseline. The models also perform well in FEVER fact verification, achieving results close to state-of-the-art pipeline models. Additionally, the models demonstrate the ability to update their knowledge as the world changes by replacing the non-parametric memory.Hàm Helper tạo Công cụ Vectorstore và công cụ Tóm tắt cho tất cả các tài liệu
def get_doc_tools(file_path:str,name:str)->str:
'''
get vector query and sumnmary query tools from a document
'''
#load documents
documents = SimpleDirectoryReader(input_files = [file_path]).load_data()
print(f"length of nodes")
splitter = SentenceSplitter(chunk_size=1024,chunk_overlap=100)
nodes = splitter.get_nodes_from_documents(documents)
print(f"Length of nodes : {len(nodes)}")
#instantiate Vectorstore
vector_index = VectorStoreIndex(nodes,storage_context=storage_context)
vector_index.storage_context.vector_store.persist(persist_path="/content/chroma_db")
#
# Define Vectorstore Autoretrieval tool
def vector_query(query:str,page_numbers:Optional[List[str]]=None)->str:
'''
perform vector search over index on
query(str): query string needs to be embedded
page_numbers(List[str]): list of page numbers to be retrieved,
leave blank if we want to perform a vector search over all pages
'''
page_numbers = page_numbers or []
metadata_dict = [{"key":'page_label',"value":p} for p in page_numbers]
#
query_engine = vector_index.as_query_engine(similarity_top_k =2,
filters = MetadataFilters.from_dicts(metadata_dict,
condition=FilterCondition.OR)
)
#
response = query_engine.query(query)
return response
#
#llamiondex FunctionTool wraps any python function we feed it
vector_query_tool = FunctionTool.from_defaults(name=f"vector_tool_{name}",
fn=vector_query)
# Prepare Summary Tool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(response_mode="tree_summarize",
se_async=True,)
summary_query_tool = QueryEngineTool.from_defaults(name=f"summary_tool_{name}",
query_engine=summary_query_engine,
description=("Use ONLY IF you want to get a holistic summary of the documents."
"DO NOT USE if you have specified questions over the documents."))
return vector_query_tool,summary_query_tool
Chuẩn bị danh sách đầu vào với tên tài liệu được chỉ định
import os
root_path = "/content/data"
file_name = []
file_path = []
for files in os.listdir(root_path):
if file.endswith(".pdf"):
file_name.append(files.split(".")[0])
file_path.append(os.path.join(root_path,file))
#
print(file_name)
print(file_path)
################################RESPONSE###############################
['self_rag_arxiv', 'crag_arxiv', 'RAG_arxiv', '', 'BERT_arxiv']
['/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf']Lưu ý: FunctionTool yêu cầu một chuỗi khớp với mẫu ‘^[a-zA-Z0–9_-]+$’ cho tên công cụ
Tạo công cụ vector và công cụ tóm tắt cho từng tài liệu
papers_to_tools_dict = {}
for name,filename in zip(file_name,file_path):
vector_query_tool,summary_query_tool = get_doc_tools(filename,name)
papers_to_tools_dict[name] = [vector_query_tool,summary_query_tool]
####################RESPONSE###########################
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28Đưa các công cụ vào một danh sách phẳng
initial_tools = [t for f in file_name for t in papers_to_tools_dict[f]]
initial_toolsViệc nhồi nhét quá nhiều lựa chọn công cụ vào lời nhắc đến LLM sẽ dẫn đến các vấn đề sau:
- Các công cụ có thể không vừa với lời nhắc, đặc biệt nếu số lượng tài liệu của chúng ta lớn vì chúng ta đang lập mô hình từng tài liệu như một công cụ riêng biệt.
- Chi phí và độ trễ sẽ tăng đột biến do số lượng token tăng lên.
- Có thể gây nhầm lẫn dẫn đến LLm không hoạt động như hướng dẫn.
Một giải pháp ở đây là thực hiện RAG ở cấp độ công cụ. Để thực hiện điều này, chúng ta sẽ sử dụng lớp ObjectIndex của Llama-Index.
Lớp này ObjectIndex là lớp cho phép lập chỉ mục các đối tượng Python tùy ý. Như vậy, nó khá linh hoạt và có thể áp dụng cho nhiều trường hợp sử dụng. Như ví dụ:
- Sử dụng một
ObjectIndexđể lập chỉ mục các đối tượng Công cụ để sau đó tác nhân sẽ sử dụng. - Sử dụng
ObjectIndexđể lập chỉ mục một đối tượng SQLTableSchema
Đây VectorStoreIndex là thành phần quan trọng của LlamaIndex, tạo điều kiện thuận lợi cho việc lưu trữ và truy xuất dữ liệu. Nó hoạt động bằng cách:
- Chấp nhận danh sách
Nodecác đối tượng và xây dựng chỉ mục từ chúng. - Sử dụng các cửa hàng vectơ khác nhau làm phụ trợ lưu trữ, nâng cao tính linh hoạt và khả năng mở rộng của ứng dụng.
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
#
obj_index = ObjectIndex.from_objects(initial_tools,index_cls=VectorStoreIndex)
#Thiết lập ObjectIndex làm công cụ truy xuất
obj_retriever = obj_index.as_retriever(similarity_top_k=2)
tools = obj_retriever.retrieve("compare and contrast the papers self rag and corrective rag")
#
print(tools[0].metadata)
print(tools[1].metadata)
###################################RESPONSE###########################
ToolMetadata(description='Use ONLY IF you want to get a holistic summary of the documents.DO NOT USE if you have specified questions over the documents.', name='summary_tool_self_rag_arxiv', fn_schema=<class 'llama_index.core.tools.types.DefaultToolFnSchema'>, return_direct=False)
ToolMetadata(description='vector_tool_self_rag_arxiv(query: str, page_numbers: Optional[List[str]] = None) -> str\n\n perform vector search over index on\n query(str): query string needs to be embedded\n page_numbers(List[str]): list of page numbers to be retrieved,\n leave blank if we want to perform a vector search over all pages\n ', name='vector_tool_self_rag_arxiv', fn_schema=<class 'pydantic.v1.main.vector_tool_self_rag_arxiv'>, return_direct=False)Thiết lập tác nhân RAG
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
#
agent_worker = FunctionCallingAgentWorker.from_tools(tool_retriever=obj_retriever,
llm=llm,
system_prompt="""You are an agent designed to answer queries over a set of given papers.
Please always use the tools provided to answer a question.Do not rely on prior knowledge.""",
verbose=True)
agent = AgentRunner(agent_worker)Hỏi câu hỏi 1
#
response = agent.query("Compare and contrast self rag and crag.")
print(str(response))
##############################RESPONSE###################################
Added user message to memory: Compare and contrast self rag and crag.
=== LLM Response ===
Sure, I'd be happy to help you understand the differences between Self RAG and CRAG, based on the functions provided to me.
Self RAG (Retrieval-Augmented Generation) is a method where the model generates a holistic summary of the documents provided as input. It's important to note that this method should only be used if you want a general summary of the documents, and not if you have specific questions over the documents.
On the other hand, CRAG (Contrastive Retrieval-Augmented Generation) is also a method for generating a holistic summary of the documents. The key difference between CRAG and Self RAG is not explicitly clear from the functions provided. However, the name suggests that CRAG might use a contrastive approach in its retrieval process, which could potentially lead to a summary that highlights the differences and similarities between the documents more effectively.
Again, it's crucial to remember that both of these methods should only be used for a holistic summary, and not for answering specific questions over the documents.
Hỏi câu hỏi 2
response = agent.query("Summarize the paper corrective RAG.")
print(str(response))
###############################RESPONSE#######################
Added user message to memory: Summarize the paper corrective RAG.
=== Calling Function ===
Calling function: summary_tool_RAG_arxiv with args: {"input": "corrective RAG"}
=== Function Output ===
The corrective RAG approach is a method used to address issues or errors in a system by categorizing them into three levels: Red, Amber, and Green. Red signifies critical problems that need immediate attention, Amber indicates issues that require monitoring or action in the near future, and Green represents no significant concerns. This approach helps prioritize and manage corrective actions effectively based on the severity of the identified issues.
=== LLM Response ===
The corrective RAG approach categorizes issues into Red, Amber, and Green levels to prioritize and manage corrective actions effectively based on severity. Red signifies critical problems needing immediate attention, Amber requires monitoring or action soon, and Green indicates no significant concerns.
assistant: The corrective RAG approach categorizes issues into Red, Amber, and Green levels to prioritize and manage corrective actions effectively based on severity. Red signifies critical problems needing immediate attention, Amber requires monitoring or action soon, and Green indicates no significant concerns.Kết luận
Không giống như quy trình RAG tiêu chuẩn phù hợp với các truy vấn đơn giản trên một số tài liệu, cách tiếp cận này điều chỉnh dựa trên những phát hiện ban đầu để tăng cường khả năng truy xuất dữ liệu hơn nữa. Tại đây, chúng tôi đã phát triển một tác nhân nghiên cứu tự chủ để nâng cao khả năng tương tác và phân tích dữ liệu của chúng ta một cách toàn diện.