

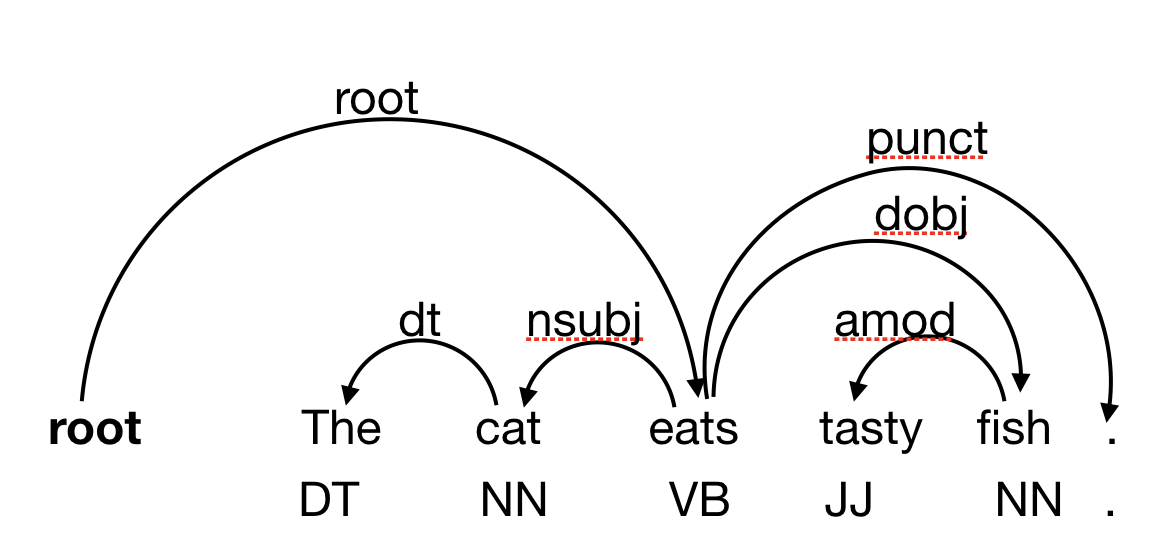
Phân giải phụ thuộc (Dependency Parsing) là quá trình phân tích cú pháp câu để xác định các mối quan hệ phụ thuộc cú pháp giữa các từ trong một câu. Nhiệm vụ của Dependency Parsing là tạo ra một cây phụ thuộc (dependency tree) biểu diễn sự phụ thuộc cú pháp giữa các từ trong câu.
Cơ chế Dependency Parsing trong huấn luyện mô hình ngôn ngữ thường dựa trên các phương pháp học máy và mô hình học sâu. Mô hình được huấn luyện trên một tập dữ liệu gồm các câu đã được gán nhãn với các quan hệ phụ thuộc giữa các từ. Quá trình huấn luyện mô hình có thể được thực hiện bằng việc tối ưu hóa một hàm mất mát, ví dụ như hàm mất mát phụ thuộc vào các cạnh (edge) trong cây phụ thuộc.
Trong quá trình huấn luyện, mô hình học cách dự đoán quan hệ phụ thuộc giữa các từ dựa trên các đặc trưng ngữ cảnh của các từ đó. Đặc trưng ngữ cảnh có thể bao gồm thông tin từ vựng, vị trí của từ trong câu, từ loại, hoặc các đặc trưng ngữ nghĩa khác. Mô hình sẽ cố gắng tìm ra các mẫu và quy tắc phụ thuộc trong dữ liệu huấn luyện để dự đoán các mối quan hệ phụ thuộc chính xác trong câu.
Ví dụ:
Giả sử chúng ta có câu tiếng Việt sau: “Tôi đang đọc một cuốn sách hay.”
Quá trình Dependency Parsing sẽ tạo ra một cây phụ thuộc để biểu diễn mối quan hệ phụ thuộc giữa các từ trong câu.
Cây phụ thuộc cho câu trên có thể được biểu diễn như sau:
đọc (ROOT)
/ \
Tôi sách
/ \
một hayTrong cây phụ thuộc này, từ “đọc” là nút gốc (ROOT) của cây, và các từ còn lại là con của nút gốc. Cụ thể, từ “Tôi” phụ thuộc vào “đọc”, “sách” phụ thuộc vào “đọc”, “một” phụ thuộc vào “sách”, và “hay” phụ thuộc vào “sách”.
Các mối quan hệ phụ thuộc được biểu diễn bằng các cạnh trong cây phụ thuộc. Mỗi cạnh sẽ có một nhãn mô tả mối quan hệ phụ thuộc. Ví dụ, trong cây trên, cạnh giữa “Tôi” và “đọc” có nhãn là “nsubj” (chủ ngữ), cạnh giữa “đọc” và “sách” có nhãn là “ROOT” (gốc), cạnh giữa “sách” và “một” có nhãn là “num” (số từ), và cạnh giữa “sách” và “hay” có nhãn là “amod” (tính từ bổ nghĩa).
Trong ví dụ trên, từ “đọc” được chọn làm nút gốc (ROOT) của cây phụ thuộc vì nó thể hiện hành động chính trong câu. Trong một câu, nút gốc thường là từ đại diện cho hành động hoặc trạng thái chính.
Trong trường hợp này, câu chứa động từ “đọc” và từ “đọc” đang biểu thị hành động chính mà người nói (tôi) đang thực hiện. Các từ khác như “Tôi”, “sách”, “một”, và “hay” đều liên quan đến hành động “đọc” và phụ thuộc vào nó.
Do đó, để xây dựng cây phụ thuộc, từ “đọc” được chọn làm nút gốc và các từ khác trong câu được liên kết với nó thông qua các mối quan hệ phụ thuộc.
Ví dụ khác: “Giá thay gas điều hoà 9000btu dùng gas R32 là bao nhiêu?”
(Giá)
/ | \
(thay) (điều hoà)
/ |
(gas) (9000btu)
| |
(R32) (dùng)Trong câu này, động từ “thay” (replace) là nút gốc (root) của cây phụ thuộc. Từ “giá” (price) là phụ thuộc trực tiếp của “thay” (replace), và từ “điều hoà” (air conditioner) là phụ thuộc trực tiếp của “thay” (replace). Từ “gas” (gas) là phụ thuộc trực tiếp của “điều hoà” (air conditioner), và từ “9000btu” (9000btu) là phụ thuộc trực tiếp của “điều hoà” (air conditioner). Cuối cùng, từ “dùng” (use) là phụ thuộc trực tiếp của “9000btu” (9000btu), và từ “R32” (R32) là phụ thuộc trực tiếp của “gas” (gas).
Cây phụ thuộc này biểu thị mối quan hệ phụ thuộc giữa các từ trong câu. Ví dụ, từ “giá” (price) là một đối tượng (object) của động từ “thay” (replace), và từ “điều hoà” (air conditioner) là một chủ thể (subject) của động từ “thay” (replace). Từ “gas” (gas) là một loại (type) của “điều hoà” (air conditioner), và từ “9000btu” (9000btu) là một thông số (specification) của “điều hoà” (air conditioner). Từ “R32” (R32) là loại gas (gas type) mà “điều hoà” (air conditioner) sử dụng.
Quá trình phân giải phụ thuộc có thể áp dụng cho văn bản lớn được không?
Câu trả lời là Có, quá trình này có thể được áp dụng để phân tích một đoạn văn bản lớn. Tuy nhiên, quá trình phân tích sẽ phức tạp hơn và có thể đòi hỏi tài nguyên tính toán cao.
Phân tích Dependency Parsing trên đoạn văn bản lớn thường được thực hiện bằng cách chia văn bản thành các câu riêng biệt và sau đó áp dụng Dependency Parsing cho từng câu một. Quá trình này có thể sử dụng các mô hình Dependency Parsing như Neural Dependency Parser hoặc Transition-Based Parser để tạo ra cây phụ thuộc cho mỗi câu.
Tuy nhiên, khi phân tích một đoạn văn bản lớn, có một số thách thức cần xem xét. Đầu tiên, việc chia văn bản thành các câu có thể gặp khó khăn nếu không có dấu chấm câu rõ ràng để phân cách câu. Thứ hai, sự phụ thuộc giữa các câu trong đoạn văn bản cũng có thể được xem xét để xác định mối quan hệ giữa chúng.
Ngoài ra, khi phân tích một đoạn văn bản lớn, cần xem xét hiệu suất tính toán và tài nguyên để đảm bảo quá trình phân tích có thể được thực hiện một cách hiệu quả. Các kỹ thuật như phân tán xử lý (distributed processing) và tối ưu hóa thuật toán có thể được áp dụng để tăng tốc quá trình phân tích trên đoạn văn bản lớn.
Ứng dụng của phân giải phụ thuộc cú pháp áp dụng ở đâu
Phân giải phụ thuộc cú pháp có nhiều ứng dụng hữu ích trong lĩnh vực xử lý ngôn ngữ tự nhiên và các tác vụ liên quan. Dưới đây là một số ứng dụng của Dependency Parsing:
- Phân tích câu: Dependency Parsing giúp phân tích cú pháp của câu, xác định cấu trúc ngữ pháp và mối quan hệ phụ thuộc giữa các từ. Điều này có thể hỗ trợ việc phân tích cú pháp tự động, trích xuất thông tin và phân loại câu.
- Dịch máy: Trong quá trình dịch máy, Dependency Parsing có thể giúp xây dựng cây phụ thuộc cho câu nguồn và câu đích, từ đó giúp hiểu và ánh xạ mối quan hệ ngữ nghĩa giữa các từ trong cả hai ngôn ngữ. Điều này có thể cung cấp thông tin quan trọng để cải thiện chất lượng dịch máy.
- Trích xuất thông tin: Dependency Parsing có thể giúp trích xuất thông tin cú pháp từ văn bản như tên, địa chỉ, ngày tháng, và quan hệ giữa các thực thể. Việc hiểu cấu trúc ngữ pháp và mối quan hệ phụ thuộc trong câu giúp xác định và trích xuất thông tin cần thiết một cách chính xác.
- Phân tích ý kiến: Trong phân tích ý kiến, Dependency Parsing có thể giúp xác định mối quan hệ phụ thuộc giữa các từ trong câu và phân tích quan điểm, tình cảm, và ý kiến được diễn đạt trong câu. Điều này hỗ trợ việc hiểu cách các từ và cụm từ tương tác trong câu để đưa ra đánh giá và phân loại ý kiến.
- Xử lý ngôn ngữ tự nhiên: Dependency Parsing cung cấp thông tin về cấu trúc ngữ pháp của văn bản, giúp máy hiểu mối quan hệ giữa các từ và cụm từ. Điều này có thể hỗ trợ cho các tác vụ khác như phân giải đồng tham chiếu, tổng hợp văn bản, tạo ngữ liệu huấn luyện cho các mô hình ngôn ngữ khác, và nhiều ứng dụng khác.
Phân giải phụ thuộc này có ý nghĩa thế nào trong việc huấn luyện dữ liệu riêng của myGPT
myGPT là giải pháp huấn luyện dữ liệu dựa trên việc ánh xạ mẫu dữ liệu riêng trên không gian đã được huấn luyện sẵn để tìm ra mẫu và biểu diễn thành không gian số của các đối tượng sau đó lưu trữ lại trên cơ sở dữ liệu vector riêng vì vậy sẽ không áp dụng việc phân tích và phân giải phụ thuộc nhiều cho giai đoạn huấn luyện mà nó sẽ áp dụng trong việc phân tích cú pháp của câu hỏi mà người dùng đưa tới nhằm phân tích câu hỏi, trích xuất thông tin, phân tích các chỉ thị để kiểm soát các yêu cầu trước khi đưa tới thực hiện trên mô hình dữ liệu đã được lưu trữ riêng.
Phân tích và hiểu câu hỏi, yêu cầu cũng như chỉ thị của người dùng từ sẽ giúp cho ứng dụng của myGPT có thể phân biệt được chính xác dữ liệu đầu vào, từ đó sẽ quyết định phân nhánh đến các hành động tiếp theo như hỏi mô hình; truy vấn cơ sở dữ liệu quan hệ; thực hiện các tác vụ chỉ định (các chương trình phần mềm đã được lập trình sẵn) hay chỉ đơn thuần là đưa ra những câu trả lời tương tác với người dùng ngay lập tức mà không cần đưa qua xử lý trên dữ liệu vector nữa.
Tóm lại, phân giải phụ thuộc là một công cụ quan trọng trong xử lý ngôn ngữ tự nhiên và mang lại hiệu quả trong việc được áp dụng nhiều với myGPT trong việc hiểu câu hỏi của người dùng.