

Các mô hình ngôn ngữ lớn có tiềm năng khổng lồ, nhưng cũng có nhược điểm lớn. Knowledge graphs (biểu đồ tri thức) giúp làm cho các mô hình ngôn ngữ lớn trở nên chính xác hơn, minh bạch hơn và dễ hiểu hơn.
Sự phấn khích và lo lắng ban đầu xoay quanh ChatGPT đang giảm dần. Vấn đề là, điều đó đưa doanh nghiệp ở đâu? Liệu đây có phải là một xu hướng tạm thời mà có thể bỏ qua một cách an toàn hay là một công cụ mạnh mẽ cần phải đón nhận? Và nếu là trường hợp sau, thì phương pháp an toàn nhất để áp dụng nó là gì?
ChatGPT, một dạng của trí tuệ nhân tạo sinh sáng, chỉ là một biểu hiện đơn lẻ của khái niệm tổng quan về các mô hình ngôn ngữ lớn (LLMs). LLMs là một công nghệ quan trọng và được cho là ổn định, nhưng chúng không phải là giải pháp cắm và chạy cho các quy trình kinh doanh của bạn. Để đạt được lợi ích từ chúng, bạn cần phải làm một số công việc.
Điều này bởi vì, mặc dù có tiềm năng khổng lồ, các LLMs đến với một loạt thách thức. Những thách thức này bao gồm vấn đề như hiện tượng mây mịt, chi phí cao liên quan đến việc đào tạo và mở rộng, sự phức tạp trong việc giải quyết và cập nhật chúng, tính không nhất quán bẩm sinh, khó khăn trong việc kiểm tra và cung cấp giải thích, và sự ưu ái cho nội dung bằng tiếng Anh.
Cũng có các yếu tố khác như việc LLMs kém trong việc suy luận và cần sự hướng dẫn cẩn thận để có câu trả lời đúng. Tất cả những vấn đề này có thể được giảm thiểu bằng cách hỗ trợ LLM nội bộ dựa trên nguồn dữ liệu của bạn bằng một knowledge graph (biểu đồ tri thức).
Sức mạnh của knowledge graphs (biểu đồ tri thức)

Knowledge graph (biểu đồ tri thức) là một cấu trúc đầy thông tin cung cấp một cái nhìn về các thực thể và cách chúng tương tác với nhau. Ví dụ, Rishi Sunak là người nắm giữ vị trí thủ tướng của Vương quốc Anh. Rishi Sunak và Vương quốc Anh là các thực thể, và việc nắm giữ vị trí thủ tướng là cách họ tương quan với nhau. Chúng ta có thể biểu diễn những danh tính và mối quan hệ này dưới dạng một mạng lưới các sự kiện có thể khẳng định với một biểu đồ về những gì chúng ta biết.
Sau khi xây dựng một knowledge graph, bạn không chỉ có thể truy vấn nó để tìm các mẫu, như “Ai là các thành viên trong nội các của Rishi Sunak,” mà bạn cũng có thể tính toán trên biểu đồ bằng cách sử dụng thuật toán và khoa học dữ liệu biểu đồ. Với công cụ bổ sung này, bạn có thể đặt ra các câu hỏi phức tạp về bản chất của toàn bộ biểu đồ có hàng tỷ phần tử, không chỉ một phần con. Bây giờ bạn có thể đặt câu hỏi như “Ai là các thành viên của chính phủ Sunak không thuộc nội các nhưng có ảnh hưởng mạnh mẽ nhất?”
Việc biểu diễn những mối quan hệ này dưới dạng một biểu đồ có thể khám phá ra các sự thật trước đây bị che khuất và dẫn đến những thông tin quý báu. Bạn thậm chí có thể tạo ra các embeddings từ biểu đồ này (bao gồm cả dữ liệu và cấu trúc của nó) có thể được sử dụng trong các luồng máy học hoặc là một điểm tích hợp với các mô hình ngôn ngữ lớn.
Sử dụng knowledge graphs với các mô hình ngôn ngữ lớn
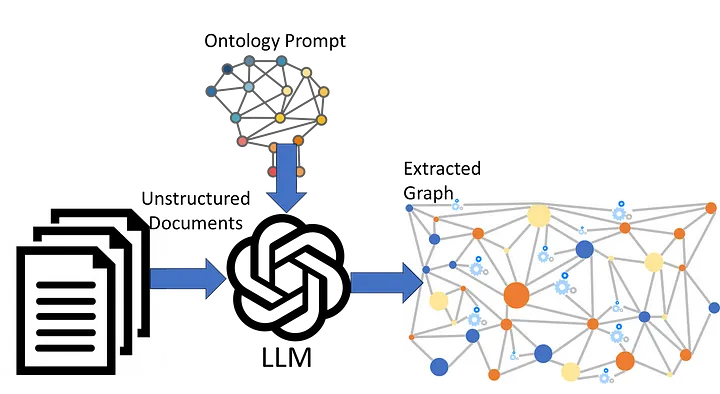
Tuy nhiên, một knowledge graph chỉ là một nửa của câu chuyện. Các LLMs là nửa còn lại, và chúng ta cần hiểu cách kết hợp chúng làm việc cùng nhau. Chúng tôi thấy xuất hiện bốn mẫu cơ bản:
- Sử dụng một LLM để tạo ra một knowledge graph.
- Sử dụng knowledge graph để đào tạo một LLM.
- Sử dụng knowledge graph trên đường tương tác với một LLM để làm phong phú cho các truy vấn và câu trả lời.
- Sử dụng knowledge graphs để tạo ra các mô hình tốt hơn.
Trong mẫu cơ bản đầu tiên, chúng ta sử dụng các tính năng xử lý ngôn ngữ tự nhiên của LLMs để xử lý một lượng lớn dữ liệu văn bản (ví dụ, từ web hoặc các tạp chí). Sau đó, chúng ta yêu cầu LLM (mà làm cho nó trở nên không trong suốt) tạo ra một knowledge graph (mà là trong suốt). Knowledge graph có thể được kiểm tra, đánh giá chất lượng và được quản lý. Điều quan trọng đối với các ngành công nghiệp được quy định chặt chẽ như ngành dược phẩm, knowledge graph là rõ ràng và xác định về các câu trả lời của nó một cách mà LLMs không thể.
Trong mẫu cơ bản thứ hai, chúng ta thực hiện ngược lại. Thay vì đào tạo LLMs trên một bộ sưu tập chung lớn, chúng ta đào tạo chúng độc quyền trên knowledge graph hiện có của chúng ta. Bây giờ, chúng ta có thể xây dựng các chatbot có kỹ năng rất cao đối với sản phẩm và dịch vụ của chúng tôi và trả lời mà không gây hiện tượng mây mịt.
Trong mẫu cơ bản thứ ba, chúng ta chặn các tin nhắn đi và đến từ LLM và làm phong phú chúng bằng dữ liệu từ knowledge graph của chúng ta. Ví dụ, “Cho tôi xem năm bộ phim mới nhất với các diễn viên tôi thích” không thể được LLM trả lời một mình, nhưng nó có thể được làm phong phú bằng cách khám phá một knowledge graph về phim ảnh cho các bộ phim phổ biến và diễn viên của chúng, sau đó được sử dụng để làm phong phú lời yêu cầu được đưa ra cho LLM. Tương tự, trên đường trở lại từ LLM, chúng ta có thể sử dụng embeddings và giải quyết chúng trên knowledge graph để cung cấp thông tin sâu hơn cho người gọi.
Mẫu cơ bản thứ tư liên quan đến việc tạo ra các trí tuệ nhân tạo (AI) tốt hơn bằng knowledge graphs. Nghiên cứu thú vị từ Yejen Choi tại Đại học Washington cho thấy hướng tiến bộ tốt nhất. Trong công việc của nhóm của cô, một LLM được làm phong phú bởi một loại trí tuệ nhân tạo phụ, nhỏ hơn gọi là một “critic” (nhà phê bình). AI này tìm kiếm các lỗi trong quá trình suy luận của LLM, và trong quá trình đó tạo ra một knowledge graph để sử dụng ở bước tiếp theo bởi một quá trình đào tạo khác tạo ra một mô hình “sinh viên” (student). Mô hình sinh viên nhỏ hơn và chính xác hơn so với LLM gốc trên nhiều bài kiểm tra vì nó không học những sai sót về sự thật hoặc câu trả lời không nhất quán cho các câu hỏi.
Hiểu về đa dạng sinh học trên Trái đất bằng cách sử dụng knowledge graphs
Chúng ta cần tự nhắc lại lý do tại sao chúng ta đang thực hiện công việc này bằng các công cụ giống như ChatGPT. Sử dụng trí tuệ nhân tạo sinh sáng có thể giúp các nhân viên hiểu biết và chuyên gia thực hiện các truy vấn bằng ngôn ngữ tự nhiên mà họ muốn câu trả lời mà không cần phải hiểu và diễn giải một ngôn ngữ truy vấn hoặc xây dựng các giao diện lập trình ứng dụng nhiều lớp. Điều này có tiềm năng tăng cường hiệu suất và cho phép nhân viên tập trung thời gian và năng lượng của họ vào các nhiệm vụ quan trọng hơn.
Hãy xem xét Basecamp Research, một công ty công nghệ sinh học có trụ sở tại Anh đang thực hiện công việc thảo luận về đa dạng sinh học trên Trái đất và cố gắng hỗ trợ một cách đạo đức việc đưa các giải pháp mới từ thiên nhiên vào thị trường. Để làm điều này, họ đã xây dựng knowledge graph về đa dạng sinh học tự nhiên lớn nhất của hành tinh, gọi là BaseGraph, với hơn bốn tỷ mối quan hệ.
Bộ dữ liệu này đang cung cấp dữ liệu cho nhiều dự án đổi mới khác. Một trong số đó là thiết kế protein, trong đó nhóm đang sử dụng một mô hình ngôn ngữ lớn được đầu tư bởi một mô hình kiểu ChatGPT để tạo ra chuỗi enzyme gọi là ZymCtrl. Được xây dựng đặc biệt cho trí tuệ nhân tạo sinh sáng, Basecamp hiện đang tích hợp ngày càng nhiều mô hình ngôn ngữ lớn vào toàn bộ knowledge graph của họ. Công ty đang nâng cấp BaseGraph để trở thành một knowledge graph được bổ sung hoàn toàn bằng LLMs như cách tôi đã mô tả.
Làm cho nội dung phức tạp trở nên dễ tìm kiếm, truy cập và dễ giải thích hơn

Mặc dù công việc của Basecamp Research là tiên phong, nhưng họ không phải là người duy nhất đang khám phá kết hợp giữa LLM và knowledge graph. Một tập đoàn năng lượng toàn cầu nổi tiếng đang sử dụng knowledge graph cùng với ChatGPT trong đám mây cho trung tâm kiến thức doanh nghiệp của họ. Bước tiếp theo là cung cấp các dịch vụ nhận thức được cung cấp bởi trí tuệ nhân tạo sinh sáng cho hàng ngàn nhân viên trên các bộ phận pháp lý, kỹ thuật và các bộ phận khác.
Hãy xem xét một ví dụ khác, một nhà xuất bản toàn cầu đang chuẩn bị một công cụ trí tuệ nhân tạo sinh sáng được đào tạo trên knowledge graph sẽ giúp làm cho một lượng lớn nội dung học thuật phức tạp trở nên dễ tìm kiếm, truy cập và dễ giải thích hơn đối với các khách hàng nghiên cứu bằng ngôn ngữ tự nhiên hoàn toàn.
Điều đáng chú ý về dự án sau này là nó hoàn toàn phù hợp với cuộc thảo luận trước đó của chúng ta: chuyển đổi các ý tưởng cực kỳ phức tạp thành ngôn ngữ thực tế, trực quan, cho phép tương tác và sự hợp tác. Khi làm như vậy, nó giúp chúng ta giải quyết các thách thức quan trọng một cách chính xác và theo cách mà mọi người tin tưởng.
Dường như việc đào tạo một LLM trên dữ liệu được quản lý, chất lượng cao và có cấu trúc của knowledge graph đang trở nên rõ ràng hơn, loạt thách thức liên quan đến ChatGPT sẽ được giải quyết, và những phần thưởng mà bạn đang tìm kiếm từ trí tuệ nhân tạo sinh sáng sẽ dễ dàng hơn để thực hiện. Một báo cáo của Gartner vào tháng 6, “Các Mô Hình Thiết Kế Trí Tuệ Nhân Tạo cho Knowledge Graphs và Generative AI,” nhấn mạnh rằng knowledge graphs cung cấp một đối tác lý tưởng cho LLMs, nơi mức độ chính xác và sự chính xác cao là một yêu cầu.
Dường như đây là một sự kết hợp hoàn hảo đối với tôi. Còn bạn thì sao?
Jim Webber là nhà khoa học trưởng của Neo4j, một công ty hàng đầu trong lĩnh vực cơ sở dữ liệu biểu đồ và phân tích và là tác giả đồng tác giả của cuốn sách “Graph Databases” (phiên bản 1 và 2, O’Reilly), “Graph Databases for Dummies” (Wiley), và “Building Knowledge Graphs” (O’Reilly).