


Sự phát triển của Trí tuệ nhân tạo (AI) đang ngày càng mạnh mẽ và rất nhiều cá nhân cũng như doanh nghiệp đã kiếm tìm được nhiều lợi ích từ sự phát triển này trong nhiều ứng dụng thực tế khác nhau tuy nhiên vẫn còn nhiều ý kiến cũng như lo ngại liên quan đến công nghệ AI:
- Trí tuệ nhân tạo sẽ là mối đe dọa cho nhân loại? Để làm được điều đó, AI trước tiên cần phải vượt qua trí thông minh của con người. Các chuyên gia không mong đợi điều đó sẽ xảy ra trong 30-40 năm tới.
- AI sẽ là mối đe dọa cho công việc của chúng ta? Có, 44% lao động có trình độ học vấn thấp sẽ có nguy cơ thất nghiệp về công nghệ vào năm 2030.
- Liệu chúng ta có thể tin tưởng vào phán đoán của hệ thống AI không? Chưa được, công nghệ AI có thể kế thừa những thành kiến của con người do những thành kiến này có trong dữ liệu sử dụng để đào tạo AI.
Trong bài viết này, chúng tôi tập trung vào vấn đề thành kiến AI và sẽ trả lời các câu hỏi liên quan đến thành kiến tồn tại trong thuật toán trí tuệ nhân tạo, cũng như các ví dụ về thành kiến AI cho đến các phương pháp loại bỏ những thành kiến đó khỏi thuật toán AI.
Thành kiến AI là gì?
Thành kiến AI là xu hướng tạo ra trả lời bất thường trong đầu ra của các thuật toán học máy, do các giả định thành kiến đã được đưa vào trong quá trình phát triển thuật toán hoặc tồn tại thành kiến trong dữ liệu huấn luyện.
Các loại thành kiến AI?
Có 2 lý do dẫn đến một hệ thống AI sẽ chứa đựng những thành kiến :
- Thành kiến nhận thức: Đây là những lỗi vô thức trong suy nghĩ ảnh hưởng đến phán đoán và quyết định của cá nhân. Những thành kiến này xuất phát từ nỗ lực của bộ não nhằm đơn giản hóa việc xử lý thông tin về thế giới. Hơn 180 thành kiến của con người đã được các nhà tâm lý học đã xác định và phân loại. Những thành kiến về nhận thức có thể xâm nhập vào các thuật toán học máy thông qua một trong hai hành động:
- nhà thiết kế vô tình giới thiệu họ với mô hình
- tập dữ liệu huấn luyện đã bao gồm những thành kiến đó
- Thiếu dữ liệu đầy đủ: Nếu dữ liệu không đầy đủ, nó có thể không mang tính đại diện và do đó có thể bao gồm sai lệch. Ví dụ, hầu hết các nghiên cứu tâm lý học đều sử dụng các kết quả nghiên cứu từ sinh viên đại học, đó là một nhóm cụ thể và không đại diện cho toàn bộ dân số trong cộng đồng.
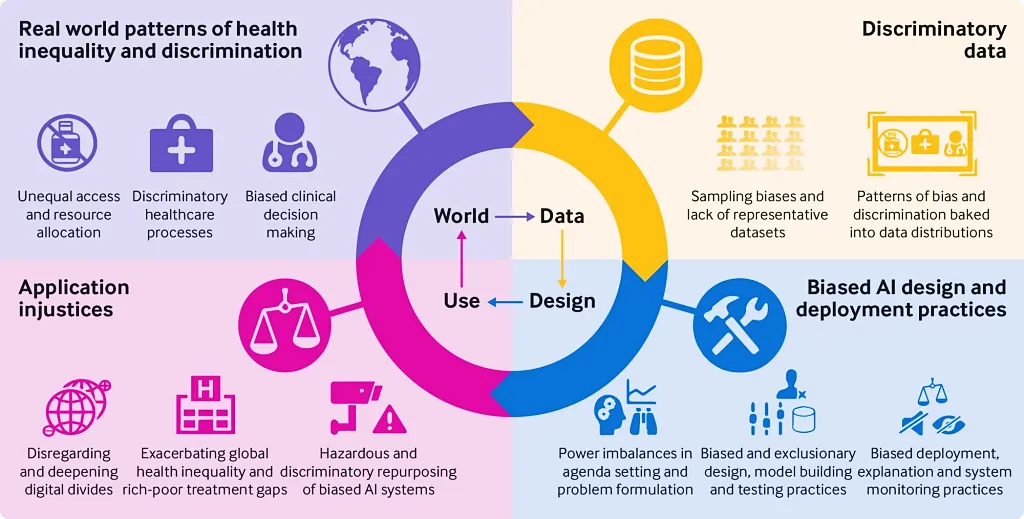
Nguồn: Tạp chí Y khoa Anh
Liệu AI có bao giờ hoàn toàn không thiên vị?
Về mặt kỹ thuật có thể trả lời “có”. Nếu một hệ thống AI được tiếp nhận nguồn dữ liệu đầu vào với chất lượng cao thì có thể loại bỏ được điều này. Nếu bạn có thể ngăn chặn tập dữ liệu đào tạo của mình khỏi các giả định có ý thức hay vô thức về chủng tộc, giới tính hoặc các khái niệm hệ tư tưởng khác, thì bạn có thể xây dựng một hệ thống AI đưa ra các quyết định khách quan dựa trên dữ liệu.
Tuy nhiên, trong thế giới thực, chúng tôi không mong đợi AI sẽ sớm hoàn toàn không thiên vị do lập luận tương tự mà chúng tôi đã đưa ra ở trên. AI có thể hoạt động tốt nhưng thực tế thì dữ liệu là do người tạo ra và hiện có rất nhiều thành kiến của con người được tìm ra và chúng cũng vẫn liên tục được cập nhật một cách không ngừng. Vì vậy, khó có thể có được trí óc con người hoàn toàn không thiên vị và hệ thống AI cũng vậy. Suy cho cùng, con người đang tạo ra dữ liệu sai lệch trong khi con người và các thuật toán do con người tạo ra đang cố gắng kiểm tra dữ liệu để xác định và loại bỏ những sai lệch đó.
Những gì chúng ta có thể làm đối với sự thiên vị hay thành kiến AI là giảm thiểu nó bằng cách thử nghiệm dữ liệu và thuật toán, đồng thời phát triển hệ thống AI với các nguyên tắc AI hoạt động có trách nhiệm.
Làm cách nào để khắc phục các sai lệch trong thuật toán AI và máy học?
Đầu tiên, nếu tập dữ liệu của bạn đã hoàn chỉnh, bạn nên thừa nhận rằng những thành kiến về AI chỉ có thể xảy ra do định kiến của con người và bạn nên tập trung vào việc loại bỏ những định kiến đó khỏi tập dữ liệu. Tuy nhiên, nó không dễ dàng như người ta tưởng.
Một cách tiếp cận đơn giản là loại bỏ các lớp được bảo vệ (chẳng hạn như giới tính hoặc chủng tộc) khỏi dữ liệu và xóa các nhãn làm cho thuật toán bị sai lệch. Tuy nhiên, cách tiếp cận này có thể không hiệu quả vì các nhãn bị loại bỏ có thể ảnh hưởng đến sự hiểu biết về mô hình và độ chính xác của kết quả của bạn có thể trở nên kém hơn.
Vì vậy, không có cách khắc phục nhanh chóng nào để loại bỏ tất cả các thành kiến nhưng có những khuyến nghị từ các chuyên gia tư vấn như McKinsey mà chúng ta có thể tham khảo dưới đây về phương pháp hay để giảm thiểu thành kiến AI:
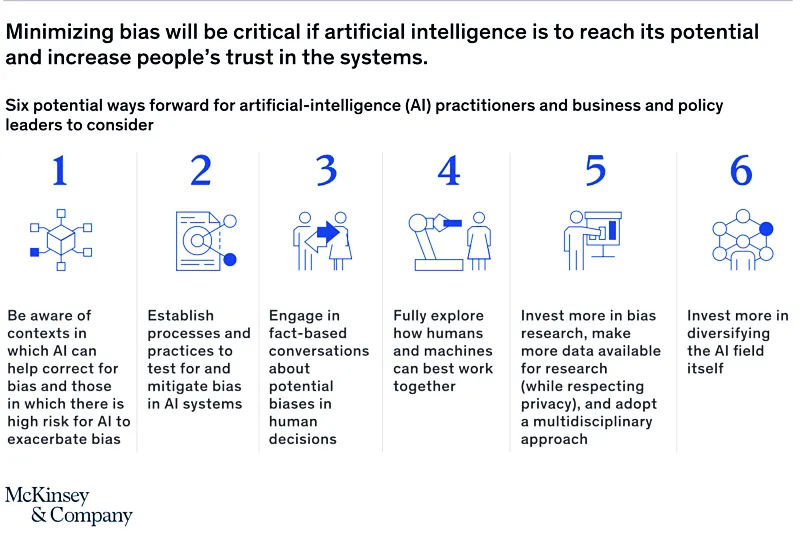
Các bước khắc phục sai lệch trong hệ thống AI:
- Tìm hiểu thuật toán và dữ liệu để đánh giá nơi nào có nguy cơ xảy ra sự không công bằng cao. Ví dụ:
- Kiểm tra tập dữ liệu huấn luyện xem nó có mang tính đại diện và đủ lớn để ngăn chặn các sai lệch phổ biến như sai lệch lấy mẫu hay không.
- Tiến hành phân tích trong nhóm nhỏ bao gồm việc tính toán số liệu mô hình cho các nhóm cụ thể được đề cập đến trong tập dữ liệu. Điều này có thể giúp xác định xem hiệu suất của mô hình có giống nhau giữa các nhóm hay không.
- Theo dõi mô hình theo thời gian để chống lại các thành kiến. Kết quả của thuật toán học máy có thể thay đổi khi chúng học hoặc khi dữ liệu đào tạo thay đổi.
- Sử dụng chiến thuật chống sai lệch ở nhiều mức độ khác nhau từ kỹ thuật, hoạt động và toàn tổ chức:
- Chiến lược kỹ thuật sử dụng các công cụ có thể giúp bạn xác định các nguồn sai lệch tiềm ẩn và tiết lộ các đặc điểm trong dữ liệu ảnh hưởng đến độ chính xác của mô hình
- Các chiến lược hoạt động bao gồm cải thiện quy trình thu thập dữ liệu bằng cách sử dụng “đội đỏ” nội bộ và kiểm toán viên của bên thứ ba. Bạn có thể tìm thêm các phương pháp thực tiễn khác từ nghiên cứu của Google AI về tính công bằng
- Chiến lược tổ chức bao gồm việc thiết lập một nơi làm việc nơi các số liệu và quy trình được trình bày minh bạch
- Cải thiện các quy trình do con người điều khiển khi bạn xác định được các thành kiến trong dữ liệu đào tạo. Việc xây dựng và đánh giá mô hình có thể làm nổi bật những thành kiến đã được chú ý trong một thời gian dài. Trong quá trình xây dựng mô hình AI, các công ty có thể xác định những thành kiến này và sử dụng kiến thức này để hiểu lý do dẫn đến sai lệch. Thông qua đào tạo, thiết kế quy trình và thay đổi văn hóa, các công ty có thể cải thiện quy trình thực tế để giảm bớt sự thiên vị.
- Quyết định các trường hợp sử dụng trong đó ưu tiên đưa ra quyết định tự động và khi nào thì con người nên tham gia.
- Thực hiện theo một cách tiếp cận đa ngành. Nghiên cứu và phát triển là chìa khóa để giảm thiểu sai lệch trong tập hợp dữ liệu và thuật toán. Loại bỏ thành kiến là một chiến lược đa ngành bao gồm các nhà đạo đức học, nhà khoa học xã hội và chuyên gia hiểu rõ nhất các sắc thái của từng lĩnh vực ứng dụng trong quy trình. Do đó, các công ty nên tìm cách đưa những chuyên gia như vậy vào các dự án AI của họ.
- Đa dạng hóa tổ chức của bạn. Sự đa dạng trong cộng đồng AI giúp giảm bớt việc xác định các thành kiến. Những người đầu tiên nhận thấy vấn đề thiên vị hầu hết là người dùng đến từ cộng đồng thiểu số cụ thể đó. Do đó, việc duy trì một nhóm phát triển AI đa dạng có thể giúp bạn giảm thiểu những thành kiến không mong muốn về AI.
Cách tiếp cận tập trung vào dữ liệu để phát triển AI cũng có thể giúp giảm thiểu sai lệch trong hệ thống AI.
Công cụ để giảm sự thiên vị
AI Fairness 360
IBM đã phát hành một thư viện nguồn mở để phát hiện và giảm thiểu những thành kiến trong các thuật toán học tập không giám sát hiện có 34 người đóng góp (tính đến tháng 9 năm 2020) trên Github. Thư viện có tên AI Fairness 360 và nó cho phép các lập trình viên AI:
- kiểm tra thành kiến trong các mô hình và tập dữ liệu bằng một bộ số liệu toàn diện.
- giảm thiểu thành kiến với sự trợ giúp của 12 thuật toán đóng gói như Học cách trình bày công bằng, Phân loại tùy chọn từ chối, Loại bỏ tác động khác nhau.
Tuy nhiên, các thuật toán phát hiện và giảm thiểu sai lệch của AI Fairness 360 được thiết kế cho các vấn đề phân loại nhị phân, đó là lý do tại sao nó cần được mở rộng cho các vấn đề đa lớp và hồi quy nếu vấn đề của bạn phức tạp hơn.
IBM Watson OpenScale
Watson OpenScale của IBM thực hiện kiểm tra và giảm thiểu sai lệch trong thời gian thực khi AI đưa ra quyết định.
Công cụ What-If của Google
Bằng cách sử dụng Công cụ What-If, bạn có thể kiểm tra hiệu suất trong các tình huống giả định, phân tích tầm quan trọng của các tính năng dữ liệu khác nhau và trực quan hóa hành vi của mô hình trên nhiều mô hình và tập hợp con của dữ liệu đầu vào cũng như các số liệu công bằng ML khác nhau.
Một số ví dụ về thành kiến AI?
Loại bỏ trọng âm cho trung tâm chăm sóc khách hàng
Công ty khởi nghiệp Sanas ở Bay Area đã phát triển một hệ thống dịch giọng dựa trên AI để làm cho nhân viên trung tâm chăm sóc khách hàng từ khắp nơi trên thế giới trở nên quen thuộc hơn với khách hàng Mỹ. Công cụ này chuyển giọng của người nói thành giọng Mỹ “trung tính” theo thời gian thực. Theo báo cáo của SFGATE, chủ tịch Sanas, Marty Sarim, nói rằng giọng nói là một vấn đề vì “chúng gây ra sự thiên vị và gây hiểu lầm”.
Không thể loại bỏ những thành kiến về chủng tộc bằng cách khiến mọi người trở thành người da trắng và người Mỹ. Ngược lại, nó sẽ làm trầm trọng thêm những thành kiến này vì những nhân viên trung tâm chăm sóc khách hàng không phải người Mỹ không sử dụng công nghệ này sẽ phải đối mặt với sự phân biệt đối xử thậm chí còn tồi tệ hơn nếu giọng Mỹ da trắng trở thành tiêu chuẩn.
Công cụ tuyển dụng thiên vị của Amazon
Với ước mơ tự động hóa quy trình tuyển dụng, Amazon đã bắt đầu một dự án AI vào năm 2014. Dự án của họ chỉ dựa trên việc xem xét sơ yếu lý lịch của người xin việc và xếp hạng ứng viên bằng cách sử dụng thuật toán do AI cung cấp để nhà tuyển dụng không mất thời gian vào các công việc sàng lọc sơ yếu lý lịch thủ công. Tuy nhiên, đến năm 2015, Amazon nhận ra rằng hệ thống tuyển dụng AI mới của họ không đánh giá ứng viên một cách công bằng và nó thể hiện sự thiên vị đối với phụ nữ.
Amazon đã sử dụng dữ liệu lịch sử trong 10 năm qua để đào tạo mô hình AI của họ. Dữ liệu lịch sử cho thấy sự thiên vị đối với phụ nữ vì nam giới chiếm ưu thế trong ngành công nghệ và nam giới chiếm 60% nhân viên của Amazon. Do đó, hệ thống tuyển dụng của Amazon đã hiểu nhầm rằng ứng viên nam được ưu tiên hơn. Nó phạt những hồ sơ có chứa từ “của phụ nữ”, chẳng hạn như “đội trưởng câu lạc bộ cờ vua của phụ nữ”. Do đó, Amazon đã ngừng sử dụng thuật toán cho mục đích tuyển dụng.
Thành kiến chủng tộc trong thuật toán chăm sóc sức khỏe
Một thuật toán dự đoán nguy cơ bệnh tật trong chăm sóc sức khỏe được sử dụng trên hơn 200 triệu công dân Hoa Kỳ đã thể hiện sự thiên vị về chủng tộc vì thuật toán này dựa vào số liệu bị lỗi để xác định nhu cầu.
Thuật toán được thiết kế để dự đoán những bệnh nhân nào có thể sẽ cần được chăm sóc y tế bổ sung, tuy nhiên, sau đó người ta tiết lộ rằng thuật toán đã tạo ra các kết quả lỗi có lợi cho bệnh nhân da trắng hơn bệnh nhân da đen.
Các nhà thiết kế thuật toán đã sử dụng chỉ các tiêu chăm sóc sức khỏe của bệnh nhân trước đây làm đại diện cho nhu cầu y tế. Đây là cách giải thích tồi đối với dữ liệu lịch sử vì thu nhập và chủng tộc là những số liệu có mối tương quan cao và việc đưa ra các giả định chỉ dựa trên một biến số của số liệu tương quan đã khiến thuật toán đưa ra kết quả không chính xác.
Xu hướng trong quảng cáo Facebook
Có rất nhiều ví dụ về sự thiên vị của con người và chúng tôi thấy điều đó xảy ra trên các nền tảng công nghệ. Vì dữ liệu trên nền tảng công nghệ sau này được sử dụng để đào tạo các mô hình học máy nên những thành kiến này sẽ dẫn đến các mô hình học máy có sai lệch.
Vào năm 2019, Facebook đã cho phép các nhà quảng cáo của mình cố tình nhắm mục tiêu quảng cáo theo giới tính, chủng tộc và tôn giáo. Ví dụ: phụ nữ được ưu tiên trong các quảng cáo việc làm cho vị trí điều dưỡng hoặc thư ký, trong khi quảng cáo việc làm cho người lao công và tài xế taxi hầu hết được hiển thị cho nam giới, đặc biệt là nam giới thuộc nhóm thiểu số.
Từ nguyên nhân trên Facebook sẽ không còn cho phép nhà tuyển dụng chỉ định nhắm mục tiêu theo độ tuổi, giới tính hoặc chủng tộc trong quảng cáo của mình.
Kết luận
Với những thông tin được cung cấp ở trên, chúng tôi hy vọng đã mang lại cho các bạn những hiểu biết nhất định trong việc xử lý thành kiến hay những hiểu biết sai lệch của quá trình đào tạo cũng như vận hành một mô hình ngôn ngữ có độ phức tạp như thế nào đồng thời có thể vận dụng nó trong các trường hợp sử dụng của thực tế.