


Ngày 2 tháng 10 năm 2023
Tác giả: Aayush Mittal
Các Mô hình Ngôn ngữ lớn, mặc dù mạnh mẽ về khả năng ngôn ngữ, nhưng lại thiếu khả năng nắm bắt điều gì đang diễn ra “ngay lúc này”. Trong thế giới đầy sự nhanh chóng, “ngay lúc này” là tất cả.
Nghiên cứu đã chỉ ra rằng các mô hình ngôn ngữ được huấn luyện trước lớn (LLMs) cũng là các kho kiến thức thực tế.
Chúng đã được huấn luyện trên nhiều dữ liệu đến mức chúng đã tiếp thu rất nhiều sự thật và con số. Khi được điều chỉnh tinh chỉnh, chúng có thể đạt được kết quả đáng kinh ngạc trong nhiều nhiệm vụ xử lý ngôn ngữ tự nhiên khác nhau.
Nhưng đây là điều quan trọng: khả năng của họ để truy cập và xử lý kiến thức đã lưu trữ này đôi khi không hoàn hảo. Đặc biệt là khi nhiệm vụ cần nhiều kiến thức, các mô hình này có thể tụt lại so với các kiến trúc chuyên biệt hơn. Đó giống như có một thư viện với tất cả các sách trên thế giới, nhưng không có sổ tay để tìm kiếm những gì bạn cần.
Cải tiến mới về khả năng duyệt web của ChatGPT từ OpenAI là một bước tiến quan trọng trong hướng Retrieval-Augmented Generation (RAG). Với khả năng mới này, ChatGPT giờ có thể tìm kiếm trên internet để lấy thông tin hiện tại và uy tín, tương tự như phương pháp RAG, nó có khả năng động lấy dữ liệu từ các nguồn bên ngoài để cung cấp câu trả lời phong phú hơn.
Hiện tại, tính năng này chỉ có sẵn cho người dùng Plus và Enterprise của OpenAI, nhưng OpenAI đang kế hoạch triển khai tính năng này cho tất cả người dùng trong tương lai gần. Người dùng có thể kích hoạt tính năng này bằng cách chọn ‘Duyệt web với Bing’ trong tùy chọn GPT-4.
Kỹ thuật tạo prompt (câu hỏi khởi đầu) là hiệu quả nhưng không đủ
Các prompt (câu hỏi khởi đầu) đóng vai trò như cửa ngõ đến kiến thức của LLM (Mô hình Ngôn ngữ Lớn). Chúng hướng dẫn mô hình, cung cấp hướng cho câu trả lời. Tuy nhiên, việc tạo ra một prompt hiệu quả không phải lúc nào cũng là giải pháp hoàn chỉnh để đạt được những gì bạn muốn từ một LLM. Tuy nhiên, hãy cùng xem qua một số thực hành tốt cần xem xét khi viết prompt:
- Sự Rõ Ràng: Một prompt được định nghĩa rõ ràng loại bỏ sự mơ hồ. Nó nên rõ ràng, đảm bảo rằng mô hình hiểu rõ ý định của người dùng. Sự rõ ràng thường dẫn đến các câu trả lời mạch lạc và có liên quan hơn.
- Ngữ cảnh: Đặc biệt đối với các đầu vào phức tạp, vị trí của hướng dẫn có thể ảnh hưởng đến kết quả đầu ra. Ví dụ, việc di chuyển hướng dẫn đến cuối của một prompt dài thường có thể mang lại kết quả tốt hơn.
- Sự Chính Xác trong Hướng Dẫn: Sức mạnh của câu hỏi thường được truyền đạt thông qua cấu trúc “ai, cái gì, ở đâu, khi nào, tại sao, làm thế nào”, có thể hướng dẫn mô hình đến một câu trả lời tập trung hơn. Ngoài ra, việc chỉ định định dạng hoặc kích thước đầu ra mong muốn cũng có thể làm cho đầu ra của mô hình tinh xảo hơn.
- Xử Lý Sự Không Chắc Chắn: Quan trọng là hướng dẫn mô hình cách phản ứng khi nó không chắc chắn. Ví dụ, hướng dẫn mô hình trả lời bằng “Tôi không biết” khi không chắc chắn có thể ngăn nó tạo ra các câu trả lời không chính xác hoặc “thiết thực”.
- Tư Duy Theo Bước: Đối với các hướng dẫn phức tạp, hướng dẫn mô hình suy nghĩ theo cách có hệ thống hoặc chia công việc thành các công việc con có thể dẫn đến đầu ra toàn diện và chính xác hơn.
Liên quan đến tầm quan trọng của các prompt trong việc hướng dẫn ChatGPT, một bài viết tổng hợp có thể được tìm thấy trong một bài viết trên mygpt.vn.
Thách thức trong Mô hình Trí tuệ Nhân tạo (Generative AI)
Kỹ thuật tạo prompt (prompt engineering) bao gồm việc điều chỉnh các hướng dẫn được đưa cho mô hình của bạn để cải thiện hiệu suất của nó. Đây là một cách rất hiệu quả về chi phí để nâng cao độ chính xác của ứng dụng Trí tuệ Nhân tạo Tạo ra của bạn, chỉ đòi hỏi điều chỉnh mã nhỏ. Mặc dù kỹ thuật tạo prompt có thể cải thiện đáng kể đầu ra, nhưng quan trọng là hiểu rõ các hạn chế bẩm sinh của các mô hình ngôn ngữ lớn (LLM). Hai thách thức chính là hiện tượng ảo tưởng (hallucinations) và giới hạn kiến thức (knowledge cut-offs).
- Hiện tượng ảo tưởng (Hallucinations): Đây là những trường hợp mô hình tự tin trả về một câu trả lời sai hoặc bịa đặt. Mặc dù các LLM tiên tiến có cơ chế tích hợp để nhận biết và tránh những đầu ra như vậy.

- Giới hạn Kiến thức (Knowledge Cut-offs): Mỗi mô hình LLM đều có một ngày kết thúc huấn luyện, sau đó nó không có ý thức về các sự kiện hoặc phát triển mới. Hạn chế này có nghĩa là kiến thức của mô hình bị đóng băng tại điểm cuối cùng của ngày huấn luyện trước đó. Ví dụ, một mô hình được huấn luyện đến năm 2022 sẽ không biết về các sự kiện diễn ra vào năm 2023.

Tích hợp tìm kiếm trong quá trình tạo (Retrieval-augmented generation – RAG) cung cấp một giải pháp cho những thách thức này. Nó cho phép các mô hình truy cập thông tin bên ngoài, giảm thiểu vấn đề của hiện tượng ảo tưởng bằng cách cung cấp quyền truy cập vào dữ liệu độc quyền hoặc thuộc lĩnh vực cụ thể. Đối với vấn đề giới hạn kiến thức, RAG có thể truy cập thông tin hiện tại vượt ra ngoài ngày huấn luyện của mô hình, đảm bảo đầu ra luôn cập nhật.
Nó cũng cho phép LLM lấy dữ liệu từ nhiều nguồn bên ngoài trong thời gian thực. Điều này có thể là cơ sở kiến thức, cơ sở dữ liệu hoặc thậm chí là internet vô cùng rộng lớn.
Giới thiệu về Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation (RAG) là một khung (framework), chứ không phải một công nghệ cụ thể, cho phép các Mô hình Ngôn ngữ Lớn (LLM) tiếp cận dữ liệu mà chúng không được huấn luyện trên đó. Có nhiều cách để triển khai RAG, và lựa chọn tốt nhất phụ thuộc vào nhiệm vụ cụ thể của bạn và tính chất của dữ liệu bạn đang làm việc.
Khung RAG hoạt động theo cách có cấu trúc:
Nhập Prompt đầu vào
Quá trình bắt đầu với đầu vào hoặc câu hỏi từ người dùng. Điều này có thể là một câu hỏi hoặc một tuyên bố yêu cầu thông tin cụ thể.
Truy xuất từ Nguồn Bên Ngoài
Thay vì tạo ra trực tiếp một câu trả lời dựa trên việc huấn luyện, mô hình, với sự giúp đỡ của một thành phần truy xuất (retriever), tìm kiếm thông qua các nguồn dữ liệu bên ngoài. Các nguồn này có thể bao gồm cơ sở kiến thức, cơ sở dữ liệu và kho lưu trữ tài liệu, thậm chí là dữ liệu truy cập trên internet.
Hiểu về Quá trình Truy xuất
Ở bản chất của nó, quá trình truy xuất tương tự như một thao tác tìm kiếm. Nó liên quan đến việc trích xuất thông tin quan trọng nhất phản hồi vào đầu vào của người dùng. Quá trình này có thể được chia thành hai giai đoạn:
- Cơ sở dữ liệu chỉ mục (Indexing): Có thể nói, phần khó khăn nhất trong toàn bộ hành trình của RAG là chỉ mục cơ sở kiến thức của bạn. Quá trình chỉ mục có thể được chia thành hai giai đoạn chính: Tải lên và Chia nhỏ. Trong các công cụ như LangChain, những quá trình này được gọi là “loaders” (công cụ tải lên) và “splitters” (công cụ chia nhỏ). Các công cụ tải lên lấy nội dung từ các nguồn khác nhau, có thể là trang web hoặc tệp PDF. Sau khi đã tải lên, các công cụ chia nhỏ sau đó chia thành các phần nhỏ hơn, tối ưu hóa chúng để nhúng và tìm kiếm.
- Truy vấn (Querying): Đây là việc trích xuất các đoạn kiến thức phù hợp nhất dựa trên một thuật ngữ tìm kiếm.
Mặc dù có nhiều cách tiếp cận truy xuất, từ đơn giản như so khớp văn bản đến việc sử dụng công cụ tìm kiếm như Google, các hệ thống Retrieval-Augmented Generation (RAG) hiện đại dựa vào tìm kiếm ngữ nghĩa. Tại trái tim của tìm kiếm ngữ nghĩa là khái niệm về nhúng (embeddings).
Nhúng là trung tâm của cách Mô hình Ngôn ngữ Lớn (LLM) hiểu ngôn ngữ. Khi con người cố gắng diễn đạt cách họ trích xuất ý nghĩa từ từng từ, giải thích thường quay trở lại hiểu biết bẩm sinh. Sâu bên trong cấu trúc kognitif của chúng ta, chúng ta nhận biết rằng “child” và “kid” đồng nghĩa, hoặc rằng “red” và “green” đều chỉ màu sắc.
Tăng cường cho Prompt (Augmenting the Prompt)
Thông tin được truy xuất sau đó được kết hợp với prompt gốc, tạo thành một prompt bổ sung hoặc mở rộng. Prompt bổ sung này cung cấp cho mô hình thêm ngữ cảnh, điều này đặc biệt quý báu nếu dữ liệu thu được thuộc lĩnh vực cụ thể hoặc không thuộc phạm vi huấn luyện ban đầu của mô hình.
Hoàn thành hội thoại (Generating the Completion)
Với prompt được bổ sung trong tay, mô hình sau đó tạo ra một bản hoàn thiện hoặc câu trả lời. Câu trả lời này không chỉ dựa trên quá trình huấn luyện của mô hình mà còn được thông báo bởi dữ liệu thời gian thực được truy xuất.

Kiến trúc của Mô hình LLM RAG Đầu Tiên
Bài báo nghiên cứu của Meta được công bố vào năm 2020, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” cung cấp cái nhìn sâu hơn về kỹ thuật này. Mô hình Retrieval-Augmented Generation bổ sung quá trình tạo truyền thống bằng cơ chế truy xuất hoặc tìm kiếm bên ngoài. Điều này cho phép mô hình trích dẫn thông tin liên quan từ các tập dữ liệu lớn, cải thiện khả năng tạo ra các câu trả lời có ngữ cảnh chính xác.
Dưới đây là cách nó hoạt động:
- Bộ Nhớ Tham số (Parametric Memory): Đây là mô hình ngôn ngữ truyền thống của bạn, giống như một mô hình seq2seq. Nó đã được huấn luyện trên lượng lớn dữ liệu và biết nhiều thông tin.
- Bộ Nhớ Phi tham số (Non-Parametric Memory): Hãy nghĩ về nó như một công cụ tìm kiếm. Đó là một chỉ số vector dày đặc của ví dụ Wikipedia, có thể được truy cập bằng cách sử dụng một công cụ truy xuất thần kinh.
Khi kết hợp, hai phần này tạo thành một mô hình chính xác. Mô hình RAG trước tiên truy xuất thông tin liên quan từ bộ nhớ phi tham số của nó và sau đó sử dụng kiến thức tham số của mình để đưa ra một câu trả lời mạch lạc.
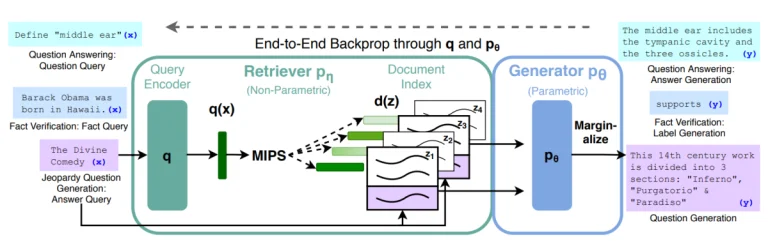
Quy trình Hai Bước:
Mô hình RAG LLM hoạt động theo một quy trình hai bước:
- Truy xuất (Retrieval): Mô hình trước tiên tìm kiếm các tài liệu hoặc đoạn văn phù hợp từ một bộ dữ liệu lớn. Điều này được thực hiện bằng cách sử dụng một cơ chế truy xuất dày đặc, sử dụng embeddings để biểu diễn cả truy vấn và các tài liệu. Các embeddings sau đó được sử dụng để tính điểm tương đồng, và các tài liệu được xếp hạng cao nhất được truy xuất.
- Tạo ra (Generation): Với các tài liệu phù hợp nhất hàng đầu trong tay, chúng sau đó được đưa vào một trình tạo chuỗi thành chuỗi bên cạnh truy vấn ban đầu. Trình tạo này sau đó tạo ra đầu ra cuối cùng, lấy ngữ cảnh từ cả truy vấn và các tài liệu đã thu thập.
Truy xuất Dày đặc (Dense Retrieval):
Các hệ thống truy xuất truyền thống thường dựa vào biểu diễn thưa như TF-IDF. Tuy nhiên, RAG LLM sử dụng biểu diễn dày đặc, trong đó cả truy vấn và tài liệu được nhúng vào không gian vector liên tục. Điều này cho phép so sánh tương đồng tinh tế hơn, bắt kết quả về mối quan hệ ngữ nghĩa vượt ra khỏi việc chỉ so sánh từ khóa đơn giản.
Tạo Chuỗi thành Chuỗi (Sequence-to-Sequence Generation):
Các tài liệu đã thu thập hoạt động như một ngữ cảnh mở rộng cho mô hình tạo ra. Mô hình này, thường dựa trên các kiến trúc như Transformers, sau đó tạo ra đầu ra cuối cùng, đảm bảo rằng nó có tính mạch lạc và phù hợp về ngữ cảnh.
Tìm Kiếm Tài Liệu
Chỉ Mục và Truy Xuất Tài Liệu
Để truy xuất thông tin hiệu quả, đặc biệt từ các tài liệu lớn, dữ liệu thường được lưu trữ trong một cơ sở dữ liệu vector. Mỗi mảnh dữ liệu hoặc tài liệu được chỉ mục dựa trên một vector nhúng, chứa thông tin bản chất ngữ nghĩa của nội dung. Chỉ mục hiệu quả đảm bảo việc truy xuất nhanh chóng thông tin liên quan dựa trên câu hỏi đầu vào.
Cơ Sở Dữ Liệu Vector
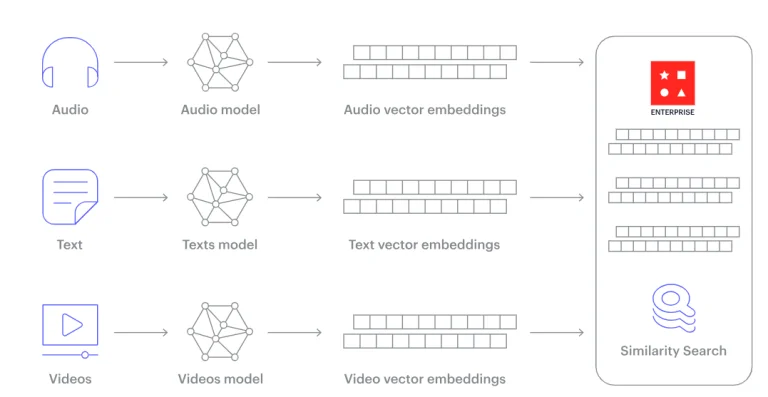
Cơ sở dữ liệu vector, đôi khi được gọi là lưu trữ vector, là các cơ sở dữ liệu được tùy chỉnh để lưu trữ và truy xuất dữ liệu vector. Trong lĩnh vực Trí tuệ Nhân tạo và khoa học máy tính, các vector đơn giản là danh sách số biểu thị các điểm trong một không gian đa chiều. Khác với các cơ sở dữ liệu truyền thống, chú trọng vào dữ liệu bảng, cơ sở dữ liệu vector được thiết kế để quản lý dữ liệu tự nhiên phù hợp với định dạng vector, chẳng hạn như các vector nhúng từ các mô hình Trí tuệ Nhân tạo.
Một số cơ sở dữ liệu vector đáng chú ý bao gồm Annoy, Faiss của Meta, Milvus và Pinecone. Các cơ sở dữ liệu này đóng vai trò quan trọng trong các ứng dụng Trí tuệ Nhân tạo, hỗ trợ trong các nhiệm vụ từ hệ thống đề xuất đến tìm kiếm hình ảnh. Các nền tảng như AWS cũng cung cấp các dịch vụ được tùy chỉnh cho nhu cầu cơ sở dữ liệu vector, chẳng hạn như Amazon OpenSearch Service và Amazon RDS for PostgreSQL. Các dịch vụ này được tối ưu hóa cho các trường hợp sử dụng cụ thể, đảm bảo chỉ mục và truy vấn hiệu quả.
Chia nhỏ tài liệu thành các phần liên quan với nhau (Chunking for Relevance)
Bởi vì nhiều tài liệu có thể rất lớn, một kỹ thuật được biết đến là “chia thành các phần” thường được sử dụng. Điều này bao gồm việc chia các tài liệu lớn thành các phần nhỏ hợp nhất về mặt ngữ nghĩa. Sau đó, các phần này được chỉ mục và truy xuất khi cần, đảm bảo rằng các phần quan trọng nhất của một tài liệu được sử dụng để bổ sung cho câu hỏi.
Xem xét Cửa Sổ Ngữ Cảnh (Context Window)
Mỗi LLM hoạt động trong một cửa sổ ngữ cảnh, đó chính là lượng thông tin tối đa mà nó có thể xem xét cùng một lúc. Nếu nguồn dữ liệu bên ngoài cung cấp thông tin vượt quá cửa sổ này, thông tin đó cần được chia thành các phần nhỏ hơn sao cho vẫn vừa với cửa sổ ngữ cảnh của mô hình.
Lợi ích của việc Sử dụng Retrieval-Augmented Generation (RAG)
- Tăng độ chính xác: Bằng cách tận dụng các nguồn dữ liệu bên ngoài, RAG LLM có thể tạo ra các câu trả lời không chỉ dựa trên dữ liệu huấn luyện mà còn được cung cấp bởi thông tin phù hợp và cập nhật nhất có sẵn trong ngữ cảnh truy xuất.
- Vượt qua khoảng trống Kiến thức: RAG hiệu quả đối phó với các hạn chế kiến thức bẩm sinh của LLM, cho dù do ngày kết thúc huấn luyện của mô hình hay sự vắng mặt của dữ liệu cụ thể cho lĩnh vực đó trong tập dữ liệu huấn luyện của nó.
- Tính linh hoạt: RAG có thể được tích hợp với các nguồn dữ liệu bên ngoài khác nhau, từ cơ sở dữ liệu độc quyền trong tổ chức đến dữ liệu truy cập công khai trên internet. Điều này làm cho nó phù hợp với một loạt ứng dụng và ngành công nghiệp.
- Giảm Hiện tượng ảo tưởng: Một trong những thách thức của LLM là khả năng xuất hiện “hiện tượng ảo tưởng” hoặc việc tạo ra thông tin không đúng hoặc bịa đặt. Bằng cách cung cấp ngữ cảnh dữ liệu thời gian thực, RAG có thể giảm đáng kể khả năng xuất hiện các đầu ra như vậy.
- Khả năng Mở Rộng: Một trong những lợi ích chính của RAG LLM là khả năng mở rộng. Bằng cách tách riêng quá trình truy xuất và tạo ra, mô hình có thể xử lý hiệu quả các tập dữ liệu lớn, phù hợp cho các ứng dụng thực tế nơi dữ liệu phong phú.
Thách thức và Yếu tố cân nhắc
- Chi phí tính toán cao: Quy trình hai bước có thể đòi hỏi nhiều tính toán, đặc biệt là khi xử lý các tập dữ liệu lớn.
- Phụ thuộc vào dữ liệu: Chất lượng của các tài liệu được truy xuất trực tiếp ảnh hưởng đến chất lượng của quá trình sinh ra đáp ứng. Do đó, công việc kiểm soát chất lượng bộ dữ liệu truy xuất có vai trò đặc biệt quan trọng..
Kết Luận
Bằng cách tích hợp các quy trình truy xuất và hình thành đáp ứng, Retrieval-Augmented Generation cung cấp một giải pháp mạnh mẽ cho các nhiệm vụ đòi hỏi nhiều kiến thức, đảm bảo đầu ra có thông tin và phù hợp về ngữ cảnh sử dụng.
Lợi ích thực sự của RAG nằm trong tiềm năng ứng dụng thực tế của nó. Đối với các lĩnh vực như chăm sóc sức khỏe, nơi thông tin kịp thời và chính xác có thể quyết định, RAG cung cấp khả năng trích xuất và tạo ra cái nhìn từ văn bản y khoa rộng lớn một cách liền mạch. Trong lĩnh vực tài chính, nơi thị trường thay đổi theo từng phút, RAG có thể cung cấp thông tin thời gian thực dựa trên dữ liệu, giúp trong quá trình ra quyết định có thông tin cơ sở. Hơn nữa, trong lĩnh vực học thuật và nghiên cứu, các học giả có thể tận dụng RAG để quét qua các kho dữ liệu rộng lớn, làm cho việc xem xét văn bản và phân tích dữ liệu hiệu quả hơn.