


Bối cảnh NLP đã được cách mạng hóa nhờ sự ra đời của các mô hình ngôn ngữ lớn (LLM) như GPT-3 và GPT-4. Những mô hình này đã đặt nền tảng vững chắc cho việc tạo ra các ứng dụng mạnh mẽ và có thể mở rộng. Tuy nhiên, tiềm năng của những mô hình này bị ảnh hưởng rất nhiều bởi chất lượng của lời nhắc, điều này nêu bật tầm quan trọng của kỹ thuật nhanh chóng.
Hơn nữa, các ứng dụng NLP trong thế giới thực thường yêu cầu độ phức tạp cao hơn mức mà một phiên ChatGPT có thể cung cấp. Đây là lúc LangChain phát huy tác dụng!
Sản phẩm trí tuệ của Harrison Chase, LangChain, là một thư viện Python được thiết kế để giúp bạn tận dụng sức mạnh của LLM để xây dựng các ứng dụng NLP tùy chỉnh. Tính đến tháng 5 năm 2023, thư viện thay đổi cuộc chơi này đã thu nhận được gần 40.000 sao trên GitHub.
Hướng dẫn toàn diện dành cho người mới bắt đầu này cung cấp phần giới thiệu kỹ lưỡng về LangChain, cung cấp thông tin khám phá chi tiết về các tính năng cốt lõi của nó. Nó hướng dẫn bạn quy trình xây dựng một ứng dụng cơ bản bằng cách sử dụng LangChain và chia sẻ các mẹo có giá trị cũng như các phương pháp hay nhất trong ngành để tận dụng tối đa khuôn khổ mạnh mẽ này. Cho dù bạn là người mới sử dụng Mô hình học ngôn ngữ (LLM) hay đang tìm kiếm một cách hiệu quả hơn để phát triển các ứng dụng tạo ngôn ngữ, hướng dẫn này đóng vai trò là nguồn tài nguyên quý giá giúp bạn tận dụng khả năng của LLM với LangChain.
Tổng quan về mô-đun LangChain
Các mô-đun này đóng vai trò là sự trừu tượng hóa cơ bản tạo thành nền tảng của bất kỳ ứng dụng nào được cung cấp bởi Mô hình ngôn ngữ (LLM). LangChain cung cấp các giao diện được chuẩn hóa và thích ứng cho từng mô-đun. Ngoài ra, LangChain còn cung cấp các tích hợp bên ngoài và thậm chí cả các triển khai sẵn sàng để sử dụng liền mạch. Hãy tìm hiểu sâu hơn về các mô-đun này.
LLM:
LLM là thành phần cơ bản của LangChain. Về cơ bản, nó là một trình bao bọc xung quanh một mô hình ngôn ngữ lớn giúp sử dụng chức năng và khả năng của một mô hình ngôn ngữ lớn cụ thể.
Chuỗi:
Như đã nêu trước đó, LLM (Mô hình ngôn ngữ) đóng vai trò là đơn vị cơ bản trong LangChain. Tuy nhiên, phù hợp với khái niệm “LangChain”, nó cung cấp khả năng liên kết nhiều cuộc gọi LLM với nhau để giải quyết các mục tiêu cụ thể.
Ví dụ: bạn có thể có nhu cầu truy xuất dữ liệu từ một URL cụ thể, tóm tắt văn bản được truy xuất và sử dụng bản tóm tắt kết quả để trả lời các câu hỏi.
Mặt khác, chuỗi cũng có thể đơn giản hơn về bản chất. Chẳng hạn, bạn có thể muốn thu thập dữ liệu đầu vào của người dùng, tạo lời nhắc bằng cách sử dụng đầu vào đó và tạo phản hồi dựa trên lời nhắc đã tạo.
Lời nhắc:
Lời nhắc đã trở thành một cách tiếp cận mô hình hóa phổ biến trong lập trình. Nó đơn giản hóa việc tạo và quản lý lời nhắc với các lớp và chức năng chuyên biệt, bao gồm cả PromptTemplate thiết yếu.
Trình tải và sử dụng tài liệu:
Các mô-đun Trình tải và sử dụng tài liệu của LangChain đơn giản hóa việc truy cập và tính toán dữ liệu. Trình tải tài liệu chuyển đổi các nguồn dữ liệu đa dạng thành văn bản để xử lý, trong khi mô-đun utils cung cấp các phiên hệ thống tương tác và đoạn mã để tính toán toán học .
Cơ sở dữ liệu véc tơ:
Loại chỉ mục được sử dụng rộng rãi liên quan đến việc tạo các nhúng số cho từng tài liệu bằng cách sử dụng Mô hình nhúng. Các phần nhúng này, cùng với các tài liệu liên quan, được lưu trữ trong một kho lưu trữ véc tơ. Kho véc tơ này cho phép truy xuất hiệu quả các tài liệu liên quan dựa trên các phần nhúng của chúng.
Đại lý:
LangChain cung cấp một cách tiếp cận linh hoạt cho các nhiệm vụ mà chuỗi các lệnh gọi mô hình ngôn ngữ không mang tính quyết định. “Đại lý” của nó có thể hành động dựa trên đầu vào của người dùng và các phản hồi trước đó. Thư viện cũng tích hợp với cơ sở dữ liệu vectơ và có khả năng bộ nhớ để giữ lại trạng thái giữa các cuộc gọi, cho phép tương tác nâng cao hơn.
Xây dựng ứng dụng
Bây giờ chúng ta đã hiểu về LangChain, hãy xây dựng ứng dụng PDF Q/A Bot bằng cách sử dụng LangChain và OpenAI. Trước tiên, hãy để tôi cho bạn xem sơ đồ kiến trúc cho ứng dụng của chúng ta và sau đó chúng ta sẽ bắt đầu tạo ứng dụng của mình.
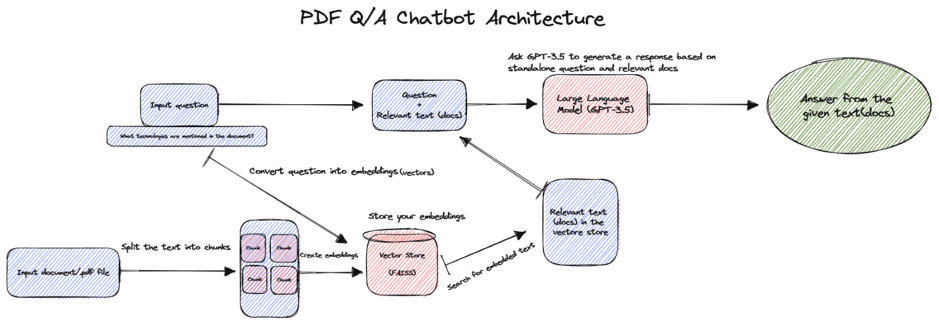
Dưới đây là mã ví dụ minh họa kiến trúc của chatbot Hỏi & Đáp dạng PDF được hỗ trợ bởi công nghệ mới. Mã này sử dụng mô hình ngôn ngữ OpenAI để xử lý ngôn ngữ tự nhiên, cơ sở dữ liệu FAISS để tìm kiếm sự tương đồng hiệu quả, PyPDF2 để đọc tệp PDF và Streamlit để tạo giao diện ứng dụng web. Chatbot tận dụng Chuỗi truy xuất hội thoại của LangChain để tìm câu trả lời phù hợp nhất từ tài liệu dựa trên câu hỏi của người dùng. Thiết lập tích hợp này mang lại trải nghiệm trả lời câu hỏi tương tác và chính xác cho người dùng.
Nhập các thư viện cần thiết
Câu lệnh nhập: Những dòng này nhập các thư viện và chức năng cần thiết để chạy ứng dụng.
- PyPDF2: Thư viện Python được sử dụng để đọc và thao tác với các tệp PDF.
- langchain: một khuôn khổ để phát triển các ứng dụng được cung cấp bởi các mô hình ngôn ngữ.
- streamlit: Một thư viện Python được sử dụng để tạo các ứng dụng web một cách nhanh chóng.
from PyPDF2 import PdfReader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharaterTextSplitter
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
import streamlit as st
from langchain.chains import ConversationalRetrivalChainNếu LangChain và OpenAI chưa được cài đặt, trước tiên bạn cần chạy các lệnh sau trong terminal.
pip install langchain openaiĐặt khóa API OpenAI
Bạn sẽ thay thế trình giữ chỗ bằng khóa API OpenAI mà bạn có thể truy cập từ API OpenAI. Dòng trên đặt khóa API OpenAI mà bạn cần để sử dụng các mô hình ngôn ngữ của OpenAI.
# Thiết lập API Key
OPENAI_API_KEY = "Khoá API của bạn"Giao diện Streamlit UI
Những dòng mã này tạo giao diện web bằng Streamlit. Người dùng được nhắc tải lên tệp PDF.
st.title("Chatbot Hỏi đáp")
st.write("Tải lên file PDF của bạn để bắt đầu hỏi nội dung")
uploaded_file = st.file_uploader("Chọn một file PDF", type="pdf")Đọc file PDF
Nếu một tệp đã được tải lên, khối này sẽ đọc tệp PDF, trích xuất văn bản từ mỗi trang và nối nó thành một chuỗi.
if uploaded_file:
doc_reader = PdfReader(upload_file)
raw_text = ""
for i, page in enumerate(doc_reader.pages):
text = page.extract_text()
if text:
raw_text += textTách văn bản thành phần nhỏ
Mô hình ngôn ngữ thường bị giới hạn bởi số lượng văn bản bạn có thể chuyển tới chúng. Vì vậy, cần phải chia chúng thành những phần nhỏ hơn. Nó cung cấp một số tiện ích để làm như vậy.
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap_200,
length_function=1en,
)
texts = text_splitter.split_text(raw_text)Việc sử dụng Bộ tách văn bản cũng có thể giúp cải thiện kết quả từ các tìm kiếm trong cửa hàng vectơ, chẳng hạn như. các đoạn nhỏ hơn đôi khi có thể phù hợp hơn với truy vấn. Ở đây chúng tôi đang chia văn bản thành 1k mã thông báo với 200 mã thông báo chồng lên nhau.
Nhúng
Ở đây, hàm OpenAIEmbeddings được sử dụng để tải xuống các phần nhúng, là các biểu diễn vectơ của dữ liệu văn bản. Sau đó, các phần nhúng này được sử dụng với FAISS để tạo chỉ mục tìm kiếm hiệu quả từ các đoạn văn bản.
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = FAISS.from_texts(texts, embeddings)Tạo chuỗi truy vấn trong hội thoại
Các chuỗi được phát triển là các thành phần mô-đun có thể dễ dàng tái sử dụng và kết nối. Chúng bao gồm các chuỗi hành động được xác định trước được gói gọn trong một dòng mã. Với các chuỗi này, không cần phải gọi mô hình GPT hoặc xác định các thuộc tính nhắc nhở một cách rõ ràng. Chuỗi cụ thể này cho phép bạn tham gia vào cuộc trò chuyện trong khi tham khảo tài liệu và lưu lại lịch sử tương tác.
qa = ConversationalRetrievalChain.from_llm(
llm=OpenAI(temperature=0, openai_api_key=OPENAI_API_KEY),
retriever=docsearch.as_retriever(),
return_source_documents=True,
)
chat_history = []
query = st.text_input("Hãy đặt câu hỏi về tài liệu đã được tải lên:")Streamlit để tạo phản hồi và hiển thị trong ứng dụng
Khối này chuẩn bị một phản hồi bao gồm câu trả lời được tạo và các tài liệu nguồn và hiển thị nó trên giao diện web.
generate_button = st.button("Tạo câu trả lời")
if generate_button and query:
with st.spinner("Đang tạo câu trả lời..."):
result = qa({"question": query, "chat_history": chat_history})
answer = result["answer"]
source_documents = result['source_document']
response = {
"answer": answer,
"source_documents": source_documents
}
st.write("response:", response)Chạy ứng dụng
Sau khi hoàn thành, hãy chạy ứng dụng của bạn để nhận kết quả mà bạn đã thực hiện. Chúc các bạn thành công!