


Tác giả: Aayush Mittal
ngày 21 tháng 3 năm 2024
Trong thế giới của xử lý ngôn ngữ tự nhiên (NLP), việc xây dựng các mô hình ngôn ngữ lớn và có khả năng hơn đã là động lực chính đằng sau nhiều tiến bộ gần đây. Tuy nhiên, khi những mô hình này phát triển về kích thước, yêu cầu tính toán cho việc huấn luyện và suy luận trở nên ngày càng đòi hỏi, đẩy ra giới hạn của các nguồn tài nguyên phần cứng có sẵn.
Giới thiệu Mixture-of-Experts (MoE), một kỹ thuật hứa hẹn giảm bớt gánh nặng tính toán này trong khi cho phép huấn luyện các mô hình ngôn ngữ lớn và mạnh mẽ hơn. Trong bài viết kỹ thuật này, chúng ta sẽ đi sâu vào thế giới của MoE, khám phá nguồn gốc, cách hoạt động bên trong và các ứng dụng của nó trong các mô hình ngôn ngữ dựa trên transformer.
Nguồn gốc của Mixture-of-Experts
Khái niệm về Mixture-of-Experts (MoE) có thể được truy vết về đầu những năm 1990 khi các nhà nghiên cứu khám phá ý tưởng về tính toán có điều kiện, nơi một phần của mạng nơ-ron được kích hoạt một cách chọn lọc dựa trên dữ liệu đầu vào. Một trong những công trình tiên phong trong lĩnh vực này là bài báo “Adaptive Mixture of Local Experts” của Jacobs và các cộng sự vào năm 1991, đề xuất một khung làm việc học có giám sát cho một bộ phận các mạng nơ-ron, mỗi mạng chuyên một khu vực khác nhau của không gian đầu vào.
Ý tưởng cốt lõi đằng sau MoE là có nhiều mạng “chuyên gia”, mỗi mạng chịu trách nhiệm xử lý một phần của dữ liệu đầu vào. Một cơ chế cửa, thường là một mạng nơ-ron, xác định mạng chuyên gia nào (hoặc nhóm mạng chuyên gia) nên xử lý một đầu vào cụ thể. Tiếp cận này cho phép mô hình phân bổ tài nguyên tính toán của mình một cách hiệu quả hơn bằng cách kích hoạt chỉ các chuyên gia liên quan cho mỗi đầu vào, thay vì sử dụng toàn bộ khả năng của mô hình cho mỗi đầu vào.
Trong suốt những năm qua, các nhà nghiên cứu đã khám phá và mở rộng ý tưởng về tính toán có điều kiện, dẫn đến các phát triển như MoEs phân cấp, xấp xỉ thấp cho tính toán có điều kiện, và các kỹ thuật để ước lượng độ dốc thông qua các nơ-ron ngẫu nhiên và hàm kích hoạt ngưỡng cứng.
Mixture-of-Experts trong Transformers
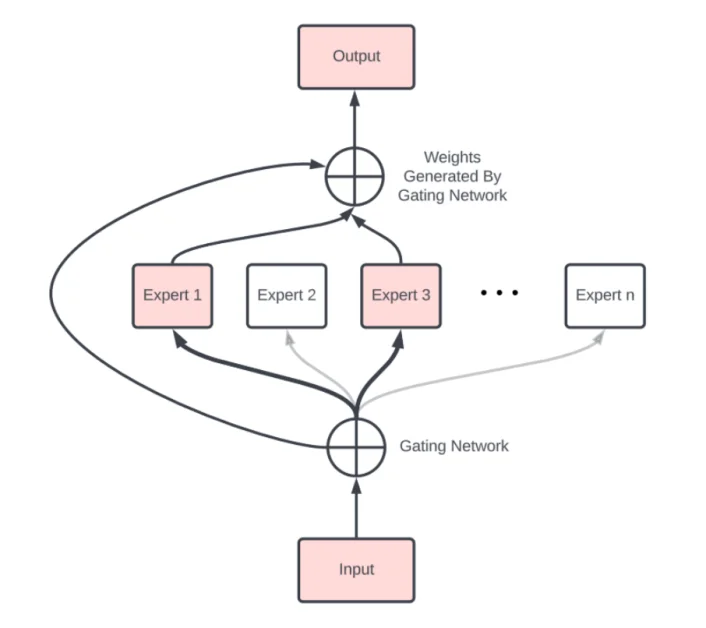
Mặc dù ý tưởng về MoE đã tồn tại trong nhiều thập kỷ, việc áp dụng nó vào các mô hình ngôn ngữ dựa trên transformer là khá mới mẻ. Các transformers, đã trở thành tiêu chuẩn không chính thức cho các mô hình ngôn ngữ tiên tiến, được tạo thành từ nhiều lớp, mỗi lớp chứa một cơ chế tự chú ý và một mạng nơ-ron truyền thẳng (FFN).
Điểm đột phá chính trong việc áp dụng MoE vào transformers là thay thế các lớp FFN dày đặc bằng các lớp MoE thưa thớt, mỗi lớp gồm nhiều mạng chuyên gia FFN và một cơ chế cửa. Cơ chế cửa xác định chuyên gia (hoặc nhóm chuyên gia) nào nên xử lý mỗi token đầu vào, cho phép mô hình kích hoạt một cách chọn lọc chỉ một phần của các chuyên gia cho một chuỗi đầu vào cụ thể.
Một trong những công trình sớm đã thể hiện tiềm năng của MoE trong transformers là bài báo “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer” của Shazeer và các cộng sự vào năm 2017. Công trình này giới thiệu khái niệm về một lớp MoE thưa thớt được cổng hóa, sử dụng một cơ chế cửa thêm tính thưa thớt và nhiễu vào quá trình lựa chọn chuyên gia, đảm bảo rằng chỉ một phần của các chuyên gia được kích hoạt cho mỗi đầu vào.
Kể từ đó, một số công trình khác đã tiến xa hơn trong việc áp dụng MoE vào transformers, giải quyết các thách thức như không ổn định trong quá trình huấn luyện, cân bằng tải và suy luận hiệu quả. Các ví dụ đáng chú ý bao gồm Switch Transformer (Fedus và cộng sự, 2021), ST-MoE (Zoph và cộng sự, 2022), và GLaM (Du và cộng sự, 2022).
Lợi ích của Mixture-of-Experts đối với Mô hình Ngôn ngữ
Lợi ích chính của việc sử dụng MoE trong các mô hình ngôn ngữ là khả năng mở rộng kích thước mô hình trong khi duy trì một chi phí tính toán tương đối không đổi trong quá trình suy luận. Bằng cách kích hoạt chỉ một phần của các chuyên gia cho mỗi token đầu vào, các mô hình MoE có thể đạt được sức mạnh biểu đạt tương đương với các mô hình dày đặc lớn hơn nhiều trong khi yêu cầu ít tính toán hơn đáng kể.
Ví dụ, giả sử có một mô hình ngôn ngữ với một lớp FFN dày đặc có 7 tỷ tham số. Nếu chúng ta thay thế lớp này bằng một lớp MoE gồm tám chuyên gia, mỗi chuyên gia có 7 tỷ tham số, tổng số lượng tham số tăng lên thành 56 tỷ. Tuy nhiên, trong quá trình suy luận, nếu chúng ta chỉ kích hoạt hai chuyên gia cho mỗi token, chi phí tính toán tương đương với một mô hình dày đặc có 14 tỷ tham số, vì nó tính toán hai phép nhân ma trận 7 tỷ tham số.
Hiệu quả tính toán này trong quá trình suy luận đặc biệt quý giá trong các tình huống triển khai nơi tài nguyên bị hạn chế, như thiết bị di động hoặc môi trường tính toán biên. Ngoài ra, yêu cầu tính toán giảm thiểu trong quá trình huấn luyện có thể dẫn đến tiết kiệm năng lượng đáng kể và làm giảm lượng carbon thải, phù hợp với sự tập trung ngày càng tăng về các thực hành AI bền vững.
Những Thách thức và Yếu tố Cần Xem Xét
Mặc dù các mô hình MoE mang lại những lợi ích hấp dẫn, việc áp dụng và triển khai chúng cũng đồng thời đặt ra nhiều thách thức và yếu tố cần xem xét:
- Sự Bất Ổn Trong Quá Trình Huấn Luyện: Các mô hình MoE thường dễ bị ổn định hơn so với các đối thủ dày đặc của chúng. Vấn đề này xuất phát từ tính thưa thớt và điều kiện của việc kích hoạt các chuyên gia, có thể dẫn đến thách thức trong việc truyền gradient và hội tụ. Các kỹ thuật như router z-loss (Zoph và cộng sự, 2022) đã được đề xuất để giảm thiểu những sự bất ổn này, nhưng vẫn cần thêm nghiên cứu.
- Feinetuning và Overfitting: Các mô hình MoE thường dễ bị overfit hơn trong quá trình feinetuning, đặc biệt là khi nhiệm vụ phía dưới có một tập dữ liệu tương đối nhỏ. Hành vi này được quy cho sự tăng cường và thưa thớt của các mô hình MoE, có thể dẫn đến sự chuyên sâu quá mức vào dữ liệu huấn luyện. Cần phải sử dụng các chiến lược regularization và feinetuning cẩn thận để giảm thiểu vấn đề này.
- Yêu Cầu Về Bộ Nhớ: Mặc dù các mô hình MoE có thể giảm chi phí tính toán trong quá trình suy luận, chúng thường có yêu cầu về bộ nhớ cao hơn so với các mô hình dày đặc cùng kích thước. Điều này là do tất cả các trọng số chuyên gia cần phải được tải vào bộ nhớ, mặc dù chỉ một phần được kích hoạt cho mỗi đầu vào. Ràng buộc về bộ nhớ có thể hạn chế khả năng mở rộng của các mô hình MoE trên các thiết bị có tài nguyên hạn chế.
- Cân Bằng Tải: Để đạt được hiệu quả tính toán tối ưu, việc cân bằng tải trọng qua các chuyên gia là rất quan trọng, đảm bảo rằng không có một chuyên gia nào bị quá tải trong khi các chuyên gia khác vẫn chưa được sử dụng hết. Cân bằng tải này thường được đạt được thông qua các mất mát phụ trợ trong quá trình huấn luyện và điều chỉnh cẩn thận của hệ số dung lượng, quyết định số lượng tối đa các token có thể được gán cho mỗi chuyên gia.
- Chi Phí Giao Tiếp: Trong các kịch bản huấn luyện và suy luận phân tán, các mô hình MoE có thể giới thiệu thêm chi phí giao tiếp do cần phải trao đổi thông tin kích hoạt và gradient qua các chuyên gia nằm trên các thiết bị hoặc bộ gia tốc khác nhau. Các chiến lược giao tiếp hiệu quả và thiết kế mô hình tinh thông về phần cứng là rất cần thiết để giảm thiểu chi phí giao tiếp này.
Mặc dù có những thách thức này, tiềm năng của các mô hình MoE trong việc tạo ra các mô hình ngôn ngữ lớn và có khả năng hơn đã thúc đẩy những nỗ lực nghiên cứu đáng kể để đối phó và giảm thiểu những vấn đề này.
Ví dụ: Mixtral 8x7B và GLaM
Để minh họa ứng dụng thực tế của MoE trong các mô hình ngôn ngữ, hãy xem xét hai ví dụ đáng chú ý: Mixtral 8x7B và GLaM.
Mixtral 8x7B là một biến thể MoE của mô hình ngôn ngữ Mistral, được phát triển bởi Anthropic. Nó bao gồm tám chuyên gia, mỗi chuyên gia có 7 tỷ tham số, dẫn đến tổng cộng 56 tỷ tham số. Tuy nhiên, trong quá trình suy luận, chỉ có hai chuyên gia được kích hoạt cho mỗi token, hiệu quả giảm chi phí tính toán xuống mức của một mô hình dày đặc có 14 tỷ tham số.
Mixtral 8x7B đã thể hiện được hiệu suất ấn tượng, vượt trội hơn mô hình Llama có 70 tỷ tham số trong khi cung cấp thời gian suy luận nhanh hơn nhiều. Một phiên bản được điều chỉnh theo hướng dẫn của Mixtral 8x7B, được gọi là Mixtral-8x7B-Instruct-v0.1, cũng đã được phát hành, nâng cao thêm khả năng của nó trong việc tuân theo các hướng dẫn bằng ngôn ngữ tự nhiên.
Một ví dụ đáng chú ý khác là GLaM (Google Language Model), một mô hình MoE quy mô lớn được phát triển bởi Google. GLaM sử dụng kiến trúc transformer chỉ có bộ giải mã và được huấn luyện trên một tập dữ liệu khổng lồ có 1.6 nghìn tỷ token. Mô hình đạt được hiệu suất ấn tượng trong các đánh giá few-shot và one-shot, phù hợp với chất lượng của GPT-3 trong khi chỉ sử dụng một phần ba năng lượng cần thiết để huấn luyện GPT-3.
Sự thành công của GLaM có thể được quy cho kiến trúc MoE hiệu quả của nó, cho phép huấn luyện một mô hình với một số lượng tham số lớn trong khi vẫn duy trì yêu cầu tính toán hợp lý. Mô hình cũng đã chứng minh được tiềm năng của các mô hình MoE để tiết kiệm năng lượng và bền vững về môi trường so với các mô hình dày đặc.
Kiến trúc Grok-1
Grok-1 là một mô hình MoE dựa trên transformer với một kiến trúc độc đáo được thiết kế để tối ưu hiệu suất và hiệu quả. Hãy khám phá các thông số chính:
- Tham số: Với 314 tỷ tham số đáng kinh ngạc, Grok-1 là mô hình LLM mở lớn nhất cho đến nay. Tuy nhiên, nhờ kiến trúc MoE, chỉ có 25% trọng số (khoảng 86 tỷ tham số) hoạt động vào bất kỳ thời điểm nào, nâng cao khả năng xử lý.
- Kiến trúc: Grok-1 sử dụng một kiến trúc Mixture-of-8-Experts, với mỗi token được xử lý bởi hai chuyên gia trong quá trình suy luận.
- Lớp: Mô hình bao gồm 64 lớp transformer, mỗi lớp tích hợp nhiều đầu chú ý và khối dày.
- Tokenization: Grok-1 sử dụng một bộ mã hóa từ SentencePiece với kích thước từ vựng là 131,072 token.
- Nhúng và Mã hóa Vị trí: Mô hình có các nhúng 6,144 chiều và sử dụng các nhúng vị trí quay, cho phép một cách diễn giải động hơn của dữ liệu so với các mã hóa vị trí cố định truyền thống.
- Chú ý: Grok-1 sử dụng 48 đầu chú ý cho các truy vấn và 8 đầu chú ý cho các khóa và giá trị, mỗi đầu chú ý có kích thước là 128.
- Độ dài Ngữ cảnh: Mô hình có thể xử lý các chuỗi lên đến 8,192 token, sử dụng độ chính xác bfloat16 để tính toán hiệu quả.
Hiệu suất và Chi tiết Triển khai
Grok-1 đã thể hiện được hiệu suất ấn tượng, vượt trội hơn so với LLaMa 2 70B và Mixtral 8x7B với điểm MMLU là 73%, thể hiện sự hiệu quả và độ chính xác của nó qua các bài kiểm tra khác nhau.
Tuy nhiên, điều quan trọng cần lưu ý là Grok-1 đòi hỏi tài nguyên GPU đáng kể do kích thước của nó. Triển khai hiện tại trong phiên bản mã nguồn mở tập trung vào việc xác minh tính chính xác của mô hình và sử dụng một triển khai lớp MoE không hiệu quả để tránh việc cần các nhân kernel tùy chỉnh.
Tuy nhiên, mô hình hỗ trợ chia tách kích hoạt và lượng tử hóa 8-bit, có thể tối ưu hiệu suất và giảm yêu cầu bộ nhớ.
Một điều đáng chú ý, xAI đã phát hành Grok-1 dưới giấy phép Apache 2.0, làm cho trọng số và kiến trúc của nó trở nên dễ truy cập đối với cộng đồng toàn cầu để sử dụng và đóng góp.
Phiên bản mã nguồn mở bao gồm một kho mã mẫu ví dụ JAX mà thể hiện cách tải và chạy mô hình Grok-1. Người dùng có thể tải trọng số kiểm tra bằng cách sử dụng một trình tải torrent hoặc trực tiếp thông qua HuggingFace Hub, tạo điều kiện cho việc truy cập dễ dàng vào mô hình đột phá này.
Tương lai của Mixture-of-Experts trong các Mô hình Ngôn ngữ
Khi nhu cầu về các mô hình ngôn ngữ lớn và có khả năng hơn tiếp tục tăng lên, dự kiến sự áp dụng của các kỹ thuật MoE sẽ tiếp tục được tăng tốc. Các nỗ lực nghiên cứu hiện đang tập trung vào việc giải quyết những thách thức còn lại, chẳng hạn như cải thiện tính ổn định của quá trình huấn luyện, giảm thiểu việc quá mức tinh chỉnh trong quá trình điều chỉnh cuối cùng, và tối ưu hóa yêu cầu bộ nhớ và giao tiếp.
Một hướng tiếp cận triển vọng là khám phá các kiến trúc MoE phân cấp, trong đó mỗi chuyên gia chính là một tập hợp của nhiều chuyên gia con. Hướng tiếp cận này có thể tiềm ẩn khả năng mở rộng và hiệu suất tính toán hơn nữa trong khi vẫn duy trì sức mạnh biểu đạt của các mô hình lớn.
Ngoài ra, việc phát triển các hệ thống phần cứng và phần mềm được tối ưu hóa cho các mô hình MoE là một lĩnh vực nghiên cứu đang hoạt động. Các bộ tăng tốc và khung trình huấn luyện phân tán được thiết kế để xử lý mẫu tính toán thưa thớt và có điều kiện của các mô hình MoE có thể tăng cường thêm hiệu suất và khả năng mở rộng của chúng.
Hơn nữa, việc kết hợp các kỹ thuật MoE với các tiến bộ khác trong mô hình hóa ngôn ngữ, chẳng hạn như các cơ chế chú ý thưa thớt, các chiến lược mã hóa token hiệu quả và các biểu diễn đa phương tiện, có thể dẫn đến các mô hình ngôn ngữ mạnh mẽ và linh hoạt hơn, có khả năng giải quyết một loạt các nhiệm vụ đa dạng.
Kết luận
Kỹ thuật Mixture-of-Experts đã nổi lên như một công cụ mạnh mẽ trong hành trình tìm kiếm các mô hình ngôn ngữ lớn và có khả năng hơn. Bằng cách kích hoạt các chuyên gia dựa trên dữ liệu đầu vào một cách lựa chọn, các mô hình MoE đề xuất một giải pháp hứa hẹn cho các thách thức tính toán liên quan đến việc mở rộng các mô hình dày đặc. Mặc dù vẫn còn các thách thức cần vượt qua, như sự không ổn định trong quá trình huấn luyện, quá mức tinh chỉnh, và yêu cầu bộ nhớ, nhưng những lợi ích tiềm ẩn của các mô hình MoE về hiệu quả tính toán, khả năng mở rộng và tính bền vững về môi trường làm cho chúng trở thành một lĩnh vực nghiên cứu và phát triển hấp dẫn.
Khi lĩnh vực xử lý ngôn ngữ tự nhiên tiếp tục đẩy ranh giới của những gì có thể, việc áp dụng các kỹ thuật MoE có thể sẽ đóng một vai trò quan trọng trong việc khả thi hóa thế hệ tiếp theo của các mô hình ngôn ngữ. Bằng cách kết hợp MoE với các tiến bộ khác trong kiến trúc mô hình, kỹ thuật huấn luyện và tối ưu hóa phần cứng, chúng ta có thể kỳ vọng vào những mô hình ngôn ngữ mạnh mẽ và linh hoạt hơn, có thể thực sự hiểu và giao tiếp với con người một cách tự nhiên và liền mạch.