

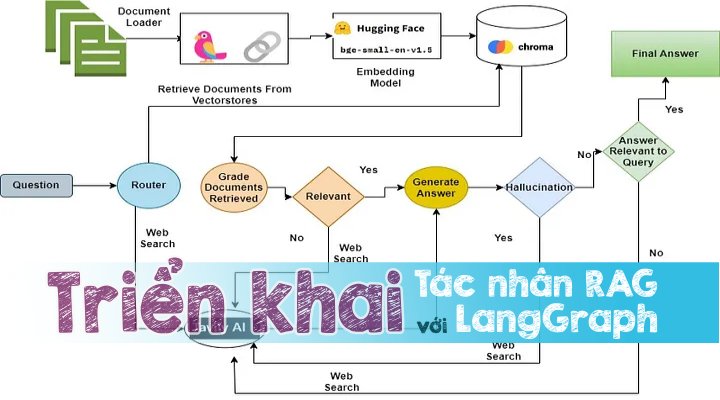
Trong bài viết này, chúng tôi sẽ mô phỏng cách thức để triển khai một ứng dụng RAG Agent tin cậy hơn bằng cách sử dụng kết hợp giữa LangGraph, Groq-Llama-3 và Chroma cùng các khái niệm về RAG dưới đây:
- Adaptive RAG. Được triển khai để xây dựng Bộ định tuyến nhằm điều hướng các câu hỏi theo các phương pháp truy xuất khác nhau.
- Corrective RAG. Được triển khai để tạo nên cơ chế dự phòng nhằm xử lý khi ngữ cảnh được truy xuất không liên quan đến câu hỏi được hỏi.
- Self-RAG. Được triển khai khái niệm với mục đích chấm điểm ảo giác tức là kiểm tra các câu trả lời gây ảo giác hoặc không liên quan đến câu hỏi.
Tác nhân là gì?
Khái niệm cơ bản ở đây liên quan đến việc sử dụng mô hình ngôn ngữ để ra quyết định cho việc thực hiện một một chuỗi hành động nào đó. Các hành động theo chuỗi thường được fix cứng trong mã nguồn hoặc các tệp định nghĩa nào đó thì ngược lại, các tác nhân sẽ sử dụng mô hình ngôn ngữ làm công cụ suy luận để quyết định các hành động cần thực hiện và thứ tự logic của chúng mà không cần tuân thủ theo các chuỗi đó.
Nó bao gồm 3 thành phần:
- lập kế hoạch: chia nhiệm vụ thành các mục tiêu nhỏ hơn
- bộ nhớ: ngắn hạn (lịch sử trò chuyện) / dài hạn (vectorstore)
- Sử dụng công cụ: Nó có thể sử dụng các công cụ khác nhau để mở rộng khả năng của mình.
Các tác nhân có thể triển khai bằng cách sử dụng eAct trong Langchain hoặc LangGraph,
Sự cân bằng giữa các Tác nhân Langchain và LangGraph:
Độ tin cậy
- ReAct / Langchain Agent: Ít đáng tin cậy hơn vì LLM phải đưa ra quyết định chính xác ở mỗi bước
- LangGraph: Đáng tin cậy hơn khi luồng điều khiển được thiết lập và LLM có công việc cụ thể để thực hiện tại mỗi nút
Tính khả chuyển
- ReAct /Langchain Agent: Linh hoạt hơn vì LLM có thể chọn bất kỳ chuỗi hành động nào
- LangGraph: Kém linh hoạt hơn vì các hành động bị hạn chế bằng cách thiết lập luồng điều khiển tại mỗi nút
Khả năng tương thích với các LLM nhỏ hơn
- ReAct /Langchain Agent: Khả năng tương thích kém hơn
- LangGraph: Khả năng tương thích tốt hơn
Trong bài viết này chúng tôi đã sử dụng LangGraph để tạo Tác nhân.
🦜️🔗 Langchain là gì?
LangChain là một frameword để phát triển các ứng dụng được hỗ trợ bởi các mô hình ngôn ngữ. Nó cho phép các ứng dụng:
- Nhận biết ngữ cảnh: kết nối mô hình ngôn ngữ với các nguồn ngữ cảnh (chỉ thị qua prompt, các ví dụ few shot, ngữ cảnh, v.v.)
- Hiểu Lý do: dựa vào mô hình ngôn ngữ để suy luận ra lý do (câu trả lời có dựa trên ngữ cảnh hay không, hành động gì cần thực hiện, v.v.)
LangGraph là gì?
LangGraph là một thư viện mở rộng của LangChain, nó cung cấp khả năng tính toán theo chu kỳ cho các ứng dụng LLM. Trong khi LangChain hỗ trợ xác định chuỗi tính toán (Đồ thị tuần hoàn có hướng hoặc DAG), LangGraph cho phép kết hợp các chu trình. Điều này cho phép thực hiện các hành vi phức tạp hơn, giống như tác nhân, trong đó LLM có thể được gọi trong một vòng lặp để xác định hành động tiếp theo cần thực hiện.
Khái niệm chính
- Biểu đồ trạng thái: LangGraph xoay quanh khái niệm biểu đồ trạng thái, trong đó mỗi nút trong biểu đồ biểu thị một bước trong quá trình tính toán của chúng ta và biểu đồ duy trì trạng thái được truyền xung quanh và cập nhật khi quá trình tính toán diễn ra.
- Nút: Nút là các khối xây dựng nên LangGraph của bạn. Mỗi nút đại diện cho một hàm hoặc một bước tính toán. Chúng tôi xác định các nút để thực hiện các tác vụ cụ thể, chẳng hạn như xử lý đầu vào, đưa ra quyết định hoặc tương tác với các API bên ngoài.
- Các cạnh: Các cạnh kết nối các nút trong biểu đồ của bạn, xác định luồng tính toán. LangGraph hỗ trợ các cạnh có điều kiện, cho phép bạn tự động xác định nút tiếp theo sẽ thực thi dựa trên trạng thái hiện tại của biểu đồ.
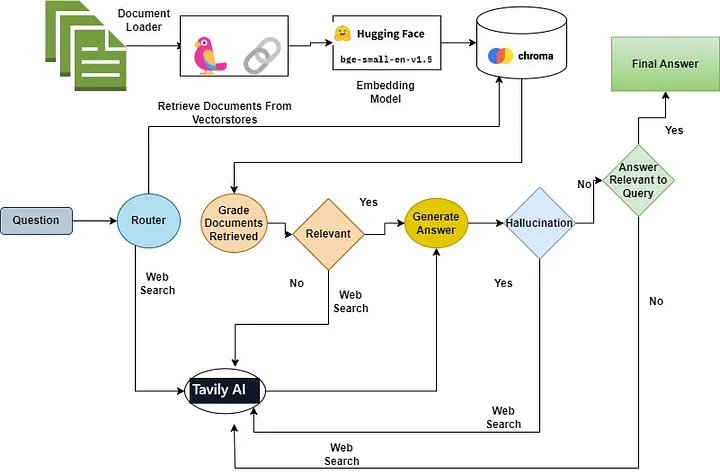
Các bước liên quan đến việc tạo biểu đồ bằng LangGraph:
- Xác định trạng thái biểu đồ: Điều này thể hiện trạng thái của biểu đồ.
- Tạo biểu đồ.
- Xác định Nút: Ở đây chúng tôi xác định các chức năng khác nhau được liên kết với từng trạng thái quy trình làm việc.
- Thêm các nút vào Biểu đồ: Ở đây, thêm các nút của chúng ta vào biểu đồ và xác định luồng bằng cách sử dụng các cạnh và các cạnh có điều kiện.
- Đặt điểm đầu vào và điểm cuối của biểu đồ.
API tìm kiếm Tavily là gì?
Tavily Search API là một công cụ tìm kiếm được tối ưu hóa cho LLM, nhằm mang lại kết quả tìm kiếm hiệu quả, nhanh chóng và liên tục. Không giống như các API tìm kiếm khác như Serp hay Google, Tavily tập trung vào việc tối ưu hóa tìm kiếm cho các nhà phát triển AI và các tác nhân AI tự trị.
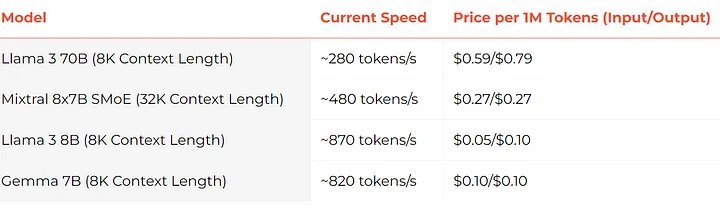
Groq là gì?
Groq cung cấp các mô hình AI và quyền truy cập API hiệu suất cao cho các nhà phát triển với khả năng suy luận nhanh hơn và với chi phí thấp hơn so với đối thủ cạnh tranh.
Các mô hình được hỗ trợ
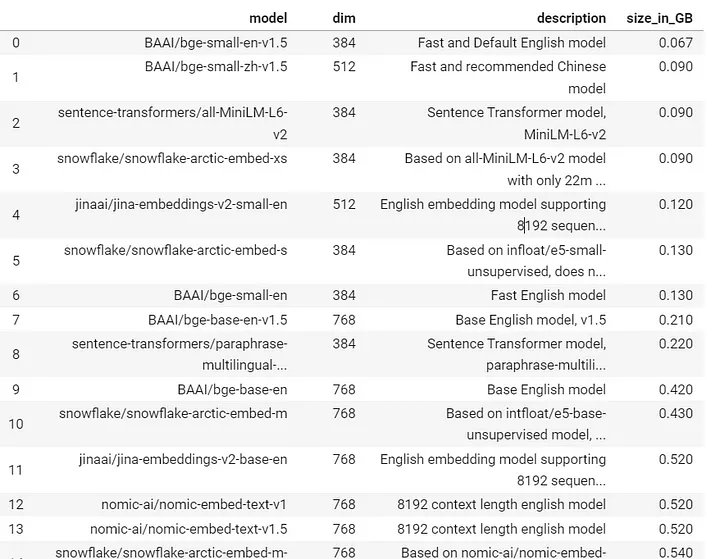
FastEmbed là gì?
FastEmbed là một thư viện Python nhẹ, nhanh, được xây dựng để tạo ra các vector nhúng.
Các mô hình nhúng được hỗ trợ
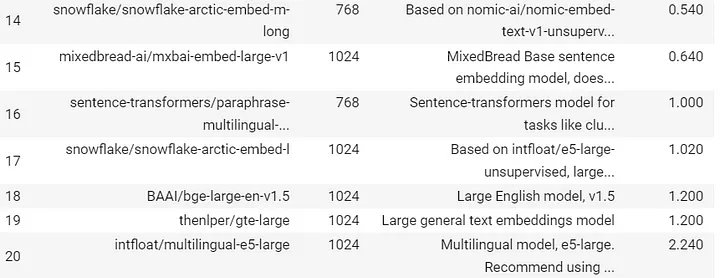
Quy trình làm việc của Tác nhân RAG
- Dựa trên câu hỏi, Bộ định tuyến sẽ quyết định chuyển hướng câu hỏi để truy xuất ngữ cảnh từ vectorstore hay thực hiện tìm kiếm trên web.
- Nếu Bộ định tuyến quyết định hướng câu hỏi ha để truy xuất từ vectorstore, thì các tài liệu phù hợp sẽ được truy xuất từ vectorstore, nếu không thì thực hiện tìm kiếm trên web bằng cách sử dụng tìm kiếm tavily-api
- Sau đó, người chấm điểm tài liệu sẽ chấm điểm các tài liệu là phù hợp hoặc không liên quan.
- Nếu bối cảnh được truy xuất được phân loại là có liên quan thì hãy kiểm tra ảo giác bằng cách sử dụng trình chấm điểm ảo giác. Nếu người chấm điểm quyết định câu trả lời không có ảo giác thì hãy đưa ra câu trả lời cho người dùng.
- Trong trường hợp ngữ cảnh được xếp loại là không liên quan thì hãy thực hiện tìm kiếm trên web để truy xuất nội dung.
- Sau khi truy xuất, trình chấm tài liệu sẽ chấm điểm nội dung được tạo từ tìm kiếm trên web. Nếu thấy phù hợp, phản hồi sẽ được tổng hợp bằng cách sử dụng LLM và sau đó được trình bày
Công nghệ được sử dụng
- Mô hình nhúng: BAAI/bge-base-en-v1.5
- LLM: Llam-3–8B
- Vectorstore: Chroma
- Đồ thị /Tác nhân: LangGraph
Triển khai mã
Cài đặt các thư viện cần thiết!
! pip install -U langchain-nomic langchain_community tiktoken langchainhub chromadb langchain langgraph tavily-python gpt4all fastembed langchain-groq Nhập thư viện cần thiết
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.fastembed import FastEmbedEmbeddingsKhởi tạo mô hình nhúng
embed_model = FastEmbedEmbeddings(model_name= "BAAI/bge-base-en-v1.5" )Khởi tạo LLM
from groq import Groq
from langchain_groq import ChatGroq
from google.colab import userdata
llm = ChatGroq(temperature=0,
model_name="Llama3-8b-8192",
api_key=userdata.get("GROQ_API_KEY"),)
Tải dữ liệu xuống
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/" ,
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/" ,
"https://lilianweng.github.io/posts/2023-10-25-adv-Attack-llm/" ,
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
print(f"len of documents :{len(docs_list)}")
Chia nhỏ Tài liệu để đồng bộ hóa với cửa sổ ngữ cảnh của LLM
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
print(f"length of document chunks generated :{len(doc_splits)}")Tải tài liệu vào vectorstore
vectorstore = Chroma.from_documents(documents=doc_splits,
embedding=embed_model,
collection_name="local-rag")Khởi tạo trình thu hồi
retriever = vectorstore.as_retriever(search_kwargs={"k":2})Triển khai bộ định tuyến
import time
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.output_parsers import StrOutputParser
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are an expert at routing a
user question to a vectorstore or web search. Use the vectorstore for questions on LLM agents,
prompt engineering, and adversarial attacks. You do not need to be stringent with the keywords
in the question related to these topics. Otherwise, use web-search. Give a binary choice 'web_search'
or 'vectorstore' based on the question. Return the a JSON with a single key 'datasource' and
no premable or explaination. Question to route: {question} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question"],
)
start = time.time()
question_router = prompt | llm | JsonOutputParser()
#
question = "llm agent memory"
print(question_router.invoke({"question": question}))
end = time.time()
print(f"The time required to generate response by Router Chain in seconds:{end - start}")
#############################RESPONSE ###############################
{'datasource': 'vectorstore'}
The time required to generate response by Router Chain in seconds:0.34175705909729004Triển khai Chuỗi
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise <|eot_id|><|start_header_id|>user<|end_header_id|>
Question: {question}
Context: {context}
Answer: <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question", "document"],
)
# Xử lý hậu kỳ
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
start = time.time()
rag_chain = prompt | llm | StrOutputParser()
#############################RESPONSE##############################
The time required to generate response by the generation chain in seconds:1.0384225845336914
The agent memory in the context of LLM-powered autonomous agents refers to the ability of the agent to learn from its past experiences and adapt to new situations.Triển khai Trình chấm điểm truy xuất
#
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing relevance
of a retrieved document to a user question. If the document contains keywords related to the user question,
grade it as relevant. It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no premable or explaination.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n <|eot_id|><|start_header_id|>assistant<|end_header_id|>
""",
input_variables=["question", "document"],
)
start = time.time()
retrieval_grader = prompt | llm | JsonOutputParser()
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))
end = time.time()
print(f"The time required to generate response by the retrieval grader in seconds:{end - start}")
############################RESPONSE ###############################
{'score': 'yes'}
The time required to generate response by the retrieval grader in seconds:0.8115921020507812Thực hiện máy chấm điểm ảo giác
# Prompt
prompt = PromptTemplate(
template=""" <|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing whether
an answer is grounded in / supported by a set of facts. Give a binary 'yes' or 'no' score to indicate
whether the answer is grounded in / supported by a set of facts. Provide the binary score as a JSON with a
single key 'score' and no preamble or explanation. <|eot_id|><|start_header_id|>user<|end_header_id|>
Here are the facts:
\n ------- \n
{documents}
\n ------- \n
Here is the answer: {generation} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "documents"],
)
start = time.time()
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader_response = hallucination_grader.invoke({"documents": docs, "generation": generation})
end = time.time()
print(f"The time required to generate response by the generation chain in seconds:{end - start}")
print(hallucination_grader_response)
####################################RESPONSE#################################
The time required to generate response by the generation chain in seconds:1.020448923110962
{'score': 'yes'}Thực hiện Trình chấm điểm câu trả lời
# Prompt
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing whether an
answer is useful to resolve a question. Give a binary score 'yes' or 'no' to indicate whether the answer is
useful to resolve a question. Provide the binary score as a JSON with a single key 'score' and no preamble or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|> Here is the answer:
\n ------- \n
{generation}
\n ------- \n
Here is the question: {question} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "question"],
)
start = time.time()
answer_grader = prompt | llm | JsonOutputParser()
answer_grader_response = answer_grader.invoke({"question": question,"generation": generation})
end = time.time()
print(f"The time required to generate response by the answer grader in seconds:{end - start}")
print(answer_grader_response)
##############################RESPONSE###############################
The time required to generate response by the answer grader in seconds:0.2455885410308838
{'score': 'yes'}Triển khai công cụ Tìm kiếm trên Web
import os
from langchain_community.tools.tavily_search import TavilySearchResults
os.environ['TAVILY_API_KEY'] = "YOUR API KEY"
web_search_tool = TavilySearchResults(k=3)Xác định trạng thái biểu đồ: biểu thị trạng thái của biểu đồ.
Xác định các thuộc tính sau:
- question
- generation: LLM
- web_search : có thêm tìm kiếm hay không
- documents: danh sách tài liệu
from typing_extensions import TypedDict
from typing import List
### State
class GraphState(TypedDict):
question : str
generation : str
web_search : str
documents : List[str]
Xác định các nút
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents from vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
#
def generate(state):
"""
Generate answer using RAG on retrieved documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
#
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question
If any document is not relevant, we will set a flag to run web search
Args:
state (dict): The current graph state
Returns:
state (dict): Filtered out irrelevant documents and updated web_search state
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke({"question": question, "document": d.page_content})
grade = score['score']
# Document relevant
if grade.lower() == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
# Document not relevant
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
# We do not include the document in filtered_docs
# We set a flag to indicate that we want to run web search
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
#
def web_search(state):
"""
Web search based based on the question
Args:
state (dict): The current graph state
Returns:
state (dict): Appended web results to documents
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
if documents is not None:
documents.append(web_results)
else:
documents = [web_results]
return {"documents": documents, "question": question}
#Xác định các cạnh có điều kiện
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
print(question)
source = question_router.invoke({"question": question})
print(source)
print(source['datasource'])
if source['datasource'] == 'web_search':
print("---ROUTE QUESTION TO WEB SEARCH---")
return "websearch"
elif source['datasource'] == 'vectorstore':
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"def decide_to_generate(state):
"""
Determines whether to generate an answer, or add web search
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
question = state["question"]
web_search = state["web_search"]
filtered_documents = state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---")
return "websearch"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
grade = score['score']
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question,"generation": generation})
grade = score['score']
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Thêm nút
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("websearch", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generataeThiết lập điểm đầu, cuối
workflow.set_conditional_entry_point(
route_question,
{
"websearch": "websearch",
"vectorstore": "retrieve",
},
)
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"websearch": "websearch",
"generate": "generate",
},
)
workflow.add_edge("websearch", "generate")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "websearch",
},
)Biên dịch workflow
app = workflow.compile()Kiểm tra quy workflow
from pprint import pprint
inputs = {"question": "What is prompt engineering?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
########################RESPONSE##############################
---ROUTE QUESTION---
What is prompt engineering?
{'datasource': 'vectorstore'}
vectorstore
---ROUTE QUESTION TO RAG---
---RETRIEVE---
'Finished running: retrieve:'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
'Finished running: grade_documents:'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('Prompt engineering refers to methods for communicating with large language '
'models to steer their behavior for desired outcomes without updating the '
'model weights. It is an empirical science that requires heavy '
'experimentation and heuristics.')Kiểm tra quy trình làm việc bằng một câu hỏi khác
ứng dụng = quy trình làm việc. biên dịch ()
app = workflow.compile()
# Test
from pprint import pprint
inputs = {"question": "Who are the Bears expected to draft first in the NFL draft?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
#############################RESPONSE##############################
---ROUTE QUESTION---
Who are the Bears expected to draft first in the NFL draft?
{'datasource': 'web_search'}
web_search
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
'Finished running: websearch:'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('According to the provided context, the Chicago Bears are expected to take '
'USC quarterback Caleb Williams with the first overall pick in the NFL draft.')Tiếp tục kiểm tra quy trình làm việc
app = workflow.compile()
#
inputs = {"question": "What are the types of agent memory?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
###########################RESPONSE############################
---ROUTE QUESTION---
What are the types of agent memory?
{'datasource': 'vectorstore'}
vectorstore
---ROUTE QUESTION TO RAG---
---RETRIEVE---
'Finished running: retrieve:'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---
'Finished running: grade_documents:'
---WEB SEARCH---
'Finished running: websearch:'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('The text mentions the following types of agent memory:\n'
'\n'
'1. Short-Term Memory (STM) or Working Memory: It stores information that the '
'agent is currently aware of and needed to carry out complex cognitive '
'tasks.\n'
'2. Long-Term Memory (LTM): It can store information for a remarkably long '
'time, ranging from a few days to decades, with an essentially unlimited '
'storage capacity.')Trực quan hóa Tác nhân/Đồ thị
!apt-get install python3-dev graphviz libgraphviz-dev pkg-config
!pip install pygraphvizfrom IPython.display import Image
Image(app.get_graph().draw_png())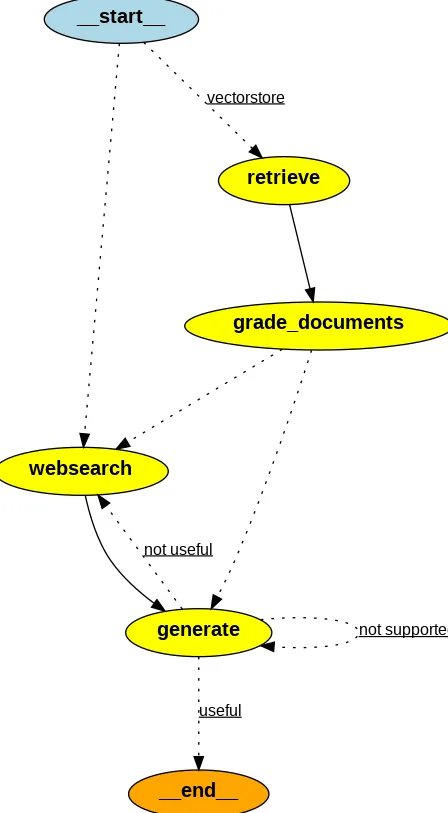
Kết luận
LangGraph là một công cụ linh hoạt được thiết kế để xây dựng các ứng dụng phức tạp, có trạng thái bằng cách sử dụng LLM. Người mới bắt đầu có thể khai thác khả năng của nó cho các dự án của mình bằng cách nắm bắt các nguyên tắc cơ bản của nó và tham gia vào các ví dụ cơ bản. Điều quan trọng là phải tập trung vào việc quản lý các trạng thái, xử lý các cạnh có điều kiện và đảm bảo không có nút cụt nào trong biểu đồ.
Theo ý kiến của chúng tôi, nó có lợi hơn khi so sánh với các tác nhân ReAct vì ở đây chúng ta có thể bố trí quyền kiểm soát hoàn toàn đối với quy trình làm việc thay vì tác nhân đưa ra quyết định.