


Tác giả: Aayush Mittal
ngày 11 tháng 10 năm 2023
Để ứng dụng Trí tuệ Nhân tạo quy mô lớn hoạt động tốt, cần phải có một hệ thống tốt để xử lý một lượng lớn dữ liệu. Một trong những hệ thống quan trọng như vậy là cơ sở dữ liệu vector. Cơ sở dữ liệu này đặc biệt vì nó xử lý nhiều loại dữ liệu như văn bản, âm thanh, hình ảnh và video dưới dạng số/vector.
Cơ sở dữ liệu Vector là một hệ thống lưu trữ chuyên biệt được thiết kế để xử lý hiệu quả các vector có chiều cao trong không gian nhiều chiều. Các vector này, có thể được coi như các điểm trong không gian đa chiều, thường biểu thị các nhúng hoặc biểu diễn nén của dữ liệu phức tạp hơn như hình ảnh, văn bản hoặc âm thanh. Cơ sở dữ liệu Vector cho phép tìm kiếm độ tương tự nhanh chóng giữa các vector này, giúp truy xuất nhanh các mục tương tự nhất từ một tập dữ liệu lớn.
Cơ sở Dữ liệu Truyền thống so với Cơ sở Dữ liệu Vector
Cơ sở Dữ liệu Vector:
- Xử lý Dữ liệu Đa Chiều: Cơ sở dữ liệu Vector được thiết kế để quản lý và lưu trữ dữ liệu trong không gian có chiều cao. Điều này đặc biệt hữu ích cho các ứng dụng như học máy, trong đó các điểm dữ liệu (như hình ảnh hoặc văn bản) có thể được biểu diễn dưới dạng vector trong không gian nhiều chiều.
- Tối ưu hóa cho Tìm kiếm Tương tự: Một tính năng nổi bật của cơ sở dữ liệu Vector là khả năng thực hiện tìm kiếm tương tự. Thay vì truy vấn dữ liệu dựa trên sự khớp chính xác, những cơ sở dữ liệu này cho phép người dùng truy xuất dữ liệu “tương tự” với một truy vấn cụ thể, làm cho chúng trở nên vô cùng quý báu cho các nhiệm vụ như truy xuất hình ảnh hoặc văn bản.
- Có khả năng Mở rộng cho Tập dữ liệu Lớn: Khi các ứng dụng Trí tuệ Nhân tạo và học máy tiếp tục phát triển, lượng dữ liệu mà chúng xử lý cũng tăng lên. Cơ sở dữ liệu Vector được xây dựng để có khả năng mở rộng, đảm bảo rằng chúng có thể xử lý lượng dữ liệu lớn mà không ảnh hưởng đến hiệu suất.
Cơ sở Dữ liệu Truyền thống:
- Lưu trữ Dữ liệu Có Cấu trúc: Các cơ sở dữ liệu truyền thống, như cơ sở dữ liệu quan hệ, được thiết kế để lưu trữ dữ liệu có cấu trúc. Điều này có nghĩa là dữ liệu được tổ chức thành các bảng, hàng và cột được xác định trước, đảm bảo tính toàn vẹn và nhất quán của dữ liệu.
- Tối ưu hóa cho Các Thao tác CRUD: Các cơ sở dữ liệu truyền thống chủ yếu được tối ưu hóa cho các thao tác CRUD. Điều này có nghĩa là chúng được thiết kế để tạo, đọc, cập nhật và xóa các mục dữ liệu một cách hiệu quả, làm cho chúng phù hợp cho một loạt ứng dụng, từ dịch vụ web đến phần mềm doanh nghiệp.
- Mẫu Cố định: Một trong những đặc điểm xác định của nhiều cơ sở dữ liệu truyền thống là mô hình cố định của chúng. Khi cấu trúc cơ sở dữ liệu đã được xác định, việc thay đổi có thể phức tạp và tốn thời gian. Sự cứng nhắc này đảm bảo tính nhất quán của dữ liệu nhưng có thể ít linh hoạt hơn so với tính chất không có mô hình cố định hoặc mô hình động của một số cơ sở dữ liệu hiện đại.
Các cơ sở dữ liệu cũ gặp khó khăn khi xử lý nhúng. Chúng không thể xử lý được tính phức tạp của chúng. Cơ sở dữ liệu vector giải quyết vấn đề này.
Biểu diễn Vector
Một khía cạnh quan trọng của hoạt động của các cơ sở dữ liệu vector là khái niệm cơ bản về biểu diễn các dạng đa dạng của dữ liệu bằng các vector số học. Hãy lấy hình ảnh làm ví dụ. Khi bạn nhìn thấy một bức tranh của một con mèo, trong khi nó có thể chỉ là một hình ảnh mèo đáng yêu đối với chúng ta, đối với máy móc, nó có thể được biến thành một vector 512 chiều duy nhất như sau:
[0.23, 0.54, 0.32, …, 0.12, 0.45, 0.90]
Với các cơ sở dữ liệu vector, ứng dụng Trí tuệ Nhân tạo tạo ra có thể thực hiện nhiều nhiệm vụ hơn. Nó có thể tìm thông tin dựa trên ý nghĩa và ghi nhớ thông tin trong thời gian dài. Điều thú vị là phương pháp này không bị hạn chế chỉ đối với hình ảnh mà còn có thể áp dụng cho dữ liệu văn bản chứa ý nghĩa ngữ cảnh và ý nghĩa ngữ nghĩa cũng.
Quá trình chuẩn hóa và cập nhật dữ liệu lên cơ sở dữ liệu vector
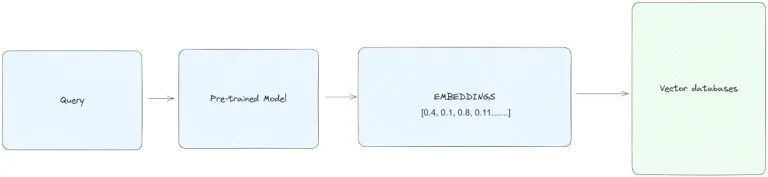
Biểu đồ thể hiện quy trình cơ bản của một cơ sở dữ liệu vector. Quy trình bắt đầu với việc nhập dữ liệu thô, sau đó đi qua quá trình tiền xử lý để làm sạch và chuẩn hóa dữ liệu.
Dữ liệu này sau đó được biến thành vector, chuyển đổi nó thành một định dạng phù hợp cho tìm kiếm tương tự và lưu trữ hiệu quả. Khi dữ liệu đã được biến thành vector, nó sẽ được lưu trữ và tạo chỉ mục để tạo điều kiện cho việc truy xuất nhanh chóng và chính xác. Khi có một truy vấn được tạo ra, cơ sở dữ liệu sẽ xử lý nó, tận dụng việc tạo chỉ mục để truy xuất dữ liệu phù hợp nhất một cách hiệu
Trí tuệ nhân tạo và Nhu cầu Cơ sở dữ liệu Vector
Trí tuệ Nhân tạo thường liên quan đến việc nhúng dữ liệu. Chẳng hạn, trong xử lý ngôn ngữ tự nhiên (NLP), ta có nhúng từ. Từ hoặc câu được biến đổi thành các vector chứa nghĩa ngữ nghĩa. Khi tạo ra văn bản giống người, các mô hình cần so sánh và truy xuất nhúng tương ứng một cách nhanh chóng, đảm bảo rằng văn bản được tạo ra giữ nguyên ý nghĩa ngữ cảnh. Đây là lý do cần sử dụng cơ sở dữ liệu vector trong Trí tuệ Nhân tạo.
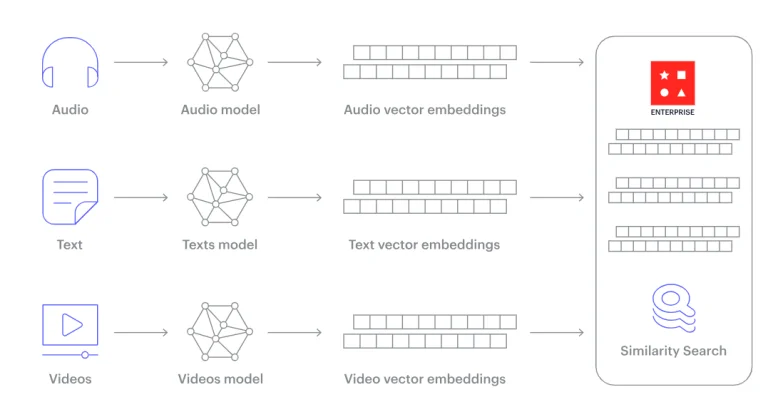
Tương tự, trong việc tạo hình ảnh hoặc âm thanh, nhúng đóng một vai trò quan trọng trong việc mã hóa các mẫu và đặc điểm. Để các mô hình này hoạt động tối ưu, chúng cần một cơ sở dữ liệu cho phép truy xuất ngay lập tức các vector tương tự, làm cho cơ sở dữ liệu vector trở thành một phần thiết yếu của bức puzzle Trí tuệ Nhân tạo Sinh sản.
Việc tạo nhúng cho ngôn ngữ tự nhiên thường liên quan đến việc sử dụng các mô hình được đào tạo trước như GPT của OpenAI, BERT.
Các Mô hình Đã Đào tạo Trước:
- GPT-3 và GPT-4: GPT-3 (Generative Pre-trained Transformer 3) của OpenAI đã là một mô hình quan trọng trong cộng đồng NLP với 175 tỷ tham số. Tiếp theo, GPT-4, với một số lượng tham số còn lớn hơn, tiếp tục đẩy giới hạn trong việc tạo ra nhúng chất lượng cao. Những mô hình này được đào tạo trên các tập dữ liệu đa dạng, giúp chúng tạo ra nhúng bắt kịp nhiều sắc thái ngôn ngữ.
- BERT và các Biến thể: BERT (Bidirectional Encoder Representations from Transformers) của Google, là một mô hình quan trọng khác đã trải qua các bản cập nhật và phiên bản như RoBERTa và DistillBERT. Việc đào tạo hai chiều của BERT, đọc văn bản cả hai chiều, đặc biệt giỏi trong việc hiểu ngữ cảnh xung quanh một từ.
- ELECTRA: Một mô hình gần đây hơn, hiệu quả và hoạt động tương đương với các mô hình lớn hơn như GPT-3 và BERT trong khi yêu cầu ít tài nguyên máy tính hơn. ELECTRA phân biệt giữa dữ liệu thật và dữ liệu giả trong quá trình đào tạo trước, giúp tạo ra những nhúng tinh tế hơn.
Bùng nổ đầu tư vào những dự án mới phát triển cơ sở dữ liệu Vector
Với sự phổ biến ngày càng tăng của Trí tuệ Nhân tạo, nhiều công ty đang đầu tư nhiều hơn vào cơ sở dữ liệu vector để làm cho các thuật toán của họ tốt hơn và nhanh hơn. Điều này có thể thấy qua các khoản đầu tư gần đây vào các công ty khởi nghiệp cơ sở dữ liệu vector như Pinecone, Chroma DB và Weviate.

Các tập đoàn lớn như Microsoft cũng có các công cụ của riêng họ. Ví dụ, Azure Cognitive Search cho phép các doanh nghiệp tạo các công cụ Trí tuệ Nhân tạo bằng cách sử dụng cơ sở dữ liệu vector.
Oracle cũng vừa thông báo về các tính năng mới cho Cơ sở dữ liệu 23c của họ, giới thiệu một Cơ sở dữ liệu Vector tích hợp. Được đặt tên là “AI Vector Search,” nó sẽ có một loại dữ liệu mới, các chỉ mục và các công cụ tìm kiếm để lưu trữ và tìm kiếm dữ liệu như tài liệu và hình ảnh bằng cách sử dụng vector. Nó hỗ trợ Retrieval Augmented Generation (RAG), kết hợp các mô hình ngôn ngữ lớn với dữ liệu kinh doanh để có câu trả lời tốt hơn cho các câu hỏi ngôn ngữ mà không cần chia sẻ dữ liệu riêng tư.
Các Yếu tố Chính của Cơ sở Dữ liệu Vector
- Chỉ mục hóa (Indexing): Do tính chiều cao của các vector, các phương pháp chỉ mục hóa truyền thống không phù hợp. Cơ sở dữ liệu vector sử dụng các kỹ thuật như đồ thị Hierarchical Navigable Small World (HNSW) hoặc cây Annoy, cho phép phân chia không gian vector một cách hiệu quả và tìm kiếm hàng xóm gần nhất một cách nhanh chóng.

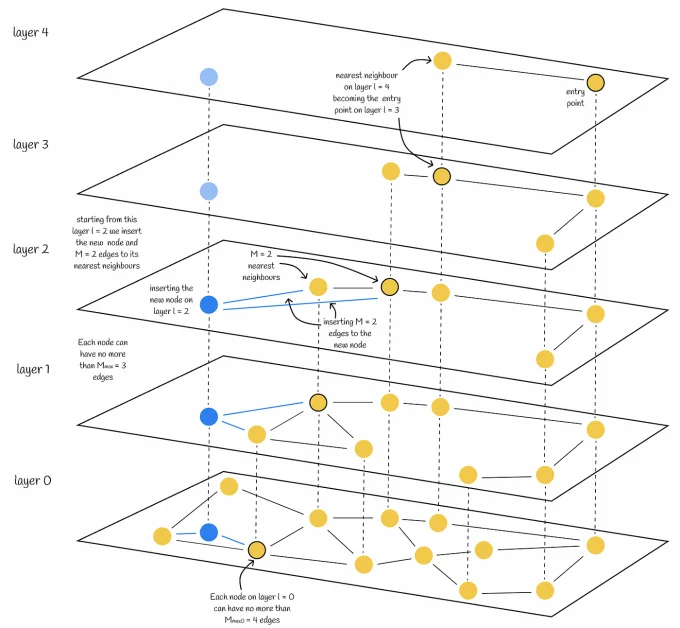
- Phương pháp Khoảng cách (Distance Metrics): Sự hiệu quả của tìm kiếm tương tự phụ thuộc vào phương pháp khoảng cách đã chọn. Các phương pháp thông thường bao gồm khoảng cách Euclidean và độ tương tự cosine, mỗi phương pháp phục vụ cho các loại phân phối vector khác nhau.
- Khả năng Mở rộng (Scalability): Khi tập dữ liệu tăng lên, thách thức về việc duy trì thời gian truy xuất nhanh cũng tăng lên. Hệ thống phân tán, tăng cường GPU và quản lý bộ nhớ tối ưu hóa là một số cách mà cơ sở dữ liệu vector đối phó với khả năng mở rộng.
Cơ sở dữ liệu Vector và Trí tuệ Nhân tạo Sinh sản: Tốc độ và Sáng tạo
Sự phép thuật thực sự xảy ra khi cơ sở dữ liệu vector làm việc cùng với các mô hình Trí tuệ Nhân tạo Sinh sản. Dưới đây là lý do:
- Tăng cường Sự Liên kết: Bằng cách cho phép truy xuất nhanh chóng các vector tương tự, các mô hình sinh sản có thể duy trì ngữ cảnh tốt hơn, dẫn đến các kết quả có tính logic và phù hợp về ngữ cảnh.
- Sáng tạo qua Quá trình Điều chỉnh: Các mô hình sinh sản có thể sử dụng cơ sở dữ liệu vector để so sánh kết quả sinh ra với một bộ sưu tập các nhúng “tốt”, cho phép họ điều chỉnh kết quả của họ trong thời gian thực.
- Đa Dạng về Kết quả: Với khả năng khám phá các khu vực khác nhau trong không gian vector, các mô hình sinh sản có thể tạo ra nhiều loại kết quả khác nhau, làm phong phú tiềm năng sáng tạo của họ.
Tương lai: Tác động và Cơ hội Tiềm năng

Khi sự kết hợp giữa Trí tuệ Nhân tạo và cơ sở dữ liệu vector có một số khả năng thú vị sẽ xuất hiện:
- Nội dung cá nhân hóa: Hãy tưởng tượng mô hình Trí tuệ Nhân tạo tạo ra nội dung cá nhân hóa, cho dù là văn bản, hình ảnh, hoặc âm nhạc, dựa trên các nhúng cá nhân của người dùng được lưu trữ trong cơ sở dữ liệu vector. Thời đại của nội dung siêu cá nhân có thể không còn xa.
- Giải pháp Truy xuất Dữ liệu trong miền ứng dụng hẹp: Ngoài Trí tuệ Nhân tạo, cơ sở dữ liệu vector có thể cách mạng hóa truy xuất dữ liệu trong các lĩnh vực như thương mại điện tử, nơi đề xuất sản phẩm có thể dựa trên dữ liệu phân tích thói quen và hành vi của người sử dụng.
Thế giới Trí tuệ Nhân tạo đang thay đổi nhanh chóng. Nó đang ảnh hưởng đến nhiều ngành công nghiệp, mang lại nhiều điều tốt lành và đặt ra những vấn đề mới cần sớm giải quyết. Cơ sở dữ liệu Vector đang làm quá tốt điều này không chỉ với hiện tại mà ngay cả với tương lai xán lạn đang đến.