

Tăng cường truy xuất (RAG) là một là một giải pháp mạnh mẽ trong việc bổ sung các kiến thức bên ngoài mô hình ngôn ngữ lớn mà không cần phải thực hiện tinh chỉnh trực tiếp đến mô hình gốc đòi hỏi nhiều xử lý cũng như vận hành ở mức phức tạp.
Mặc dù có triển vọng, tuy nhiên các ứng dụng RAG thường gặp phải những thách thức khi chuyển đổi từ phòng phát triển sang môi trường vận hành trong thực tế. Bài viết này đi sâu vào sự phức tạp của các ứng dụng RAG, khám phá những cạm bẫy phổ biến và hiểu biết chiến lược để triển khai thành công.
Từ mẫu đến thực tế
Việc triển khai các ứng dụng RAG trong môi trường thực tế gặp rất nhiều thách thức. Sự phức tạp của việc tích hợp các LLM tạo ra với các cơ chế truy xuất có nghĩa là bất kỳ số lượng thành phần nào cũng có thể trục trặc, dẫn đến các lỗi hệ thống tiềm ẩn.
Ví dụ, khả năng mở rộng và độ sẵn sàng của hệ thống là rất quan trọng; nó phải xử lý các tải không thể đoán trước và yêu cầu vẫn phải hoạt động mượt mà khi có nhu cầu cao. Hơn nữa, việc dự đoán tương tác của người dùng với hệ thống trong môi trường trực tiếp là một thách thức, đòi hỏi phải theo dõi và điều chỉnh liên tục để duy trì hiệu suất và độ tin cậy.
Hãy cùng chúng tôi xem xét một sơ đồ nguyên mẫu RAG tổng hợp dưới đây:
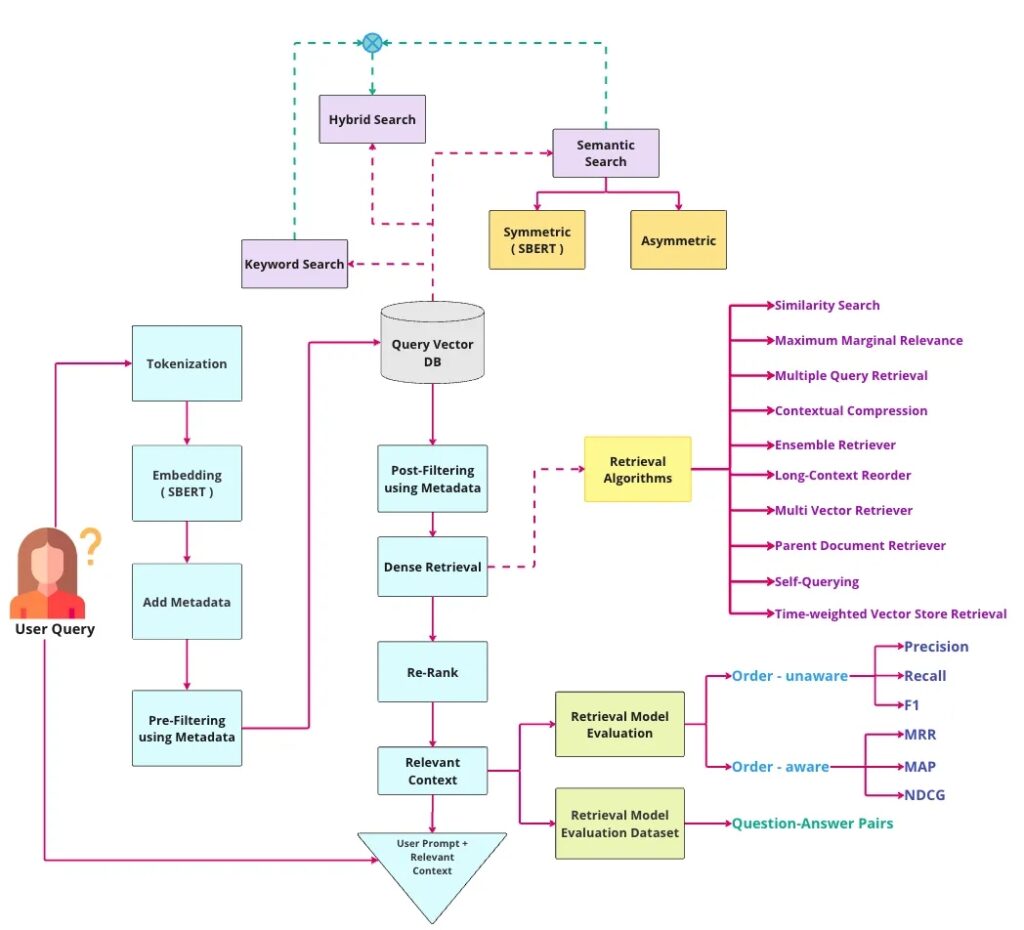
1. User Query
- Người dùng gửi truy vấn vào hệ thống.
2. Tokenization (Phân tách từ)
- Truy vấn được phân tách thành các token (từ hoặc cụm từ).
3. Embedding (SBERT)
- Truy vấn được chuyển đổi thành vector sử dụng SBERT (Sentence-BERT), một mô hình học máy để mã hóa văn bản thành các vector.
4. Add Metadata (Thêm siêu dữ liệu)
- Siêu dữ liệu có thể được thêm vào truy vấn để cung cấp thêm ngữ cảnh hoặc thông tin.
5. Pre-Filtering using Metadata (Lọc trước bằng siêu dữ liệu)
- Truy vấn có thể được lọc trước dựa trên siêu dữ liệu để giới hạn kết quả phù hợp.
6. Query Vector DB (Cơ sở dữ liệu vector truy vấn)
- Các vector truy vấn được lưu trữ trong cơ sở dữ liệu vector.
7. Post-Filtering using Metadata (Lọc sau bằng siêu dữ liệu)
- Sau khi tìm kiếm trong cơ sở dữ liệu vector, kết quả có thể được lọc thêm dựa trên siêu dữ liệu.
8. Dense Retrieval (Truy xuất đặc)
- Thực hiện truy xuất đặc từ cơ sở dữ liệu vector, tìm kiếm các kết quả có vector gần nhất với vector truy vấn.
9. Re-Rank (Sắp xếp lại)
- Các kết quả tìm kiếm được sắp xếp lại dựa trên mức độ liên quan.
10. Relevant Context (Ngữ cảnh liên quan)
- Ngữ cảnh liên quan được chọn lọc để trả về cho người dùng.
11. User Prompt + Relevant Context (Truy vấn người dùng + Ngữ cảnh liên quan)
- Kết hợp truy vấn ban đầu của người dùng với ngữ cảnh liên quan để cung cấp kết quả cuối cùng.
12. Retrieval Algorithms (Thuật toán truy xuất)
- Symmetric (SBERT): Tìm kiếm ngữ nghĩa với sự đối xứng của các vector từ SBERT.
- Asymmetric: Tìm kiếm ngữ nghĩa mà không yêu cầu sự đối xứng.
- Các thuật toán truy xuất khác bao gồm:
- Tìm kiếm tương tự
- Mức độ tương đối tối đa (Maximum Marginal Relevance)
- Truy xuất nhiều truy vấn
- Nén ngữ cảnh
- Truy xuất theo nhóm
- Sắp xếp lại ngữ cảnh dài
- Truy xuất vector đa chiều
- Truy xuất tài liệu chính
- Truy xuất tự vấn
- Truy xuất theo thời gian
13. Retrieval Model Evaluation (Đánh giá mô hình truy xuất)
- Các mô hình truy xuất được đánh giá dựa trên:
- Order-unaware: Độ chính xác (Precision), Độ gợi nhớ (Recall), F1
- Order-aware: MRR (Mean Reciprocal Rank), MAP (Mean Average Precision), NDCG (Normalized Discounted Cumulative Gain)
14. Retrieval Model Evaluation Dataset (Bộ dữ liệu đánh giá mô hình truy xuất)
- Bộ dữ liệu được sử dụng để đánh giá hiệu suất của mô hình truy xuất.
15. Hybrid Search (Tìm kiếm lai)
- Kết hợp giữa tìm kiếm từ khóa và tìm kiếm ngữ nghĩa để cải thiện kết quả.
16. Keyword Search (Tìm kiếm từ khóa)
- Sử dụng từ khóa từ truy vấn để tìm kiếm thông tin.
17. Semantic Search (Tìm kiếm ngữ nghĩa)
- Sử dụng mô hình học máy để hiểu ngữ nghĩa của truy vấn và tìm kiếm các kết quả tương tự ngữ nghĩa.
Sơ đồ trên mô tả toàn bộ quy trình từ khi nhận truy vấn của người dùng đến khi trả kết quả tìm kiếm, sử dụng sự kết hợp giữa các kỹ thuật xử lý ngôn ngữ tự nhiên và truy xuất thông tin để cung cấp kết quả chính xác và phù hợp hơn.
Các loại mô hình RAG
1. Dựa trên Phương pháp Truy xuất
- BM25: Đây là một phương pháp truyền thống trong tìm kiếm thông tin, dựa vào xác suất để đánh giá mức độ liên quan của các tài liệu. Nó thường sử dụng tần suất của từ trong tài liệu và truy vấn để xác định mức độ phù hợp.
- Truy xuất đặc (Dense Retriever): Sử dụng các mô hình mạng nơ-ron tiên tiến để mã hóa tài liệu và truy vấn thành các vector (vector embedding). Điều này cho phép hệ thống tìm kiếm các tài liệu liên quan một cách hiệu quả hơn so với các phương pháp truyền thống như BM25.
Ví dụ: Nếu bạn tìm kiếm “tác giả của Harry Potter,” BM25 sẽ tìm các tài liệu chứa từ “tác giả” và “Harry Potter,” trong khi truy xuất đặc có thể hiểu ngữ cảnh và tìm ra rằng “J.K. Rowling” là câu trả lời chính xác ngay cả khi các từ này không xuất hiện cùng nhau.
2. Dựa trên Cơ chế Tạo Nội dung
- Transformer-based Models: Các mô hình này, như BERT, GPT-2, hoặc GPT-3, được sử dụng để tạo ra phản hồi dựa trên tài liệu đã truy xuất. Chúng có khả năng hiểu ngữ cảnh và tạo ra câu trả lời chi tiết và liên quan đến truy vấn.
Ví dụ: Sau khi hệ thống tìm thấy thông tin về “J.K. Rowling” từ tài liệu, mô hình GPT-3 có thể tạo ra một đoạn văn giải thích chi tiết về tác giả này.
3. Xử lý Tuần tự và Song song
- Tuần tự (Sequential): Hệ thống đầu tiên tìm kiếm tất cả các tài liệu liên quan, sau đó sử dụng các tài liệu này để tạo ra phản hồi. Điều này giúp đảm bảo rằng phản hồi dựa trên toàn bộ tập hợp các thông tin đã truy xuất.
- Song song (Parallel): Hệ thống vừa truy xuất vừa tạo ra nội dung cùng lúc, cho phép các bước truy xuất và tạo nội dung ảnh hưởng lẫn nhau liên tục.
Ví dụ: Trong mô hình tuần tự, bạn sẽ tìm hết các bài viết về J.K. Rowling trước khi viết báo cáo, trong khi mô hình song song có thể tìm và viết từng phần một đồng thời.
4. Các Phương pháp Tinh chỉnh
- Tinh chỉnh (Fine-tuning): Mô hình RAG có thể được tinh chỉnh cho các nhiệm vụ cụ thể để cải thiện cả quá trình truy xuất và tạo nội dung. Điều này có nghĩa là mô hình học cách sử dụng thông tin truy xuất tốt hơn để tạo ra các phản hồi chính xác và hữu ích cho các nhiệm vụ cụ thể.
Ví dụ: Mô hình có thể được huấn luyện đặc biệt để trả lời câu hỏi về y học bằng cách học cách truy xuất và sử dụng thông tin từ các tài liệu y khoa một cách chính xác.
Cấu hình tuỳ chỉnh của RAG
Cấu hình RAG cho phép tùy chỉnh rộng rãi để điều chỉnh các mô hình theo nhu cầu cụ thể. Các tùy chọn cấu hình chính bao gồm:
- Số lượng tài liệu cần lấy (
n_docs): Xác định số lượng tài liệu mà trình lấy dữ liệu phải lấy, điều này có thể ảnh hưởng đến phạm vi thông tin được xem xét khi tạo phản hồi. - Độ dài kết hợp tối đa (
max_combined_length): Giới hạn tổng độ dài của ngữ cảnh được sử dụng để tạo phản hồi, ảnh hưởng đến chi tiết và phạm vi của văn bản được tạo. - Kích thước vectơ truy xuất: Xác định kích thước của nhúng được sử dụng để truy xuất, ảnh hưởng đến mức độ chi tiết của việc khớp ngữ nghĩa giữa truy vấn và tài liệu.
- Kích thước lô truy xuất: Chỉ định số lượng truy vấn truy xuất được xử lý đồng thời, ảnh hưởng đến tốc độ và hiệu quả truy xuất
Một số ứng dụng của RAG
Các mô hình RAG đặc biệt hiệu quả trong các ứng dụng đòi hỏi tích hợp kiến thức sâu sắc và hiểu biết theo ngữ cảnh, chẳng hạn như nghiên cứu pháp lý, đánh giá tài liệu khoa học và các truy vấn dịch vụ khách hàng phức tạp. Việc tích hợp các quy trình truy xuất và tạo cho phép các mô hình RAG cung cấp các phản hồi chính xác, chi tiết và có liên quan theo ngữ cảnh dựa trên các nguồn thông tin bên ngoài.
Rào cản và chiến lược giảm thiểu
Rào cản mà bạn sẽ phải đối mặt
Chất lượng truy xuất
Truy xuất hiệu quả là nền tảng cho sự thành công của RAG. Đảm bảo rằng hệ thống truy xuất các tài liệu vừa có liên quan vừa đa dạng để đáp ứng các truy vấn là rất quan trọng. Các lỗi trong lĩnh vực này có thể dẫn đến các phản hồi không chính xác hoặc không liên quan, làm suy yếu tiện ích của hệ thống và lòng tin của người dùng. Nhìn chung, việc truy xuất sẽ được thực hiện bằng một số loại ma trận tương đồng. Thuật toán rất quan trọng! Độ tương đồng Cosine sẽ có sự khớp chung nhưng có thể sẽ không phù hợp trong các ứng dụng cụ thể theo những lĩnh vực đặc thù. Đặc biệt trong chăm sóc sức khỏe, hãy chuẩn bị sử dụng các trình truy xuất đa truy vấn, tự truy vấn hoặc thậm chí là trình truy xuất tập hợp.
Ảo giác
Hệ thống RAG đôi khi tạo ra thông tin không dựa trên các tài liệu đã thu thập, một hiện tượng được gọi là ảo giác. Những điều này có thể ảnh hưởng nghiêm trọng đến độ tin cậy và độ chính xác của hệ thống, đòi hỏi phải có các cơ chế mạnh mẽ để lọc nhiễu và tích hợp thông tin từ nhiều nguồn để cung cấp phản hồi mạch lạc và chính xác
Mối quan tâm về quyền riêng tư và bảo mật
Vi phạm quyền riêng tư và lỗ hổng bảo mật là những rủi ro đáng kể, đặc biệt là khi xử lý thông tin nhạy cảm. Các ứng dụng RAG phải được thiết kế để ngăn chặn việc tiết lộ trái phép dữ liệu cá nhân hoặc dữ liệu bí mật và chống lại các cuộc tấn công thao túng có thể làm tổn hại đến tính toàn vẹn của hệ thống. Đây là một điểm khó khăn đặc biệt trong các ứng dụng doanh nghiệp của bạn. Trên thực tế, vấn đề không phải là bạn đã bảo vệ ứng dụng của mình hay chưa mà là bạn đã chấm hết tất cả các chữ i và gạch hết tất cả các chữ t. Bạn sẽ phải chứng minh rằng bạn đã làm mọi thứ có thể để bảo vệ dữ liệu doanh nghiệp.
Sử dụng độc hại và An toàn nội dung
Đảm bảo rằng các ứng dụng RAG không tạo điều kiện cho các hoạt động bất hợp pháp hoặc tạo ra nội dung có hại là điều cần thiết. Điều này bao gồm việc triển khai các biện pháp bảo vệ chống lại việc tạo hoặc phát tán nội dung có thể được sử dụng cho mục đích xấu. Điều này có thể không phải là mối quan tâm đối với tất cả người dùng và trường hợp sử dụng doanh nghiệp vì các trường hợp sử dụng này sẽ được phục vụ cho một đối tượng cụ thể bằng cách sử dụng một dữ liệu cụ thể. Không có doanh nghiệp nào sẽ chấp nhận rủi ro khi sử dụng tất cả thông tin trong RAG.
Thách thức theo từng lĩnh vực
Các ứng dụng RAG được thiết kế riêng cho các lĩnh vực cụ thể phải xử lý hiệu quả các truy vấn ngoài bên ngoài dữ liệu tiền huấn luyện, đảm bảo chúng cung cấp các phản hồi có liên quan và chính xác ngay cả khi các truy vấn nằm ngoài cơ sở kiến thức chính của chúng. Chúng ta sẽ nói thêm về điều này sau trong phần thành công – nhưng nó thực sự là một nỗi phiền toái. Tóm lại, đối với ngách của lĩnh vực mà bạn ứng dụng, tốt hơn hết bạn nên cân nhắc sử dụng một mô hình lớn dành riêng cho lĩnh vực kết hợp với một mô hình lớn tổng quát như OpenAI/Claude/bất kỳ cái gì.
Sự hoàn thiện và tính toàn vẹn của thương hiệu
Tính đầy đủ của phản hồi và duy trì tính toàn vẹn của thương hiệu là rất quan trọng đối với sự hài lòng và tin tưởng của người dùng. Hệ thống RAG phải cung cấp các câu trả lời toàn diện và phù hợp với ngữ cảnh, đồng thời tránh nội dung có thể gây tổn hại đến danh tiếng của thương hiệu
Các vấn đề kỹ thuật
Các vấn đề như truy xuất đệ quy, truy xuất cửa sổ câu và hành động cân bằng giữa triển khai LLM tự lưu trữ và dựa trên API có thể ảnh hưởng đáng kể đến hiệu suất và hiệu quả về chi phí của các ứng dụng RAG. Mỗi yếu tố này đều cần được cân nhắc cẩn thận để tối ưu hóa độ chính xác của truy xuất và hiệu quả của hệ thống
Những chiến lược để vượt qua
Để giảm thiểu những rủi ro này, các ứng dụng RAG cần phải trải qua quá trình lập kế hoạch một cách chi tiết và cẩn trọng. Không có giải pháp nào tốt hơn là dự đoán cho tương lai. Nó cũng cần phải trải qua quá trình thử nghiệm rộng rãi trên nhiều tình huống, bao gồm chất lượng truy xuất, ngăn ngừa ảo giác, bảo vệ quyền riêng tư và bảo mật.
Thế giới thực là điểm yếu của hầu hết các sản phẩm dữ liệu sản xuất. Đúng là sử dụng cùng một dữ liệu pubmed cũ sẽ cung cấp cho bạn một đường ống hoạt động nhưng khi RAG tương tác với dữ liệu thực từ các tạp chí khác nhau, nó sẽ thất bại thảm hại. Việc giám sát và cập nhật hệ thống dựa trên phản hồi và cách sử dụng thực tế là rất quan trọng để cải tiến liên tục. Điều quan trọng là phải xây dựng RAG ở quy mô nhỏ hơn bằng cách sử dụng dữ liệu thực từ nhiều nguồn khác nhau, sau đó mở rộng quy mô lên quy mô lớn. Trong thế giới ngày nay, điện toán và không gian rất rẻ, hãy tập trung vào bảo mật thông tin, cơ sở hạ tầng, những thứ như tích hợp SSO, chứng chỉ SOC2, v.v. để khi bạn xây dựng RAG, bạn sẽ có thể chia sẻ với khách hàng một cách tự tin.
Hơn nữa, việc lựa chọn cơ sở hạ tầng kỹ thuật phù hợp, đảm bảo chất lượng dữ liệu và triển khai các biện pháp bảo mật mạnh mẽ là chìa khóa để triển khai ứng dụng RAG thành công trong môi trường sản xuất. Hãy nghĩ về các đường ống dữ liệu trong tương lai. Đưa ra các kịch bản “nếu như” và xây dựng tài liệu và cơ sở mã của bạn theo đó. Không ai nói về điều đó, nhưng hãy xây dựng hợp đồng của bạn theo cách mà khách hàng của bạn biết về các “Thất bại” có thể xảy ra và “an toàn khi thất bại” tại chỗ.
Nếu bạn đang xử lý một miền cụ thể, hãy biết rằng mô hình bạn sử dụng để tạo nhúng sẽ quan trọng. Tôi đã thấy một động lực hướng tới việc sử dụng các mô hình nhỏ hơn để nhúng; tuy nhiên, nếu kích thước từ vựng cho mô hình đó không chứa các từ khóa từ miền của bạn, thì bạn sẽ phải chịu số phận. Đúng vậy, điều này có nghĩa là phải chi nhiều hơn một chút, hoặc nếu bạn có đủ tiền, thì phải chi nhiều hơn nữa để xây dựng LLM của riêng bạn duy trì từ vựng cho miền của bạn. Việc tinh chỉnh mô hình đơn giản sẽ không giải quyết được vấn đề này. Hãy nhớ rằng, những thứ bạn muốn truy xuất càng cao thì hiệu suất càng kém.
Cuối cùng là Tính toàn vẹn của thương hiệu. Hãy gọi một cái xẻng là một cái xẻng. Một thương hiệu là một bản sắc được tạo ra. Chúng ta muốn bắt chước thương hiệu một cách giống nhất có thể. Hãy coi nhiệm vụ này như là “lớp kem” cuối cùng trên chiếc bánh RAG. Trước tiên, hãy hoàn thành nhiệm vụ, trích xuất những gì bạn cần và tạo văn bản phẳng từ các bản tóm tắt để bạn có số liệu chính xác. Sau đó và chỉ sau đó, hãy yêu cầu diễn đạt lại thành một thuật ngữ thương hiệu.
Chúc may mắn! Nếu công ty bạn cần trợ giúp, hãy tìm đến MyGPT và sử dụng dịch vụ của chúng tôi trong những ứng dụng RAG thực tế mà bạn gặp phải.