


Tác giả: Haziqa Sajid
Ngày 10 tháng 2 năm 2024
Theo nghiên cứu của Microsoft, khoảng 88% số ngôn ngữ trên thế giới, được nói bởi 1,2 tỷ người, không có truy cập vào các Mô hình Ngôn Ngữ Lớn (LLMs). Điều này là do hầu hết các LLMs tập trung vào tiếng Anh, tức là chúng chủ yếu được xây dựng với dữ liệu tiếng Anh và cho người nói tiếng Anh. Ưu thế của tiếng Anh này cũng tồn tại trong quá trình phát triển của LLMs và đã dẫn đến một khoảng cách ngôn ngữ số, có thể loại trừ hầu hết mọi người khỏi các lợi ích của LLMs. Để giải quyết vấn đề này cho LLMs, cần có một LLM có thể được huấn luyện bằng nhiều ngôn ngữ và thực hiện các nhiệm vụ bằng nhiều ngôn ngữ khác nhau. Đây là lúc xuất hiện LLMs Đa Ngôn Ngữ!
Multilingual LLMs là gì?
Một LLM đa ngôn ngữ có thể hiểu và tạo ra văn bản trong nhiều ngôn ngữ khác nhau. Chúng được huấn luyện trên các tập dữ liệu chứa nhiều ngôn ngữ và có thể thực hiện các nhiệm vụ khác nhau bằng nhiều ngôn ngữ từ yêu cầu của người dùng.
Các ứng dụng của LLM đa ngôn ngữ là rất lớn, bao gồm dịch văn học sang các tiếng địa phương, giao tiếp đa ngôn ngữ trực tiếp, tạo nội dung đa ngôn ngữ, v.v. Chúng sẽ giúp mọi người dễ dàng truy cập thông tin và giao tiếp với nhau, không phụ thuộc vào ngôn ngữ của họ.
Ngoài ra, LLM đa ngôn ngữ giải quyết các thách thức như thiếu sắc thái văn hóa và bối cảnh, hạn chế dữ liệu huấn luyện và nguy cơ mất mát kiến thức trong quá trình dịch.
Cách hoạt động của Multilingual LLMs là gì?
Xây dựng một LLM đa ngôn ngữ đòi hỏi việc chuẩn bị một tập dữ liệu cân bằng các văn bản trong nhiều ngôn ngữ và lựa chọn một kiến trúc và kỹ thuật huấn luyện phù hợp để huấn luyện mô hình, ưu tiên là một mô hình Transformer, hoàn hảo cho việc học đa ngôn ngữ.
Các bước để xây dựng một LLM đa ngôn ngữ

Một kỹ thuật là chia sẻ các embeddings, những embedding này bắt kịp ý nghĩa ngữ nghĩa của từng từ qua các ngôn ngữ khác nhau. Điều này khiến cho LLM học được sự tương đồng và khác biệt của mỗi ngôn ngữ, giúp nó hiểu các ngôn ngữ khác nhau một cách tốt hơn.
Kiến thức này cũng giúp LLM thích ứng với các nhiệm vụ ngôn ngữ khác nhau, như dịch ngôn ngữ, viết theo các phong cách khác nhau, v.v. Một kỹ thuật khác được sử dụng là học chuyển giao giữa các ngôn ngữ, trong đó mô hình được tiền huấn luyện trên một tập dữ liệu lớn chứa các dữ liệu đa ngôn ngữ trước khi được điều chỉnh trên các nhiệm vụ cụ thể.
Quy trình hai bước này đảm bảo mô hình có một nền tảng vững chắc trong việc hiểu ngôn ngữ đa ngôn ngữ, khiến nó có thể thích nghi với các ứng dụng hậu cần khác nhau.
Các ví dụ về Multilingual Large Language Models
Bảng so sánh Multilingual LLM
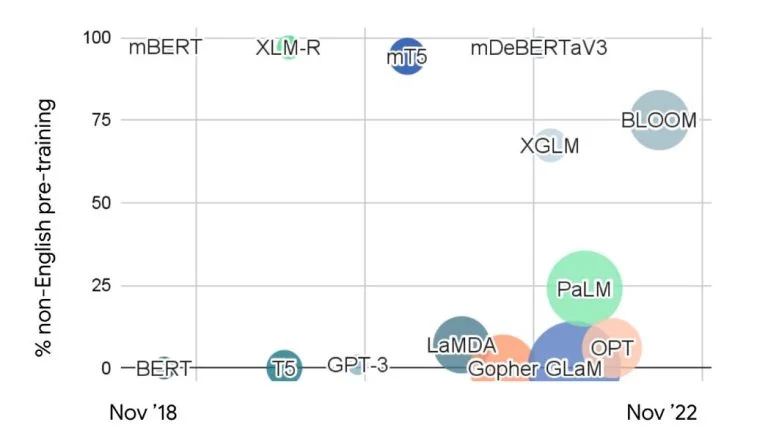
Một số ví dụ đáng chú ý về Multilingual LLM đã xuất hiện, mỗi cái phục vụ cho các nhu cầu ngôn ngữ cụ thể và bối cảnh văn hóa khác nhau. Hãy khám phá một số trong số chúng:
1. BLOOM
BLOOM là một Multilingual LLM có tính mở cửa, ưu tiên các ngôn ngữ đa dạng và tính truy cập. Với 176 tỷ tham số, BLOOM có thể xử lý các nhiệm vụ trong 46 ngôn ngữ tự nhiên và 13 ngôn ngữ lập trình, biến nó trở thành một trong những Multilingual LLM lớn nhất và đa dạng nhất.
Tính mã nguồn mở của BLOOM cho phép các nhà nghiên cứu, nhà phát triển và cộng đồng ngôn ngữ hưởng lợi từ khả năng của nó và đóng góp vào việc cải thiện của nó.
2. YAYI 2
YAYI 2 là một Multilingual LLM mã nguồn mở được thiết kế đặc biệt cho các ngôn ngữ châu Á, xem xét đến sự phức tạp và sắc thái văn hóa của khu vực này. Nó được tiền huấn luyện từ đầu trên một tập dữ liệu đa ngôn ngữ gồm hơn 16 ngôn ngữ châu Á chứa 2,65 nghìn tỷ token đã được lọc.
Điều này khiến cho mô hình đem lại kết quả tốt hơn, đáp ứng các yêu cầu cụ thể của ngôn ngữ và văn hóa ở châu Á.
3. PolyLM
PolyLM là một Multilingual LLM mã nguồn mở ‘đa ngôn ngữ’ tập trung vào giải quyết các thách thức của các ngôn ngữ ít tài nguyên bằng cách cung cấp khả năng thích ứng. Nó được huấn luyện trên một tập dữ liệu khoảng 640 tỷ token và có sẵn trong hai kích thước mô hình: 1,7 tỷ và 13 tỷ. PolyLM biết hơn 16 ngôn ngữ khác nhau.
Nó cho phép các mô hình được huấn luyện trên các ngôn ngữ có nhiều tài nguyên được điều chỉnh cho các ngôn ngữ ít tài nguyên với dữ liệu hạn chế. Sự linh hoạt này làm cho LLM trở nên hữu ích hơn trong các tình huống và nhiệm vụ ngôn ngữ khác nhau.
4. XGLM
XGLM, với 7,5 tỷ tham số, là một Multilingual LLM được huấn luyện trên một tập dữ liệu bao gồm một loạt các ngôn ngữ hơn 20 bằng kỹ thuật học một lần. Nó là một phần của một họ LLM đa ngôn ngữ tỷ lệ lớn được huấn luyện trên một tập dữ liệu lớn của văn bản và mã nguồn.
Mục tiêu của nó là bao phủ nhiều ngôn ngữ hoàn toàn, đó là lý do tại sao nó tập trung vào tính bao gồm và đa dạng ngôn ngữ. XGLM cho thấy tiềm năng để xây dựng các mô hình phục vụ nhu cầu của các cộng đồng ngôn ngữ khác nhau.
5. mT5
mT5 (massively multilingual Text-to-Text Transfer Transformer) được phát triển bởi Google AI. Được huấn luyện trên tập dữ liệu common crawl, mt5 là một Multilingual LLM tiên tiến có thể xử lý 101 ngôn ngữ, từ tiếng Tây Ban Nha và tiếng Trung phổ biến đến các ngôn ngữ ít tài nguyên như Basque và Quechua.
Nó cũng xuất sắc trong các nhiệm vụ đa ngôn ngữ như dịch, tóm tắt, trả lời câu hỏi, v.v.
Có Thể Xây Dựng Một Universal LLM?
Khái niệm về một Multilingual LLM không chủ đề ngôn ngữ, có khả năng hiểu và tạo ra ngôn ngữ mà không thiên vị về bất kỳ ngôn ngữ cụ thể nào, là một điều rất hấp dẫn.
Mặc dù việc phát triển một Multilingual LLM thực sự phổ quát vẫn còn xa xôi, nhưng các Multilingual LLMs hiện tại đã chứng minh được thành công đáng kể. Khi được phát triển hoàn chỉnh, chúng có thể đáp ứng được các nhu cầu của các ngôn ngữ ít được đại diện và các cộng đồng đa dạng.
Ví dụ, nghiên cứu cho thấy rằng hầu hết các Multilingual LLMs có thể hỗ trợ chuyển giao giữa các ngôn ngữ mà không cần dữ liệu huấn luyện cụ thể cho nhiệm vụ từ một ngôn ngữ giàu tài nguyên sang một ngôn ngữ nghèo tài nguyên.
Ngoài ra, các mô hình như YAYI và BLOOM, tập trung vào các ngôn ngữ và cộng đồng cụ thể, đã chứng minh được tiềm năng của các phương pháp tập trung vào ngôn ngữ trong việc thúc đẩy tiến bộ và tính bao gồm.
Để xây dựng một LLM phổ quát hoặc cải thiện các Multilingual LLM hiện tại, cá nhân và tổ chức cần thực hiện các biện pháp sau đây:
- Thu thập dữ liệu từ người bản xứ: Tổ chức các cuộc gặp gỡ với người bản xứ để kêu gọi sự tham gia của cộng đồng và sưu tập dữ liệu ngôn ngữ.
- Hỗ trợ các nỗ lực của cộng đồng: Ủng hộ và khuyến khích các hoạt động của cộng đồng đối với việc đóng góp mã nguồn mở và tài trợ cho nghiên cứu và phát triển đa ngôn ngữ.
Những thách thức của Multilingual LLMs
Mặc dù ý tưởng về các Multilingual LLMs đa ngôn ngữ mang lại nhiều tiềm năng, nhưng chúng cũng đối diện với một số thách thức phải được giải quyết trước khi chúng ta có thể hưởng lợi từ chúng:
1. Số lượng Dữ liệu
Các mô hình đa ngôn ngữ đòi hỏi một từ vựng lớn hơn để đại diện cho các token trong nhiều ngôn ngữ hơn so với các mô hình đơn ngôn ngữ, nhưng nhiều ngôn ngữ lại thiếu dữ liệu quy mô lớn. Điều này làm cho việc huấn luyện các mô hình này một cách hiệu quả trở nên khó khăn.
2. Lo ngại về Chất lượng Dữ liệu
Đảm bảo tính chính xác và tính thích hợp văn hóa của kết quả đầu ra của Multilingual LLMs trên các ngôn ngữ là một vấn đề lớn. Các mô hình phải được huấn luyện và điều chỉnh một cách tỉ mỉ, chú ý đến sự sắc nét ngôn ngữ và văn hóa để tránh sự thiên vị và không chính xác.
3. Hạn chế về Tài nguyên
Việc huấn luyện và chạy các mô hình đa ngôn ngữ đòi hỏi tài nguyên máy tính đáng kể như GPU mạnh mẽ (ví dụ: GPU NVIDIA A100). Chi phí cao tạo ra những thách thức, đặc biệt là đối với các ngôn ngữ và cộng đồng ít tài nguyên có hạn truy cập vào cơ sở hạ tầng máy tính.
4. Kiến trúc Mô hình
Việc điều chỉnh kiến trúc mô hình để chứa đựng các cấu trúc ngôn ngữ và độ phức tạp đa dạng là một thách thức liên tục. Các mô hình phải có khả năng xử lý các ngôn ngữ có thứ tự từ khác nhau, biến thể hình thái và hệ thống viết khác nhau trong khi duy trì hiệu suất và hiệu quả cao.
5. Khó khăn trong Đánh giá
Việc đánh giá hiệu suất của các Multilingual LLMs ngoài các tiêu chí thử nghiệm tiếng Anh là rất quan trọng để đo lường hiệu quả thực sự của chúng. Điều này đòi hỏi xem xét sắc thái văn hóa, đặc điểm ngôn ngữ và yêu cầu cụ thể của miền.
Multilingual LLMs có tiềm năng để phá vỡ các rào cản ngôn ngữ, động viên các ngôn ngữ ít tài nguyên và tạo điều kiện cho việc giao tiếp hiệu quả giữa các cộng đồng đa dạng.