

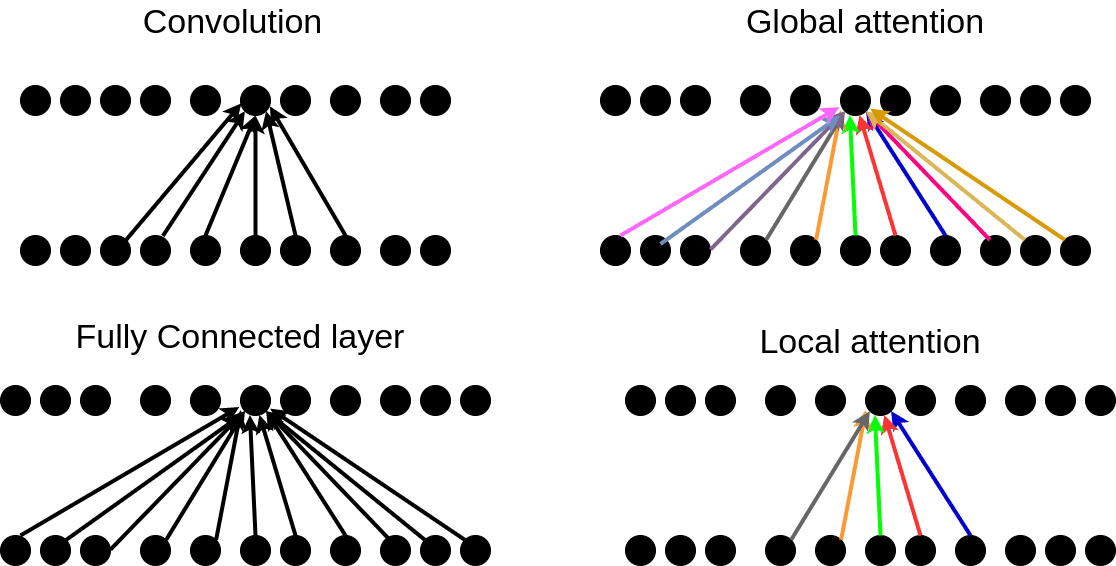
Xác định sự tập trung (Attention Mechanism) là một cơ chế trong học sâu (deep learning) được sử dụng trong các mô hình mạng nơ-ron, để giúp mô hình hoặc người xử lý dữ liệu nhận biết sự tập trung vào các phần quan trọng của đầu vào (input) trong quá trình xử lý dữ liệu. Đây là một trong những phát triển quan trọng của mạng nơ-ron dựa trên cấu trúc RNN (Recurrent Neural Network) và đã được áp dụng rộng rãi trong nhiều ứng dụng liên quan đến xử lý ngôn ngữ tự nhiên, nhận dạng hình ảnh, và nhiều lĩnh vực khác.
Cơ chế Attention giúp mô hình học được cách phân bố trọng số cho các phần quan trọng của đầu vào (input) bằng cách tính toán các trọng số cho mỗi phần của đầu vào, sau đó sử dụng các trọng số này để lấy tổng có trọng số của các phần đầu vào. Điều này cho phép mô hình tập trung vào các phần quan trọng trong đầu vào và loại bỏ các phần không quan trọng, giúp cải thiện hiệu suất của mô hình.
Các ứng dụng của cơ chế Attention trong các tác vụ xử lý ngôn ngữ tự nhiên bao gồm: dịch máy, tóm tắt văn bản, phân loại văn bản, và trả lời câu hỏi, trong khi trong nhận dạng hình ảnh thì nó được sử dụng để giúp mô hình tập trung vào các vùng quan trọng trong hình ảnh.
Một ví dụ về cách thức xác định sự tập trung với bài báo
Giả sử chúng ta có một tập dữ liệu văn bản về bài báo về công nghệ, và mục tiêu là phân loại các bài báo theo chủ đề và trả lời các câu hỏi liên quan đến các bài báo đó. Chúng ta có thể sử dụng một mô hình Attention-based RNN để đạt được mục tiêu này.
Trước khi đưa dữ liệu vào mô hình, chúng ta sẽ chia các bài báo thành các câu và đưa các câu vào mô hình dưới dạng một chuỗi các token. Tiếp theo, chúng ta sẽ sử dụng một mô hình RNN để xử lý các chuỗi đó, tạo ra một vector đại diện cho mỗi câu.
Sau đó, chúng ta sử dụng cơ chế Attention để tập trung vào các câu quan trọng trong bài báo. Cụ thể, chúng ta tính toán một vector trọng số cho mỗi câu bằng cách sử dụng một mạng nơ-ron feedforward đơn giản. Vector trọng số này đại diện cho mức độ quan trọng của mỗi câu đối với việc phân loại bài báo.
Sau khi tính toán các trọng số này, chúng ta sử dụng chúng để tạo ra một vector đại diện cho bài báo bằng cách lấy tổng có trọng số của các vector đại diện của các câu. Vector đại diện này sau đó được đưa vào một mạng nơ-ron fully-connected để phân loại bài báo vào các chủ đề khác nhau.
Khi trả lời các câu hỏi liên quan đến bài báo, chúng ta có thể sử dụng cơ chế Attention để tập trung vào các câu quan trọng trong bài báo đó. Cụ thể, chúng ta tính toán một vector trọng số cho mỗi câu bằng cách sử dụng một mạng nơ-ron feedforward đơn giản. Vector trọng số này đại diện cho mức độ quan trọng của mỗi câu đối với câu hỏi.
Sau khi tính toán các trọng số này, chúng ta sử dụng chúng để tạo ra một vector đại diện cho bài báo bằng cách lấy tổng có trọng số của các vector đại diện của các câu. Vector đại diện này sau đó được đưa vào một mạng nơ-ron fully-connected để dự đoán câu trả lời cho câu hỏi.
Giả sử chúng ta có hai bài báo sau đây:
Bài báo 1: “Công nghệ AI đã thay đổi cách chúng ta sống và làm việc”
Bài báo 2: “Người dùng iPhone đang gặp vấn đề về pin trên iOS 14”
Để phân loại các bài báo này, chúng ta sẽ sử dụng mô hình Attention-based RNN như đã mô tả trong ví dụ trước đó.
Đầu tiên, chúng ta sẽ chia các bài báo thành các câu và đưa các câu vào mô hình dưới dạng một chuỗi các token:
Bài báo 1: [“Công”, “nghệ”, “AI”, “đã”, “thay”, “đổi”, “cách”, “chúng”, “ta”, “sống”, “và”, “làm”, “việc”]
Bài báo 2: [“Người”, “dùng”, “iPhone”, “đang”, “gặp”, “vấn”, “đề”, “về”, “pin”, “trên”, “iOS”, “14”]
Sau đó, chúng ta sử dụng một mô hình RNN để xử lý các chuỗi này, tạo ra một vector đại diện cho mỗi câu. Để đơn giản, ta có thể sử dụng một mạng LSTM cho mô hình RNN này.
Tiếp theo, chúng ta tính toán một vector trọng số cho mỗi câu bằng cách sử dụng một mạng nơ-ron feedforward đơn giản. Ví dụ, ta có thể sử dụng một mạng nơ-ron với một lớp ẩn có 16 đơn vị và kích hoạt hàm ReLU.
Đầu vào cho mạng nơ-ron này là một vector đại diện cho mỗi câu, và đầu ra là một vector trọng số có giá trị từ 0 đến 1 đại diện cho mức độ quan trọng của mỗi câu đối với việc phân loại bài báo. Cụ thể, ta có thể tính toán vector trọng số như sau:
- Đầu tiên, chúng ta sử dụng một mạng nơ-ron feedforward với một lớp ẩn để tính toán một vector ẩn cho mỗi câu. Vector ẩn này sẽ được sử dụng để tính toán vector trọng số.
- Sau đó, chúng ta sử dụng một mạng nơ-ron khác để tính toán một scalar cho mỗi câu dựa trên vector ẩn tương ứng với câu đó. Scalar này sẽ được sử dụng để tính toán vector trọng số.
- Cuối cùng, chúng ta sử dụng hàm softmax để chuẩn hóa scalar tính được từ mạng nơ-ron trên thành một giá trị trong khoảng từ 0 đến 1, đại diện cho mức độ quan trọng của câu đó đối với việc phân loại bài báo.
Sau khi tính toán được vector trọng số cho mỗi câu, chúng ta sử dụng chúng để tính toán trung bình có trọng số của các vector đại diện của các câu. Vector kết quả sẽ được sử dụng để phân loại bài báo và trả lời câu hỏi.
Ví dụ, giả sử mô hình tính toán vector trọng số như sau:
- Vector đại diện cho câu 1: [0.1, 0.2, 0.3, 0.4]
- Vector đại diện cho câu 2: [0.5, 0.6, 0.7, 0.8]
- Vector đại diện cho câu 3: [0.9, 0.8, 0.7, 0.6]
- Vector trọng số cho câu 1: 0.1
- Vector trọng số cho câu 2: 0.3
- Vector trọng số cho câu 3: 0.6
Sau đó, chúng ta tính toán trung bình có trọng số của các vector đại diện của các câu như sau:
- Vector đại diện trung bình có trọng số: 0.1*[0.1, 0.2, 0.3, 0.4] + 0.3*[0.5, 0.6, 0.7, 0.8] + 0.6*[0.9, 0.8, 0.7, 0.6] = [0.72, 0.66, 0.6, 0.54]
Vector kết quả này sẽ được sử dụng để phân loại bài báo và trả lời câu hỏi. Ví dụ, nếu mô hình được huấn luyện để phân loại các bài báo vào hai loại “Công nghệ” và “Tin tức”, thì nó có thể dự đoán rằng bài báo 1 thuộc loại “Công nghệ” và bài báo 2 thuộc loại “Tin tức”.
Kết luận
Xác định sự tập trung trong huấn luyện dữ liệu là cách thức giúp cho mô hình nhận biết được ý nghĩa tổng quát của dữ liệu mà chúng ta huấn luyện từ đó có thể xác định được cách thức tương tác đầu ra từ đó mà người luyện dữ liệu có được hình dung về đối sánh dữ liệu trong quá trình tối ưu của mô hình.
Cơ chế này cũng giúp cho quá trình xử lý dữ liệu đầu vào có thể nhận biết và loại bỏ những dạng dữ liệu không mong muốn khi chúng ta đưa vào nhằm kiểm soát tốt hơn sự tập trung của mô hình giúp ta sớm đạt được kết quả mong muốn.