


Tác giả: Aayush Mittal
Ngày 1 tháng 12 năm 2023
Học máy, một phần nhỏ của Trí tuệ Nhân tạo, bao gồm ba thành phần chính: thuật toán, dữ liệu huấn luyện và mô hình kết quả. Một thuật toán, về cơ bản là một tập hợp các thủ tục, học cách nhận diện các mẫu từ một tập hợp lớn các ví dụ (dữ liệu huấn luyện). Kết quả của quá trình huấn luyện này là một mô hình học máy. Ví dụ, một thuật toán được huấn luyện với hình ảnh của chó sẽ tạo ra một mô hình có khả năng nhận diện chó trong các hình ảnh.
Hộp Đen trong Học Máy
Trong học máy, bất kỳ một trong ba thành phần – thuật toán, dữ liệu huấn luyện hoặc mô hình – có thể trở thành một hộp đen. Trong khi thuật toán thường được công bố công khai, các nhà phát triển có thể chọn giữ bí mật về mô hình hoặc dữ liệu huấn luyện để bảo vệ quyền sở hữu trí tuệ. Sự không rõ này khiến cho việc hiểu quá trình ra quyết định của trí tuệ nhân tạo trở nên khó khăn.
Hộp đen của trí tuệ nhân tạo là những hệ thống mà bên trong vẫn được giữ là bí mật hoặc không thể nhìn thấy đối với người sử dụng. Người sử dụng có thể nhập dữ liệu và nhận được kết quả, nhưng logic hoặc mã nguồn tạo ra kết quả vẫn được giấu kín. Điều này là đặc điểm phổ biến trong nhiều hệ thống trí tuệ nhân tạo, bao gồm cả các mô hình tạo ra nâng cao như ChatGPT và DALL-E 3.
Các mô hình ngôn ngữ lớn như GPT-4 đặt ra một thách thức lớn: bản chất bí mật của chúng, khiến chúng trở thành “hộp đen”. Sự mờ mịch này không chỉ là một câu đố kỹ thuật; nó đặt ra những lo ngại thực tế và đạo đức trong thế giới thực. Ví dụ, nếu chúng ta không thể nhận biết được cách những hệ thống này đưa ra những kết luận, liệu chúng ta có thể tin tưởng chúng trong các lĩnh vực quan trọng như chẩn đoán y tế hay đánh giá tài chính không?
Khám phá các Kỹ thuật của LIME và SHAP
Khả năng giải thích trong các mô hình học máy (ML) và học sâu (DL) giúp chúng ta nhìn rõ vào bản chất mờ mịt của những mô hình tiên tiến này. Local Interpretable Model-agnostic Explanations (LIME) và SHapley Additive exPlanations (SHAP) là hai kỹ thuật giải thích phổ biến như vậy.
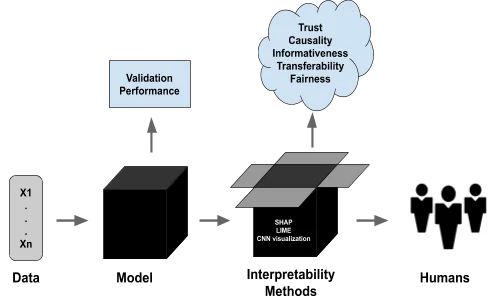
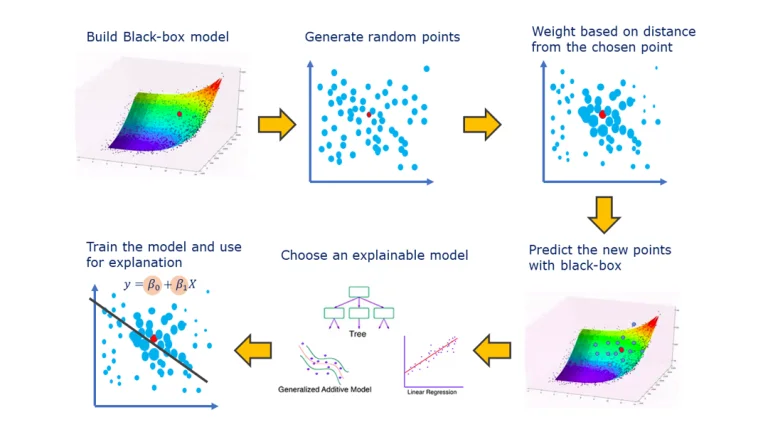
Ví dụ, LIME phân rã sự phức tạp bằng cách tạo ra các mô hình thay thế đơn giản, cục bộ mà xấp xỉ hành vi của mô hình gốc xung quanh một đầu vào cụ thể. Bằng cách này, LIME giúp hiểu cách các đặc trưng cá nhân ảnh hưởng đến các dự đoán của các mô hình phức tạp, về cơ bản cung cấp một giải thích ‘địa phương’ về lý do tại sao một mô hình đưa ra một quyết định cụ thể. Điều này đặc biệt hữu ích đối với người dùng không chuyên môn, vì nó dịch ngược quá trình đưa ra quyết định phức tạp của các mô hình thành ngôn ngữ dễ hiểu hơn.
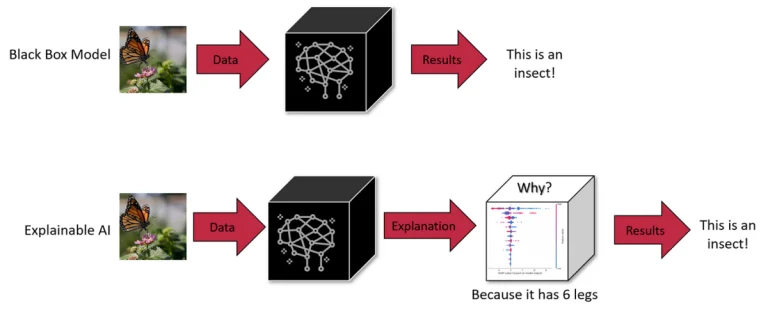
Ngược lại, SHAP lấy cảm hứng từ lý thuyết trò chơi, cụ thể là khái niệm về giá trị Shapley. Nó gán một giá trị ‘quan trọng’ cho mỗi đặc trưng, chỉ ra mức độ mà mỗi đặc trưng đóng góp vào sự khác biệt giữa dự đoán thực tế và dự đoán cơ sở (dự đoán trung bình trên tất cả các đầu vào). Sức mạnh của SHAP nằm ở tính nhất quán và khả năng cung cấp một cái nhìn toàn cầu – nó không chỉ giải thích từng dự đoán cụ thể mà còn cung cấp thông tin về mô hình như một tổng thể. Điều này đặc biệt quý báu trong các mô hình học sâu, nơi các lớp kết nối và nhiều tham số thường khiến quá trình dự đoán trở nên như một hành trình qua mê cung. SHAP làm rõ điều này bằng cách đo lường đóng góp của mỗi đặc trưng, mang lại một bản đồ rõ ràng về các đường đi quyết định của mô hình.
Cả LIME và SHAP đều trở thành các công cụ quan trọng trong lĩnh vực Trí tuệ Nhân tạo (AI) và Học máy (ML), đáp ứng nhu cầu cấp bách về sự minh bạch và đáng tin cậy. Khi chúng ta tiếp tục tích hợp AI sâu rộng vào các lĩnh vực khác nhau, khả năng giải thích và hiểu rõ những mô hình này không chỉ là một yêu cầu kỹ thuật mà còn là một yêu cầu cơ bản cho sự phát triển AI đạo đức và có trách nhiệm. Các kỹ thuật này đại diện cho những bước tiến quan trọng trong việc làm sáng tỏ những phức tạp của các mô hình ML và DL, biến chúng từ những ‘hộp đen’ không thể hiểu được thành các hệ thống có thể được hiểu, tin tưởng và sử dụng hiệu quả về quyết định và hành vi.
Quy mô và Phức tạp của các Mô hình Ngôn ngữ Lớn
Quy mô của những mô hình này làm tăng thêm vào sự phức tạp của chúng. Hãy xem xét GPT-3 ví dụ, với 175 tỷ tham số, và các mô hình mới có thể lên đến hàng nghìn tỷ. Mỗi tham số tương tác một cách phức tạp trong mạng thần kinh, đóng góp vào những khả năng mới mẻ không thể dự đoán được chỉ bằng cách xem xét các thành phần cá nhân một cách riêng lẻ. Quy mô và phức tạp này làm cho việc hiểu đúng hoàn toàn về logic nội tại của chúng trở nên gần như không thể, đặt ra một rào cản trong việc chẩn đoán độ chệch hoặc hành vi không mong muốn trong các mô hình này.
Sự đánh đổi: Quy mô so với Khả năng Giải thích
Việc giảm quy mô của các Mô hình Ngôn ngữ Lớn có thể tăng cường khả năng giải thích nhưng điều này đồng nghĩa với việc giảm đi khả năng tiên tiến của chúng. Quy mô là điều làm cho chúng có thể thực hiện những hành vi mà các mô hình nhỏ hơn không thể đạt được. Điều này tạo ra một sự đánh đổi cơ bản giữa quy mô, khả năng và khả năng giải thích.
Tác Động của Vấn Đề Hộp Đen trong các Mô hình Ngôn ngữ Lớn
- Quyết Định Sai Lầm
Sự mập mờ trong quá trình ra quyết định của các Mô hình Ngôn ngữ Lớn (LLMs) như GPT-3 hoặc BERT có thể dẫn đến sự chệch lệch và lỗi không phát hiện được. Trong các lĩnh vực như chăm sóc sức khỏe hoặc công lý hình sự, nơi quyết định mang theo hậu quả xa lớn, việc không thể kiểm tra LLMs về đạo đức và tính hợp lý là một vấn đề lớn. Ví dụ, một LLM chẩn đoán y tế dựa trên dữ liệu lỗi thời hoặc chệch lệch có thể đưa ra những đề xuất gây hại. Tương tự, các LLM trong quá trình tuyển dụng có thể vô tình duy trì các định kiến về giới tính. Tính chất ‘hộp đen’ không chỉ giấu đi các khuyết điểm mà còn có thể tăng cường chúng, đòi hỏi một cách tiếp cận tích cực để nâng cao sự minh bạch.
- Sự Hạn Chế trong Việc Thích Ứng Ở Ngữ Cảnh Đa Dạng
Sự thiếu thông tin về cách các LLM hoạt động bên trong hạn chế khả năng thích ứng của chúng. Ví dụ, một LLM trong quá trình tuyển dụng có thể không hiệu quả khi đánh giá ứng viên cho một vai trò mà ưa chuộng kỹ năng thực hành hơn là trình độ học vấn, do không thể điều chỉnh các tiêu chí đánh giá của nó. Tương tự, một LLM y tế có thể gặp khó khăn trong chẩn đoán các bệnh hiếm do sự mất cân đối trong dữ liệu. Sự không linh hoạt này làm nổi bật nhu cầu về sự minh bạch để điều chỉnh lại LLMs cho các nhiệm vụ và ngữ cảnh cụ thể.
- Thiên Lệch và Lỗ Hổng Kiến Thức
Việc xử lý dữ liệu huấn luyện lớn của LLMs đang chịu sự hạn chế do thuật toán và kiến trúc mô hình của chúng. Ví dụ, một LLM y tế có thể hiển thị những độ chệch dân số nếu được huấn luyện trên các bộ dữ liệu không cân đối. Ngoài ra, sự thành thạo của một LLM trong các chủ đề hẹp có thể là một nguồn lừa dối, dẫn đến kết quả không chính xác và quá mức tự tin. Để giải quyết những thiên lệch và lỗ hổng kiến thức này, cần hơn là chỉ là việc thêm dữ liệu; điều này đòi hỏi một sự xem xét về cơ chế xử lý của mô hình.
- Trách Nhiệm Pháp Lý và Đạo Đức
Tính mập mờ của LLMs tạo ra một khu vực pháp lý không rõ ràng liên quan đến trách nhiệm về mọi thiệt hại gây ra bởi các quyết định của chúng. Nếu một LLM trong môi trường y tế cung cấp lời khuyên sai lầm dẫn đến tổn thương cho bệnh nhân, việc xác định trách nhiệm trở nên khó khăn do tính mờ mịt của mô hình. Sự không chắc chắn pháp lý này mang lại những rủi ro cho các tổ chức triển khai LLMs trong những lĩnh vực nhạy cảm, làm nổi bật nhu cầu về quản lý rõ ràng và minh bạch.
- Vấn Đề Tin Tưởng trong Các Ứng Dụng Nhạy Cảm
Đối với các LLM được sử dụng trong các lĩnh vực quan trọng như chăm sóc sức khỏe và tài chính, sự thiếu minh bạch làm suy giảm độ tin cậy của chúng. Người sử dụng và cơ quan quản lý cần đảm bảo rằng những mô hình này không chứa đựng các độ chệch hoặc đưa ra quyết định dựa trên các tiêu chí không công bằng. Xác nhận sự vắng mặt của độ chệch trong các LLMs đòi hỏi một sự hiểu biết về quy trình ra quyết định của chúng, nhấn mạnh tầm quan trọng của khả năng giải thích để triển khai đạo đức.
- Rủi Ro với Dữ Liệu Cá Nhân
LLMs đòi hỏi dữ liệu huấn luyện mà có thể bao gồm thông tin cá nhân nhạy cảm. Tính chất ‘hộp đen’ của những mô hình này đặt ra lo ngại về cách dữ liệu này được xử lý và sử dụng. Ví dụ, một LLM y tế được huấn luyện trên hồ sơ bệnh nhân đặt ra những câu hỏi về quyền riêng tư và việc sử dụng dữ liệu. Đảm bảo rằng dữ liệu cá nhân không bị lạm dụng hoặc khai thác đòi hỏi các quy trình xử lý dữ liệu minh bạch trong những mô hình này.
Các Giải Pháp Nổi Bật cho Khả năng Giải Thích
Để đối mặt với những thách thức này, các kỹ thuật mới đang được phát triển. Trong số đó có các phương pháp xấp xỉ Phản chứng (CF). Phương pháp đầu tiên liên quan đến việc khích lệ một LLM thay đổi một khái niệm văn bản cụ thể trong khi giữ nguyên các khái niệm khác. Phương pháp này, mặc dù hiệu quả, nhưng tốn nhiều tài nguyên khi thực hiện.
Phương pháp thứ hai liên quan đến việc tạo ra một không gian nhúng riêng biệt được hướng dẫn bởi một LLM trong quá trình huấn luyện. Không gian này liên quan đến một biểu đồ nguyên nhân và giúp xác định các phù hợp xấp xỉ với các Phản chứng. Phương pháp này đòi hỏi ít tài nguyên hơn ở thời điểm kiểm tra và đã được chứng minh là có hiệu quả trong việc giải thích dự đoán của mô hình, ngay cả trong những LLMs với hàng tỷ tham số.
Các phương pháp này làm nổi bật tầm quan trọng của giải thích nguyên nhân trong các hệ thống xử lý ngôn ngữ tự nhiên để đảm bảo an toàn và xây dựng niềm tin. Xấp xỉ Phản chứng cung cấp một cách để tưởng tượng làm thế nào một văn bản cụ thể sẽ thay đổi nếu một khái niệm cụ thể trong quá trình tạo ra nó khác đi, giúp ước lượng ảnh hưởng nguyên nhân thực tế của các khái niệm cấp cao đối với các mô hình xử lý ngôn ngữ tự nhiên
Điều Tra Sâu: Các Phương Pháp Giải Thích và Nguyên Nhân trong LLMs

Công cụ Điều Tra và Quan Trọng Các Đặc Trưng
Điều tra là một kỹ thuật được sử dụng để giải mã những biểu diễn nội tại trong các mô hình. Nó có thể được thực hiện theo hướng giám sát hoặc không giám sát và nhằm vào việc xác định liệu các khái niệm cụ thể có được mã hóa ở các vị trí cụ thể trong mạng hay không. Mặc dù có hiệu quả đến một mức độ nào đó, công cụ điều tra vẫn hạn chế trong việc cung cấp giải thích nguyên nhân, như đã được làm nổi bật bởi Geiger và đồng nghiệp (2021).
Công cụ quan trọng các đặc trưng, một dạng khác của phương pháp giải thích, thường tập trung vào các đặc trưng đầu vào, mặc dù một số phương pháp dựa trên độ dốc có thể mở rộng điều này đến trạng thái ẩn. Một ví dụ là phương pháp Gradient Tổng Hợp, nó cung cấp một giải thích nguyên nhân bằng cách khám phá các đầu vào cơ sở (phản chứng, CF). Mặc dù hữu ích, những phương pháp này vẫn gặp khó khăn khi kết nối các phân tích của họ với các khái niệm thực tế trong thế giới ngoài các đặc tính đơn giản của đầu vào.
Các Phương Pháp Dựa Trên Can Thiệp
Các phương pháp dựa trên can thiệp liên quan đến việc thay đổi đầu vào hoặc biểu diễn nội tại để nghiên cứu các ảnh hưởng đối với hành vi của mô hình. Những phương pháp này có thể tạo ra các trạng thái phản chứng để ước lượng ảnh hưởng nguyên nhân, nhưng thường tạo ra các đầu vào hoặc trạng thái mạng không hợp lý trừ khi được kiểm soát cẩn thận. Mô hình ổn định Can Thiệp (CPM), được lấy cảm hứng từ khái niệm S-learner, là một phương pháp mới trong lĩnh vực này, mô phỏng hành vi của mô hình được giải thích dưới các đầu vào phản chứng. Tuy nhiên, nhu cầu về một người giải thích riêng biệt cho mỗi mô hình là một hạn chế lớn.
Xấp xỉ Phản chứng
Phản chứng được sử dụng rộng rãi trong học máy cho việc tăng cường dữ liệu, bao gồm sự biến đổi các yếu tố hoặc nhãn khác nhau. Chúng có thể được tạo ra thông qua chỉnh sửa thủ công, thay thế từ khóa heuristics hoặc tái viết văn bản tự động. Mặc dù chỉnh sửa thủ công có độ chính xác cao, nhưng cũng tốn nhiều tài nguyên. Các phương pháp dựa trên từ khóa có nhược điểm của chúng, và các phương pháp sinh tạo cung cấp một sự cân bằng giữa sự lưu loát và phạm vi.
Giải Thích Trung Thực

Trung thực trong giải thích đề cập đến việc mô tả đầy đủ cơ sở lý do của mô hình. Không có định nghĩa về trung thực được chấp nhận phổ quát, dẫn đến việc đặc trưng thông qua các chỉ số khác nhau như Độ Nhạy, Tính Nhất Quán, Đồng ý Quan Trọng Đặc Trưng, Sự Mạnh Mẽ, và Khả Năng Mô Phỏng. Hầu hết các phương pháp này tập trung vào giải thích cấp đặc trưng và thường lẫn lộn giữa sự tương quan và nguyên nhân. Công việc của chúng tôi nhằm mục tiêu cung cấp giải thích về khái niệm cấp cao, tận dụng từ vựng nguyên nhân học để đề xuất một tiêu chí trực quan: Trung Thực theo Thứ Tự.
Chúng tôi đã đào sâu vào sự phức tạp bẩm sinh của LLMs, hiểu rõ tính chất ‘hộp đen’ của chúng và những thách thức lớn mà nó đối diện. Từ rủi ro của quyết định sai lầm trong các lĩnh vực nhạy cảm như chăm sóc sức khỏe và tài chính đến những tình thế đạo đức xung quanh độ chệch và công bằng, nhu cầu về sự minh bạch trong LLMs chưa bao giờ trở nên rõ ràng như vậy.
Tương lai của LLMs và sự tích hợp của chúng vào cuộc sống hàng ngày và quyết định quan trọng của chúng phụ thuộc vào khả năng của chúng ta không chỉ để làm cho những mô hình này tiên tiến hơn mà còn hiểu được và chịu trách nhiệm hơn. Việc theo đuổi khả năng giải thích và hiểu được không chỉ là một nỗ lực kỹ thuật mà còn là một khía cạnh cơ bản của việc xây dựng niềm tin vào các hệ thống AI. Khi LLMs trở nên ngày càng tích hợp vào xã hội, nhu cầu về sự minh bạch sẽ tăng lên, không chỉ từ các chuyên gia AI mà còn từ mọi người sử dụng tương tác với những hệ thống này.