

Với sự phát triển mạnh mẽ của GenAI, hiện đang có vô số các doanh nghiệp với khả năng sẵn có về đội ngũ công nghệ của mình đang thử nghiệm kỹ thuật RAG để tạo ra các ứng dụng sử dụng riêng trong doanh nghiệp riêng của mình tuy nhiên vẫn đang vật lộn khá chật vật để đạt được chất lượng của sản phẩm cuối cùng. Những ứng dụng RAG của họ không chỉ hoạt động kém mà còn không biết lý do và những bước tiếp theo cần thực hiện.
Trong hơn 1 năm trở lại đây, chúng tôi đã có điều kiện để tiếp cận với hàng chục nhóm phát triển và các chuyên gia AI đang phát triển các hệ thống này. Thông qua trao đổi và kinh nghiệm triển khai của chính mình trong các dự án thực tế, chúng tôi đã tìm ra nguyên nhân đó chính là sự không tương đồng về mặt ngữ nghĩa của:
- dữ liệu mà bạn đang có
- cùng với dữ liệu kiến thức cơ bản được lưu trữ trong các mô hình sử dụng
- song song với nhiệm vụ của ứng dụng mà bạn cần hướng tới
Trong bài viết này, MyGPT sẽ chia sẻ những hiểu biết của mình liên quan đến những rào cản trên cùng với những chiến lược giúp các bạn có thể vượt qua nhằm đưa ứng dụng của mình tiệm cận đến trạng thái hoạt động cuối cùng.
Lưu ý: Trong bài viết này chúng tôi chỉ đề cập đến RAG cơ bản (vanilla) và ứng dụng dạng hỏi đáp để minh hoạ cho bài viết, đây cũng là những ý tưởng cốt lõi để khái quát hoá cho các trường hợp sử dụng khác.
Tại sao lại là RAG?
RAG (Retrieval Augmented Generation) là một kỹ thuật hiện đang được các nhà phát triển ứng dụng tập trung nghiên cứu mạnh mẽ với kỳ vọng về khả năng bổ sung tri thức cho mô hình ngôn ngữ nhằm tạo nên các phản hồi riêng trong từng lĩnh vực cụ thể. Nghe có vẻ hấp dẫn và về bản chất, nó là một công cụ tìm kiếm cho AI trong ứng dụng của bạn.
RAG đã giành được sự quan tâm lớn ngay sau khi GPT-3 được phát hành. Một vấn đề cấp bách mà các doanh nghiệp phải đối mặt khi xây dựng AI chạy bằng LLM là các mô hình như GPT không được đào tạo trên dữ liệu và lĩnh vực riêng cụ thể của họ. Tuy nhiên, những người thực hành LLM đã nhanh chóng phát hiện ra rằng GPT hoạt động tốt một cách đáng ngạc nhiên khi bối cảnh cụ thể của doanh nghiệp (chẳng hạn như tài liệu hỗ trợ) được cung cấp trực tiếp trong lời nhắc. Điều này đã mang đến cho các doanh nghiệp một giải pháp thay thế cho nhiệm vụ khó khăn là tinh chỉnh các mô hình.
RAG, về nguyên tắc, đây là công cụ tìm kiếm chuyên biệt dành cho AI của bạn. Đặt câu hỏi, có thể kèm theo thông tin cụ thể của người dùng, và nó sẽ trả về ngữ cảnh phù hợp nhất cho GPT.
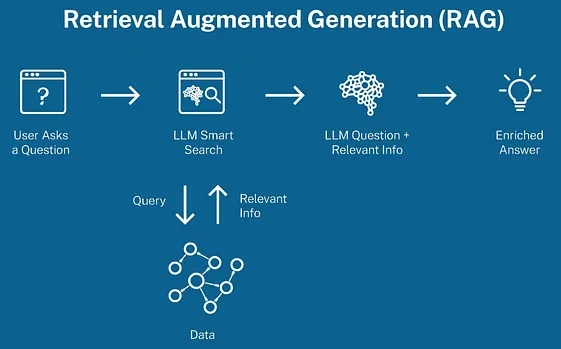
Mặc dù về mặt lý thuyết thì nghe có vẻ rất tuyệt vời, nhưng vẫn có những thách thức lớn trong việc tạo ra RAG đạt tiêu chuẩn ứng dụng cuối cùng, chúng ta sẽ tìm hiểu ở các phần sau.
Hãy bắt đầu với RAG Vanilla
RAG chỉ là một kỹ thuật, và một RAG hoạt động hoàn hảo, bất kể phần phụ trợ của nó, sẽ mang lại giá trị to lớn cho vô số trường hợp sử dụng thực tế. Trong phần này, chúng tôi cung cấp tổng quan về Vanilla RAG và hoạt động cơ bản của tìm kiếm ngữ nghĩa. Nếu bạn đã làm chủ được quá trình khó khăn khi tìm cách hợp lý hóa, bị từ chối và cuối cùng là chấp nhận sự kỳ diệu của nhúng vector, thì hãy thoải mái bỏ qua phần này.
Vanilla RAG (định nghĩa): Một công cụ tìm kiếm ngữ nghĩa một bước lưu trữ kiến thức, chẳng hạn như tài liệu hỗ trợ, trong cơ sở dữ liệu vectơ, (ví dụ như Pinecone) sử dụng mô hình nhúng có sẵn. Sau đó, việc truy xuất thông tin được thực hiện bằng cách tạo nhúng vectơ từ văn bản của câu hỏi và sử dụng số liệu so sánh, chẳng hạn như độ tương đồng cosin, để xếp hạng top-k các tài liệu có liên quan nhất.
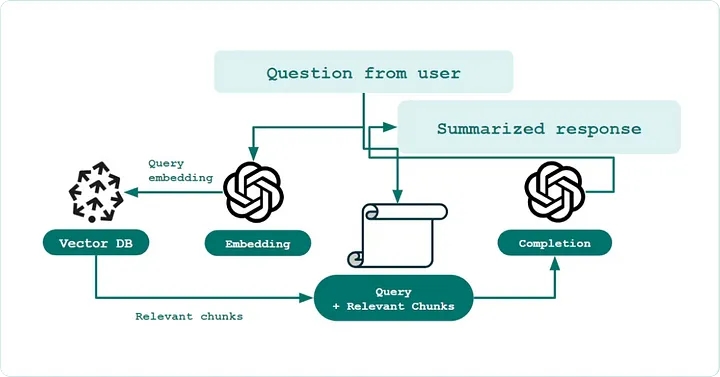
Chúng ta hãy phân tích sâu hơn nữa:
Mô hình nhúng vector lấy một chuỗi tùy ý và trả về một vector toán học có chiều cố định. Các mô hình nhúng phổ biến bao gồm text-embedding-ada-002 của OpenAI và mô hình mới nhất của họ text-embedding-3-small. Các mô hình này dịch các khối văn bản thành các vector khoảng 1500 chiều và hầu như không có khả năng diễn giải của con người.
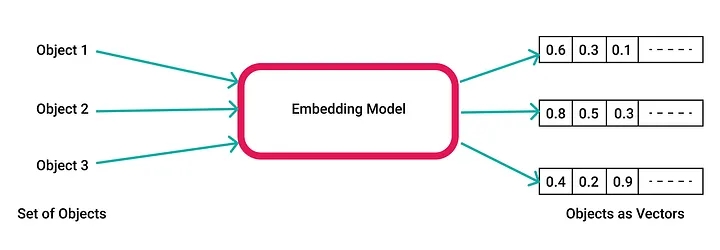
Các vectơ là công cụ hữu ích và phong phú vì bạn có thể lấy những thứ không định lượng được và 1) chia nhỏ chúng thành một mảng phong phú các chiều và 2) so sánh chúng về mặt định lượng. Một số ví dụ là:
- Bảng màu (đỏ, xanh lá cây, xanh lam) là một vectơ, trong đó mỗi giá trị nằm trong khoảng từ 0-255.
- Với các tiêu chuẩn của ngành như Chỉ số VN-Index, cổ phiếu có thể được biểu diễn dưới dạng một vectơ định lượng mức độ nhạy cảm của nó với các yếu tố kinh tế như tăng trưởng chung của Việt Nam, thay đổi về lãi suất, v.v.
- Các nền tảng như Zing MP3 có thể phân tích sở thích nghe nhạc của người dùng thành một vectơ, trong đó các thành phần có thể biểu diễn thể loại nhạc và các tính năng khác.
Độ tương đồng cosine được cho là thước đo thực tế để so sánh các vectơ trong tìm kiếm ngữ nghĩa và nó hoạt động bằng cách áp dụng cosine vào góc giữa hai vectơ thông qua tích vô hướng. Cosine càng gần 1 thì các vectơ càng giống nhau. (Có những cách khác để đo độ tương đồng ngữ nghĩa, nhưng thông thường đây không phải là nơi dễ dàng đạt được và chúng ta sẽ sử dụng độ tương đồng cosine trong suốt quá trình).
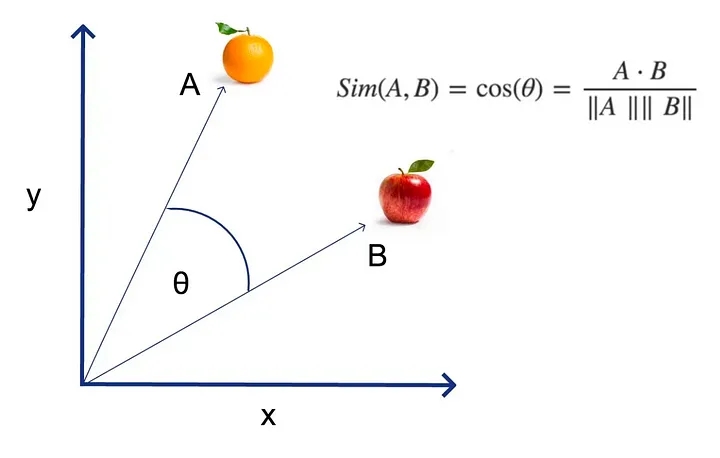
Tuy nhiên, không thể nhấn mạnh đủ rằng các số liệu so sánh vectơ như độ tương đồng cosin rất khó sử dụng vì chúng không có ý nghĩa tuyệt đối – Các giá trị phụ thuộc hoàn toàn vào mô hình nhúng và ngữ cảnh của văn bản liên quan.
Giả sử bạn khớp một câu hỏi với một câu trả lời và nhận được độ tương đồng cosin là 0,73. Đây có phải là sự khớp tốt không?
Để minh họa nhanh, hãy lấy câu hỏi “Mưa là gì?” và so sánh với ba văn bản có mức độ liên quan khác nhau. Chúng ta thấy trong bảng bên dưới rằng phạm vi và cách diễn giải các điểm tương đồng cosin từ việc sử dụng hai mô hình OpenAI khác nhau là rất khác nhau. Đối với mô hình đầu tiên, 0,73 biểu thị khớp hoàn toàn không liên quan, nhưng đối với mô hình thứ hai, 0,73 biểu thị mức độ liên quan cao. Điều này chỉ ra rằng bất kỳ hệ thống RAG nào hoạt động tốt đều cần hiệu chỉnh sự hiểu biết của riêng mình về ý nghĩa của những điểm số này.
Văn bản 1 (định nghĩa): “Mưa là sự kết tủa của các giọt nước từ các đám mây, rơi xuống đất khi chúng trở nên quá nặng và không thể lơ lửng trong không khí.”
Văn bản 2 (đề cập đến mưa): “Những cơn gió thổi hơi ẩm qua các ngọn núi là nguyên nhân gây ra mưa ở Seattle.”
Text3 (thông tin không liên quan): “VNPay là doanh nghiệp cung cấp cơ sở hạ tầng thanh toán.”

Không tương đồng ngữ nghĩa tạo ra vấn đề
Một số thách thức với Vanilla RAG có thể là do sự không tương đồng về mặt ngữ nghĩa và khả năng giải thích kém của các vector nhúng. Sự bất đồng về mặt ngữ nghĩa là sự bất tương đồng giữa ý nghĩa dự định của nhiệm vụ, sự hiểu biết của RAG về nó và kiến thức cơ bản được lưu trữ.
Điều này có tác dụng gì?
So sánh táo với cam
Có thể nói một cách đại khái rằng “câu hỏi không giống về mặt ngữ nghĩa với câu trả lời”, vì vậy việc so sánh trực tiếp giữa câu hỏi và cơ sở kiến thức thô của bạn sẽ chỉ mang lại hiệu quả nhất định.
Hãy tưởng tượng một luật sư cần tìm kiếm hàng ngàn tài liệu để tìm bằng chứng về gian lận của nhà đầu tư. Câu hỏi “Bằng chứng nào cho thấy A đã phạm tội gian lận tài chính? ” về cơ bản không có sự trùng lặp về mặt ngữ nghĩa với “A đã mua cổ phiếu XYZ vào ngày 14 tháng 3 ” (trong đó ngụ ý XYZ là đối thủ cạnh tranh và ngày 14 tháng 3 là một tuần trước khi công bố thu nhập).
Nhúng vector và độ tương tự cosin là mờ
Có một sự không hoàn hảo cố hữu trong khả năng của một vectơ để nắm bắt đầy đủ nội dung ngữ nghĩa của bất kỳ tuyên bố nào. Một sự không hoàn hảo tinh tế khác là không nhất thiết phải có sự tương đồng cosin dẫn đến thứ hạng chính xác, vì nó ngầm cho rằng mỗi chiều đều ngang bằng nhau.
Trên thực tế, tìm kiếm ngữ nghĩa với độ tương đồng cosin có xu hướng chính xác theo hướng, nhưng về bản chất là không rõ ràng. Nó có thể tuyệt vời cho các kết quả top 20, nhưng thường thì chỉ yêu cầu nó để xếp hạng câu trả lời tốt nhất một cách đáng tin cậy là quá nhiều.
Các mô hình nhúng được đào tạo sẵn trên internet không hiểu doanh nghiệp và lĩnh vực của bạn
Chúng tôi từng làm việc tại nhà máy Phích Rạng Đông, tại đó các từ ngữ như “chạy bình – Vận hành máy để sản xuất một mẫu ruột phích xác định“ hay “bình phích – ruột phích thuỷ tinh“ hay các mã như COT được sử dụng thường xuyên nhưng chúng lại được mô hình hiểu thành “run the battery” và “battery” và “Cột – Collumn” hoặc đối với trường hợp của Dauthau.INFO thì các gói sản phẩm có rất nhiều tên chứa từ “VIP” nhưng mô hình hiểu thành “nhân vật quan trọng”. Điều này chúng ta buộc phải tìm ra và xử lý chúng để hiểu một cách chính xác so với biểu diễn.
Nhìn chung, các nguồn bất tương đồng ngữ nghĩa kết hợp và góp phần vào tạo ta một thứ hạng không đáng tin cậy của kết quả trả về. Trong phần tiếp theo, chúng tôi minh họa cách chẩn đoán và giải quyết bất tương đồng ngữ nghĩa, và trong phần cuối, chúng tôi phác thảo các chiến lược ROI cao để cải thiện việc triển khai RAG.
Minh họa: Chẩn đoán và hạn chế sự bất tương đồng ngữ nghĩa
Trong minh họa này, chúng ta sẽ chẩn đoán sự bất tương đồng ngữ nghĩa hoàn toàn trong một ứng dụng RAG – tức là khi thực hiện các phép so sánh luôn cho kết quả tương đồng với nhiễu ngẫu nhiên có nghĩa là nó không đáng tin cậy. Từ đó, chúng ta cũng sẽ thấy những dấu hiệu ban đầu về cách cải thiện hiệu suất bằng cấu trúc bổ sung.
Ví dụ này được lấy từ một trường hợp sử dụng thực tế, nhưng được đơn giản hóa cho mục đích của bài đăng này để đi sâu vào vấn đề và minh họa cho điểm chính.
Chi tiết minh hoạ trên Google Colab: Xem chi tiết
Hãy tưởng tượng trường hợp sử dụng của một công ty khởi nghiệp thương mại điện tử đang xây dựng một ứng dụng RAG để sử dụng nội bộ nhằm tìm ra bảng SQL tốt nhất cho một câu hỏi kinh doanh nhất định. Dưới đây là thiết lập của ví dụ, trong đó chúng tôi:
1) Tạo hai lược đồ bảng SQL riêng biệt (sử dụng ChatGPT)
events.purchase_flow: Chứa các log tương tác từ người dùng đối với sản phẩm
base_table_text_1 = """
CREATE TABLE events.purchase_flow (
event_id SERIAL PRIMARY KEY,
user_id INT,
session_id INT,
event_type VARCHAR(50),
event_timestamp TIMESTAMP,
product_id INT,
product_category VARCHAR(50),
ip_address VARCHAR(50),
referrer VARCHAR(255),
test_mode BOOLEAN,
quantity INT DEFAULT 1,
price DECIMAL(10, 2)
);
"""aggregates.purchases: Bảng chứa phân tích tóm tắt
base_table_text_2 = """
CREATE TABLE aggregates.purchases (
day DATE,
product_category VARCHAR(50),
user_demographic VARCHAR(50),
used_coupon BOOLEAN,
distinct_users INT,
total_views INT,
total_purchases INT,
total_revenue DECIMAL(10, 2),
total_refunds INT,
avg_abandoned_cart DECIMAL(10, 2)
sum_refund_amounts,
avg_time_to_purchase DECIMAL(10, 2),
total_fraudulent_transactions INT,
avg_discount DECIMAL(10, 2),
avg_other_items_in_cart DECIMAL(10, 2),
);
"""2) Tạo một số câu hỏi giả định (sử dụng ChatGPT) để đánh giá
- Địa chỉ IP có tác động như thế nào đến loại sản phẩm được xem và mua?
- Xu hướng chung về doanh số bán giày trong quý này là gì?
- Có hành vi bất thường nào xảy ra trong vài giây mỗi giờ không?
- Sự tương tác của người dùng thay đổi như thế nào vào các sự kiện lớn như năm mới?
qas = [
("events.purchase_flow", "What is the impact of IP address on the types of products viewed and purchased?"),
("aggregates.purchases", "What is the overall trend in shoe sales this quarter?"),
("events.purchase_flow", "Is there unusual behavior within a few seconds of each hour?"),
("aggregates.purchases", "How does user engagement change around major events like New Years?"),
]3) Tạo siêu dữ liệu bổ sung (sử dụng ChatGPT) bao gồm
Mô tả ngắn gọn về từng bảng
desc1 = """Raw event captures of user events in the product flow. This table
is most effective for debugging and in-the-weeds investigations, and is generally
recommended for data scientists and engineers.
"""
desc2 = """Canonicalized table cleaned up for general business analytics. This is
recommended for most business users who are answering standard questions about the business.
"""Các câu hỏi mẫu mà mỗi bảng có đủ điều kiện để trả lời
sq1 = """
- What are the common channels onboarding users to our product in the last 3 weeks?
- What is the distribution of session times? Are there outliers?
- Which users purchased Reebok Crosstrainer Nano 2.0 shoes?
- How often do users make purchases from different devices?
- Find all sessions that led to a purchase in less than 30 seconds.
"""
sq2 = """
- What is the trend of winter gear sales by user demographic?
- What are the top product categories by revenue?
- Which user demographics most frequently abondon their cart? And how has this
changed over time?
- What have total purchases looked like quarter over quarter? What about revenue?
"""4) Kiểm tra xem điểm số tương đồng cosin nhiễu trông như thế nào bằng cách so sánh văn bản đầu vào của chúng tôi với “rác”
garbageInputs = [
"E = mc^2",
"Huh?",
"Silly text",
"The quick brown fox jumped over the lazy dog",
]
print("For our list of questions, what do cosine similarities look when compared to garbage?")
for input in garbageInputs:
print(f"Input: {input}")
embInp = getEmbedding(input)
for i, (_, q) in enumerate(qas):
embQ = getEmbedding(q)
cs = round(cosineSim(embQ, embInp), 3)
print(f"Q{i+1}: {cs}")
for i, table in enumerate([base_table_text_1, base_table_text_2]):
embT = getEmbedding(table)
cs = round(cosineSim(embT, embInp), 3)
print(f"T{i+1}: {cs}")
print()5) So sánh bốn chiến lược truy xuất khác nhau để xếp hạng, nhằm xem loại văn bản nào “tương tự nhất về mặt ngữ nghĩa” với thông tin đầu vào của chúng tôi.
- Chiến lược 1: Chỉ dựa trên sơ đồ bảng
- Chiến lược 2: Sơ đồ bảng + mô tả ngắn gọn
- Chiến lược 3: Sơ đồ bảng + mô tả ngắn gọn + câu hỏi mẫu
- Chiến lược 4: Chỉ các câu hỏi mẫu
Phát hiện sự tương đồng nhiễu Cosine
Để xây dựng trực giác về nhiễu có thể trông như thế nào, chúng tôi đã so sánh độ tương đồng cosin của các đoạn văn bản ngẫu nhiên với từng câu hỏi và văn bản bảng thô (hình minh họa bên dưới). Chúng tôi thấy rằng độ tương đồng cosin đối với các đầu vào rác là khoảng 0,04-0,23. Dưới đây là một ví dụ so sánh:

So sánh bốn chiến lược
Như chúng ta có thể thấy từ kết quả bên dưới (xem mã nguồn để kiểm tra chi tiết), Chiến lược 4, chỉ so sánh các câu hỏi với các câu hỏi mẫu, có sự chồng chéo ngữ nghĩa cao nhất và thứ hạng tốt nhất. Chiến lược 1 và 2 hoạt động tương tự nhau và nhất quán với nhiễu – nghĩa là có sự chồng chéo ngữ nghĩa yếu, nếu có, giữa các câu hỏi kinh doanh và các câu lệnh bảng SQL.
Điều này có vẻ hiển nhiên, nhưng một lần nữa, tôi thường thấy RAG được phát triển với những so sánh táo với cam tương tự. Nhưng điều có thể không hiển nhiên là Chiến lược 3, kết hợp mọi thứ lại với nhau, hoạt động kém hơn Chiến lược 4, cô lập các câu hỏi mà không có thêm chi tiết. Đôi khi, sử dụng dao mổ còn tốt hơn là búa tạ.
Nhiễu (Văn bản ngẫu nhiên, không liên quan): Điểm tương đồng cosin nằm trong khoảng 0,04 – 0,23.
Chiến lược 1 (Chỉ sơ đồ bảng): Các giá trị nằm trong khoảng 0,17 – 0,25 (phù hợp với nhiễu).
Chiến lược 2 (Sơ đồ bảng + Mô tả): Các giá trị nằm trong khoảng 0,14 – 0,25 (vẫn phù hợp với nhiễu).
Chiến lược 3 (Sơ đồ bảng + Mô tả + Câu hỏi mẫu): Giá trị nằm trong khoảng 0,23 – 0,30. Cải thiện rõ ràng, chúng ta bắt đầu thấy tín hiệu từ nhiễu.
Chiến lược 4 (Chỉ câu hỏi mẫu): Giá trị nằm trong khoảng 0,30 – 0,52. Rõ ràng là chiến lược hiệu quả nhất và nằm hoàn toàn ngoài phạm vi nhiễu. Hơn nữa, nó dẫn đến sự tách biệt lớn nhất và do đó tín hiệu mạnh hơn giữa các điểm tương đồng cosin của bảng đúng và bảng sai.
Những điều cần biết
Để tóm tắt lại, trước tiên chúng tôi xây dựng một phạm vi cơ sở của các giá trị tương đồng cosin cho biết sự so sánh với rác ngẫu nhiên. Sau đó, chúng tôi so sánh bốn chiến lược truy xuất khác nhau. Sử dụng cơ sở chúng tôi đã phát triển, chúng tôi thấy rằng có hai chiến lược có vẻ phù hợp với nhiễu. Chiến lược tốt nhất không phải là khớp trực tiếp các câu hỏi kinh doanh với các bảng SQL thô mà là khớp chúng với các câu hỏi kinh doanh mẫu mà các bảng này có thể trả lời được.
Các chiến lược tiếp theo để cải thiện RAG
Chúng tôi chỉ mới đề cập đến bề nổi. Sau đây là một số cách tiếp cận đáng giá để cải thiện chức năng từng bước trong RAG của bạn.
Cấu trúc dữ liệu của bạn để so sánh ngang bằng
Trong minh họa ở trên, chúng ta đã thấy những gợi ý ban đầu rằng bạn có thể cải thiện RAG bằng cấu trúc bổ sung, đó là liên kết các câu hỏi với ngân hàng câu hỏi hiện có trước, sau đó sẽ hướng dẫn bạn đến câu trả lời đúng. Điều này trái ngược với việc liên kết trực tiếp câu hỏi với văn bản đúng trong một bước duy nhất.
Đối với hệ thống Hỏi & Đáp được xây dựng trên tài liệu hỗ trợ, bạn có thể thấy rằng so sánh câu hỏi → câu hỏi sẽ cải thiện đáng kể hiệu suất so với so sánh câu hỏi → tài liệu hỗ trợ. Về mặt thực tế, bạn có thể yêu cầu ChatGPT tạo các câu hỏi ví dụ cho mỗi tài liệu hỗ trợ và để một chuyên gia con người biên tập chúng. Về bản chất, bạn sẽ tự điền trước Stack Overflow của mình.
Bạn có muốn đưa phương pháp “Stack Overflow” này tiến thêm một bước nữa không?
- Đối với mỗi tài liệu, hãy yêu cầu ChatGPT tạo danh sách 100 câu hỏi mà nó có thể trả lời
- Những câu hỏi này sẽ không hoàn hảo, vì vậy đối với mỗi câu hỏi bạn tạo ra, hãy tính toán độ tương đồng cosin với từng tài liệu khác
- Lọc những câu hỏi sẽ xếp hạng tài liệu đúng số 1 so với mọi tài liệu khác
- Xác định các câu hỏi chất lượng cao nhất bằng cách sắp xếp những câu hỏi có sự khác biệt lớn nhất giữa độ tương đồng cosin của tài liệu đúng và tài liệu được xếp hạng thứ hai
- Gửi cho các chuyên gia nghiệp vụ để thẩm tra thêm
Xếp hạng ngữ nghĩa + liên quan
Đây có thể là một trong những yếu tố mang lại giá trị lớn nhất cho bạn, và hầu như mọi công cụ tìm kiếm lớn mà bạn sử dụng đều làm điều này. Chúng ta đã thấy độ tương đồng cosine rất tốt để ước lượng sơ bộ, nhưng cuối cùng thì nó không thể đạt được độ chính xác cao hơn trong việc xếp hạng.
May mắn thay, doanh nghiệp của bạn có thể có nhiều thông tin hơn để giúp AI đưa ra quyết định tốt hơn. Ví dụ, bạn có thể đã thu thập các số liệu như lượt xem trang và lượt thích, và thậm chí tốt hơn nữa, bạn có thể có các số liệu này theo từng cá nhân. Bạn có thể tạo điểm liên quan kết hợp nhiều tính năng của người dùng/nhiệm vụ để tinh chỉnh thứ hạng của mình và giúp RAG của bạn hoạt động tốt hơn nhiều. Cụ thể, bạn có thể biến thứ hạng của mình thành sự kết hợp tuyến tính,
xếp hạng = (độ tương đồng cosin) + (trọng số) x (điểm liên quan)
Sử dụng AI như một con dao mổ, không phải là một cái búa tạ
Trong nhiều thập kỷ, các hoạt động kỹ thuật phần mềm đã phát triển theo hướng ưu tiên các thiết kế có nhiều thành phần nhỏ với các đảm bảo chặt chẽ, được xác định rõ ràng. Cơn sốt xung quanh giao diện trò chuyện đã đảo ngược hoàn toàn mô hình này và trong 5 năm, có thể dễ dàng bị coi là đáng ngờ.
ChatGPT và nhiều hệ sinh thái mới nổi khác khuyến khích mô hình “Hãy cho tôi bất kỳ văn bản nào, tôi sẽ cho bạn bất kỳ văn bản nào”. Không có gì đảm bảo về hiệu quả, hoặc thậm chí là chi phí và độ trễ, nhưng thay vào đó, các AI này có lời hứa suông rằng “Tôi có thể đúng một phần, đôi khi”. Tuy nhiên, các doanh nghiệp có thể xây dựng các AI mạnh mẽ hơn bằng cách cung cấp các giao diện có phạm vi và ý kiến rộng hơn để xây dựng các AI mạnh mẽ.
Lấy phân tích làm ví dụ, ngày nay không ai thành công trong việc thực hiện lời hứa về việc lấy một câu hỏi dữ liệu tùy ý và cung cấp một truy vấn SQL chính xác. Đừng nản lòng, bạn vẫn có thể xây dựng công nghệ hữu ích đáng kể. Ví dụ, một AI có phạm vi rộng hơn có thể giúp người dùng tìm kiếm từ một vũ trụ cố định các bảng SQL và các truy vấn mẫu do các nhà khoa học dữ liệu của bạn tuyển chọn. Thậm chí còn tốt hơn, vì hầu hết các câu hỏi kinh doanh dựa trên dữ liệu đã được trả lời trong quá khứ, có thể AI của bạn chỉ cần là một bot tìm kiếm đối với các câu hỏi dữ liệu trong Slack.
Kết luận
Chúng ta đang chứng kiến một kỷ nguyên mới của AI đang được mở ra. Điểm mới của kỷ nguyên này không phải là sự ra đời của NLP và các mô hình ngôn ngữ – Google đã làm điều này trong nhiều thế kỷ. Thay vào đó, một thành phần chính là công nghệ có sẵn đã giảm bớt rào cản gia nhập cho các doanh nghiệp để tận dụng công nghệ ngôn ngữ tự nhiên cho các trường hợp sử dụng cụ thể của họ. Nhưng chúng ta không nên quên rằng công nghệ này hiện vẫn đang trong giai đoạn phát triển ban đầu và khi xây dựng RAG cho AI của bạn, bạn đang xây dựng một công cụ tìm kiếm phức tạp trên cơ sở kiến thức của mình. Điều đó có thể đạt được, nhưng biết những thách thức này và giải quyết những hạn chế này là một nửa trận chiến.
Liên hệ
Nếu bạn muốn thảo luận thêm về các chủ đề này và xem chúng tôi có thể giúp gì không, đừng ngại liên hệ để cùng nhau giải quyết bài toán của bạn nhé!