Có thể đây không phải là lần đầu tiên bạn đọc về RAG và cũng không phải là lần cuối cùng nói về nó. Đối với RAG, đây là xu hướng mới được phát triển nhanh chóng và liên tục cải tiến trong các ứng dụng Generative AI. Vì vậy tìm hiểu về RAG sẽ mang lại cho chúng ta nhiều điều thú vị:
- Thứ nhất, nó cung cấp và mở rộng chức năng LLM với các trường hợp sử dụng thực tế, trải rộng trên nhiều lĩnh vực khác nhau cho nhiều mục đích khác nhau.
- Và một điều nữa là nó làm giảm bớt nỗi sợ hãi khi đưa vào ứng dụng trong thực tế về khả năng LLM dễ bị nhầm lẫn hoặc ảo giác, cung cấp giải pháp hiệu quả về mặt chi phí cho các phản ứng hợp lý của LLM trong quá trình triển khai.
Bài viết này sử dụng các tài liệu nghiên cứu đã được công bố, các blog trải nghiệm và ví dụ về mã nguồn để khảo sát các khía cạnh khác nhau của mô hình RAG, bao gồm các phương pháp, chức năng, kiến trúc, loại, lợi ích, hạn chế và hướng đi trong tương lai. Chúng ta cũng sẽ đề cập đến các đánh giá về RAG, một khía cạnh quan trọng của nghiên cứu đang nổi lên trong các ứng dụng Generative AI.
Đầu tiên, hãy bắt đầu với RAG là gì?
Thế hệ tăng cường truy xuất (RAG) là gì?
Armand Ruiz, người sáng lập nocode.ai, tuyên bố rằng RAG đánh dấu “một sự phát triển đáng kể trong lĩnh vực AI, đặc biệt là trong việc nâng cao khả năng của các mô hình ngôn ngữ lớn (LLM)”. Để mở rộng khái niệm này, một nghiên cứu khảo sát của Gao et al. gợi ý rằng RAG đã nổi lên như một giải pháp AI đầy hứa hẹn để mở rộng phạm vi của nó. Bằng cách kết hợp kiến thức từ nguồn dữ liệu bên ngoài, RAG nâng cao tính chính xác và độ tin cậy của việc tạo, đặc biệt đối với các nhiệm vụ đòi hỏi nhiều kiến thức, cập nhật kiến thức liên tục và tích hợp thông tin theo lĩnh vực cụ thể.
Một khảo sát kiểm tra toàn diện khác về kỹ thuật RAG nâng cao của Huang et al. cũng khẳng định rằng RAG “kết hợp các phương pháp truy xuất với các tiến bộ học sâu để giải quyết các hạn chế tĩnh của LLM bằng cách cho phép tích hợp động các thông tin bên ngoài cập nhật”. Nghiên cứu nêu bật những cải tiến đáng kể về khả năng của LLM.
Nói một cách đơn giản hơn, RAG nâng cao LLM bằng cách bổ sung cho chúng bối cảnh bên ngoài, như cơ sở dữ liệu và hồ sơ khách hàng, để cải thiện độ chính xác và phản hồi tổng quát của chúng.
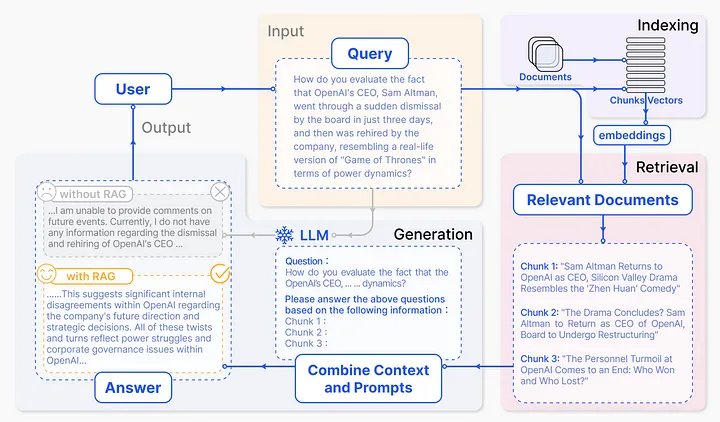
Từ những thông tin được cung cấp ở trên, có vẻ rõ ràng rằng bằng cách kết hợp bối cảnh bên ngoài từ cửa hàng bên ngoài và thông tin đầu vào của người dùng, LLM có thể tạo ra phản hồi chính xác và phù hợp với ngữ cảnh. Phương pháp này, như một phần của ứng dụng RAG điển hình, được minh họa dưới dạng luồng dữ liệu RAG cấp cao trong Hình 1.
Tại sao nên sử dụng RAG?
Mặc dù LLM khiến chúng ta choáng ngợp với những phản ứng sáng tạo và giống con người nhưng chúng phải đối mặt với những hạn chế và thách thức. Bởi vì LLM là công cụ suy luận dựa trên xác suất nên đầu ra của chúng có thể thay đổi theo từng đầu vào. “Nếu đầu vào về cơ bản là vô hạn và đầu ra về cơ bản là vô hạn, làm thế nào để bạn chứng minh [nó] an toàn?” để sử dụng, hỏi Hugh Harvey của Hardian Health.
Tuy nhiên, The Economist viết rằng, một kỹ thuật đang được xem xét rộng rãi để giải quyết những thách thức này đối với AI trong Y tế là sử dụng RAG. Tương tự, Gao et al. đề xuất rằng RAG cải thiện LLM bằng cách truy xuất các phân đoạn tài liệu thích hợp từ các nguồn bên ngoài bằng cách sử dụng sự tương đồng về ngữ nghĩa. Bằng cách tận dụng kiến thức bên ngoài, RAG giảm thiểu vấn đề tạo ra nội dung không chính xác.
Các lý do khác, Armand Ruiz liệt kê, để sử dụng RAG được chia thành các loại sau:
Giới hạn kiến thức: LLM dựa vào dữ liệu đào tạo hạn chế, trong khi RAG khai thác kiến thức bên ngoài, kết hợp với thông tin đầu vào của người dùng, để cải thiện độ chính xác và tính đầy đủ.
Rủi ro ảo giác: LLM có thể bị nhầm lẫn. RAG bổ sung dữ liệu bên ngoài và nguồn dẫn xuất để cải thiện độ chính xác và khả năng xác minh.
Hạn chế theo ngữ cảnh: LLM thiếu bối cảnh dữ liệu riêng tư. RAG thêm dữ liệu theo lĩnh vực cụ thể để tạo nên một phản hồi tốt hơn.
Khả năng kiểm tra: RAG nâng cao khả năng kiểm tra bằng cách trích dẫn các nguồn trong các phản hồi của Generative AI.
Tất cả những điều trên làm cho nó trở thành một lựa chọn hấp dẫn, vì RAG chủ yếu nhằm mục đích cải thiện chất lượng phản hồi LLM thông qua ba loại RAG riêng biệt.
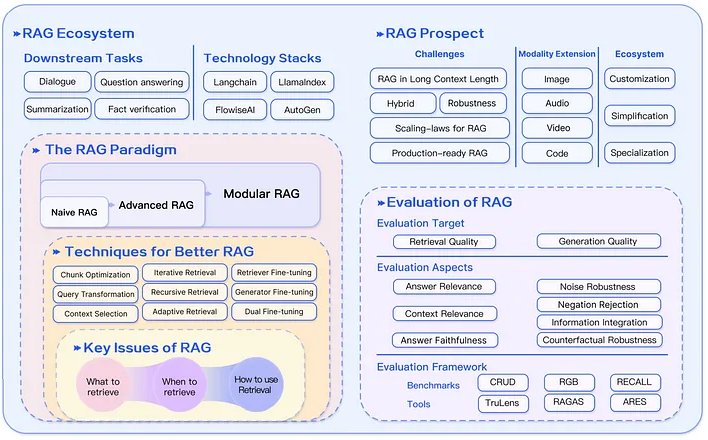
Các loại RAG
Mức độ phổ biến của RAG đang ngày càng tăng và cùng với đó, mô hình nghiên cứu của nó không ngừng phát triển. RAG có thể được phân loại thành ba loại: RAG ngây thơ, RAG nâng cao và RAG mô-đun, như minh họa trong Hình 2.
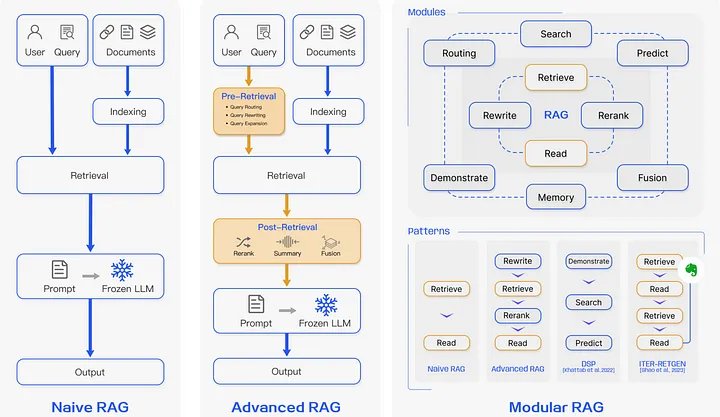
Naive RAG
Như tên cho thấy, đây là cách sớm nhất, đơn giản nhất và dễ thực hiện nhất. Sau một chuỗi các giai đoạn đơn giản, nó bao gồm ba bước: lập chỉ mục, truy xuất và tạo sinh.
Lập chỉ mục
Lập chỉ mục bắt đầu bằng cách làm sạch và trích xuất dữ liệu thô từ nhiều định dạng khác nhau như PDF, HTML, Word và Markdown, sau đó được chuyển đổi thành văn bản thuần túy. Để giải quyết các hạn chế về ngữ cảnh của mô hình ngôn ngữ, văn bản được chia thành các phần nhỏ hơn, được mã hóa thành vectơ bằng mô hình nhúng và được lưu trữ trong cơ sở dữ liệu vectơ. Điều này cho phép tìm kiếm sự tương đồng hiệu quả trong quá trình tra cứu.
Truy xuất
Sau khi lập chỉ mục, các truy vấn của người dùng được mã hóa thành vectơ bằng cách sử dụng cùng một mô hình nhúng được sử dụng để lập chỉ mục. Thuật toán tìm kiếm truy xuất tìm thấy K đoạn phù hợp nhất phù hợp với truy vấn về mặt ngữ nghĩa. Các khối tài liệu được truy xuất này, cùng với truy vấn, sau đó được kết hợp lại thành một lời nhắc mạch lạc cho giai đoạn tạo cuối cùng của LLM.
Tạo phản hồi
Lời nhắc kết hợp sẽ kích hoạt LLM phản hồi, tạo ra phản hồi bằng cách sử dụng kiến thức tham số vốn có của nó và giới hạn phản hồi của nó đối với kiến thức trong đoạn tài liệu được truy xuất.
Tuy nhiên, Naive RAG có những nhược điểm:
- Đầu tiên, giai đoạn truy xuất gặp khó khăn với độ chính xác và khả năng thu hồi, nghĩa là nó có thể dễ dàng truy xuất các tài liệu chưa được sắp xếp.
- Thứ hai, việc tạo ra sau đó có thể tạo ra ảo giác vì tài liệu được truy xuất không chính xác hoặc không được căn chỉnh.
- Hơn nữa, trong một số trường hợp, giai đoạn này có thể “bị ảnh hưởng bởi sự không liên quan, [dư thừa], độc tính hoặc sai lệch ở đầu ra, làm giảm chất lượng và độ tin cậy của phản hồi”.
Những thiếu sót này được giải quyết với Advanced RAG.
RAG nâng cao
RAG nâng cao cải thiện và tập trung vào chất lượng của giai đoạn truy xuất. Nó kết hợp các chiến lược truy xuất trước và sau truy xuất. Trong khi truy xuất trước tập trung vào các kỹ thuật lập chỉ mục thông qua việc sử dụng phương pháp cửa sổ trượt, phân đoạn chi tiết và sử dụng siêu dữ liệu, thì truy xuất sau tập trung vào việc sắp xếp lại, định vị lại và rút ngắn các phần thành các phần quan trọng sao cho chỉ các tài liệu phù hợp nhất sẽ được chọn và đưa vào LLM.
Theo Huang và các cộng sự: Xem xét toàn diện tất cả các giai đoạn của giai đoạn truy xuất: trước truy xuất, sau truy xuất và tạo, đưa ra góc nhìn sâu sắc trong nghiên cứu và phát triển trong từng giai đoạn, hoàn toàn từ quan điểm truy xuất.
Các framework như LlamaIndex, LangChain và HayStack đã triển khai khái niệm truy xuất trước và sau này dưới dạng công cụ truy xuất.
Việc cung cấp các tài liệu phù hợp nhất, được xếp hạng lại và rút gọn không chỉ cải thiện phản hồi, mức độ liên quan và độ tin cậy của LLM mà còn rút ngắn cửa sổ ngữ cảnh, giảm chi phí suy luận tổng thể.
RAG mô-đun
RAG mô-đun vượt xa hai cách tiếp cận trên. Nó linh hoạt bằng cách điều chỉnh cách tiếp cận mô-đun và giới thiệu các mẫu mới hơn, cả hai đều kết hợp các chiến lược hiệu quả.
Ví dụ: đối với các thành phần mô-đun, nó có thể bổ sung chiến lược tìm kiếm tương tự tốt hơn để truy xuất các thành phần; nó có thể viết lại hoặc sửa đổi truy vấn để có kết quả tìm kiếm nâng cao; và nó có thể định tuyến tìm kiếm trên nhiều nguồn dữ liệu khác nhau, bao gồm công cụ tìm kiếm, cơ sở dữ liệu và biểu đồ tri thức, sử dụng mã do LLM tạo và ngôn ngữ truy vấn.
Đối với các mẫu mới hơn, nó có thể triển khai các quy trình xử lý dữ liệu RAG hiệu quả để sắp xếp lại và sắp xếp lại các tài liệu được truy xuất.
Trong bất kỳ loại RAG nào bạn sử dụng để triển khai, không có loại nào đảm bảo không có sự thiếu chính xác hoặc nhầm lẫn. Một số lỗi vẫn có thể xuất hiện. Loại RAG này tiếp tục được nghiên cứu kỹ lưỡng để phát triển trong tương lai: AI có khả năng tạo ra không có ảo giác hoặc không chính xác.
Vì vậy, lời cảnh báo là: tin tưởng nhưng hãy xác minh phản hồi RAG được tạo. Tốt hơn nữa, hãy luôn kiểm tra các nguồn được sử dụng để tạo ra phản hồi.
RAG hoạt động như thế nào?
Đến bây giờ, bạn đã có trực giác về cách RAG hoạt động ở cấp độ cao, bao gồm hai giai đoạn riêng biệt – truy xuất và tạo sinh – mỗi giai đoạn có mục đích cũng như mức độ phức tạp và triển khai riêng biệt, như được mô tả trong Hình 3.
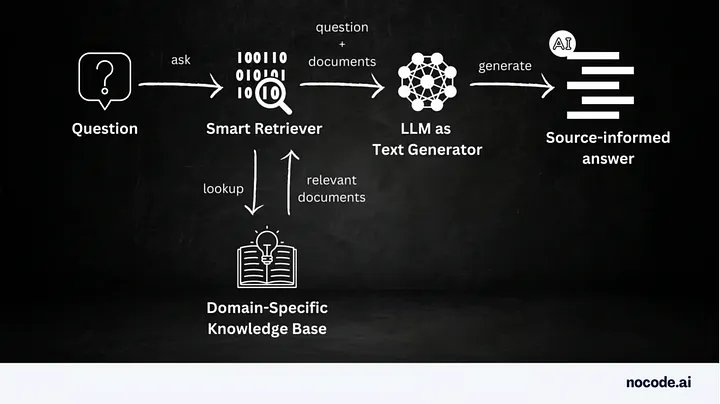
Trong giai đoạn truy xuất, các chiến lược tìm kiếm hiệu quả sẽ tìm nạp các tài liệu có ngữ nghĩa tương tự phù hợp nhất từ kho vectơ hoặc cơ sở kiến thức phù hợp với lời nhắc hoặc truy vấn của người dùng. Như đã lưu ý ở trên trong các loại RAG khác nhau, giai đoạn này rất quan trọng để đảm bảo rằng chỉ hầu hết các tài liệu có liên quan mới được kết hợp với lời nhắc cho giai đoạn thứ hai. Các khung AI tổng quát phổ biến như LangChain, LlamaIndex và Haystack triển khai những khung này như các công cụ truy xuất nâng cao. Damian Gil tập trung vào những kỹ thuật tiên tiến này trong blog hấp dẫn của anh ấy, Kỹ thuật nâng cao để cải thiện RAG của bạn.
Đối với giai đoạn tạo kết quả phản hồi, bối cảnh kết hợp và cô đọng được cung cấp cho LLM để tạo ra phản hồi cuối cùng. Một số kỹ thuật nhanh chóng có thể yêu cầu điều chỉnh giọng điệu và định dạng của phản hồi được trả về. Theo một số người thực hành RAG, trong giai đoạn tạo tạo sinh còn được gọi là tăng cường, do đó vị trí của nó trong từ viết tắt RAG.
Nhìn bề ngoài, hai giai đoạn này có vẻ đơn giản và tuần tự hơn nhưng có rất nhiều hoạt động tính toán phức tạp diễn ra ngầm. Các khung AI sáng tạo như LangChain, LlamaIndex, Haystack, HuggingFace và OpenAI và các cửa hàng vector như Pinecone và các cửa hàng vector khác trừu tượng hóa thông qua các API có lập trình, các khía cạnh chức năng của việc lập chỉ mục, tìm kiếm, truy xuất, xếp hạng lại và sắp xếp lại. Tất cả điều này giúp công việc của nhà phát triển trở nên dễ dàng hơn rất nhiều khi chỉ cần sử dụng các API khung để triển khai từng giai đoạn và viết RAG hoàn chỉnh cho một trường hợp sử dụng cụ thể.
Các trường hợp sử dụng phổ biến
Các ứng dụng dựa trên RAG đã chứng tỏ giá trị và khả năng sử dụng của chúng trên nhiều lĩnh vực khác nhau. Một số trường hợp kinh doanh đáng chú ý bao gồm sau đây:
- Hệ thống trả lời câu hỏi của khách hàng: Trong các lĩnh vực như chăm sóc sức khỏe, sản xuất và CNTT, các chatbot được tăng cường RAG có thể đưa ra câu hỏi bằng cách truy xuất thông tin ngữ cảnh có liên quan từ cơ sở kiến thức nội bộ để trả lời các truy vấn của khách hàng. Ví dụ: hãy xem xét một tổ chức chăm sóc sức khỏe sử dụng mô hình RAG để tạo ra một hệ thống cung cấp câu trả lời y tế chính xác bằng cách truy cập và giải thích tài liệu y khoa hoặc hồ sơ thử nghiệm nội bộ.
- Hệ thống đề xuất nội dung: Trong lĩnh vực RecSys, nó cải thiện sự tương tác của người dùng và mức độ tương tác với nội dung bằng cách tận dụng các công cụ truy xuất nâng cao để đưa ra đề xuất được cá nhân hóa.
- Phân tích nghiên cứu giáo dục và pháp lý: RAG đơn giản hóa và tạo ra các tài liệu nghiên cứu cô đọng về giáo dục. Để phân tích pháp lý và chuẩn bị các vụ việc pháp luật, nó có thể truy cập và tóm tắt các tài liệu pháp lý liên quan để phân tích.
- Tạo và tóm tắt nội dung: Mô hình RAG giúp việc tạo nội dung dễ dàng hơn bằng cách tìm kiếm thông tin hữu ích từ nhiều nơi khác nhau, bao gồm cả cơ sở kiến thức nội bộ. Họ có thể hỗ trợ bằng các báo cáo và tóm tắt cô đọng. Ví dụ: người viết và nhà nghiên cứu tại một công ty tin tức có thể sử dụng mô hình RAG nội bộ, cùng với kho hoặc cơ sở tin tức kiến thức nội bộ, để tạo các bài báo hoặc bản tóm tắt ngắn của các báo cáo dài.
Thành phần RAG
Kiến trúc RAG tiêu chuẩn bao gồm các thành phần lập chỉ mục, truy xuất và tạo sinh câu phản hồi, mỗi thành phần có các tùy chọn phần mềm nguồn mở và nguồn đóng. Lựa chọn của bạn sẽ bị ảnh hưởng bởi các yếu tố như ngân sách, kỹ năng nội bộ và sự hỗ trợ của cộng đồng cho từng thành phần.
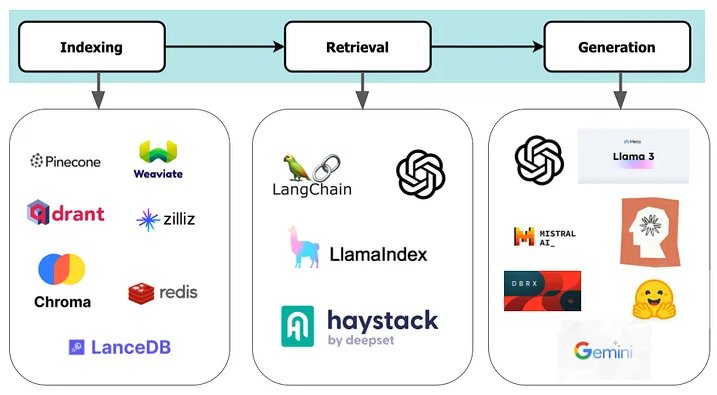
Lập chỉ mục: Trong giai đoạn này, các tài liệu được xử lý, phân đoạn và chuyển đổi thành các phần nhúng dưới dạng số để lưu trữ trong cơ sở dữ liệu vectơ. Hiệu quả của việc xây dựng chỉ mục trong cơ sở dữ liệu vectơ và tìm kiếm tiếp theo của nó ảnh hưởng đến khả năng truy xuất ngữ cảnh chính xác.
Theo Gao và cộng sự. đề xuất các phương pháp lập chỉ mục được tối ưu hóa bao gồm phân đoạn mã thông báo, cửa sổ trượt có chồng chéo, thêm siêu dữ liệu (số trang, URL, tác giả, danh mục, dấu thời gian, v.v.) để làm phong phú các khối và thiết lập hệ thống phân cấp tài liệu cha-con trong các khối. Tất cả điều này tạo điều kiện thuận lợi cho tác vụ tìm kiếm truy xuất các đoạn có liên quan nhất về mặt ngữ nghĩa đối với truy vấn của người dùng.
Nhiều tùy chọn lưu trữ vectơ nguồn mở và nguồn đóng có sẵn cho giai đoạn này, như trong Hình 4.
Truy xuất: Trong RAG, việc tìm kiếm các tài liệu liên quan một cách hiệu quả là điều cần thiết. Điều này liên quan đến những cân nhắc chính như nguồn truy xuất, mức độ chi tiết, xử lý trước, xếp hạng lại và chọn mô hình nhúng. Các framework phổ biến như LangChain, LlamaIndex, Haystack và OpenAI cung cấp giao diện có lập trình cũng như các mô hình nhúng để bạn lựa chọn. Hoàng và cộng sự. phác thảo một số chiến lược truy xuất như tìm kiếm và xếp hạng, sắp xếp lại, thao tác truy vấn và lọc. Những cách tiếp cận này cũng được thảo luận ở trên trong các phương pháp RAG nâng cao và mô-đun.
Tạo sinh phản hồi: Cuối cùng, giai đoạn này phụ thuộc rất nhiều vào hai giai đoạn trước. Nếu không lập chỉ mục thích hợp cho cơ sở tri thức và truy xuất các tài liệu liên quan đến truy vấn của người dùng, LLM có thể không tạo ra phản hồi mạch lạc như mong muốn.
Theo Huang và cộng sự; và Gao và cộng sự. đề xuất các phương pháp khác nhau. Một là tinh chỉnh truy vấn và tài liệu của người dùng bằng kỹ thuật nhanh chóng. Một cách khác là ưu tiên các tài liệu có liên quan và điều chỉnh hệ thống cũng như lời nhắc của người dùng để tạo ra âm thanh và định dạng mong muốn.
Đối với giai đoạn này, bạn có thể sử dụng bất kỳ API nào của mô hình LLM được lưu trữ nguồn mở và nguồn đóng để tạo.
Kỹ thuật prompt, RAG và Fine-tuning
Kể từ khi phát hành ChatGPT và LLM trước đó, chúng đã thu hút được sự chú ý đáng kể do mức độ phổ biến, các trường hợp sử dụng có mục đích và mức độ phổ biến của nó. Một số kỹ thuật tối ưu hóa cho LLM đã bị nhầm lẫn hoặc bị nhầm lẫn với LLM tinh chỉnh và kỹ thuật prompt. Hơn nữa, mỗi cái đều khác biệt và có một kịch bản cụ thể cho phương pháp của nó.
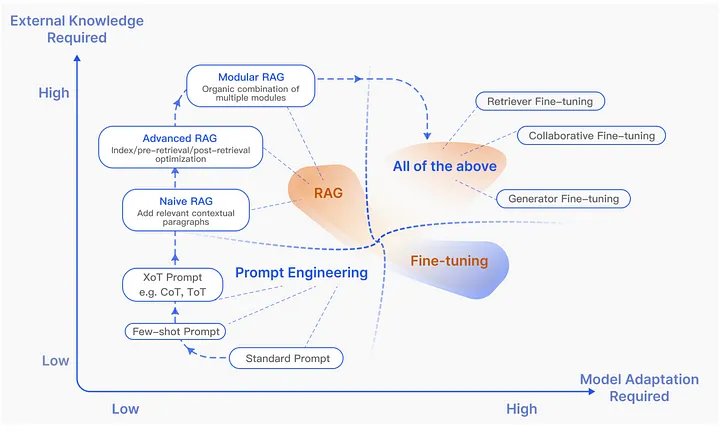
Hình trên, dưới dạng biểu đồ mô tả và minh họa sự khác biệt giữa chúng và khi nào bạn nên sử dụng từng phần, dựa trên hai trục: cơ sở kiến thức bên ngoài và yêu cầu thích ứng mô hình.
Từ biểu đồ này, chúng ta có thể kết luận rằng Kỹ thuật prompt bao gồm những thay đổi tối thiểu đối với mô hình hoặc cơ sở kiến thức bên ngoài. Nó sử dụng các khả năng kiến thức tham số vốn có của LLM, sử dụng các phương pháp prompt như zero-short, few-short learning hoặc suy luận chain of thought (CoT).
Ban đầu, trong Naive RAG, hầu như không cần điều chỉnh mô hình. Khi nghiên cứu advance RAG, module RAG và nâng cao sẽ cần kết hợp với các phương pháp fine tuning.
Tuy nhiên, việc tinh chỉnh yêu cầu đào tạo bổ sung mô hình với tập dữ liệu theo lĩnh vực cụ thể làm phát sinh thêm chi phí đào tạo. Nhà khoa học dữ liệu trưởng của Anyscale Waleed Khadus lập luận rằng việc tinh chỉnh cũng chỉ dành cho hình thức, không nhất thiết phải dành cho dữ liệu thực tế. Nó dẫn đến việc tạo ra một mô hình thích hợp cho các nhiệm vụ cụ thể của lĩnh vực được giải quyết trong từng trường hợp sử dụng thích hợp.
Hơn nữa, việc tinh chỉnh hình thức, định dạng, phong cách và giọng điệu phản hồi của người dùng là điều cần thiết. ChatGPT là một ví dụ về tinh chỉnh GPT4 cho hoạt động tương tác hướng dẫn và hỏi đáp.
Cả việc tinh chỉnh và RAG đều phải đối mặt với những thách thức. Việc tinh chỉnh cần thêm dữ liệu theo miền cụ thể để đào tạo, gặp khó khăn với dữ liệu lỗi thời, yêu cầu quyền truy cập vào các mô hình LLM nguồn mở và các giải pháp được lưu trữ, đồng thời có thể tạo ra kết quả không chính xác.
RAG phụ thuộc chủ yếu vào các kho lưu trữ vectơ có thể mở rộng, hỗ trợ các cơ chế truy xuất hiệu quả trong khung dành cho nhà phát triển AI và mong muốn các phương pháp tiếp cận RAG nâng cao và mô-đun để có kết quả tối ưu.
Ngoài những thách thức, mỗi thách thức đều có giá trị riêng cho trường hợp sử dụng cụ thể của nó. Tuy nhiên, tất cả những điều đó đều ổn và RAG hoạt động rất tốt trong hầu hết thời gian, nhưng còn khi chúng bị lỗi thì sao. Và bạn đánh giá chúng như thế nào?
Đánh giá RAG
Để đánh giá tính hiệu quả của các ứng dụng LLM dựa trên RAG, điều quan trọng là phải xem xét các tiêu chí như độ chính xác, độ trung thực, mức độ liên quan và độ mạnh mẽ. Tất cả điều này đã thúc đẩy nghiên cứu đáng kể về các khuôn khổ, phương pháp và thước đo để đánh giá hiệu quả tổng thể.
Các nghiên cứu gần đây đã tập trung vào việc đánh giá hiệu suất của mô hình RAG đối với các nhiệm vụ tiếp theo bằng cách sử dụng các số liệu truyền thống và đã được thiết lập như điểm số Kết hợp chính xác (EM) và F1, cùng với các thước đo khác được liệt kê trong Bảng 1, theo Gao et al. Các biện pháp truyền thống này chưa đủ và chưa hoàn thiện hoặc chưa được tiêu chuẩn hóa để định lượng các khía cạnh đánh giá RAG, từ đầu đến cuối.

Vì mục đích đó, nghiên cứu đáng kể gần đây tập trung vào hai lĩnh vực – khía cạnh dựa trên truy xuất và khía cạnh dựa trên thế hệ – để giới thiệu các khuôn khổ và điểm chuẩn nhằm đánh giá RAG một cách toàn diện và toàn diện. Huang và tại. trong cuộc khảo sát của họ, họ đã lập bảng các khuôn khổ và tiêu chuẩn toàn diện này trong Bảng 2.
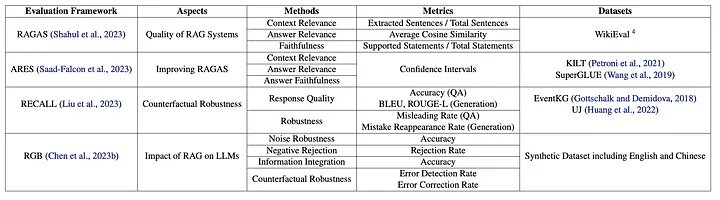
Trong khi các framework và điểm chuẩn dựa trên Truy xuất tập trung vào hiệu quả của việc truy xuất thông tin liên quan để hỗ trợ các tác vụ thì khía cạnh Dựa trên và Tạo sinh lại tập trung vào việc đánh giá chất lượng ngôn ngữ, tính mạch lạc, mức độ liên quan và độ chính xác đối với sự thật cơ bản.
Cùng với nhau, những điều này cung cấp một điểm khởi đầu đầy đủ để đánh giá RAG, mặc dù nghiên cứu đang diễn ra vẫn tiếp tục trong các lĩnh vực bao gồm chất lượng truy xuất, kết hợp tinh chỉnh các phương pháp RAG nâng cao, luật chia tỷ lệ cho RAG và RAG đa mô hình.
Tương lai của RAG
Những tuyên bố rằng các công việc trong RAGs đã được thực hiện và để đó là không trung thực. Một lĩnh vực phát triển nhanh chóng như GenAI sẽ không bao giờ hoàn thiện cả. Các tài liệu gần đây đề xuất các lĩnh vực nghiên cứu sâu hơn bao gồm:
- Các phương pháp tìm kiếm có thể module hoá để gắn và chạy trong các Advance RAG
- RAG dựa trên nhiều mô hình ngôn ngữ khác nhau
- Đơn giản hóa phương pháp truy xuất, đặc biệt trong quá trình truy xuất nhiều bước nhảy và sắp xếp lại
- RAG sẵn sàng sản xuất
- RAG có độ dài ngữ cảnh siêu lớn…
Ví dụ và hướng dẫn về RAG
Dưới đây là danh sách một vài ví dụ về RAG:
- RAG phẳng với kho vector Pinecone, kiến thức bên ngoài và Claude3
- Cách xây dựng chỉ mục truy xuất với Pinecone
- Cách tìm kiếm chỉ mục kiến thức bằng Pinecone
- RAG phẳng với LlamaIndex, Elaticsearch và Mistral
- Kỹ thuật RAG nâng cao
- Tạo ứng dụng RAG chất lượng cao với Databricks
- Xây dựng các ứng dụng LLM dựa trên RAG
- Xây dựng Chatbot tin tức tài chính theo thời gian thực RAG với Gemini và Qdrant
- Sách dạy nấu ăn GenAI
Tóm tắt
Tóm lại, tôi nhắc lại rằng đây không phải là lần đọc cuối cùng của bạn trên RAG. Vô số bài viết sẽ theo dõi và xuất hiện, cả về loại RAG cụ thể cũng như chi tiết triển khai và mã.
Trong bài viết này, khi tìm hiểu về RAG ở cấp độ cao, chúng tôi đã khám phá các mô hình RAG, các phương pháp được đề cập, chức năng, kiến trúc, loại, lợi ích, hạn chế và hướng đi trong tương lai bằng cách sử dụng các tài liệu nghiên cứu, blog thực tế và ví dụ về mã. Chúng tôi cũng thảo luận về các đánh giá RAG, một khía cạnh nghiên cứu mới nổi về các ứng dụng AI sáng tạo.
Đối với tôi, Hình 6 ghi lại và tóm tắt, với mức độ chi tiết trực quan sống động, bản chất của mô hình RAG.