


Tác giả: Zain Khan
Ngày 9 tháng 6 năm 2023
Các chuyên gia kỹ thuật dữ liệu và phân tích cần ưu tiên việc tạo ra, sắp xếp và chuẩn bị dữ liệu phù hợp để xây dựng các mô hình Trí tuệ Nhân tạo thành công. Nghiên cứu này cung cấp thông tin được sắp xếp về các giải pháp Trí tuệ Nhân tạo dựa trên dữ liệu, tập trung vào việc cải thiện hệ thống dữ liệu một cách có hệ thống để xây dựng các hệ thống Trí tuệ Nhân tạo đáng tin cậy và chính xác.
Tổng quan
Kết Quả Chính
- Trí tuệ Nhân tạo dựa trên dữ liệu đang dần dịch chuyển ra khỏi cách tiếp cận tập trung vào mô hình. Với trí tuệ Nhân tạo dựa trên dữ liệu, kết quả của các giải pháp Trí tuệ Nhân tạo được thúc đẩy hơn bằng cách tăng cường và bổ sung dữ liệu đào tạo, thay vì điều chỉnh mô hình hoặc mã nguồn.
- Thời gian, chi phí và tài nguyên tiêu hao trong việc khám phá dữ liệu thủ công, làm sạch dữ liệu, trích xuất đặc điểm, kiểm tra chất lượng dữ liệu và tự động hóa tiếp tục tăng lên khi phức tạp hóa và sự không tiện dụng của dữ liệu gia tăng. Dữ liệu chất lượng kém dẫn đến các mô hình Học máy không chính xác và lãng phí thời gian, công sức và tài nguyên.
- Các công cụ chuẩn bị dữ liệu hiện đại hỗ trợ sự hiệu quả với các tính năng mạnh mẽ như lịch sử dữ liệu, tự động hóa, trích xuất đặc điểm tự động và tăng cường dữ liệu để giúp chuẩn bị bộ dữ liệu chất lượng cao cho Trí tuệ Nhân tạo.
- Khó khăn trong việc tìm kiếm các công cụ kết hợp tăng cường dữ liệu, chú thích hỗ trợ Trí tuệ Nhân tạo, đánh dấu dữ liệu, tiền xử lý dữ liệu, gia tăng và các tính năng không cần code trong một công cụ duy nhất. Các tính năng khác biệt bao gồm việc theo dõi nguồn gốc dữ liệu, kiểm tra chất lượng tự động, dự đoán tác động biến đổi, khám phá dữ liệu dựa trên thực tế ảo và 3D.
Những đề xuất
Các chuyên gia kỹ thuật dữ liệu và phân tích làm việc trên việc xây dựng hệ thống Trí tuệ Nhân tạo nên:
- Áp dụng một cách tiếp cận Trí tuệ Nhân tạo dựa trên dữ liệu bằng cách sử dụng công cụ và kỹ thuật chuẩn bị dữ liệu gia tăng và tự phục vụ, cũng như công cụ và kỹ thuật tự động hóa việc tạo đặc điểm để giải quyết các thách thức dữ liệu phức tạp.
- Tận dụng các công cụ tăng cường dữ liệu, khám phá dữ liệu trực quan được tăng cường bởi Trí tuệ Nhân tạo và công cụ tăng cường dữ liệu để cải thiện chất lượng bộ dữ liệu.
- Giảm thời gian, chi phí và công sức tiêu hao cho việc gắn nhãn và chú thích dữ liệu thủ công bằng cách tận dụng các kỹ thuật đánh dấu hiện đại và công cụ đánh dấu dữ liệu được tăng cường bởi Trí tuệ Nhân tạo.
- Đánh giá các tác động tài chính và kỹ thuật của việc đầu tư vào các công cụ tự phục vụ so với việc khám phá các tùy chọn mã nguồn mở. Chọn một sự kết hợp phù hợp với nhu cầu của bạn, với sự đa dạng về dữ liệu và kỹ năng.
Giả định về Kế hoạch Chiến lược
Thông qua năm 2024, các nhiệm vụ quản lý dữ liệu thủ công sẽ giảm hơn 50% thông qua việc sử dụng học máy, dẫn đến việc hầu hết các nhiệm vụ này được tự động hóa hoặc tăng cường.
Đến năm 2025, việc sử dụng dữ liệu tổng hợp và học chuyển giao sẽ giảm hơn 50% lượng dữ liệu thật cần cho Trí tuệ Nhân tạo.
Phân tích
Theo khảo sát của Tổ chức AI của Gartner năm 2021, các nhóm Trí tuệ Nhân tạo liên tục tiêu thời gian nhiều hơn để tạo ra, sắp xếp và chuẩn bị dữ liệu hơn là phát triển và thiết kế mô hình (xem Hình 1).
Hình 1: Phân bổ khối lượng công việc nhóm AI phải thực hiện
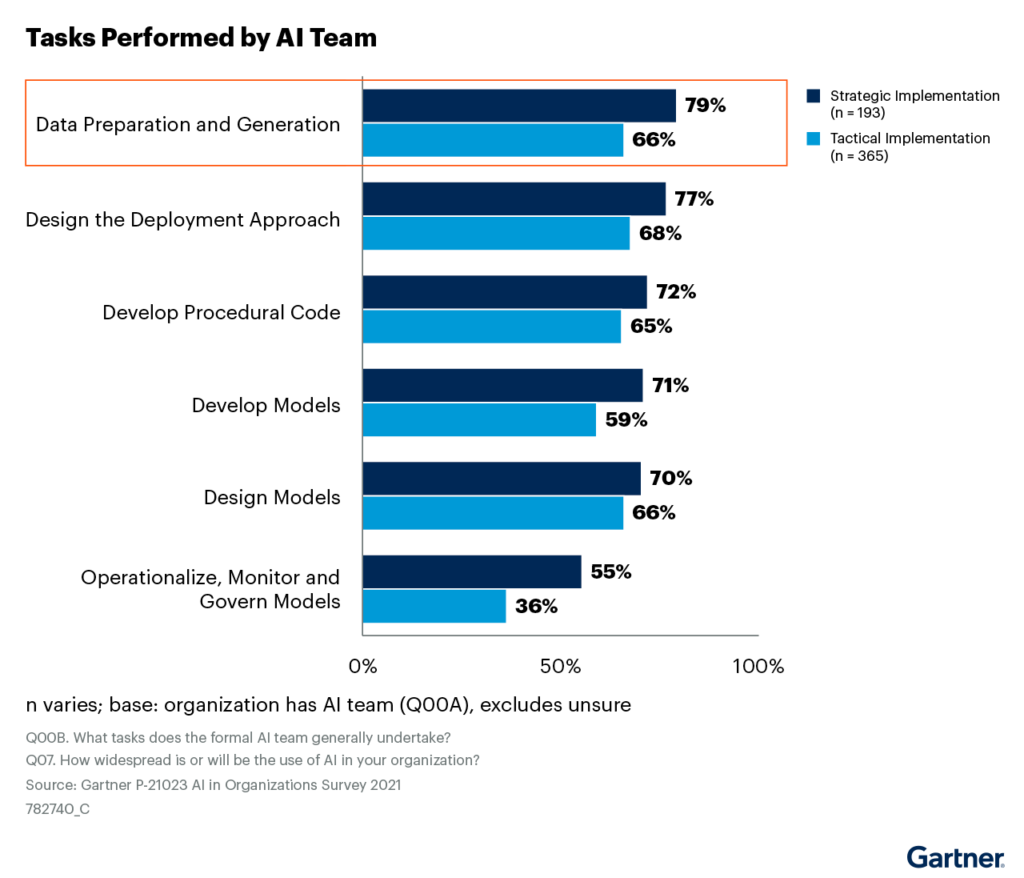
Tuy nhiên, các thách thức về dữ liệu liên quan đến tính tiện lợi, khối lượng, phức tạp và chất lượng tiếp tục làm trở ngại cho việc triển khai Trí tuệ Nhân tạo (xem Hình 2).
Hình 2: Rào cản trong việc Triển khai Trí tuệ Nhân tạo
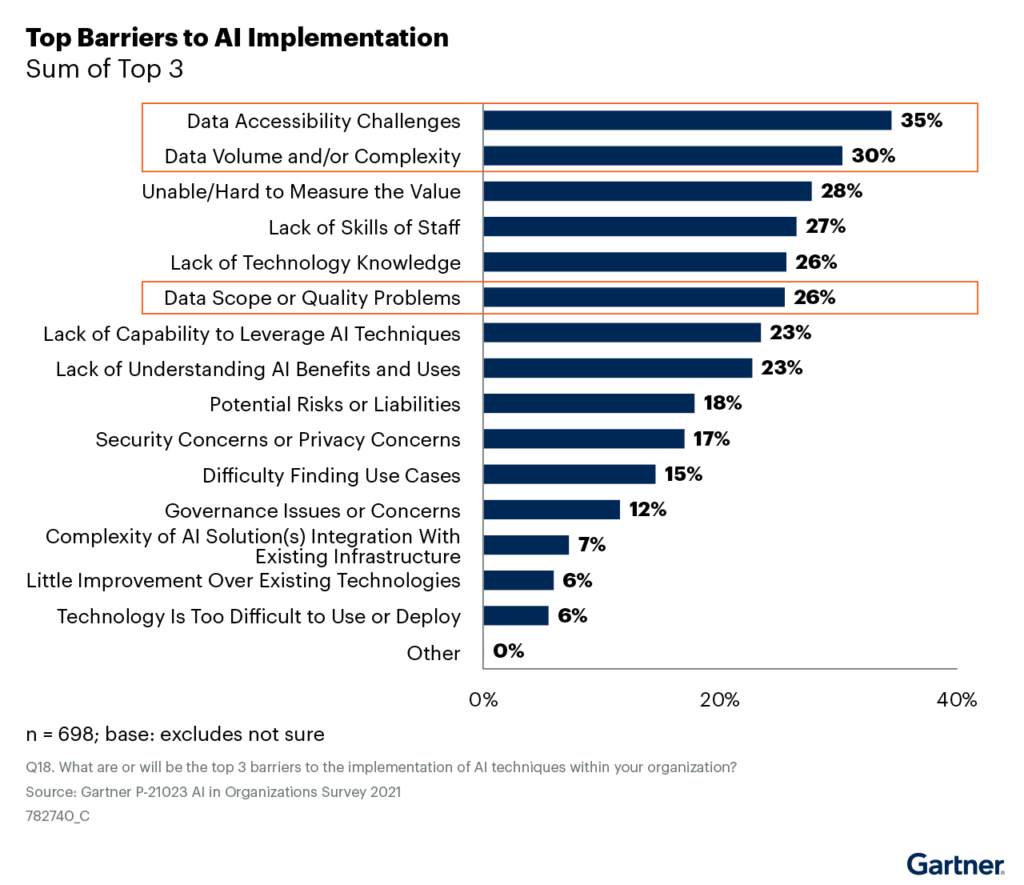
Một câu hỏi bắt đầu nảy sinh: Tại sao các vấn đề liên quan đến dữ liệu vẫn tồn tại mặc cho các nhóm Trí tuệ Nhân tạo dành nhiều thời gian hơn cho việc chuẩn bị dữ liệu?
Thế nào dữ liệu hướng tới Trí tuệ nhân tạo (AI) và tại sao điều đó là cần thiết?
Trí tuệ Nhân tạo dựa trên dữ liệu (Data-centric AI) tập trung vào việc xây dựng hệ thống Trí tuệ Nhân tạo tốt hơn thông qua việc cơ bản hoá dữ liệu và đại diện cho sự chuyển đổi từ một cách tiếp cận tập trung vào mô hình và mã nguồn sang một cách tiếp cận tập trung vào dữ liệu hơn. Phát triển Trí tuệ Nhân tạo truyền thống đã tập trung vào việc tinh chỉnh và điều chỉnh các thuật toán hoặc cải thiện mã nguồn được sử dụng để phát triển mô hình Trí tuệ Nhân tạo, nhưng tiếp cận Trí tuệ Nhân tạo dựa trên dữ liệu giữ mô hình và mã nguồn không đổi trong khi liên tục cải thiện dữ liệu.
Dữ liệu kém chất lượng đang gây thiệt hại khoảng 3 nghìn tỷ đô la Mỹ mỗi năm, và vấn đề về chất lượng dữ liệu phổ biến trong mọi ngành. Khi các bộ dữ liệu trở nên lớn hơn và phức tạp hơn, việc đảm bảo chất lượng của chúng trở nên khó khăn mà không sử dụng các kỹ thuật và công cụ từ cả không gian quản lý dữ liệu và phân tích nâng cao. Sự xuất hiện gần đây của các công cụ Trí tuệ Nhân tạo sinh ra như ChatGPT đòi hỏi lượng lớn lao động con người để tạo ra dữ liệu đào tạo chất lượng cao, và việc sử dụng con người không phải lúc nào cũng khả thi – như trong trường hợp công nhân Kenya bị tiếp xúc với nội dung tầm thường khi làm việc để loại bỏ tính độc hại từ dữ liệu đào tạo. Khi các trường hợp sử dụng phân tích và Trí tuệ Nhân tạo tiếp tục phát triển, các phương pháp tự động hóa, công cụ mới hơn và các phương pháp kỹ thuật hóa cơ bản cần phải được xem xét lại và củng cố để đảm bảo lợi ích tối đa từ quá trình phát triển Trí tuệ Nhân tạo.
Trí tuệ Nhân tạo dựa trên dữ liệu (Data-centric AI) tập trung vào việc cơ bản hóa dữ liệu một cách có hệ thống để xây dựng hệ thống Trí tuệ Nhân tạo tốt hơn, và đại diện cho sự chuyển đổi từ một cách tiếp cận tập trung vào mô hình và mã nguồn sang một cách tiếp cận tập trung vào dữ liệu hơn.
Hình 3 thể hiện các thành phần khác nhau của Trí tuệ Nhân tạo dựa trên dữ liệu:
- Chuẩn bị dữ liệu và kỹ thuật chế biến đặc điểm (Data Preparation and Feature Engineering)
- Gắn nhãn và chú thích dữ liệu (Data Labeling and Annotation)
- Dữ liệu tổng hợp (Synthetic Data)
- Tăng cường dữ liệu (Data Enrichment)
Hình 3: Các giải pháp Trí tuệ Nhân tạo dựa trên dữ liệu
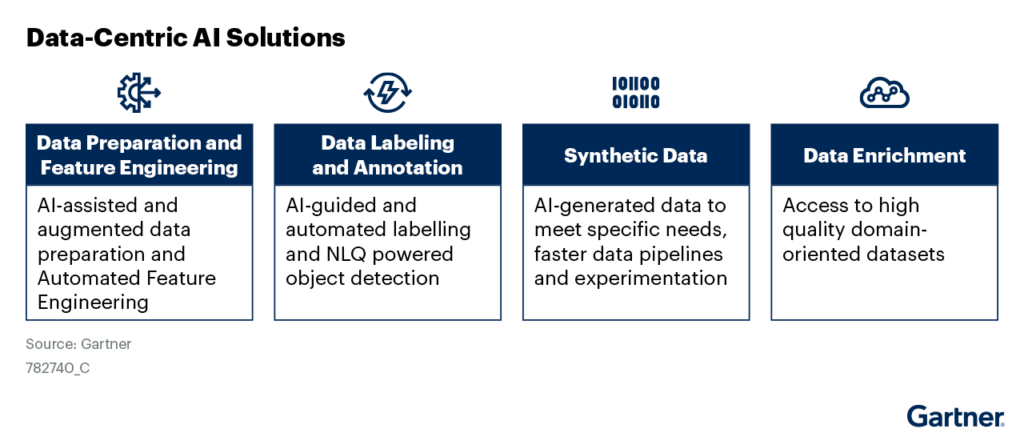
Nghiên cứu này sẽ khám phá từng giải pháp này và làm sáng tỏ về các tính năng của chúng và cách chúng có thể thêm động lực và giúp chuẩn bị dữ liệu chất lượng cao hơn, cũng như giúp thúc đẩy quá trình phát triển Trí tuệ Nhân tạo đa dạng hóa.
Chuẩn bị & Kỹ thuật xử lý dữ liệu
Chuẩn bị dữ liệu tập trung chủ yếu vào phân tích dữ liệu thám hiểm (EDA), làm sạch và biến đổi dữ liệu để chuẩn bị các bộ dữ liệu có cấu trúc chất lượng cao để trích xuất và chế biến đặc điểm. Cả hai nhiệm vụ này liên quan mật thiết với nhau, nhưng việc tiền xử lý dữ liệu thường được thực hiện trước khi thực hiện kỹ thuật chế biến đặc điểm. Bảng 1 mô tả các bước chuẩn bị dữ liệu.

Phân tích và khai phá dữ liệu
Mô tả và Các Kỹ thuật
- Nên được thực hiện để khám phá hình dạng chung của bộ dữ liệu, hiểu về chất lượng liên quan đến trùng lặp, giá trị bị thiếu, mục nhập không mong muốn và điều tra về các đặc điểm, cũng như cách chúng có thể liên quan đến nhau.
- Các ví dụ bao gồm các phương pháp phi đồ thị một biến, đa biến phi đồ thị, một biến đồ thị và đa biến đồ thị. Các phương pháp phi đồ thị liên quan đến việc tính toán các thống kê tóm tắt và các phương pháp đồ thị liên quan đến biểu đồ. Các phương pháp một biến liên quan đến một biến, trong khi phương pháp đa biến liên quan đến nhiều biến.
Ví dụ và Các Trường Hợp Sử Dụng
- Các phương pháp phi đồ thị bao gồm giá trị trung bình, trung vị, mode, phương sai, độ lệch và độ nhọn.
- Các phương pháp đồ thị bao gồm biểu đồ cột, biểu đồ phân tán, biểu đồ nhiệt độ, biểu đồ bong bóng và biểu đồ chạy.
- Kết hợp giữa các biểu đồ có thể dẫn đến kết quả tốt (ví dụ, biểu đồ boxplot cạnh nhau là phương pháp đồ thị tốt nhất để xem xét mối quan hệ giữa biến hạng mục và biến định lượng). Biểu đồ phân tán có thể được đặt lên biểu đồ boxplot để cung cấp thông tin bổ sung về sự khác biệt hoặc tương đồng về phân phối.
Tiền xử lý dữ liệu

Mô tả và Kỹ thuật:
- Tiền xử lý dữ liệu bao gồm việc làm sạch, định hình, xử lý các giá trị bị thiếu và cải thiện chất lượng dữ liệu trước khi trích xuất đặc điểm.
- Các phân tích đa biến, dưới dạng các phương pháp dựa trên k-nearest neighbor và hồi quy, chẳng hạn như hồi quy tuyến tính đa biến (MLR), máy hỗ trợ vector (SVM), cây quyết định và mạng thần kinh nhân tạo (ANN) có thể được sử dụng để xử lý các giá trị bị thiếu. Các kỹ thuật phân cụm và phát hiện ngoại lệ sử dụng các thuật toán, chẳng hạn như CLARANS, DBSCAN và LOF có thể được sử dụng để xác định dữ liệu bất thường.
Ví dụ và Các Trường Hợp Sử Dụng:
- Phân tích một biến nên được sử dụng khi tỷ lệ dữ liệu bị thiếu nhỏ (từ 1-5%) và thông thường không được khuyến nghị cho dữ liệu chuỗi thời gian. Phân tích đa biến cho kết quả tốt hơn cho tỷ lệ dữ liệu bị thiếu lớn hơn (~15%) và nên được sử dụng để xử lý giá trị bị thiếu trong khoảng thời gian dài hơn.
- Các phương pháp dựa trên phân cụm có thể được sử dụng như các bước sơ bộ để xác định các cụm dữ liệu, sau đó các phương pháp thống kê có thể được áp dụng để xác định ngoại lệ. Tuy nhiên, các phương pháp phân cụm cho các bộ dữ liệu lớn có thể mất nhiều thời gian tính toán.
Tiền xử lý dữ liệu có thể được thực hiện thủ công hoặc thông qua các công cụ chuẩn bị dữ liệu. Các phương pháp thủ công bao gồm việc sử dụng các ngôn ngữ lập trình mã nguồn mở như Python dưới dạng notebook, và các môi trường phát triển tích hợp như PyCharm và Visual Studio Code để phát triển. Mặc dù các thư viện phổ biến như pandas, matplotlib và seaborn khá nổi tiếng, Bảng 2 cung cấp một số ví dụ về các thư viện mới mạnh mẽ và các thư viện khác nổi tiếng khác có thể giúp tăng tốc và đơn giản hóa quá trình chuẩn bị dữ liệu.